WTF Bites
-
@Gąska On the contrary, I'd be surprised if any system anywhere somehow managed to avoid "garbage in, garbage out"
That's literally what unique constraint on primary key is meant to prevent.
-
@Gąska On the contrary, I'd be surprised if any system anywhere somehow managed to avoid "garbage in, garbage out"
För the last 8 or so years, I've had people unironically suggest having AI to fix bad and missing data, because AI is magic, in every project I've worked on.
Mr Babbage would like a word with them.
-
I bet they made them proper simple, non-composite primary keys, though.
I am not really sure they are primary or secondary keys; there is always the UUID and there is the resource name and you use the resource name as key most of the time, but can use the UUID too.
-
@Bulb wait we're still talking about SQL right?
-
@Gąska How many times did this bite Microsoft in the arse? Because they have everything keyed with UUIDs (they are calling them GUIDs, but that's just their naming deviation) and they do generally assume they are unique across all tables and not-exactly-tables.
I bet they made them proper simple, non-composite primary keys, though.
And if Linux repo had SHA1 collisions with real consequences, I don't believe MS didn't have GUID collisions - especially since GUID is significantly shorter than SHA1.
The probability of a memory corruption of a GUID is 1015 times higher than a collision of an algorithm 4 GUID.
-
@Gąska I have no idea what the storage underlying all of Microsoft infrastructure is. It might be a NonR-DBMS, RDBMS or some ungodly mix of both.
-
The probability of a memory corruption of a GUID is 1015 times higher than a collision of an algorithm 4 GUID.
I think this is conditional probability, based on assumption that P(UUID implementation is correct, bug-free)==1
What is the real value?
-
Azure is really being really helpful today. It's user-friendly like a hedgehog in the arse.
$ az resource list --tag environment=somename
you cannot use '--tag' with '--resource-group'(If the default value for resource group is set, please use 'az configure --defaults group=""' command to clear it first)Yes, of course I do have default group set, because all the other commands I need require it. And I only want the resources from that group anyway, just filtered by the tag (not like I had access to any other group anyway).
-
@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
Also - birthday problem. The probability of collision is much, much higher than Raymond's 2-122. As I said, the official Linux Git repo has actually suffered from the even more unlikely collision of 160-bit SHA1's.
-
@Gąska On the contrary, I'd be surprised if any system anywhere somehow managed to avoid "garbage in, garbage out"
That's literally what unique constraint on primary key is meant to prevent.
At this point I have no idea what it is you are talking about†, but I'm quickly coming to realize I really don't care enough about this discussion to keep it going.
† I was talking about there being an "undocumented assumption that all UUIDs are unique" everywhere; so if this assumption is broken, everything breaks, natch.
-
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
-
@Gąska How many times did this bite Microsoft in the arse? Because they have everything keyed with UUIDs (they are calling them GUIDs, but that's just their naming deviation) and they do generally assume they are unique across all tables and not-exactly-tables.
I bet they made them proper simple, non-composite primary keys, though.
And if Linux repo had SHA1 collisions with real consequences, I don't believe MS didn't have GUID collisions - especially since GUID is significantly shorter than SHA1.
The probability of a memory corruption of a GUID is 1015 times higher than a collision of an algorithm 4 GUID.
LOL the part at the end of your link is hilarious in context of your post.
Bonus chatter: Note that I’m not saying that a collision caused by a random bit flip is more likely than a collision caused by a v4 GUID happening to match some other v4 GUID.
-
@Kamil-Podlesak said in WTF Bites:
The probability of a memory corruption of a GUID is 1015 times higher than a collision of an algorithm 4 GUID.
I think this is conditional probability, based on assumption that P(UUID implementation is correct, bug-free)==1
What is the real value?The point is that you're worrying about something that has a mathematically larger than zero but realistically impossible probability because "it could happen", while not giving equal thought to things that are far more likely but just assumed to be correct.
