@Tsaukpaetra The one setting affected both. Afterward, my wife found a "custom" setting which allowed speed and temperature to be set to different unit systems.
But, frankly, I really couldn't care what Blakey thinks.
@Tsaukpaetra The one setting affected both. Afterward, my wife found a "custom" setting which allowed speed and temperature to be set to different unit systems.
But, frankly, I really couldn't care what Blakey thinks.
So I was in Canada, driving away from the airport at around 3AM in a newly picked up rental car, when the car started getting really sluggish. It was having a really hard time getting up to speed.
Finally figured it out: my wife had changed the climate control to display in Fahrenheit and this had the side-effect of changing the speedometer to MPH.
@Zerosquare said in FUCKING HELL WHY DOES IT REBOOT ZERO TIMES WHEN I CLICK REBOOT ONCE:
The bug only occurs if the hash for your motherboard's serial number falls into a certain range, which explains why some people like @pie_flavor never experience it.
Cue @Lorne-Kates commenting about @pie_flavor's motherboard.
Sheesh, really glad MPS got the boot.
Interesting journalism fail fallowed by a boring flame fest. Thanks for hanging around, @bjolling.
@null1 said in "Best" web technology?:
(probably MySQL, though I am open to
suggestions)
Why not MongoDB? I hear it can be used to emulate Redis.
Why does it need one?
The one it has does not match it's configured hostname, there is no reverse record for it and it is not known in advance. Most things I can think of that would ‘need’ a DNS record are broken by one of these issues.
I've seen it used to identify a POD in a field that required a valid DNS name. But it would be more straightforward to use the pod name in the first component.
But it isn't used for service discovery so doesn't factor into how well Kubernetes uses DNS for service discovery.
So according to the Register, Microsoft claims the customer wasn't setting resource limits and was overloading their nodes. Seems a typical "WOMM, ship it!" type issue.
On closer inspection I’m surprised they didn’t trigger the “Why are you posting screenshots of the Lounge?” dialog.
That also means that Microsoft is innocent in this one,
If the customer had brought their own Kubernetes to Azure then I would have agreed with you here. But they appear to be using a Microsoft-provided Kubernetes service. Microsoft's should have known about this problem.
because the delays appear only when going through the kubernetes internal DNS that is used (badly¹) for service discovery between the components orchestrated by kubernetes itself.
I wouldn't say they appear only through Kubernetes. The long DNS search list and extensive NAT use of typical Kubernetes deployments are significant exacerbating factors.
And according to the later comments on that bug, it appears the problem is in the internal DNS timing out on AAAA queries.
No, the problem is in the NAT implementation. The rapid-fire dual DNS queries increase the probability of triggering the problem and the poor retry logic of libc's DNS client makes the impact quite bad, but those are merely contributing factors. That Kubernetes doesn't support dual-stack well anyway is just the cherry on top.
¹ Kubernetes creates sensible DNS names for services (which are load-balancing fronts for things) in the form servicename
.namespace.svc.cluster.local..
So you say the DNS names for services are sensible, so what makes the use "badly"?
But for pods (the actual instances) while it gives them their names as hostnames, it does not register those in DNS, but instead gives them records of form dash-separated-ip-address
.namespace.pod.cluster.local.. Hell, if I know the IP address, I can just write it and don't need DNS and if I don't, you haven't helped me a iota.
A pods needs to have some DNS name; one constructed out of the IP address seems as good as any other. You don't necessarily need to use it.
@cartman82 said in WTF Bites:
- Random DNS failures
This is a known problem. The distributed fail here is epic.
And given that the runner is also (almost always) the shift manager
My sibling worked at a Burger King when in high school. Was known as "Super Push" because particularly competent at expediting, said position being called "push".
So not always shift manager.
@Atazhaia Perhaps I could suggest the anger management techniques in Daniel Tiger:

