WTF Bites
-
But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
Getting difficult, I guess I'm bound to forget something important … absolute minimum would probably be all the consonants * tone marks * diacritical vowels - 36*4*6=865 plus maybe 50 individual glyphs. We're back at my gut feeling of "lower four digits" :)
That's good. Lower four digits is much more manageable. So let's say there are like 10 more alphabets in SEA with similar properties, that's like 20k-30k characters tops. Add another 20k from CJK, and we still have about 15000 code points of head room. So we can probably fit all written languages of the world, and all the emoji (of which there are 1300 currently) within 16 bits without too much trouble. This concludes my proof that almost every difficulty in handling Unicode text is self-inflicted by the Unicode Consortium, and not inherent to text encoding in general.
Assuming they stuck to what you said was the absolute worst thing they ever did instead of addressing the complaints and adding a total of >92k CJK characters.
IIRC the official list of all Han characters prepared by the government of China has "only" 9000 characters, with 2000 in active use. AFAIK Japan and Koreas have even less than that. The other 50k-80k characters are only of interest to archeologists.
And names. Names used by Japanese and Chinese speakers often use characters that basically don't exist outside of those uses--archaic ones, ones that were niche even when they were created, etc. Since names are much more about sound and look than about meaning.
-
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe. As it stood, they had a bunch of legacy encodings to deal with together with early 1990s rendering technology and a whole lot of semi-experts on narrow fields and no way to cross-check their work (consider all the characters that were initially simply forgotten).
The need to represent what existed in the legacy encodings faithfully is a good excuse for most of these things, but not for not bringing in somebody who knows each of the scripts they were encoding really well to check they are not forgetting any important glyphs.
It happened in so many scripts that I can only conclude it's pretty fucking hard to find such an expert in the first place. How do you select one if you have very little knowledge about the field they're supposed to be the best in? There's the cultural aspect that things like "this is set in stone now and changing anything at all about it later is somewhere between impossible and a huge fucking hassle" is a very alien concept to many people who are good at the more obscure scripts. And on top of that, the intersectionality of CS and language disability was probably interesting™.
 : What do you mean, "missing"? Sure, I didn't list this character as a separate one because we generally just use that one and make a little stroke here.
: What do you mean, "missing"? Sure, I didn't list this character as a separate one because we generally just use that one and make a little stroke here.
 BUT WE SAID NO COMBINING CHARACTERS!
BUT WE SAID NO COMBINING CHARACTERS! 
Combining...???Fun fact: I'm now listed as a Unicode contributor in an area I'm not really qualified in at all, just because I seem to have been the first one who ever built an automated test and found a mistake that native speakers hadn't spotted in like 20 years.
-
@Kamil-Podlesak said in WTF Bites:
Especially on Windows, because Windows insistence on codepages was absolute shitstorm on

- Windows still supports applications that use the non-Unicode API and of course nothing has changed on those APIs since the Unicode version was introduced, so it is still as much of a shitstorm as always, one just less often gets in the area where it rages.
Especially when interacting with other platforms, it's a source of endless joy:
 Issues · microsoft/terminal
Issues · microsoft/terminal
The new Windows Terminal and the original Windows console host, all in the same place! - Issues · microsoft/terminal
-
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe. As it stood, they had a bunch of legacy encodings to deal with together with early 1990s rendering technology and a whole lot of semi-experts on narrow fields and no way to cross-check their work (consider all the characters that were initially simply forgotten).
The need to represent what existed in the legacy encodings faithfully is a good excuse for most of these things, but not for not bringing in somebody who knows each of the scripts they were encoding really well to check they are not forgetting any important glyphs.
It happened in so many scripts that I can only conclude it's pretty fucking hard to find such an expert in the first place. How do you select one if you have very little knowledge about the field they're supposed to be the best in?
You ask the top university in a given country for help. Duh.
From what I heard, the Unicode Consortium didn't even try to find any experts outside Europe and USA.
-
And now for something completely different.
User identity crisis or A/B testing gone wrong?
