WTF Bites
-
I can upload an anonymized version of the explanation from my lawyer if you're interested?
Nah thanks, I'll trust your lawyer and insurance to know what the heck they're doing.
Just wanted to say I'm surprised by this, because IMO you should just tell them (the claiming party, not your insurance) "proof or GTFO".
-
@Benjamin-Hall said in WTF Bites:
WTF of my life right now When adding an integration test
a) randomly (but only sometimes) causes other, unrelated tests to fail even after commenting out the added test again! (but only sometimes).
OR
b) works, if you put a breakpoint and immediately hit "resume"you might have subtle monkey business going on. Even though each test is supposed to create entirely new, non-conflicting ids (UUIDs, in fact) and only write/read its own ids.
Likely something totally unrelated. Some test which created a background thread which was still running when that test proper had ended, and then later on crashed some how, and on a totally unrelated place you get the finger shown.
-
@BernieTheBernie said in WTF Bites:
@Benjamin-Hall said in WTF Bites:
WTF of my life right now When adding an integration test
a) randomly (but only sometimes) causes other, unrelated tests to fail even after commenting out the added test again! (but only sometimes).
OR
b) works, if you put a breakpoint and immediately hit "resume"you might have subtle monkey business going on. Even though each test is supposed to create entirely new, non-conflicting ids (UUIDs, in fact) and only write/read its own ids.
Likely something totally unrelated. Some test which created a background thread which was still running when that test proper had ended, and then later on crashed some how, and on a totally unrelated place you get the finger shown.
Maybe. It's all async tests that actually create stuff in the database (because it's testing the sql repository code). Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result. Or any number of other heisenbugs.
-
@Benjamin-Hall said in WTF Bites:
Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result.
If that is possible, you have a big problem as it is the sort of fault that can crop up occasionally in production. If it is possible at all. Please let that not be the fault!
-
@Benjamin-Hall said in WTF Bites:
@BernieTheBernie said in WTF Bites:
@Benjamin-Hall said in WTF Bites:
WTF of my life right now When adding an integration test
a) randomly (but only sometimes) causes other, unrelated tests to fail even after commenting out the added test again! (but only sometimes).
OR
b) works, if you put a breakpoint and immediately hit "resume"you might have subtle monkey business going on. Even though each test is supposed to create entirely new, non-conflicting ids (UUIDs, in fact) and only write/read its own ids.
Likely something totally unrelated. Some test which created a background thread which was still running when that test proper had ended, and then later on crashed some how, and on a totally unrelated place you get the finger shown.
Maybe. It's all async tests that actually create stuff in the database (because it's testing the sql repository code). Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result. Or any number of other heisenbugs.
If you can put spies around any of the collaborators you can attach decrements for a countdown latch to those and then actually block until the threads in the test have done :allthethings:.
However! Don't do that until you've excluded @dkf's concern above.
-
@Benjamin-Hall said in WTF Bites:
Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result.
If that is possible, you have a big problem as it is the sort of fault that can crop up occasionally in production. If it is possible at all. Please let that not be the fault!
Yeah. Especially since it's just a call to a built-in library. Because even we aren't stupid enough to roll our own UUID generator.
-
@Benjamin-Hall said in WTF Bites:
@Benjamin-Hall said in WTF Bites:
Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result.
If that is possible, you have a big problem as it is the sort of fault that can crop up occasionally in production. If it is possible at all. Please let that not be the fault!
Yeah. Especially since it's just a call to a built-in library. Because even we aren't stupid enough to roll our own UUID generator.
Are you stupid enough to use an existing one incorrectly?
-
@Benjamin-Hall said in WTF Bites:
@Benjamin-Hall said in WTF Bites:
Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result.
If that is possible, you have a big problem as it is the sort of fault that can crop up occasionally in production. If it is possible at all. Please let that not be the fault!
Yeah. Especially since it's just a call to a built-in library. Because even we aren't stupid enough to roll our own UUID generator.
In any case, that sounds like a good thing to work on fixing this week. Even if it turns out that the fix is just "don't run these in parallel because the isolation is broken".
-
@Benjamin-Hall said in WTF Bites:
@Benjamin-Hall said in WTF Bites:
Could also be that the "create a unique id" thing was being called from two different threads simultaneously and gave back the same result.
