AWS issues
-
@dse said in AWS issues:
@ben_lubar said in AWS issues:
@dse said in AWS issues:
Why Go+PHP?!!!?

@dse said in AWS issues:
Go JIT
The original flame graph I remember you had Go extensions that were JIT compiled. Where as the majority of forum is in another language (PHP?, or JS?)
O think you're thinking of something completely different....
-
@dse said in AWS issues:
@ben_lubar said in AWS issues:
@dse said in AWS issues:
Why Go+PHP?!!!?
@dse said in AWS issues:
Go JIT
The original flame graph I remember you had Go extensions that were JIT compiled. Where as the majority of forum is in another language (PHP?, or JS?)
 GitHub - gopherjs/gopherjs: A compiler from Go to JavaScript for running Go code in a browser
GitHub - gopherjs/gopherjs: A compiler from Go to JavaScript for running Go code in a browser
A compiler from Go to JavaScript for running Go code in a browser - gopherjs/gopherjs
-
@Lorne-Kates said in AWS issues:
@Tsaukpaetra said in Testing candidate's mettle S02E04:
I heard we ran out of AWS credits

Why the fuck does a forum software need so much CPU that it requires a goddamn AWS?!?
And how the fuck does a forum software manage to EXCEED THE AWS CREDITS?!?!
Javascript.
-
@dangeRuss said in AWS issues:
@Weng said in AWS issues:
... I want to know how the fuck a t2.micro with Windows is cheaper than a t2.micro with RHEL or SLES.
Hmm
windows
t2.micro 1 Variable 1 EBS Only $0.018 per HourRHEL
t2.micro 1 Variable 1 EBS Only $0.073 per HourSLES
t2.micro 1 Variable 1 EBS Only $0.023 per HourWell RHEL costs money too, and not sure about SLES.
On the other hand RHEL is probably licensed per instance, but with windows you can probably run a shitton VMs with a single datacenter license (on a single physical box).
RHEL https://www.redhat.com/wapps/store/catalog.html
2 sockets, 1 physical or 2 virtual nodes
Standard Subscription (1 year) $799 USD
Premium Subscription (1 year) $1,299 USD
-
@dse said in AWS issues:
Where as the majority of forum is in another language (PHP?
Hint: it's in the name of the software
-
well..... things seem to have improved today..... the forum is no longer physically painful to browse, and servercooties says it's been good for at least an hour.
so..... assuming things stay this way.... time for a retrospective then?
- What was the proximate cause of this multi-day cooties storm?
- What was the ultimate cause of the multi-day cooties storm?
- What was done to alleviate this cooties storm?
- What has been done to prevent this from occurring again?
@ben_lubar, As you are the sole (to my knowledge) active member of this forum with the necessary level of access to assess and affect these questions, would you be so kind as to chime in with the best approximation of an answer to these questions we have?
Thank you.
-
-
@Yamikuronue said in AWS issues:
@accalia said in AWS issues:
assuming things stay this way...
Big assumption :(
and a flawed one it appears.
-
@accalia said in AWS issues:
assuming things stay this way
Why would you say it? It's the equivalent of saying "Well, it can't get any worse!"
-
@accalia said in AWS issues:
well..... things seem to have improved today..... the forum is no longer physically painful to browse, and servercooties says it's been good for at least an hour.
so..... assuming things stay this way.... time for a retrospective then?
- What was the proximate cause of this multi-day cooties storm?
- What was the ultimate cause of the multi-day cooties storm?
- What was done to alleviate this cooties storm?
- What has been done to prevent this from occurring again?
@ben_lubar, As you are the sole (to my knowledge) active member of this forum with the necessary level of access to assess and affect these questions, would you be so kind as to chime in with the best approximation of an answer to these questions we have?
Thank you.
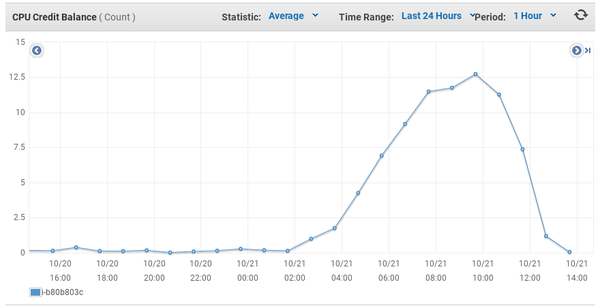
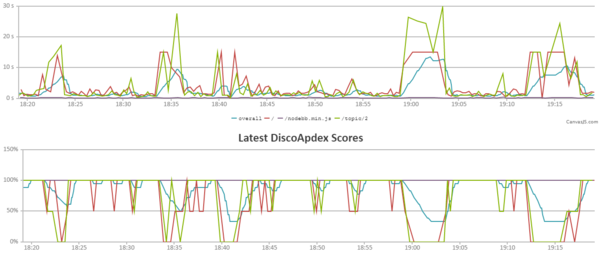
(first image is UTC, second image is UTC-6, 00:00 in the first image corresponds to 18:00 in the second)
Basically, with a t2.medium instance, we have access to 40% of one CPU core (or 20% of two) plus an additional 40% that we can save up to 24 hours worth. One CPU credit is worth 100% utilization of a single CPU core for 1 minute, so our peak in the first graph is only worth 12-ish minutes of two cores running at max speed (we need about 1.6 credits for 1 minute of both cores being maxed out).
