WTF Bites
-
@dcon Don't give fbmac ideas.
-
@dcon The Bad Idea Thread is

-
@Zerosquare said in WTF Bites:
I'd be curious to see what an AI would generate if you used Blakeyrat's posts as a training set.
 Use these forums (yes, especially the garage; no, not the Lounge) as the training material.
Use these forums (yes, especially the garage; no, not the Lounge) as the training material.It'd be all kinds of awesome!
-
-
-
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
New benefit at work this year: Prudential Insurance that pays out for various accidents, emergency room visits, etc. So I signed up and the other day got mail from them saying that I should set up an account in their portal where I can make claims, etc. Cool...I don't have a claim to make right now but I'd like to be prepared just in case. Follow the links and end up here:
Ah, "Register Now." That looks like what I need. So I click it. A javascript "link," natch. It goes here:
https://mybenefits/nonssocontroller/newUserReg.htm
Good jerb, guys. I went to their "Accessibility Help" page and told them about how I can't access the registration page.
The register button works now. However...
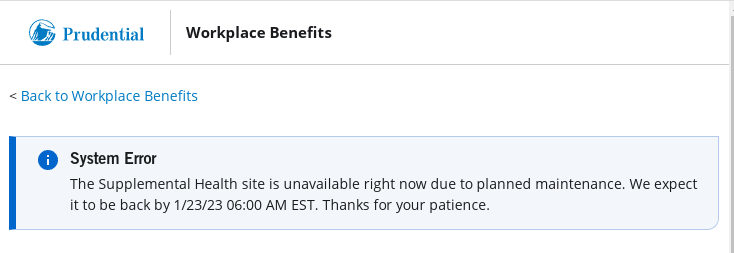
And so we proceed...
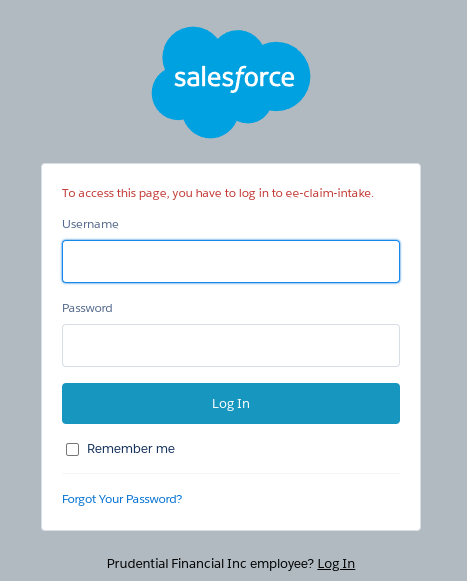
No idea what the
ee-claim-intakemight be. And no, my user credentials for the Prudential site don't get me past that.Is this a step forwards or backwards?

-
-
@boomzilla More balloons spotted!
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
New benefit at work this year: Prudential Insurance that pays out for various accidents, emergency room visits, etc. So I signed up and the other day got mail from them saying that I should set up an account in their portal where I can make claims, etc. Cool...I don't have a claim to make right now but I'd like to be prepared just in case. Follow the links and end up here:
Ah, "Register Now." That looks like what I need. So I click it. A javascript "link," natch. It goes here:
https://mybenefits/nonssocontroller/newUserReg.htm
Good jerb, guys. I went to their "Accessibility Help" page and told them about how I can't access the registration page.
The register button works now. However...
And so we proceed...
No idea what the
ee-claim-intakemight be. And no, my user credentials for the Prudential site don't get me past that.Is this a step forwards or backwards?
Try escalating the issue

BTW, this is what your employer holds your value at - go ahead, waste your meaningless time.
-
Unexpected error? Aren't all errors supposed to be unexpected?
-
@Gern_Blaanston said in WTF Bites:
Unexpected error? Aren't all errors supposed to be unexpected?
Only when testing!
-
@Tsaukpaetra And they are testing in production?
-
 Tesla to recall 362,758 cars because Full Self Driving Beta is dangerous
Tesla to recall 362,758 cars because Full Self Driving Beta is dangerous