Of course this could go wrong, but realistically the reason why it goes wrong are what you said: a bug in the code. This is independent of it being mathematically possible or not.Instead of a UUID key you might as well just use a monotonically increasing integer (AUTO INCREMENT). Now that is "guaranteed" to be correct, no more of this mathematical uncertainty! It's proven to work!
But it isn't. This code could be buggy too. Or the memory of it could be corrupted by radioactivity too. As well as everything else down the line. And as long as you're not having a serious argument about your auto increment key creating a collision this whole point is moot.@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
See above. That's not "you hit an impossible scenario" but "something else has a bug".
Also - birthday problem. The probability of collision is much, much higher than Raymond's 2-122. As I said, the official Linux Git repo has actually suffered from the even more unlikely collision of 160-bit SHA1's.
Raymond is comparing the probability for collision of two keys, so it's correct the way it is.
Of course you're right that for a database with many keys you need to consider the birthday paradox. This gives you basically that you'll end up with a collision at about 261 entries. That's still pretty big. Coincidentally, it's also just about the same time as when you have to worry that a 64 bit auto increment key overflows. So if you complain that a 64 bit auto increment key is buggy you can complain about GUIDs too, but not otherwise.
-
… also the
aztool uses JMESPath for processing the results. So I can filter the tag withaz resource list --query "[?tags.environment == 'somename']"instead…Ok, here comes another fun... obviously in bash with literal argument it is better to use the non-interpolating
'as outer quote, so let's swap the quotes. Well, turns out thataz resource list --query '[?tags.environment == "somename"]'returns the… non-matching resources for some reason. Um ?
?Well, it turns out that in JMESPath, double-quotes quote identifiers, just so you can write
.foo."kebab-cased-key".barinstead of typing out the dreaded brackets like.foo["kebab-cased-key"].baryou'd write in JavaScript. Together with the fact that unlike JSONPath andjq-syntax references into current context don't start with.this however means that you can't just write a string literal like you are used to in JavaScript. Instead, you have to write it in'single quotes'.And that's not all. Because identifier refers to the context,
true,falseother normally constants also do that, so if you want to refer to the JavaScript built-in object of the same name, you have to write it in back-quotes. Like`this`.?Side note: why did the opposite quotes return non-matching resources rather than nothing at all? Well, because the other resources don't have the
environmenttag, so both sides resolve to undefined and all undefineds appear to be equal here.
-
the official Linux Git repo has actually suffered from the even more unlikely collision of 160-bit SHA1's.
Did it? Google does not seem to know about it.
-
@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
See above. That's not "you hit an impossible scenario" but "something else has a bug".
Hitting the specific bug I talked about was itself an "impossible" scenario.
Of course you're right that for a database with many keys you need to consider the birthday paradox. This gives you basically that you'll end up with a collision at about 261 entries. That's still pretty big. Coincidentally, it's also just about the same time as when you have to worry that a 64 bit auto increment key overflows. So if you complain that a 64 bit auto increment key is buggy you can complain about GUIDs too, but not otherwise.
The difference is that sequential numbers are GUARANTEED to work until hit the limit, while GUIDs are probabilistic. I mean, what's the probability that two completely different files completely unintentionally get the same 160-bit SHA1 hash? And yet it happened. And something tells me MS generates a lot more GUIDs than Linux kernel teams make changes in source code.
-
More generally, every kind of resource in Azure has different naming rules.
Learn the rules by heart and you'll be able to tell what sort of resource you're dealing with just from the name!
-
@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
See above. That's not "you hit an impossible scenario" but "something else has a bug".
Hitting the specific bug I talked about was itself an "impossible" scenario.
Of course you're right that for a database with many keys you need to consider the birthday paradox. This gives you basically that you'll end up with a collision at about 261 entries. That's still pretty big. Coincidentally, it's also just about the same time as when you have to worry that a 64 bit auto increment key overflows. So if you complain that a 64 bit auto increment key is buggy you can complain about GUIDs too, but not otherwise.
The difference is that sequential numbers are GUARANTEED to work until hit the limit, while GUIDs are probabilistic. I mean, what's the probability that two completely different files completely unintentionally get the same 160-bit SHA1 hash? And yet it happened. And something tells me MS generates a lot more GUIDs than Linux kernel teams make changes in source code.