We saved up some credits while most of our readers were asleep, but then people woke up and went to work and started browsing and we quickly ran out.
As to why the cooties are a lot less bad than before, I think a major reason is that a bot was doing what appeared to be a dumb breadth first traversal and that bot is now banned along with the other bad bots. It had 28329 page views this week, with 500+ of them today, even after it has been getting 503s on every pageview for over 24 hours. For a comparison, all sockbots together have 17362 pageviews this week, and there are 5 active sockbots.
-
@ben_lubar Do the logs go sufficiently far back to determine what else has changed? If the bot were the sole cause of the high CPU usage, things should have returned to normal by now. They're definitely better than a couple days ago, but still not great.
What does the two-week credit usage look like? If there is a day where it suddenly changes, can it be reconciled with the access logs to find the cause?
-
@reverendryan We know what drained the credits: the constant restart loop the site got into overnight one night burned through our entire reserve stock of credits before any admins were around to stop it.
-
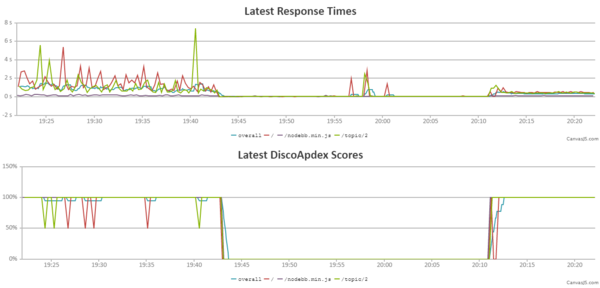
@Yamikuronue Something is still different, though, or the credit balance would be bouncing back with the restart loop fixed and the bot banned.
According to Ben's graph, between 10:00 and 12:00 UTC we were using credits at a rate of about 28/hour, or a net loss of 4 credits per hour (we earn 24/hour), while in the 8-hour overnight period we gained credits at a rate of about 1.5/hour. If I've mathed correctly that's a net spend of about 50 credits per day. We can accumulate up to 576 credits. At this burn rate we run out of credits in only 12 days if we start with a full bank which is why I think something is still changed/wrong.
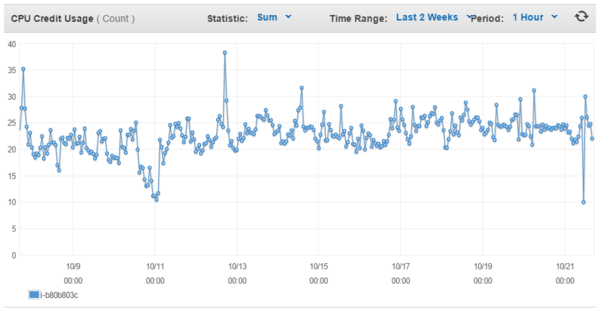
There's an actual CPU Credit Usage graph that @ben_lubar could pull with two weeks of history.
-
@reverendryan said in AWS issues:
There's an actual CPU Credit Usage graph that @ben_lubar could pull with two weeks of history.
Pull request accepted!
-
@ben_lubar said in AWS issues:
Basically, with a t2.medium instance, we have access to 40% of one CPU core (or 20% of two) plus an additional 40% that we can save up to 24 hours worth. One CPU credit is worth 100% utilization of a single CPU core for 1 minute, so our peak in the first graph is only worth 12-ish minutes of two cores running at max speed (we need about 1.6 credits for 1 minute of both cores being maxed out).
That's with 4 GB if I'm not mistaken? I mean, I have plenty of CPU free on my OVH server and 4 GB won't hurt any of the other VMs on it either, so if you want a VM with 2-3 cores and 4 GB, you can have one for free.
I have overprovisioned the CPUs so the cores are not guaranteed 100% of the time but as bored as that box is most of the time it would definitely beat the AWS VM hands down.
-
@reverendryan said in AWS issues:
or a net loss of 4 credits per hour (we earn 24/hour)
I don't think that's how it works. You only earn credits if you're idle, not if it's under any sort of load. While you're burning credits, you don't earn any. At least that's how I read it.
-
@e4tmyl33t said in AWS issues:
@reverendryan said in AWS issues:
or a net loss of 4 credits per hour (we earn 24/hour)
I don't think that's how it works. You only earn credits if you're idle, not if it's under any sort of load. While you're burning credits, you don't earn any. At least that's how I read it.
We get 24 credits if we stay below 20% usage per core. If we have more than 20% usage, it eats part of those credits.
-
@ben_lubar said in AWS issues:
20% usage per core
So in other words, 0 usage on your graph? Meaning we haven't earned any credits in the past two weeks?
We are definitely too big for this box
-
@ben_lubar That's... more subtle than I was expecting; we're mostly under the 24-credit mark on the left (if only just), and mostly at/over on the right. Not the smoking gun I was hoping for, though, in terms of pining down a specific event.
@e4tmyl33t said in AWS issues:
I don't think that's how it works. You only earn credits if you're idle, not if it's under any sort of load. While you're burning credits, you don't earn any. At least that's how I read it.