NHTSA has concerns about four different kinds of FSD behavior.
My brain initially misread the title as 32, 768 cars and I thought "Damn, they're recalling 32 megabytes of cars".
-
@Gern_Blaanston 32 kilobytes. That number is burned into my memory from dealing with 8-bit computers...
-
-
@Gern_Blaanston 32 kilobytes. That number is burned into my memory from dealing with 8-bit computers...
Oops, yes, should be kilobytes.
-
Huawei’s Watch Buds ask: “What if your smartwatch also contained earbuds?”

The whole watch face lifts up, revealing a mostly hollow body that holds earbuds.

-
The client's in-house developer is making JSON, or rather what he thinks is a JSON, with sprintf. He somehow hasn't come up with the idea of trying to parse it before sending it to us for review.
-
@sebastian-galczynski said in WTF Bites:
The client's in-house developer is making JSON, or rather what he thinks is a JSON, with sprintf.
Most people are
 .
.… but usually it's hidden deep in the bowels of a serializer that takes care of closing all braces, brackets and quotes, putting commas where they belong and escaping the text between quotes. Doing it by hand is an option for simpler cases, but yeah, you have to check it's valid before you declare the task complete.
-
@sebastian-galczynski said in WTF Bites:
The client's in-house developer is making JSON, or rather what he thinks is a JSON, with sprintf.
Most people are
.… but usually it's hidden deep in the bowels of a serializer that takes care of closing all braces, brackets and quotes, putting commas where they belong and escaping the text between quotes. Doing it by hand is an option for simpler cases, but yeah, you have to check it's valid before you declare the task complete.
The guy is doing verification by sending it to the guys who are paid to deal with it. They will tell him what's wrong if he just
 enough. Much better than trying to make sense of what a parser would complain about!
enough. Much better than trying to make sense of what a parser would complain about!
-
Doing it by hand is an option for simpler cases, but yeah, you have to check it's valid before you declare the task complete.
This.
But also fuck JSON for getting its panties into a twist about extra commas and such.
-
But also fuck JSON for getting its panties into a twist about extra commas and such.
I strongly disagree with it's choice of comma separating entries instead of terminating them, but otherwise it's reasonable. Fail early, fail loud.
… it should also insist on consistent formatting and unicodebetically sorted keys
 .
.
-
WTF SAP! you don't have money to put a decent stock photo there ...
Also:

-
@Luhmann You see anything indecent on that photo?
-
@Bulb
there is definitely more going on under the fold, horny bean counters
-
… it should also insist on consistent formatting and unicodebetically sorted keys .

JSON et al. seems to be for the kind of amounts of data that you can wrangle with a shell script (
 ). Keeping track of state and ordering is a pain there. Just let me process things entry-by-entry.
). Keeping track of state and ordering is a pain there. Just let me process things entry-by-entry.(inb4 bash has support for arrays and hash tables.)
-
The guy is doing verification by sending it to the guys who are paid to deal with it.
They can just run it through JSONSchema and see whether it conforms to anything they want to accept. If not, send it back with
NOT ACCEPTABLE; GENERATOR ERROR!without saying anything else.
-
The guy is doing verification by sending it to the guys who are paid to deal with it.
They can just run it through JSONSchema and see whether it conforms to anything they want to accept. If not, send it back with
NOT ACCEPTABLE; GENERATOR ERROR!without saying anything else.To run it through JSONSchema, I'd have to first run it through JSON.parse(), which I didn't even try, because the propsed thing ended with a rather conspicuous
},},}
-
@sebastian-galczynski said in WTF Bites:
The guy is doing verification by sending it to the guys who are paid to deal with it.
They can just run it through JSONSchema and see whether it conforms to anything they want to accept. If not, send it back with
NOT ACCEPTABLE; GENERATOR ERROR!without saying anything else.To run it through JSONSchema, I'd have to first run it through JSON.parse(), which I didn't even try, because the propsed thing ended with a rather conspicuous
},},}I don't see anything wrong with that par se... he could have just not indented the last three closing } for the nested object chain

