WTF Bites
-
@error okay but how does that make some letters more equal than others? That's the part I don't get.
Depends on the numbers of legs.
-
@LaoC if you had to guess, without any form of character composition, how many distinct glyphs would be needed for the entirety of Lao language?
-
The Latin script works a bit differently when writing Turkish than it works when writing other languages. Turkish has I/ı and İ/i unlike all other languages written in Latin script that have I/i. It is really similar problem to how the Hanzi script works a bit differently when adopted by Japanese as Kanji. You can then try to encode the look of the letters or some kind of their identity and either way you complicate something.
Unicode already has separate code points for a and а. Why not make Turkish I and i separate code points as well? But noooooo, that would be too easy, better change the fundamental property of uppercase-lowercase relationship and make it locale dependent! That's so much easier and fixes so many problems we didn't even know we had! God fucking dammit. Sometimes Unicode Consortium makes weird decisions. But sometimes they seem to turn off their thinking entirely. Seriously, what were they smoking when they decided on this solution? And it only saves two code points! Two code points, when there are now thousands allocated to various shades of poo!
I did say they are totally inconsistent about how and what they are trying to encode.
Even this is probably for histerical raisins though. Whatever legacy encoding was used for Turkish before probably only coded the other two variants of i and Unicode started with piling all the characters from all the legacy encodings on one heap in the interest of easier transformation.
-
Filed under: I'm changing my username to IıİilIıİilIıİilIıİilIıİilIıİilIıİil
"Barcodes" (i.e., usenames consisting solely of |Il) are a thing among some players, to avoid being easily identified. Of course, that only really works if there's more than one person doing it.
-
@HardwareGeek said in WTF Bites:
A few decades ago, there was a diet fad of "pre-digested liquid proteins" (basically, bottles of mixed amino acids). IIRC, it ended when people started dying of liver or kidney damage, or something like that.
Status: concerned about my amino acid supplement intake