It does; our credits accumulate regardless of usage, they are just spent immediately if we're using the CPU above the threshold.
AWS said in [http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/t2-instances.html#t2-instances-cpu-credits]
Each T2 instance starts with a healthy initial CPU credit balance and then continuously (at a millisecond-level resolution) receives a set rate of CPU credits per hour, depending on instance size. The accounting process for whether credits are accumulated or spent also happens at a millisecond-level resolution, so you don't have to worry about overspending CPU credits; a short burst of CPU takes a small fraction of a CPU credit.
When a T2 instance uses fewer CPU resources than its base performance level allows (such as when it is idle), the unused CPU credits (or the difference between what was earned and what was spent) are stored in the credit balance for up to 24 hours, building CPU credits for bursting.So, maybe we should talk short- and long- term fixes. @apapadimoulis, would you approve upgrading the instance class to t2.large to accommodate our current credit usage, until the forum can be moved out of AWS in December? If you wanted to crowd-fund the difference, I'm sure enough people (myself and @accalia at least) would donate.
-
@reverendryan I also have a balance in the "light money on fire" budget.
-
I would "Twitch subscribe" ($5/mo) to WTDWTF Forums.
-
Sorry, did I read this correctly? It costs $200 a month to host these forums and - given all the cooties - that is not enough?
How expensive would TDWTF be if it were running on MyBB? A tenner a month?
-
@reverendryan said in AWS issues:
So, maybe we should talk short- and long- term fixes. @apapadimoulis, would you approve upgrading the instance class to t2.large to accommodate our current credit usage, until the forum can be moved out of AWS in December? I
that's more or less the plan i've been talking over with alex and ben via email (because it's easier to get to these days than the forum). at leastr i think that's the plan....
I'll let @ben_lubar explain the plan more fully once he and Alex hash out the fine details.
-
You know what they do to horses that are as crippled as this server, right? Just sayin'.
-
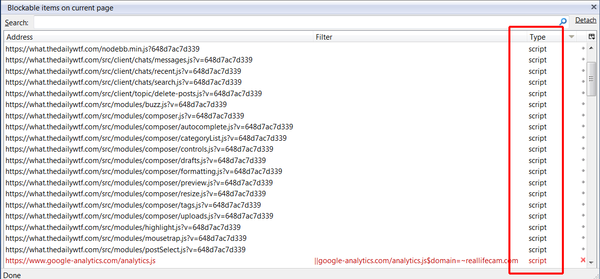
Maybe you wouldn't need an entire Amazon Data Center if you didn't have this insanity on every page:
-
@HardwareGeek said in AWS issues:
You know what they do to horses that are as crippled as this server, right? Just sayin'.
I eagerly await your answer. But it never comes. Because new-post streaming randomly stopped working.
So apparently we a huge server to run NodeBB because it's a cutting edge forum that uses tons of CPU power in order to not do it's core feature well. =(
-
@El_Heffe said in AWS issues:
Maybe you wouldn't need an entire Amazon Data Center if you didn't have this insanity on every page:
Are those all 200, or are any of them 304?
What's the size of all those requests?
Also, adblocker FTW there. ;)
-
@Lorne-Kates said in AWS issues:
What's the size of all those requests?
For a larff, I did a hard refresh on the page.
http://i.imgur.com/4QbwjnC.png
500k across 56 requests.
Across 19s to request and 28 seconds to load. :|
Also, I don't know if I've ever in my life seen a 101 response code.
-
@Lorne-Kates said in AWS issues:
Also, I don't know if I've ever in my life seen a 101 response code.
As a Firefox 22 user, I'm surprised websockets work on your browser.
-
@Lorne-Kates said in AWS issues:
(Just the title)I eagerly await your answer.
-
@ben_lubar said in AWS issues:
@Lorne-Kates said in AWS issues:
Also, I don't know if I've ever in my life seen a 101 response code.
As a Firefox 22 user, I'm surprised websockets work on your browser.
You use Firefox 22, too?
"As a Firefox 22 user, I prefer chewy chocolate chip cookies over crunchy ones."
-
@Lorne-Kates said in AWS issues:
Also, I don't know if I've ever in my life seen a 101 response code.
"A status code of 101 indicates that the server is changing to the protocol it defines in the "Upgrade" header it returns to the client. For example, when requesting a page, a browser might receive a statis code of 101, followed by an "Upgrade" header showing that the server is changing to a different version of HTTP."