-
JSON et al. seems to be for the kind of amounts of data that you can wrangle with a shell script
You need
jqor similar for that anywayKeeping track of state and ordering is a pain there. Just let me process things entry-by-entry.
Requiring it comes sorted makes that easier, because than you just have to remember the previous key and check it precedes the current one. If they are not sorted, you have to remember all of them to check they don't repeat.
-
@sebastian-galczynski said in WTF Bites:
To run it through JSONSchema, I'd have to first run it through JSON.parse(), which I didn't even try, because the propsed thing ended with a rather conspicuous
},},}Then it will go
COMPUTER SAYS NO. Job done.My point was to throw it back in their face when they can't get their shit together. It is their fault.
-
Requiring it comes sorted makes that easier, because than you just have to remember the previous key and check it precedes the current one. If they are not sorted, you have to remember all of them to check they don't repeat.
I don't know why I'd check that at all. If the problem is in the data, then input validation should take care of that independently of being invalid JSON or whatever. If the problem is in the schema (formal or informal), the suggestion sounds a lot like one should sort their class members alphabetically to make it easy to spot if somebody typed one twice (which isn't useful either).
Besides, keeping items sorted by key (realistically) means that you have to have all key-value pairs in memory whenever the key changes. If you just want to check for duplicate keys, you just have to remember the keys.
-
My point was to throw it back in their face when they can't get their shit together. It is their fault.
That's what we did. Now he's defending his "JSON". He says he 'thought it's not a problem to our parser' and 'always done that'.
What actually happens: he probably passes this crap through some unusually permissive parser somewhere further down the chain, so that's not what gets sent to our API. But if so, why would he make us review something that's not exactly the same thing that we're going to recieve?This is the same guy that "struggled" with that JWT expiry timestamp, and again I can't shake off suspicions of sabotage.
-
-
@sebastian-galczynski said in WTF Bites:
again I can't shake off suspicions of sabotage
He's a fuckwit. You don't need to be respectful of his time and effort.
-
Requiring it comes sorted makes that easier, because than you just have to remember the previous key and check it precedes the current one. If they are not sorted, you have to remember all of them to check they don't repeat.
I don't know why I'd check that at all. If the problem is in the data, then input validation should take care of that independently of being invalid JSON or whatever.
It is job for the input validation. There are good reasons RFC 8785 exists.
If the problem is in the schema (formal or informal), the suggestion sounds a lot like one should sort their class members alphabetically to make it easy to spot if somebody typed one twice (which isn't useful either).
There are many better reasons to keep the members sorted in the schema and documentation. E.g. it's easier to find the elements and it's easier to merge—if everybody adds to the end, there is always conflict, if it's sorted, there almost never is.
By the way, have you ever noticed the order of elements in a XML schema is (usually; it can be relaxed by jumping through some hoops) mandatory for the document?
Besides, keeping items sorted by key (realistically) means that you have to have all key-value pairs in memory whenever the key changes. If you just want to check for duplicate keys, you just have to remember the keys.
Key is a key. It cannot change. Changing a key means deleting the old entry and adding a new one.
-
@sebastian-galczynski said in WTF Bites:
again I can't shake off suspicions of sabotage.
This is very likely an internal aspect of the foreign policy of their country of origin, India. If it isn't, well, then there is nothing they are good at.
-
keeping items sorted by key (realistically) means that you have to have all key-value pairs in memory whenever the key changes.
Realistically, we had merge sort even before we had memory, and the value is reducible to a reference.
If you just want to check for duplicate keys, you just have to remember the keys.
In for instance memory, I suppose. Maybe you mean in less memory? Like a Bloom filter? And of course one would need all the keys in memory, as it may take log-n random file accesses to search a sorted corpus.
-
It is job for the input validation. There are good reasons RFC 8785 exists.