 When you feel so mad
When you feel so mad
That you want to roar, 
Take a deep breath
And kill a trans ...
Oh, wait, that's @Lorne-Kates!
@ApoY2k said in Google launched something called knative, but it's website won't tell you what it does:
AFAIUnderstand it, kubernetes is sort of an automatic load balancer. You just throw in your Docker images, configure it a bit and it will run them, restart them, scale them to your config.
Kubernetes has a load balancing component, but it has much larger scope.
Kubernetes is about orchestration. You install into it "resource definitions," YAML files describing the state of things you want to be. Programs called "controllers" notice these and work toward bringing reality in line with the desired state. It has a base set of resource definition types and corresponding controllers, in addition to some low level stuff to get things working.
Knative appears to be some higher level resource types and corresponding controllers. It also appears to have an events system.
We chose HipChat because it allows us to have the server be local, not in someone else's datacenter. Slack is blocked at the firewall.
Hipchat Server and Hipchat Data Center will also be discontinued and Atlassian said it is working on a “migration path” for its customers.
Well, fiddlesticks!
@erufael So what you’re telling us is that you’re one short of a full deck?
@tsaukpaetra There’s a whole cheap-ass TV series on that. Reasons range from extremely mild symptoms to extremely unobservant people.

Queues of "about a mile long" formed at one shopping centre, prompting calls to police.
A mother in Milton Keynes said she had taken her five-year-old daughter out of school to ensure they could get in the queue for a discounted bear.
"She's only five, they're not really doing much in school that's important at that age," she said.

@ben_lubar said in How not to do UUIDs:
congrats on this word having 4 Google results and all of them being this page.
Apple does a little better:
Except for Maps. But, you know, Apple Maps.
@lorne-kates said in Uber, the sociopathic company full of psychopaths, now with murder! (Because regulations aren't "Disruptive" enough!):
Huh? I can't find any reference to those. Did you mean these:
No, more like:

@lorne-kates said in Uber, the sociopathic company full of psychopaths, now with murder! (Because regulations aren't "Disruptive" enough!):
- there is no such thing as a "designated speed trap zone". WTF are you even talking about?
Florida. The speed limit signs for such have a yellow band above them.
@stillwater When I was in the Boy Scouts the thing was to send the newbies around asking for a left handed smoke shifter.
When some came around our camp we gave them an old blower motor. We were later treated to the sight of the scoutmaster two camps over scratching his head looking at what his scouts brought back.

Redoine Faid sparks a 3,000-strong manhunt after escaping French prison with the help of armed men.
The prison courtyard where the helicopter landed was the only area not protected by anti-aircraft netting. Prison union representative Martial Delabroye said that was because inmates do not use it, "except to leave the prison".
Well, okay then!
@thebread said in Enterprise scale application on a consumer account? Genius!:
What's even funnier is the dev gets called for that
By a "Customer Engineer, Google Cloud".
@dkf I think one of JIRA's main problems is that it's too customizable. Because it's always customized badly.
@magnusmaster said in I'm done with MS and their .NET Core Bullshit:
jwt tokens
Are those like ATM machines?
@the_bytemaster said in Xamarin's contiuing barrel of cross-platform, XML-encoding fut the wuckery:
I am hoping that this move to http://docs.microsoft.com will be the last big move for a long time.