If that is possible, you have a big problem as it is the sort of fault that can crop up occasionally in production. If it is possible at all. Please let that not be the fault!
Yeah. Especially since it's just a call to a built-in library. Because even we aren't stupid enough to roll our own UUID generator.
In any case, that sounds like a good thing to work on fixing this week. Even if it turns out that the fix is just "don't run these in parallel because the isolation is broken".
So. Yeah. As usual,
 is me. Turns out I'd forgotten an
is me. Turns out I'd forgotten an awaitin one of the statements in the helper functions to insert this crap into the database. So the tests were continuing before (sometimes) everything had finished inserting. Which left it in "interesting" states that weren't possible to pick up on looking at the final state of the database...because by that time all the inserts had finished.Thankfully, that's all in the test code only. Now to refactor this unmitigated mess into something more useable.
-
@Benjamin-Hall In Rust if you don't
awaitsomething, it just gets deleted without running, making async functions into effectively scoped threads. Would be helpful if other languages had that too.
-
@Benjamin-Hall In Rust if you don't
awaitsomething, it just gets deleted without running, making async functions into effectively scoped threads. Would be helpful if other languages had that too.Gooseman? Hey, long time n...


-
@Applied-Mediocrity said in WTF Bites:
@Benjamin-Hall In Rust if you don't
awaitsomething, it just gets deleted without running, making async functions into effectively scoped threads. Would be helpful if other languages had that too.Gooseman? Hey, long time n...
Hm, you know, I think this is proof that we are Maverick. We killed Goose, but then just kept flying anyway and maybe will save the world.
-
Status: Got an automated tool saying a not-my-application is using "insecure" LDAP requests. This is an app that proudly proclaims "3 layers of encryption!".

-
If you can put spies around any of the collaborators you can attach decrements for a countdown latch to those and then actually block until the threads in the test have done :allthethings:.

-
We killed Goose
Wh.. what? B... but you told me
he went to live on a farmhe asked to be banned
-

Back-end server: that operation took ~300 ms from receipt of request to time out the door.
Front-end server: Yeah, I sent it off to the backend server and got a response back in ~300 ms. And returned within that second.
Browser: Guys? That response took 7.6 seconds after you acknowledged receipt of request. And my connection is quite good (every other request was finishing within 100ms of the server-noted time, so ~50ms of latency on this particular connection).Whatever the cause, not my problem. Because all I'm tasked with is the backend stuff--no way I'm going to touch the front-end for this particular ticket. It's mucky enough already.
Edit: and yes, I did make sure that the server timestamps and front-end timestamps match so that I know I'm timing the right request/response pair.
Actually, looking more into it:
- The timestamp on the apache log entry must be the receipt time, not the response time. It matches when the browser thinks it sent the request. And is ~8s (that's the precision available in the log) before the time it said it forwarded the request to the real back-end. That's the culprit. The front end server is taking forever to do something (probably check authentication, because that's all it has to do before forwarding the request). And that's so far outside my scope I can't even see it from here.
-
@Benjamin-Hall said in WTF Bites:
The front end server is taking forever to do something (probably check authentication, because that's all it has to do before forwarding the request).
I'd guess it's something like a reverse DNS lookup. If it was around a second, auth would be a strong guess (bcrypt is bloody slow, by design) but once you're out to 8 seconds that's unlikely to be auth unless it is bouncing around a lot of servers. Like way more than I need to handle for OIDC (which comes back in under a second in our deployment, even though that's hosted elsewhere entirely). If I remember right, Apache likes doing reverse DNS yet it's almost completely useless in practice because so many places have dynamic DNS and don't register everything.
-
@Benjamin-Hall said in WTF Bites:
The front end server is taking forever to do something (probably check authentication, because that's all it has to do before forwarding the request).
I'd guess it's something like a reverse DNS lookup. If it was around a second, auth would be a strong guess (bcrypt is bloody slow, by design) but once you're out to 8 seconds that's unlikely to be auth unless it is bouncing around a lot of servers. Like way more than I need to handle for OIDC (which comes back in under a second in our deployment, even though that's hosted elsewhere entirely). If I remember right, Apache likes doing reverse DNS yet it's almost completely useless in practice because so many places have dynamic DNS and don't register everything.