-
@Gąska Didn't someone else already mention they had half of the UI switched to Lithuanian? Or was it Latvian? Either way does not seem to be just you.
-
IIRC the official list of all Han characters prepared by the government of China has "only" 9000 characters, with 2000 in active use. AFAIK Japan and Koreas have even less than that. The other 50k-80k characters are only of interest to archeologists.
Well, Unicode includes Linear B since 2003 and even the older and undeciphered Linear A since 2014, so clearly they've decided that it should also include stuff that is only of interest to archeologists (and not to many of them, at that!).
I'm guessing that at some point they switched their goal from "being able to reproduce any current writing system" to "being able to reproduce any writing system"... I was going to make some half-assed
 about them not having European Middle-Ages ligatures, but actually there is apparently a project for that as well...
about them not having European Middle-Ages ligatures, but actually there is apparently a project for that as well...
-
: What do you mean, "missing"? Sure, I didn't list this character as a separate one because we generally just use that one and make a little stroke here.
BUT WE SAID NO COMBINING CHARACTERS!
Combining...???Also, there is the weird-but-not-really-surprising thing that writing evolved organically, in parallel of language itself, and doesn't necessarily lend itself well to rigid classification with unique distinct character points.
Take ancient Egyptian. If you go back far enough (say, 1000 BC), you have the nice hieroglyphs that we can see on temples and tombs. If you go back a bit less (say 1 AD) you get Demotic. Many Demotic symbols are very straightforwardly derived from hieroglyphs. In some cases one Demotic symbol represents several hieroglyphs. And we have intermediate documents from across the centuries where we can see the evolution from one to the other (since Demotic is basically just hieroglyphs being simplified as they get written faster and faster). But ultimately they end up being different symbols, you can't substitute one Demotic symbol for its hieroglyphic origin, it doesn't make sense.
So if you were to encode those into Unicode (which apparently hasn't be tried yet...) you'd need (at least) two code points for the Demotic/hieroglyphic variants of the same character, but you'd also have to decide at which point one becomes the other, which is simply not how writing evolved (basically, you'd have to discretise a continuous variable).
Another amusing example in how writing evolves are the diacritics on capital letters (e.g. É, À...). In pre-printing writing, diacritics were present on all letters, including capitals (that is, when diacritics were used, which in itself is a different story). The first printers kept it as it was part of the language. But then when e.g. typing machines came along, the need to simplify keyboards to keep everything usable (and cheap enough) for a mass-market meant that diacritics on capitals were dropped. What was first seen as a failing of the method became the norm, and by the end of the typing machine era (i.e. the end of the 20th century), typographic manuals taught that capitals didn't take diacritics! But then came computers and it again became fairly easy to produce them, and older typographic standards came back, and nowadays it's mostly seen as an error to not use diacritics on capital letters. Except... not always, there are still many documents that don't use them and it's become so ingrained that both are more or less accepted in practice.
So when it comes to a font, obviously there should be two glyphs produced in the end (whether it's by combination or any other method doesn't matter), but the interesting thing is that to faithfully reproduce the usage, you might sometimes need to use one or the other, for the same letter! (for example that means that you can't assume that
lowercase E = esince sometimes it would actually belowercase E = é || è || ê || ë!!!)I guess my conclusion is that, once more, the Real World show us that it can't be put into nice, clear and distinct mathematical categories, and that every time we try to do that, we hit edge cases where it doesn't work.
-
I'm guessing that at some point they switched their goal from "being able to reproduce any current writing system" to "being able to reproduce any writing system"...
So I just need to convince them that some people genuinely communicate (or have communicated) expressly via an ordered set of moon-like symbols that unambiguously begins with the left side being illuminated… or perhaps by ideograms of various pterosaurian genera…
-
It happened in so many scripts that I can only conclude it's pretty fucking hard to find such an expert in the first place. How do you select one if you have very little knowledge about the field they're supposed to be the best in?
As long as there are some teachers of that language that should do. The thing is rather that you need a corpus of text and encode it in the proposed encoding to verify everything is in place, and that's a lot of effort.