@gąska said in The Official Status Thread:
the most boring last 10 minutes I've ever seen
@pie_flavor And for some reason it indents your signature?
Got a letter today. My Canadian account is converting from a bankbook to electronic statements.
Will wonders never cease?
@polygeekery How are they to learn except by observation? This too shall pass.
So to speak.
@kian said in Branches, Builds, and Deployment:
I should clarify we don't have a service but rather an on premise product
For our legacy on-premise product I got rid of the master branch.
Used to be when we thought we were close to release we'd cut a release branch from master. People wouldn't get the memo and would commit code intended for the release into master after the release was branched.
So next release after cutting the release branch I deleted master. After that we would branch the next release off of the pending release whenever we were ready to start work on the next release. As people usually knew which release their change was intended for they would know which branch to commit into.
And we had automated merges from earlier pending release branches into later ones.
@sockpuppet7 said in Branches, Builds, and Deployment:
It's buying you that this way the master branch is a place where you'll apply hotfixes if needed.
Nope, hotfixes have to go through develop as well. If develop is busted, ain't no fixes going to production.
It's not the only way for doing that, but I don't see how other methods would be significantly better than that.
Hotfix goes into its own feature branch. Integration tests on the build from that branch pass, code review approved, merge to master.
@magus said in Branches, Builds, and Deployment:
@greybeard said in Branches, Builds, and Deployment:
Sure, when a change to a service doesn't break its own tests but does break the tests of its clients one has to do something to get some confidence that breakage would get noticed, diagnosed, and reported.
But why tie that to the length and boundaries of a sprint?Because that's the point of sprints?
The point of sprints is to put a limit on requirements churn.
For every bit of code to remain in QA for an entire sprint before promotion then any change would have to enter QA and wait until the end of the current sprint. Then that entire artifact would have to remain in QA without change for the entirety of that subsequent sprint. It could then be promoted in the second sprint after it was last changed.
There is nothing about the point of sprints that prevents QA from being scheduled to start testing the change in the same sprint as it was made or which invalidates any testing done before the subsequent sprint boundary.
@unperverted-vixen said in [Branches, Builds, and Deployment](/post
I heard rumor of some teams cherry-picking from develop into master, which is just
That's what we do.
It kinda invalidates the testing that happened against develop. Plus a problem with one change in develop has a good chance of preventing anything else from going forward.
Since we can't deploy multiple feature branches
Yeah, I figured having a high cost for creating deployment environments to be the most likely reason for having the anti-pattern. Aside from the irrational ones, such as "we can't have artifacts with release-format version numbers which haven't passed QA" or "we have to make sure we don't break staging."
I suppose in theory we could use feature branches for development, merge to development for QA testing, then when stuff is approved merge from the feature branch to master. But I just don't see a benefit to that approach, besides burning lots of developer hard drive space.
You could automate the creation and removal of deployment environments, thus allowing you to deploy multiple feature branches.
You could have feature branch builds take turns deploying and testing in that single not-staging environment.
@magus said in Branches, Builds, and Deployment:
If we have something major enough, we'll talk about it
So by "with no exceptions" you mean "with exceptions"?
But generally, it's not about work that takes two weeks, it's about having something stable and used for a long enough period that we feel comfortable calling it stable before we move it forward.
So instead of test coverage you're just hoping someone happens to notice something and complain?
Sure, when a change to a service doesn't break its own tests but does break the tests of its clients one has to do something to get some confidence that breakage would get noticed, diagnosed, and reported.
But why tie that to the length and boundaries of a sprint?
@magus said in Branches, Builds, and Deployment:
I want every bit of code to remain in QA for an entire sprint before promotion, with no exceptions.
So no way to even do a production break-fix before the end of the following sprint?
I'm curious: what is it your QA folks are doing that takes them the bulk of a sprint to detect a stop-ship problem?
@unperverted-vixen said in Branches, Builds, and Deployment:
Two branches. Call them Development and Master.
A bunch of projects here have a "develop" branch. The "develop" branch seems a big anti-pattern to me. If the only way to get into master is through develop and everything in develop goes into master at once, then what is all this faffing about with develop buying anyone? Just put it directly into master!
I heard rumor of some teams cherry-picking from develop into master, which is just .
I am carrying out a war on "develop" branches.

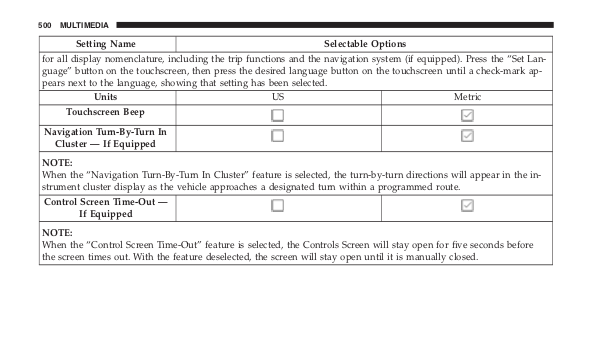
 Horrors of using Azure Kubernetes Service in production
Horrors of using Azure Kubernetes Service in production
 Yakety-yak app HipChat whacked in Slack chat chaps' tech snatch pact
Yakety-yak app HipChat whacked in Slack chat chaps' tech snatch pact

 Soccer, by Paul and Storm
Soccer, by Paul and Storm
 https://www.amazon.com/Tough-Coughs-Ploughs-Dough-Writings/dp/0688065481/ref=sr_1_1
https://www.amazon.com/Tough-Coughs-Ploughs-Dough-Writings/dp/0688065481/ref=sr_1_1
{kind=link}