Knowing how our auth system
 works , I'm suspecting a table deadlock mess in looking up the cookie values. I'm not sure what it would be reverse-DNS looking up. And it only happens occasionally--most responses are (at that stage) effectively instant. Could also be trying to renew the login cookie or something stupid.
works , I'm suspecting a table deadlock mess in looking up the cookie values. I'm not sure what it would be reverse-DNS looking up. And it only happens occasionally--most responses are (at that stage) effectively instant. Could also be trying to renew the login cookie or something stupid.Our auth system is...bad. Like, mega ultra bad. Both security-wise AND basic functionality wise. Thankfully that's someone else's mess to handle.
-
@Benjamin-Hall said in WTF Bites:
Knowing how our auth system
works , I'm suspecting a table deadlock mess in looking up the cookie values. I'm not sure what it would be reverse-DNS looking up. And it only happens occasionally--most responses are (at that stage) effectively instant. Could also be trying to renew the login cookie or something stupid.Someone's hold long transactions against the server side part of the cookie store? That'd be weird and stupid. It would require someone to go really quite far out of their way to make things bad for it to be a candidate.
Reverse DNS is, OTOH, well known to be slow when there's no entry for the IP address you're looking up. Yes, your local nameserver will cache things for you for a while, but those caches aren't kept all that long. What would Apache be looking up? Oh, just the name for every IP address of every incoming connection, probably just so that it can use the name in the log (or in case it wants to pass it to a CGI script or other such numbnuts thing).
 Apache httpd won't stop doing reverse DNS requests for clients' IPs
Apache httpd won't stop doing reverse DNS requests for clients' IPs

Obviously my Apache httpd instance is doing reverse DNS (RDNS, give me the hostname for this IP address) lookups for each incoming client connection's IP address. This is bad. Especially since some...
I'm not say that's it, but it sure smells like it might be.
-
Apache httpd
… should be indented five feet down and covered with dirt. I haven't seen good reason to use that moloch for at least 15 years.
Filed under: so of course I just recently kicked one out of the project where it was serving just plain static files
-
I haven't seen good reason to use that moloch for at least 15 years.
That's about the last time I used it. Actually, I think I was still using it up until about 12 years ago (the last time I had any web server of my own), but it's probably been over 15 since I last set up or configured any web server.
-
@Benjamin-Hall said in WTF Bites:
Knowing how our auth system
works , I'm suspecting a table deadlock mess in looking up the cookie values. I'm not sure what it would be reverse-DNS looking up. And it only happens occasionally--most responses are (at that stage) effectively instant. Could also be trying to renew the login cookie or something stupid.Someone's hold long transactions against the server side part of the cookie store? That'd be weird and stupid. It would require someone to go really quite far out of their way to make things bad for it to be a candidate.
Reverse DNS is, OTOH, well known to be slow when there's no entry for the IP address you're looking up. Yes, your local nameserver will cache things for you for a while, but those caches aren't kept all that long. What would Apache be looking up? Oh, just the name for every IP address of every incoming connection, probably just so that it can use the name in the log (or in case it wants to pass it to a CGI script or other such numbnuts thing).
Apache httpd won't stop doing reverse DNS requests for clients' IPs
Obviously my Apache httpd instance is doing reverse DNS (RDNS, give me the hostname for this IP address) lookups for each incoming client connection's IP address. This is bad. Especially since some...
I'm not say that's it, but it sure smells like it might be.
Interesting. But why would it only happen for one request out of dozens, sporadically?
The reason I'm pointing my finger at the auth process is that there are a few steps (remember,
 homebrew system) involving looking up a bunch of data. And if it needs to refresh the authentication, it may need to look up the same information from two different places. We've had deadlocks causing issues there before. And there are patches in place, but again, homebrew system. It's not simply doing an hash password -> lookup value -> reject/accept loop.
homebrew system) involving looking up a bunch of data. And if it needs to refresh the authentication, it may need to look up the same information from two different places. We've had deadlocks causing issues there before. And there are patches in place, but again, homebrew system. It's not simply doing an hash password -> lookup value -> reject/accept loop.