Well, Unicode includes Linear B since 2003 and even the older and undeciphered Linear A since 2014, so clearly they've decided that it should also include stuff that is only of interest to archeologists (and not to many of them, at that!).
And archeologists apparently give more fucks about having an encoding for the materials they study than governments and universities about having it for their official language. Because
there is apparently a project for that
The Unicode consortium themselves did a shoddy job, because the representatives of the big software vendors didn't give many fucks about languages they didn't support at the time. And since then they are basically just accepting requests for addition.
Therefore to get something included, someone interested needs to prepare the proposal. And preferably create the corpus. And it seems that writers of some languages bitch about missing this or that character and working around it with various approximations, but none of them sat down yet and wrote down the proposal to add the missing bits. Somewhat surprising when it's even official language somewhere (as is the case of some Indic scripts), but apparently is the case.
-
But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
Getting difficult, I guess I'm bound to forget something important … absolute minimum would probably be all the consonants * tone marks * diacritical vowels - 36*4*6=865 plus maybe 50 individual glyphs. We're back at my gut feeling of "lower four digits" :)
That's good. Lower four digits is much more manageable. So let's say there are like 10 more alphabets in SEA with similar properties, that's like 20k-30k characters tops. Add another 20k from CJK, and we still have about 15000 code points of head room. So we can probably fit all written languages of the world, and all the emoji (of which there are 1300 currently) within 16 bits without too much trouble. This concludes my proof that almost every difficulty in handling Unicode text is self-inflicted by the Unicode Consortium, and not inherent to text encoding in general.
Assuming they stuck to what you said was the absolute worst thing they ever did instead of addressing the complaints and adding a total of >92k CJK characters.
IIRC the official list of all Han characters prepared by the government of China has "only" 9000 characters, with 2000 in active use.
That will be the simplified ones. Add to that ~8000 traditional ones from the Big5 charset …
AFAIK Japan and Koreas have even less than that. The other 50k-80k characters are only of interest to archeologists.
Reading and reproducing something akin to say Chaucer is normally considered literature, not archaeology.
What good is a grand unified encoding scheme anyway if for some texts you have to come up with yet another (and probably multiple) variation of it?You're forgetting one thing - THEY ALREADY DID start with a blank slate and brought experts of all the world's writing systems. It's actually been done. It's been the entire point of Unicode Consortium to bring in the experts to start anew and come up with one encoding that fits all. It's just, they fucked up.
Not "drop-in and fahgeddaboutit" compatibility but at least "we have exactly that character for you so you can have a bijective mapping to your 8-bit charset and be done with providing a new load/save function instead of writing a whole new renderer and checking every single one of your string comparison and search algorithms and waiting for all your dependencies to update, too" compatibility.
Except that bijective mapping was already dependent on the legacy encoding.
Of course. The stuff that existed before. That's what people used and what had to be mapped.
There is no reason at all why 0x49 in 8859-9 has to map to the same Unicode character as 0x49 in 8859-1.
Except it being the exact same character of course.
-
For example, Pakistan, which uses Urdu alphabet, has a law that every official government document has to start with Bismillah, written in Arabic letters. And it would be quite difficult to do with Urdu keyboard, and copy-pasting is quite fragile too, so instead they somehow convinced the Unicode Consortium to include it as a standalone code point to make life easier.
Surely called a POM - a Pakistani Ordinance Marker
-
Another amusing example in how writing evolves are the diacritics on capital letters (e.g. É, À...). In pre-printing writing, diacritics were present on all letters, including capitals (that is, when diacritics were used, which in itself is a different story). The first printers kept it as it was part of the language. But then when e.g. typing machines came along, the need to simplify keyboards to keep everything usable (and cheap enough) for a mass-market meant that diacritics on capitals were dropped. What was first seen as a failing of the method became the norm, and by the end of the typing machine era (i.e. the end of the 20th century), typographic manuals taught that capitals didn't take diacritics! But then came computers and it again became fairly easy to produce them, and older typographic standards came back, and nowadays it's mostly seen as an error to not use diacritics on capital letters. Except... not always, there are still many documents that don't use them and it's become so ingrained that both are more or less accepted in practice.