Edit: that stuff appears to still be on the market. Source for the liver and kidney damage?
Sorry, no source, just my memory of something that happened 40+ years ago. I think it was only a real problem when people were so into the fad that their entire diet consisted of liquid protein; probably not a problem as a supplement, but IANAD.
-
I actually recognize Ñ as a distinct letter and it bugs me when people use N in its place.
So do Spanish speakers. There are only a handful of words than begin with Ñ, but they are listed separately in the dictionary, between N and O.
Also, I'd almost swear than when I took high school Spanish decades ago, ch was alphabetized separately from c, but it's not in the dictionary I currently have, so
 .
.
-
@boomzilla said in WTF Bites:
I don't have to reauthenticate more than once or twice a week.
I only have to reauthenticate when our VPN server hiccups. Or my WiFi hiccups. And if the hiccup is short enough, it may reconnect automatically. So, sometimes more than a week; sometimes two or three times a day, depending on the phase of the moon, the alignment between Mercury and Uranus, and how hard it's raining. And whether the reauthentication is successful seems to depend on whether I blindly accept the invalid certificate, or verify that it is the right invalid certificate before accepting it.
-
@HardwareGeek said in WTF Bites:
I actually recognize Ñ as a distinct letter and it bugs me when people use N in its place.
So do Spanish speakers. There are only a handful of words than begin with Ñ, but they are listed separately in the dictionary, between N and O.
Also, I'd almost swear than when I took high school Spanish decades ago, ch was alphabetized separately from c, but it's not in the dictionary I currently have, so
.I don't recall
chbeing like that but I do recallll(two Ls) having its own entry in the alphabet.
-
@boomzilla Maybe that's what I was thinking of, but my current dictionary doesn't alphabetize either
chorllseparately. I do remember that bothchandllhave distinct names when reciting the alphabet: a be ce che de ... ka ele elle eme ene eñe o ...According to https://www.spanish411.net/Spanish-Alphabet.asp,
Ask several Spanish-speakers how many letters there are in the alphabet and you'll get several different answers (with or without a song). Not everyone in the Spanish-speaking world agrees on what the alphabet looks like. For many years this was the official Spanish alphabet:
a, b, c, ch, d, e, f, g, h, i, j, k, l, ll, m, n, ñ, o, p, q, r, s, t, u, v, w, x, y, z
So in older Spanish dictionaries words beginning with "ch" are listed in a separate section after the rest of the "c" words, and words beginning with "ll" are listed after the rest of the "l" words. However, in 2010 the Real Academia Española, which is basically in charge of the official Spanish language, decided that "ch" and "ll" should no longer be considered distinct letters. This leaves us with a 27-letter alphabet:
a, b, c, d, e, f, g, h, i, j, k, l, m, n, ñ, o, p, q, r, s, t, u, v, w, x, y, z
To confuse the issue, some Spanish-language sources consider "rr" a separate letter and others don't count the "k" or the "w" since they almost always appear in words that originated outside of the Spanish language.
So how many letters are there? Officially there are 27, but you may find answers anywhere between 25 ("ñ," but no "k" or "w") and 30 (the 26 you're used to plus "ch," "ll," "ñ," and "rr.")
So, my memory of what I learned in high school is correct, but the alphabet officially changed since then. My dictionary incorporates the 2010 changes, even though it is from 2001.
-
I know someone named Saldana but she pronounces it Saldaña, but how do you
 someone about their own name?
someone about their own name?
Filed under: It's not her maiden name. She's white as snow.
-
@error
Pff lucky basters I wish I had 24h. I have 3h. Making it brake in the middle of a remote to a client or a connection with a fat lob app that hangs when the connection drops more then likely.
To boot the "keep connected" pop-up seems to give you 5sec to reply with your 2fa token. It's a miracle if it succeeds.
-
-
I know someone named Saldana but she pronounces it Saldaña, but how do you
someone about their own name?Many people who immigrated to USA had to change their legal names so they only contain basic Latin (often they change the name completely to the English counterpart, but that's much less common nowadays than it was a few generations ago, back when Americans were still very racist). But that's only their legal name - they still use their real name in daily life, both pronunciation and spelling (when they can). Moreover, first-generation immigrants often give their kids the names from their country of origin, repeating the pattern of legal spelling not matching pronunciation. But because the children haven't been raised in those countries, their legal names feel very real to them and don't get what their parents are talking about. So their identity is the anglicized spelling but original pronunciation.
I'm not saying that's the case with Saldana, but that might be the case with Saldana.
Edit:
Filed under: It's not her maiden name.
Oh okay, nevermind.
She's white as snow.
In other news, Spain doesn't exist.
-
:sigh:
-
She's white as snow.
In other news, Spain doesn't exist.
 I don't just mean her skin. She was born and raised here; so were her parents.
I don't just mean her skin. She was born and raised here; so were her parents.
-
@error so white people only exist in USA. Even if you don't mean skin color but something else, it still doesn't make sense.
-
@error so white people only exist in USA. Even if you don't mean skin color but something else, it still doesn't make sense.
Generally ethnicity is more defined by your familial heritage rather than your skin tone, though "white" is used colloquially in both ways. People of Spanish descent are generally considered... Spanish. White pretty much means Anglo.
-
@error yes, yes, yes, no, and please for the love of God don't mix up Spanish with Hispanic. Spanish are absolutely white, just like Italians and other Europeans with above average melanin content. Not to mention other white ethnic groups that have nothing to do with English, like me.
-
I'm gonna ask for a jeffing I think...
-
Filed under: I'm changing my username to IıİilIıİilIıİilIıİilIıİilIıİilIıİil
Makes me think of an equalizer...
-
Also different in English, but röckdöts aren't a great use to start with
I’ve never seen it elsewhere, but Raymond Chen uses it as diaeresis, e.g. coördinate. Which is funny, because I read it as an umlaut, realize what he means, then go on reading it as an umlaut anyway.
But then I also read röckdöts as umlauts.
-
I know someone named Saldana but she pronounces it Saldaña, but how do you
someone about their own name?So I'm not the only one.

-
-
But then I also read röckdöts as umlauts.
Same. Also "coördinate" sounds fucking stupid.
-
@error yes, yes, yes, no, and please for the love of God don't mix up Spanish with Hispanic. Spanish are absolutely white, just like Italians and other Europeans with above average melanin content. Not to mention other white ethnic groups that have nothing to do with English, like me.
OK fine, we'll forget ethnicity. The lady in question also says habañero, which is objectively wrong.
-
-
-
-
-
-
@TimeBandit said in WTF Bites:
White pretty much means Anglo.

Signed:

Co-signed:

Notarized:

-
@LaoC if you had to guess, without any form of character composition, how many distinct glyphs would be needed for the entirety of Lao language?
Off the top of my head I'd have said something in the lower four digits, but it looks worse if you make a rough calculation: there are 36 consonants and consonant combinations, and 37 vowel/diphthong signs, four tone marks, and one "cancellation mark" that says something like "I know this syllable is broken but it's a loan word so that's OK". A syllable can have all of these plus one of three end consonants. That's 36*37*5*2*4=53280 possible syllables (the last factors are not 4*1*3 because they're optional so one extra null element). You wouldn't have to add well-formed syllables with a cancellation mark so it would be just™ 26640, but then you'd need a whole bunch of malformed ones with it, so somewhere between these two numbers.
You could probably bring it down by cheating a bit with some of the a and e vowels that basically sit next to the rest and don't get any diacriticals added above or below so they can be linearly combined like Latin, but it would make the character selection algorithm even worse. With syllables as short as ຕີ or as long as ເອື້ອຢ you'd be hard pressed to make it look acceptable even with Unicode's half/full width forms though.
-
But then I also read röckdöts as umlauts.
Same. Also "coördinate" sounds fucking stupid.
 As English doesn't have umlauts, it's sounds exactly the way it's supposed to, /o-o:/ and not /u:/.
As English doesn't have umlauts, it's sounds exactly the way it's supposed to, /o-o:/ and not /u:/.
-
@LaoC interesting. That's way more complicated than I anticipated and 65000 may really be not enough. That said, I can't help but notice...
ເອື້ອຢ
...is clearly four distinct glyphs. Perhaps it's cultural difference in how we perceive words and letters. Or maybe it's Unicode or my browser's renderer that's deficient and it's supposed to be more blended together. But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
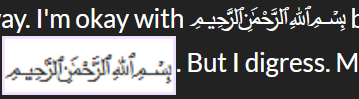
Also, I didn't mean we should've made all glyphs the same size. This is clearly absurd and character width isn't something that text encoding should deal with anyway. I'm okay with ﷽ being as long as it is and I don't understand why my browser renders it here as
 . It's supposed to be
. It's supposed to be  . But I digress. My point is that Unicode made many things needlessly complicated and near-arbitrary character/accent composition is one of them.
. But I digress. My point is that Unicode made many things needlessly complicated and near-arbitrary character/accent composition is one of them.
-
@TimeBandit said in WTF Bites:
White pretty much means Anglo.
Signed:
Co-signed:
Tangential:

-
@LaoC interesting. That's way more complicated than I anticipated and 65000 may really be not enough. That said, I can't help but notice...
ເອື້ອຢ
...is clearly four distinct glyphs. Perhaps it's cultural difference in how we perceive words and letters. Or maybe it's Unicode or my browser's renderer that's deficient and it's supposed to be more blended together.
No, the rendering is most likely fine; the stacking of upper vowel and tone mark usually looks crappy but I haven't seen worse rendering breakage anywhere in a long time. And you're right - the first ເ is the e I mentioned as a possibility to "cheat" because it never gets any diacriticals, but I forgot a few possibilities on top of e and a, the ອ and ຢ there would work as well.
But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
Getting difficult, I guess I'm bound to forget something important … absolute minimum would probably be all the consonants * tone marks * diacritical vowels - 36*4*6=865 plus maybe 50 individual glyphs. We're back at my gut feeling of "lower four digits" :)
Also, I didn't mean we should've made all glyphs the same size. This is clearly absurd and character width isn't something that text encoding should deal with anyway. I'm okay with ﷽ being as long as it is and I don't understand why my browser renders it here as
. It's supposed to be .It looks like a pretty good approximation for a semitransparent pile of poo here.
But I digress. My point is that Unicode made many things needlessly complicated and near-arbitrary character/accent composition is one of them.
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe. As it stood, they had a bunch of legacy encodings to deal with together with early 1990s rendering technology and a whole lot of semi-experts on narrow fields and no way to cross-check their work (consider all the characters that were initially simply forgotten).
-
@Tsaukpaetra said in WTF Bites:
@TimeBandit said in WTF Bites:
White pretty much means Anglo.
Signed:
Co-signed:
Notarized:
Cursed:

-
But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
Getting difficult, I guess I'm bound to forget something important … absolute minimum would probably be all the consonants * tone marks * diacritical vowels - 36*4*6=865 plus maybe 50 individual glyphs. We're back at my gut feeling of "lower four digits" :)
That's good. Lower four digits is much more manageable. So let's say there are like 10 more alphabets in SEA with similar properties, that's like 20k-30k characters tops. Add another 20k from CJK, and we still have about 15000 code points of head room. So we can probably fit all written languages of the world, and all the emoji (of which there are 1300 currently) within 16 bits without too much trouble. This concludes my proof that almost every difficulty in handling Unicode text is self-inflicted by the Unicode Consortium, and not inherent to text encoding in general.
Also, I didn't mean we should've made all glyphs the same size. This is clearly absurd and character width isn't something that text encoding should deal with anyway. I'm okay with ﷽ being as long as it is and I don't understand why my browser renders it here as
. It's supposed to be .It looks like a pretty good approximation for a semitransparent pile of poo here.
Politics go you know where