-
@Lorne-Kates said in AWS issues:
@ben_lubar said in AWS issues:
@Lorne-Kates said in AWS issues:
Also, I don't know if I've ever in my life seen a 101 response code.
As a Firefox 22 user, I'm surprised websockets work on your browser.
You use Firefox 22, too?
How do you think I tested all the bugfixes?
-
@ben_lubar The same way you stress-tested the system?

-
@ben_lubar said in AWS issues:
@Lorne-Kates said in AWS issues:
Also, I don't know if I've ever in my life seen a 101 response code.
As a Firefox 22 user, I'm surprised websockets work on your browser.
As an admin of this forum, your modifiers dangle.
-
-
@accalia said in AWS issues:
servercooties says it's been good for at least an hour.
@accalia said in AWS issues:
assuming things stay this way
I'm not feeling particularly confident in that assumption for the near future.
-
@e4tmyl33t said in AWS issues:
@pydsigner said in AWS issues:
your modifiers dangle.

Please restrict discussion of modified dangles to the
 thread.
thread.
-
@HardwareGeek said in AWS issues:
@e4tmyl33t said in AWS issues:
@pydsigner said in AWS issues:
your modifiers dangle.
Please restrict discussion of modified dangles to the
thread.What does that thread have to do with piercings?
-
@Dreikin said in AWS issues:
What does that thread have to do with piercings?
I don't know what it has to do with now. I set it to "ignore" thousands of posts ago. The way topics drift around here, it could be discussing almost anything imaginable, including any number I'd rather not imagine.
-
-
Left side: one potato. Right side: 8 eggplants. Middle: 1 @ben_lubar.
-
Thanks, @ben_lubar and @apapadimoulis!
-
Oh yeah, this is nice and zippy! Well done.
-
It seems that one-boxing is broken, though.
On the other hand, it seems that one-boxing is broken.
Filed under: Is that good or bad...?
-
@djls45 said in AWS issues:
It seems that one-boxing is broken, though.
On the other hand, it seems that one-boxing is broken.
Filed under: Is that good or bad...?Whoops, sorry about that. Fixed. (Sorry about the 502-ing while I fixed it)
-
@El_Heffe The way I understand it, this is the response websockets look for.
 RFC 6455: The WebSocket Protocol
RFC 6455: The WebSocket Protocol

The WebSocket Protocol enables two-way communication between a client running untrusted code in a controlled environment to a remote host that has opted-in to communications from that code. The security model used for this is the origin-based security model commonly used by web browsers. The...
Filed Under: Look at it at your own risk
-
@Kuro said in AWS issues:
@El_Heffe The way I understand it, this is the response websockets look for.
RFC 6455: The WebSocket Protocol
The WebSocket Protocol enables two-way communication between a client running untrusted code in a controlled environment to a remote host that has opted-in to communications from that code. The security model used for this is the origin-based security model commonly used by web browsers. The...
Filed Under: Look at it at your own risk
I ain't afraid of no RFC!
Filed under: famous last words
-
-
 They Shoot Horses, Don't They? (1969) ⭐ 7.8 | Drama
They Shoot Horses, Don't They? (1969) ⭐ 7.8 | Drama

{kind=link}
{kind=link}