Your whole existence is probabilistic. Nothing in thermodynamics prevents me from suddenly flying to the moon, it's just pretty unlikely.
Just how unlikely was already discussed: It doesn't matter, as long as you consider sequential numbers to be guaranteed while ignoring that they could be buggy or suffer memory corruption, too.
-
The difference is that sequential numbers are GUARANTEED to work until hit the limit, while GUIDs are probabilistic.
Whereas sequential numbers are great if they're never handed out to other databases, but become a pain as public identifiers. Or if the database is being replicated or merged.
It's time to stop blaming the programmer and start blaming the database itself.
-
@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
See above. That's not "you hit an impossible scenario" but "something else has a bug".
Hitting the specific bug I talked about was itself an "impossible" scenario.
Of course you're right that for a database with many keys you need to consider the birthday paradox. This gives you basically that you'll end up with a collision at about 261 entries. That's still pretty big. Coincidentally, it's also just about the same time as when you have to worry that a 64 bit auto increment key overflows. So if you complain that a 64 bit auto increment key is buggy you can complain about GUIDs too, but not otherwise.
The difference is that sequential numbers are GUARANTEED to work until hit the limit, while GUIDs are probabilistic. I mean, what's the probability that two completely different files completely unintentionally get the same 160-bit SHA1 hash? And yet it happened. And something tells me MS generates a lot more GUIDs than Linux kernel teams make changes in source code.
Your whole existence is probabilistic.
Sure, but does that mean we should always assume the near-impossible scenarios will never happen? Note that I never said that wishful thinking isn't a valid strategy - it might be perfectly fine even with fuckup propability as high as 10% in some scenarios. As long as you're aware it's possible.
Just how unlikely was already discussed: It doesn't matter, as long as you consider sequential numbers to be guaranteed while ignoring that they could be buggy or suffer memory corruption, too.
I'd argue that some bugs are more likely than others and have different effects, and that should be taken into consideration in design. Mersenne Twister with shitty seed? Not unheard of. Atomic value not updating properly? Basically cosmic rays territory. Uninitialized memory accidentally interpreted as sequential ID? You'll notice it immediately, given that the higher 20 bits ought to be all zeroes. With GUID? You won't ever know.
-
I'd argue that some bugs are more likely than others and have different effects, and that should be taken into consideration in design. Mersenne Twister with shitty seed? Not unheard of. Atomic value not updating properly? Basically cosmic rays territory. Uninitialized memory accidentally interpreted as sequential ID? You'll notice it immediately, given that the higher 20 bits ought to be all zeroes. With GUID? You won't ever know.
That's fine, but doesn't depend on the mathematical probability of a GUID collision. If said collision probability was in fact 0, your point would still stand.
In the end, it's plain old bugs that will be far more likely. If your argument is simply about being defensive in the presence of bugs, I'm not arguing against that.
-
@topspin fair enough.
-
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Ah, it took some re-reading, but I see now where I misinterpreted what you were saying.
I blame it on insufficient levels of caffeine at the time.
-
Google Sheets will not open a CSV file stored in Google Drive.
You have got to be kidding me? There has to be a way to do this. The only way that I can find to get it done would be to download the CSV file and then import it from my computer. I cannot open it or import it if it is already stored in Google Drive.
That is fucking retarded.
-
@Polygeekery said in WTF Bites:
Google Sheets will not open a CSV file stored in Google Drive.
You have got to be kidding me? There has to be a way to do this. The only way that I can find to get it done would be to download the CSV file and then import it from my computer. I cannot open it or import it if it is already stored in Google Drive.
That is fucking retarded.
Yes. I believe you can import a CSV file into a sheets document, but there's no one-click from the Drive interface to do that.
-
@Tsaukpaetra that's the dumb part. The files are already in Google Drive, but I cannot import them in to a sheet from Google Drive. I can only import them from my computer. So the only workflow I can find to get it done is to download them and then import them.