-
@Benjamin-Hall said in WTF Bites:
But why would it only happen for one request out of dozens, sporadically?
… because the (negative) DNS resolver cache just expired?
-
@Zerosquare said in WTF Bites:
We killed Goose
Wh.. what? B... but you told me
he went to live on a farmhe asked to be bannedHow do you think we do bans?
-
@Benjamin-Hall said in WTF Bites:
Interesting. But why would it only happen for one request out of dozens, sporadically?
There are whole layers of complex caches in there!
The reason I'm pointing my finger at the auth process is that there are a few steps (remember,
homebrew system) involving looking up a bunch of data. And if it needs to refresh the authentication, it may need to look up the same information from two different places. We've had deadlocks causing issues there before. And there are patches in place, but again, homebrew system. It's not simply doing an hash password -> lookup value -> reject/accept loop.Well, if it is the auth then you should see it in the database lock patterns. You should be able to see those from the DB side of things.
The reason why I doubt it is the auth is because I just don't think it'll go to 8 seconds (unless it has totally deadlocked, but then you should either see lock failures in your logs or be able to catch the system deadlocked). DNS failures instead look a lot like what you describe, including the weird sporadic nature, and they're known to be too easy to induce in Apache.
-
@Benjamin-Hall said in WTF Bites:
Interesting. But why would it only happen for one request out of dozens, sporadically?
There are whole layers of complex caches in there!
The reason I'm pointing my finger at the auth process is that there are a few steps (remember,
homebrew system) involving looking up a bunch of data. And if it needs to refresh the authentication, it may need to look up the same information from two different places. We've had deadlocks causing issues there before. And there are patches in place, but again, homebrew system. It's not simply doing an hash password -> lookup value -> reject/accept loop.Well, if it is the auth then you should see it in the database lock patterns. You should be able to see those from the DB side of things.
The reason why I doubt it is the auth is because I just don't think it'll go to 8 seconds (unless it has totally deadlocked, but then you should either see lock failures in your logs or be able to catch the system deadlocked). DNS failures instead look a lot like what you describe, including the weird sporadic nature, and they're known to be too easy to induce in Apache.
Yeah. That's what I'm thinking at this point as I dig in. It seems that the primary source of those reverse DNS lookups is,
as it seems, the default logging parameters. I can't find anywhere we're performing them manually, but logging in Apache with %h(log hostname, which is on by default) does the lookup. Supposedly turning it to%a(which logs the requester's ip instead, which for other reasons will always resolve to the load balancers or the reverse-proxy in front of that server and so probably should just be omitted entirely as log noise) prevents that.
-
is 50 grams, dried... how???
-
@Benjamin-Hall Doing some timing. Seeing huge swings across results:
Every 5th request (for basically the same data) takes ~3x as long as the others, with all of that difference concentrated in two places. Note: these are in the 1-2 second pathologically (300-500 ms normally) range, not the really high 7-8 second range earlier.- doing the initial auth stuff (which includes, for reasons, starting a transaction that will run until the entire process finishes and the request returns). Normally this takes ~30-40 ms. Pathologically, this takes as much as 900 ms.
- Unexplained time (which could be time to do imports, because PHP doesn't like it if those aren't first and also includes network latency and any reverse-dns lookups). Knowing history, network latency is ~40-70 ms each way. This total "unexplained" bucket varies from 87 ms to 854 ms. And doesn't vary nicely with the other one, although if the first is low the second is generally fairly low, in the 200ms range.
- doing the initial auth stuff (which includes, for
-
@Benjamin-Hall Which leaves another 6 seconds unaccounted for.
-
@dkf I noted that these were for total request times in the 1.5 to 2 second range. I don't have any timing on the longer ones, since they haven't happened in this timing branch so far.
-
@Applied-Mediocrity said in WTF Bites:
@Polygeekery `E_NO_REPRO`I bet the kicker was that topipic where he recently out-@remi-ed @remi. I didn't think it was possible.
 quote chains is one thing, but that one was probably like that Meshuggah thing - 5 minutes of non-stop dakka, but on the keyboard.
quote chains is one thing, but that one was probably like that Meshuggah thing - 5 minutes of non-stop dakka, but on the keyboard.You talking about me or someone else that acted more French than the Frenchman? Or someone else?