Or how the letter ‘þ’ disappeared from English. It was originally used for what is now always written with the digraph ‘th’. Then it was used alternately with the digraph. But as print started, many printers bought fonts from Germany and Italy and those didn't have that letter, so it got replaced by ‘y’ or the digraph ‘th’ used until the usage settled on the digraph
thand the letter ‘þ’ was forgotten (except on Iceland).
-
On the subject of YouTube, do these assholes really automatically translate titles now?
It suggested this video:
https://www.youtube.com/watch?v=MzRCDLre1b4
As far as I can tell from the onebox, its actual title is "some light quantum mechanics". However, to me YouTube shows the video as "Etwas Licht Quantenmechanik (mit MinutePhysics)", without any hint that it's a machine-garbage-translated title. And obviously it fucks up the pun on light(simple) / light(EM wave) and translates it as Licht.
This is maximally idiotic for several reasons. I don't get to see what the real title is, I assume the video is in German when it isn't, I assume the video is by some other creator because I know this one publishes videos in English, etc.
And then I clicked on the subtitles button and it enabled Arabic subtitles. Because fuck you, that's why.
-
@sebastian-galczynski said in WTF Bites:
But the certificate store is just a collection of certificates in always the same X509 format, and their presence or absence in the system trust store has an important meaning.
Nowdays - yes. But when these APIs were designed, a typical Windows box went for years without any updates,
Fat chance they'd update Java or any user apps in the meantime. Only if they did the updates, that wouldn't automatically update the Java applications' one.
and had a bunch of trojans meddling with the system certs. It was safer to just use a separate store, along with a separate update mechanism (remember these pestering Java Update pop-ups? Or are they still there?)
I'd assume that if a trojan can meddle with the system certs it can meddle with any other cert on the system, too. Or that's how it should be in any decent system design; maybe I'm being naïve about Windows again …
-
and had a bunch of trojans meddling with the system certs. It was safer to just use a separate store, along with a separate update mechanism (remember these pestering Java Update pop-ups? Or are they still there?)
I'd assume that if a trojan can meddle with the system certs it can meddle with any other cert on the system, too. Or that's how it should be in any decent system design; maybe I'm being naïve about Windows again …
Also, if a trojan has compromised your system certs, you're probably already fucked anyway.
-
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe. As it stood, they had a bunch of legacy encodings to deal with together with early 1990s rendering technology and a whole lot of semi-experts on narrow fields and no way to cross-check their work (consider all the characters that were initially simply forgotten).
The need to represent what existed in the legacy encodings faithfully is a good excuse for most of these things, but not for not bringing in somebody who knows each of the scripts they were encoding really well to check they are not forgetting any important glyphs.
It happened in so many scripts that I can only conclude it's pretty fucking hard to find such an expert in the first place. How do you select one if you have very little knowledge about the field they're supposed to be the best in?
You ask the top university in a given country for help. Duh.
That's a good one.
From what I heard, the Unicode Consortium didn't even try to find any experts outside Europe and USA.
Too expensive, amirite? Should have done it as a UN commission

I found them more responsive to bug reports than most companies. There are still quite a few bugs considering all the top experts around the world can look at the documents and report omissions.
-
and had a bunch of trojans meddling with the system certs. It was safer to just use a separate store, along with a separate update mechanism (remember these pestering Java Update pop-ups? Or are they still there?)
I'd assume that if a trojan can meddle with the system certs it can meddle with any other cert on the system, too. Or that's how it should be in any decent system design; maybe I'm being naïve about Windows again …
Also, if a trojan has compromised your system certs, you're probably already fucked anyway.
Yeah, that's what I was aiming at. Butbutbut, Java is "write once, run anywhere", even the most trojan-ridden spam boxes!!!1
-
Trying to update the BIOS on a HP laptop: Download file. Put on USB.