My point is that if there is a reason the data cannot have duplicate entries, then that's a part of validation outside of JSON or any other serialization format. JSON being unable to have duplicate keys for their dictionary-style objects is separate from that.
Key is a key. It cannot change. Changing a key means deleting the old entry and adding a new one.
That's maybe a bit of poor wording on my part. Consider instead joining two datasets, where the joined dataset has a new set of keys (simplest case is perhaps translating from one key to a different one, because one of the systems uses one type of key and another one uses a different). If you want to keep the keys sorted, that's a global operation.
For @Gribnit: Sorting: O(N) memory and O(N log(N)) operations. Checking for duplicate keys is just amortized O(N) in both memory and operations. The latter has a smaller constant (just the size of the key), the former has a larger one (the key and value, which even with a reference will be in memory, and references are still extra memory). You're probably using hash tables in both cases, so data structure overheads will be similar.
-
It is job for the input validation. There are good reasons RFC 8785 exists.
My point is that if there is a reason the data cannot have duplicate entries, then that's a part of validation outside of JSON or any other serialization format. JSON being unable to have duplicate keys for their dictionary-style objects is separate from that.
Key is a key. It cannot change. Changing a key means deleting the old entry and adding a new one.
That's maybe a bit of poor wording on my part. Consider instead joining two datasets, where the joined dataset has a new set of keys (simplest case is perhaps translating from one key to a different one, because one of the systems uses one type of key and another one uses a different). If you want to keep the keys sorted, that's a global operation.
For @Gribnit: Sorting: O(N) memory and O(N log(N)) operations. Checking for duplicate keys is just amortized O(N) in both memory and operations. The latter has a smaller constant (just the size of the key), the former has a larger one (the key and value, which even with a reference will be in memory, and references are still extra memory). You're probably using hash tables in both cases, so data structure overheads will be similar.
Point is tho that at scale I would be using a Bloom filter backed by binary file search.
-
@Gribnit Yeah, sure, why not. Bloom filter reduces the lookups further, so checking for existing keys is even more efficient. Binary file search sounds awful, and excruciatingly so when you have your data in JSON. To be fair, if you have enough data for this to be a consideration, it's probably not in JSON. (I hope.)
-
Checking for duplicate keys
Most code that processes JSON doesn't bother to check for duplicate keys within an object at all, and it is entirely undefined which actual key/value pair it will use when someone gives malformed data. But only validators and code by paranoids (
 ) really check for dupes. The order of keys in an object is defined to be unimportant (except perhaps for canonicalisation, and then you have many other things to care about too). Sort if you want, JSON don't care.
) really check for dupes. The order of keys in an object is defined to be unimportant (except perhaps for canonicalisation, and then you have many other things to care about too). Sort if you want, JSON don't care.Validation is best left as something to only turn on when someone is being an idiot. This case sounds like time to flip that switch.
-
Bloom filter
 Google:
Google:
After searching, the page split and looked like it was folding in on itself or something. Some kind of Easter Egg coding challenge thing. Hyeah, right.
-
@boomzilla If you do well enough at that challenge (solve ~8 big data related code challenges in Java or Python) you move to the front of the line for a job at Google.
-
@TwelveBaud I figured it was going to be something awful like that.
-
@boomzilla said in WTF Bites:
@TwelveBaud I figured it was going to be something awful like that.
Responding to their emails carries similar hazards.
But, glad to show you a tiny glimpse of the world you would otherwise never see. Don't thank me - thank you.
-
-
Bloom filter reduces the lookups further
It's also an important part of Irish cultural life.
-
@boomzilla said in WTF Bites:
@TwelveBaud I figured it was going to be something awful like that.
Responding to their emails carries similar hazards.
But, glad to show you a tiny glimpse of the world you would otherwise never see. Don't thank me - thank you.
Indeed. The downside of not being formally trained in CS is that I've never had exposure to lots of stuff like that. The upside, of course, is everything else.



 Leopold Bloom - Wikipedia
Leopold Bloom - Wikipedia