-
AccuWeather is less accurate every day. It used to be that they were right on the money most of the time but lately......not so much. Like just now it has been raining for 5-10 minutes and I check to see when it is supposed to end.
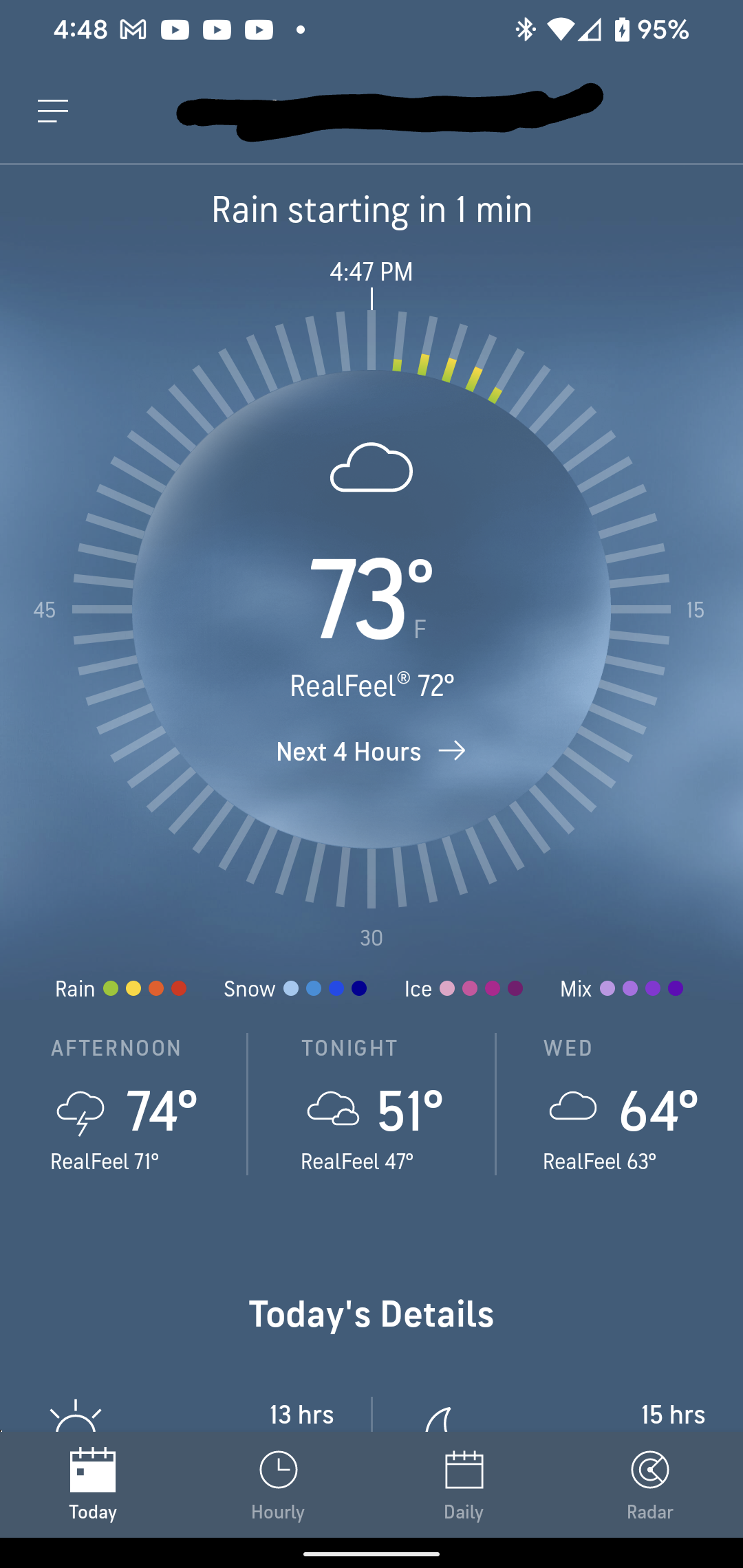
So that's of less than useful utility.