File must be in directory HP/BIOS/New on USB storage."
Try again.
"Invalid BIOS file."Well, it does support updating from the internet too...
"Update found."
Update.
computer freezesAlso, why does HP distribute all their updates as self-unpacking archives (.exe) like it's still the goddamn 90s? Rrgh.
-
I'm not quite sure about Khmer but it seems to be a fairly close relative of Thai/Lao in the family of Brahmic scripts.
It is, but it has some "extras". E.g. "subscript form". Khmer is not tonal in contrast to Thai and Lao, but has terrible diphthongs/triphthongs - the pronunciation depends on something like the "high" vs. "low" series of consonants...
-
Also, why does HP distribute all their updates as self-unpacking archives (.exe) like it's still the goddamn 90s? Rrgh.
All of HP is goddamn 90s, from HP/UX all the way to their website that uses server names like www243.doc.foo.hp.com in their URLs because load balancers are new-fangled crap hipsters use.
-
I know someone named Saldana but she pronounces it Saldaña, but how do you
 someone about their own name?
someone about their own name?Like many Germans of east european origin. "ie" is a long "i" (American "ee") in German, but "ye" in Polish. Worse, "cz" is Polish for (American) "ch", some pronounce it like "k-ts". Or Hungarian Nagy (nawdzh) suddenly becomes "nah-ghee"...
-
@topspin
 here (so
here (so  macOS)
macOS)Arabic kalligraphy of a whole sentence ("in the name of God, the almighty, the merciful"). That what I consider a
- it is a whole sentence, not a single character / glyph.
-
-
I think this USB memory stick is a bit broken...
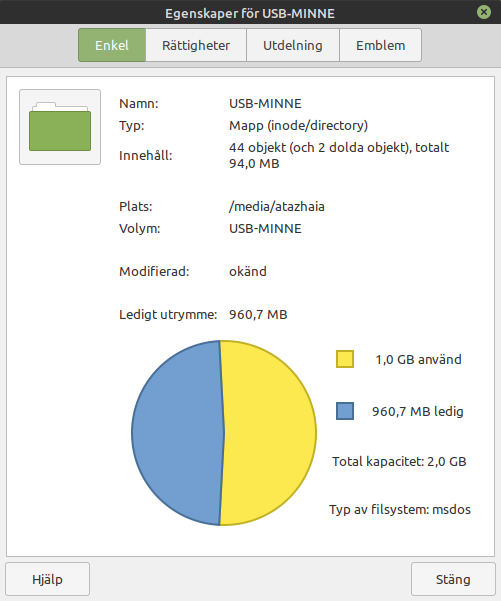
94 MB files, but 1 GB in use. Hmm...
-
Another amusing example in how writing evolves are the diacritics on capital letters (e.g. É, À...). In pre-printing writing, diacritics were present on all letters, including capitals (that is, when diacritics were used, which in itself is a different story). The first printers kept it as it was part of the language. But then when e.g. typing machines came along, the need to simplify keyboards to keep everything usable (and cheap enough) for a mass-market meant that diacritics on capitals were dropped. What was first seen as a failing of the method became the norm, and by the end of the typing machine era (i.e. the end of the 20th century), typographic manuals taught that capitals didn't take diacritics!
TIL
I suppose it's a french thing? Because languages that actually need diacritics just used dead keys on typewriters. We have an old one in my family (1920 or something) and it did does have several dead keys. Of course, using these on capital letters resulted in typographically abhorrent result - but than again, these typewriters did not actually have zero and one digits (people just used capital O and lowercase l) nor parenthesis (slashes all the way) nor underscore (just move the paper one notch and type dash).
-
@BernieTheBernie said in WTF Bites:
I'm not quite sure about Khmer but it seems to be a fairly close relative of Thai/Lao in the family of Brahmic scripts.
It is, but it has some "extras". E.g. "subscript form". Khmer is not tonal in contrast to Thai and Lao, but has terrible diphthongs/triphthongs - the pronunciation depends on something like the "high" vs. "low" series of consonants...