But I digress. My point is that Unicode made many things needlessly complicated and near-arbitrary character/accent composition is one of them.
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe.
You're forgetting one thing - THEY ALREADY DID start with a blank slate and brought experts of all the world's writing systems. It's actually been done. It's been the entire point of Unicode Consortium to bring in the experts to start anew and come up with one encoding that fits all. It's just, they fucked up.
-
She was born and raised here; so were her parents.
But if it's not her maiden name, why does that matter?
Doesn't that mean she got the name from their spouse?Or do you mean, it's not her last name?
-
Also different in English, but röckdöts aren't a great use
In my mind, this always sounds like “rerkderts.” I’ve probably said it out loud, too.
fake edit: psuedo-
 d by topspin
d by topspin
-
@Gąska it looks like your squigglies got all messed up:

-
@topspin
 here (so
here (so  macOS)
macOS)
-
@dkf so that makes 4 different renderings of the same text that don't look remotely alike.
-
Hah! Suck it.

Zoom, enhance:
Filed under: but why are the colors inverted?
-
@topspin @dkf Since it's just one code-point and that different fonts (rendering systems?) can draw whatever they want as long as it matches the description, this is not really surprising.
It could equally well look like any of those pictures.



etc.
etc.(btw, this means I think @Gąska is wrong when he says that "it's supposed to be [like this]"... it's about as wrong as saying that U+0041 should not look like this:
 )
)
-
@Zecc On the other hand:

Nice job rendering differently in two places, Firefox.
@topspin @dkf Since it's just one code-point and that different fonts (rendering systems?) can draw whatever they want as long as it matches the description, this is not really surprising.
Alrighty then.
-
But anyway, let me rephrase the question. How many glyphs would be needed if the only form of composition was horizontal concatenation?
Getting difficult, I guess I'm bound to forget something important … absolute minimum would probably be all the consonants * tone marks * diacritical vowels - 36*4*6=865 plus maybe 50 individual glyphs. We're back at my gut feeling of "lower four digits" :)
That's good. Lower four digits is much more manageable. So let's say there are like 10 more alphabets in SEA with similar properties, that's like 20k-30k characters tops. Add another 20k from CJK, and we still have about 15000 code points of head room. So we can probably fit all written languages of the world, and all the emoji (of which there are 1300 currently) within 16 bits without too much trouble. This concludes my proof that almost every difficulty in handling Unicode text is self-inflicted by the Unicode Consortium, and not inherent to text encoding in general.
Assuming they stuck to what you said was the absolute worst thing they ever did instead of addressing the complaints and adding a total of >92k CJK characters.
Also, I didn't mean we should've made all glyphs the same size. This is clearly absurd and character width isn't something that text encoding should deal with anyway. I'm okay with ﷽ being as long as it is and I don't understand why my browser renders it here as
. It's supposed to be .It looks like a pretty good approximation for a semitransparent pile of poo here.
Politics go you know where
In …
renderer.cc, amirite?But I digress. My point is that Unicode made many things needlessly complicated and near-arbitrary character/accent composition is one of them.
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe.
You're forgetting one thing - THEY ALREADY DID start with a blank slate and brought experts of all the world's writing systems. It's actually been done. It's been the entire point of Unicode Consortium to bring in the experts to start anew and come up with one encoding that fits all. It's just, they fucked up.
Not "drop-in and fahgeddaboutit" compatibility but at least "we have exactly that character for you so you can have a bijective mapping to your 8-bit charset and be done with providing a new load/save function instead of writing a whole new renderer and checking every single one of your string comparison and search algorithms and waiting for all your dependencies to update, too" compatibility.
-
Also different in English, but röckdöts aren't a great use
In my mind, this always sounds like “rerkderts.” I’ve probably said it out loud, too.
Öhmagöd, nöw ah sö öt!
-
Work VPN forces you to reconnect every 24 hours, exactly. A bit annoying, but logical right?
Except that, because it's exactly 24 hours, it always kicks me off the minute work officially starts, and I have to go through the 2FA song and dance.
Reconnect at the end of the day, then it will be a reminder that it's time to log off
-
I'm just arguing against the "needlessly". If they could have started with a blank slate and brought in some experts with a reeeeally broad overview over all the world's writing systems who could have considered all the pros and cons at once, then maybe. As it stood, they had a bunch of legacy encodings to deal with together with early 1990s rendering technology and a whole lot of semi-experts on narrow fields and no way to cross-check their work (consider all the characters that were initially simply forgotten).
The need to represent what existed in the legacy encodings faithfully is a good excuse for most of these things, but not for not bringing in somebody who knows each of the scripts they were encoding really well to check they are not forgetting any important glyphs.