-
@Benjamin-Hall For comparison, there are a few things that are slow in the service I've been working on recently, but they're mostly under tight control. The main things left are running crypt, checking with the OIDC service (both of which are at most once per session) and compiling the page renderers (once per page per run of the service) because I've not been able to find a working way to do that during my build. (I compile the pages during the build to check for errors, but the runtime engine ignores the result.)
Both of those general categories are either limited to when people log in (when I get the evidence to upgrade the session type) or are not going to be big problems in practice (because I shouldn't be launching the process frequently). None of them involve a database lock; I made sure that every transaction is short (and measured them to be sure). The biggest problem I had was with the driver for the DB starting transactions when it shouldn't, and which was
 the "best" kind of correct (but really not what I wanted due to the subtleties of other things going on). All works now, of course. But I digress. The point is know your delays, know where they come from, and know how often they bite.
the "best" kind of correct (but really not what I wanted due to the subtleties of other things going on). All works now, of course. But I digress. The point is know your delays, know where they come from, and know how often they bite.
-
@Polygeekery said in WTF Bites:
You talking about me or someone else that acted more French than the Frenchman? Or someone else?
Yes.
It did seem like lots of scrolling past on my tiny old phone. Five inches don't do the job these days

-
-
The point is know your delays, know where they come from, and know how often they bite.
Yeah. That's what I'm trying to figure out right now.
lots of details
So I've done more instrumentation around the hot spots.Defined 4 basic categories per request:
- Includes (this being PHP, no compilation is involved)
- "API startup" (this includes the piece that sets up the db connection. Not sure yet if it actually opens one.
- Auth/session start
- The actual operation
- unexplained/latency
The last two are quite consistent and small (averaging 10 and 43 ms). The first two....
- Includes takes anywhere from 23 ms to 3115 ms. Mostly in the shorter end (out of 7 runs, 5 were under 60 ms, then 60, then 3115 ms).
- API startup takes anywhere from 15 ms to 2462 ms. With 3 at under 40ms and 4 at over 1.6 seconds.
- latency is relatively constant. That's also the reverse-DNS timing.
So guessing it is grabbing a DB connection...and taking forever to do so.
-
@Polygeekery said in WTF Bites:
someone else that acted more French than the Frenchman
There's Quebecoiş in here? Ye gods, @boomzilla, first you're letting the Irish in, and now this.
-
@Polygeekery I got a "Rain to end" status with no time lately, and am still kinda worried.
-
@Applied-Mediocrity said in WTF Bites:
It did seem like lots of scrolling past on my tiny old phone. Five inches don't do the job these days
Under normal circumstances I would say that I know those feels, but in this case I don't.
-
@Benjamin-Hall As expected, it was in instantiating the db access class, which does open a connection. Which aren't pooled (from what I can tell). Although the slowdown also could be opening a TCP socket for something that's used...about never from what I can tell. And certainly doesn't belong in that class and shouldn't be instantiated/opened for every request (since only about 1% of workflows touch it, let alone 1% of traffic). This whole process can take 10ms...or 6000ms.
The other weird thing is that sometimes just doing the includes/requires can take 30ms...or 7000 ms. That's probably I/O, although I'm not confident enough with how containers work to say if it's really reading from disk or from a memory-based filesystem at that point.
-
@Benjamin-Hall said in WTF Bites:
I'm not confident enough with how containers work to say if it's really reading from disk or from a memory-based filesystem at that point.
Containers, as long as speaking about the usual Linux runc runtime, simply store the layers somewhere in
/var/liband then tell the kernel to combine them with overlayfs. So whatever the base filesystem is, that's where they are.But there shouldn't be much difference between disk and memory-based. If you had swap, there should even be none, because memory files will be offloaded to swap when not in use and the memory used for caching the things that are in use instead – but kubernetes nodes usually don't have swap, apparently because the authors of it didn't understand how it works.
Either way, 7000 ms latency sounds too much even for a local disk. Could it be actually stored on a network filesystem?
-
@Benjamin-Hall said in WTF Bites:
As expected, it was in instantiating the db access class, which does open a connection. Which aren't pooled (from what I can tell). Although the slowdown also could be opening a TCP socket for something that's used...about never from what I can tell. And certainly doesn't belong in that class and shouldn't be instantiated/opened for every request (since only about 1% of workflows touch it, let alone 1% of traffic). This whole process can take 10ms...or 6000ms.