The high and low classes are the same in Thai and Lao. It does look a bit more complicated, I can recognize only like every other letter. And subscript forms sure are nasty. Firefox seems to have a problem with those:

When I paste it into Kitty I get something that looks closer to what I think a subscript should be.
-
-
@Tsaukpaetra are you using the MS Teams version of Zoom?

Because when I start that my fans are ready for lift-off.Funnily enough, I had a Teams call the other day, and it was going through a VPN. The picture quality was great, full resolution and everything, but it literally took 30+ seconds to update each frame, possibly with a long delay as well. But despite that, the audio came through 100% clear, without any delay.
-
94 MB files, but 1 GB in use. Hmm...
NTFS and someone created a file with an alternate file stream? (I seem to remember those don't get counted in the file size)
-
@Kamil-Podlesak said in WTF Bites:
Another amusing example in how writing evolves are the diacritics on capital letters (e.g. É, À...). In pre-printing writing, diacritics were present on all letters, including capitals (that is, when diacritics were used, which in itself is a different story). The first printers kept it as it was part of the language. But then when e.g. typing machines came along, the need to simplify keyboards to keep everything usable (and cheap enough) for a mass-market meant that diacritics on capitals were dropped. What was first seen as a failing of the method became the norm, and by the end of the typing machine era (i.e. the end of the 20th century), typographic manuals taught that capitals didn't take diacritics!
TIL
I suppose it's a french thing? Because languages that actually need diacritics just used dead keys on typewriters.
Yes, I think that it's mostly a French thing, where indeed diacritics are (mostly) not significant. I mean, they're part of the language and my name is Rémi not Remi, but there is no possible confusion (and diacritiqued letters are considered as variations of the letter (e.g. for the order in dictionary), not as separate letters). So they're not quite optional, but they can be considered as optional without making the language un-understandable.
Digression:
There still exist a few cases where the diacritic changes the meaning of the word but usually the context is enough. One such case, on which I regularly joke, is that "congress" and "congers" are written respectively "congrès" and "congres". Many town have a congress centre, sometimes called "palais des congrès" (lit. congress palace), and as it's often written in large letters on e.g. road signs, I have seen it several times written in all caps. And yes, sometimes the diacritic was missing. So it said "PALAIS DES CONGRES" and I jokingly referred to it as the "fish palace" (congers' palace).
-
@remi And then there's Russian, where the only real diacritic is
ё. Which is printed ase. Except they're very very different letters. And sometimes the only difference between words (or different cases) is that one letter, and context doesn't always disambiguate. And sometimes those meanings are very different.Russians love to claim that their language is fully phonetic. What you see is what you say. Except, well, no. It isn't. Especially when you throw in different regional dialects.
Language is weird. Mostly because it was made by people, and people are weird.
-
94 MB files, but 1 GB in use. Hmm...
NTFS and someone created a file with an alternate file stream? (I seem to remember those don't get counted in the file size)
FAT32. But considering how slow it was to read and write to the stick, random disconnect and a very long time to get it remounted I would say hardware fuxxored.
Also, I had the bad luck of getting new laptops on the HP years at work. Would be nice if my laptop refresh happened on a Dell year for a change. Essentially, they do central negotiations for each year as to who gets to supply the laptops for the company and then they are leased for 3 years after which we have the option to buy them for private use or return them, and then we get the new model for that year. If I want a different model I have to negotiate for a
 laptop which means motivating my needs which is
laptop which means motivating my needs which is  . Or say I want a MacBook. And while I love having a MacBook as a personal laptop, having one for my work is... less optimal. I very much prefer Linux there.
. Or say I want a MacBook. And while I love having a MacBook as a personal laptop, having one for my work is... less optimal. I very much prefer Linux there.
-
@Benjamin-Hall said in WTF Bites:
@remi And then there's Russian, where the only real diacritic is
ё. Which is printed ase. Except they're very very different letters. And sometimes the only difference between words (or different cases) is that one letter, and context doesn't always disambiguate. And sometimes those meanings are very different.I remember this was very confusing to me, too... until one teacher once remarked "yeah, ë is always stressed anyway, so...."
Like,
did I not learn such a useful rule in the previous 4 years learning the language?
Especially since it's obviously related to the rule "unstressed 'o' is pronunciated as 'a'"Russians love to claim that their language is fully phonetic. What you see is what you say. Except, well, no. It isn't. Especially when you throw in different regional dialects.
Well, to be honest, at least it's more phonetic than Polish or Czech (and the latter are quite prone to jump into random online discussion claiming that). German is pretty close, but AFAIK the most "phonetic" language is probably Finnish.
-
@Kamil-Podlesak I have something quite garagey to say about Estonian, but I'll refrain.
And yes, unstressed
oisa, or more properlyschwa. Except in some dialects, where they pronounceхорошоexactly as written. Most Russian dialects have 3 different sounds for those 3ocharacters, something likeKha ruh sho.
-
@Benjamin-Hall said in WTF Bites:
Most Russian dialects have 3 different sounds for those 3 o characters, something like Kha ruh sho.
4, if you count the colloquial "unvoiced" variant, t.i.,
Khra sho.
-
I feel like someone needs to post
 this isn’t funny!!, except that it’s not the funny stuff thread.
this isn’t funny!!, except that it’s not the funny stuff thread.
-
@Bulb I have it half in Catalan

-
And while I love having a MacBook as a personal laptop, having one for my work is... less optimal. I very much prefer Linux there.
Good news !
 Ubuntu is 'Completely Usable' on Apple Silicon
Ubuntu is 'Completely Usable' on Apple Silicon

Ubuntu Linux is up and running on Apple Silicon thanks to developers working at Coreillium. They now hope to upstream their work on Linux for M1.
-
@Gąska I'm incredibly interested in that fucking ghost video now..,
-
@TimeBandit How is anything Ubuntu good news? If I wanted a horrible desktop experience I'd just use Windows on my laptop!

-
On the subject of YouTube, do these assholes really automatically translate titles now?
Yes. For some time now, based on my Russian subscriptions...
-
is a bit broken...
Someone set the cluster size (or whatever) to some ungodly number? Who wants to calculate it?
NTFS
No, you can see it's "msdos" formatted. So probably fat32
Edit:

-
How is anything Ubuntu good news?
If it works with Ubuntu, it should work with the other ones soon
-
I feel like someone needs to post
this isn’t funny!!, except that it’s not the funny stuff thread.This language discussion isn't a bite!
-
Except it being the exact same character of course.
It has a different uppercase form. It may be "the same", but it absolutely isn't exactly the same. If it were, there would be no problem in treating it the same. But there is.
Half of Cyrillic alphabet is stroke-for-stroke identical to Latin alphabet, including having the same lowercase and uppercase, and yet each of them gets unique code point. If Cyrillic can do it, there's no reason why Turkish can't do it. And Turkish has more reason to do it than Cyrillic.
-

Warning, the following zero files will be overwritten!
-
There still exist a few cases where the diacritic changes the meaning of the word but usually the context is enough. One such case, on which I regularly joke, is that "congress" and "congers" are written respectively "congrès" and "congres". Many town have a congress centre, sometimes called "palais des congrès" (lit. congress palace), and as it's often written in large letters on e.g. road signs, I have seen it several times written in all caps. And yes, sometimes the diacritic was missing. So it said "PALAIS DES CONGRES" and I jokingly referred to it as the "fish palace" (congers' palace).
Lot's of fishy stuff takes place in Congress.

-
@TimeBandit said in WTF Bites:
Ubuntu ... 'Completely Usable'
Note the scare quotes around "completely usable".
-
@HardwareGeek said in WTF Bites:
@TimeBandit said in WTF Bites:
Ubuntu ... 'Completely Usable'
Note the scare quotes around "completely usable".
The scare quotes stand for: completely usable (graphics emulated in software rendering)
 Khmer script - Wikipedia
Khmer script - Wikipedia