Most databases are pretty expensive to open connections to. In some cases, it spawns a new database process for the connection (which can be an incredibly variable cost thing; it depends on what else is going on on that shared resource). Pooling is a good idea in those circumstances, and is usually relatively easy to add providing you're doing your local connection delegate resource management right. No idea about the details of doing that in PHP (there are relevant-looking notes here, but I don't know how applicable they are to you).
Unless you're using SQLite. That needs a totally different connection management strategy in the first place, and connections are actually pretty cheap anyway. I don't know about the other local in-process databases. Except that Derby sucks (BTDT, don't want to go back ever) which I bet you're not using as that'd be using a
 Java DB from PHP, which would be of the day.
Java DB from PHP, which would be of the day.
-
-
Except that Derby sucks (BTDT, don't want to go back ever) which I bet you're not using as that'd be using a
Java DB from PHP, which would be of the day.We have an instance of Artifactory here. It runs on Derby. As it's grown quite big over the years, the admins fear trying to export the content to import it into something more reliable because it almost certainly won't be able to complete the dump.
-
@Benjamin-Hall said in WTF Bites:
The other weird thing is that sometimes just doing the includes/requires can take 30ms...or 7000 ms. That's probably I/O, although I'm not confident enough with how containers work to say if it's really reading from disk or from a memory-based filesystem at that point.
Back when we were investigating this for our PHP codebase, we found the include/require performance to be very consistent. Do any of the included files contain anything other than class or function definitions?
-
@Benjamin-Hall said in WTF Bites:
As expected, it was in instantiating the db access class, which does open a connection. Which aren't pooled (from what I can tell). Although the slowdown also could be opening a TCP socket for something that's used...about never from what I can tell. And certainly doesn't belong in that class and shouldn't be instantiated/opened for every request (since only about 1% of workflows touch it, let alone 1% of traffic). This whole process can take 10ms...or 6000ms.
Most databases are pretty expensive to open connections to. In some cases, it spawns a new database process for the connection (which can be an incredibly variable cost thing; it depends on what else is going on on that shared resource). Pooling is a good idea in those circumstances, and is usually relatively easy to add providing you're doing your local connection delegate resource management right. No idea about the details of doing that in PHP (there are relevant-looking notes here, but I don't know how applicable they are to you).
Actually, I've run into a similar problem recently, with a customer that uses Azure. As it turned out, creating a new connection to a postgresql hosted as Azure service takes up to 60 seconds. This is quite a problem when the connection pool is configured, by default, with 5000ms connection timeout.
It still got, somehow, 5 or so valid connections - so everything worked fine as long as only one single user used the application. Any spikes in usage (parallel requests) however tried to allocate more and failed miserably.
Edit: My guess is that the reason is TLS encryption which is enabled by default (and we haven't found any way to actually disable it, but then I just said wrapped the call with "we don't provide support of Azure infrastructure, please contact Microsoft" official statement).
-
@Kamil-Podlesak said in WTF Bites:
My guess is that the reason is TLS encryption which is enabled by default
That doesn't sound right, as in if you were talking half a second then maybe TLS would be it (this would be incredibly visible to everyone here; HTTPS is built on top of TLS) but 60 seconds is two orders of magnitude more. A 60 second delay is more in line with the cost of spinning up a new instance.
-
@Kamil-Podlesak said in WTF Bites:
As it turned out, creating a new connection to a postgresql hosted as Azure service takes up to 60 seconds.
There is a bajillion of PostgreSQL server options; do you by chance remember which one?
It sounds like it was severely undersized. You seem to end up choosing a size of the instance in all the variants. But I can also imagine that if it is an auto-scaling one, it simply takes those 60 seconds to spin up a new VM.
-
Either way, 7000 ms latency sounds too much even for a local disk.
Could be a local disk that's gone to sleep and needs to spin up.
-
@Zerosquare said in WTF Bites:
Either way, 7000 ms latency sounds too much even for a local disk.
Could be a local disk that's gone to sleep and needs to spin up.
- It's all SSDs these days.
- Even a spinning disk spins up faster than that.
- Servers would be unlikely to spin disks down anyway.