-
@Tsaukpaetra said in WTF Bites:
Status: This piece of shit software thinks a 201 response is a failure.
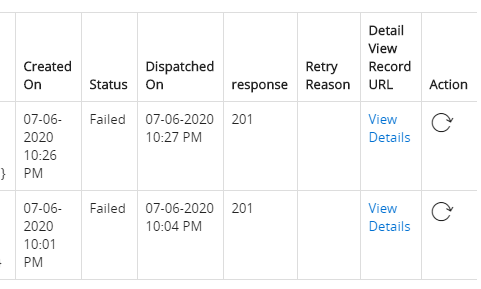
What garbage....
Yeah.
successful = (response.Code == 200);Don't tell me you've never seen code that does that. I certainly have, more than once!
-
Apropos JMESPath. There is:
- JMESPath (with
 syntax)
syntax) - JSONPath (relying on “underlying script engine”)
- jq (with less syntax, but not a library)

- JMESPath (with
-
-
@Tsaukpaetra said in WTF Bites:
As I was trying to enable IPv6 I discovered Cox fucks with your connection and will helpfully resolve non-existing domains for you! To the cox search page, natch.
 That's just bog-standard DNS redirection instead of providing NXDOMAIN when you ask their domain servers for something that doesn't resolve.
That's just bog-standard DNS redirection instead of providing NXDOMAIN when you ask their domain servers for something that doesn't resolve.So, you know, don't use your ISP's DNS server and run your own recursive resolver or go through a DNS server like Google's instead.
-
So, you know, don't use your ISP's DNS server and run your own recursive resolver or go through a DNS server like Google's instead.
I do, normally...
Wait, I think I'm repeating myself...
-
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
 WORDS MEAN THINGS
WORDS MEAN THINGS
-
@Tsaukpaetra Did you forget to set
2001:4860:4860::8888and2001:4860:4860::8844as your DNS6 servers? What a shame...
-
@TwelveBaud said in WTF Bites:
@Tsaukpaetra Did you forget to set
2001:4860:4860::8888and2001:4860:4860::8844as your DNS6 servers? What a shame...Brah I didn't even know that you had to. I left them blank assuming it would simply not hand them out and the computers would use the IPv4 DNS servers. This was apparently a bad assumption.
-
@topspin ever since I've received a bug report from system verification team that turned out to be a one-in-a-billion chance of deadlock, within 24 hours of them having started testing the code containing the deadlock, I'm being paranoid about these near-impossible events. Especially considering that random number generators are usually much less random than people think.
See above. That's not "you hit an impossible scenario" but "something else has a bug".
Hitting the specific bug I talked about was itself an "impossible" scenario.
Of course you're right that for a database with many keys you need to consider the birthday paradox. This gives you basically that you'll end up with a collision at about 261 entries. That's still pretty big. Coincidentally, it's also just about the same time as when you have to worry that a 64 bit auto increment key overflows. So if you complain that a 64 bit auto increment key is buggy you can complain about GUIDs too, but not otherwise.
The difference is that sequential numbers are GUARANTEED to work until hit the limit, while GUIDs are probabilistic. I mean, what's the probability that two completely different files completely unintentionally get the same 160-bit SHA1 hash? And yet it happened. And something tells me MS generates a lot more GUIDs than Linux kernel teams make changes in source code.
Now do nulls in file names.
-
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
-
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
Does sound kind of dumb when you say it like that that. Also seems irrelevant to the previous discussion (or maybe I didn't go back far enough), but whatever.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
Does sound kind of dumb when you say it like that that. Also seems irrelevant to the previous discussion (or maybe I didn't go back far enough), but whatever.
It's not my fault everyone else talks about everything except the original topic.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
-
I hope using pedantic terminology straight from academia will clear things up.
Nah, better use acronyms instead!
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
Does sound kind of dumb when you say it like that that. Also seems irrelevant to the previous discussion (or maybe I didn't go back far enough), but whatever.
It's not my fault everyone else talks about everything except the original topic.
Putting small WTFs into this mega-thread? It's at least your fault that you aren't talking about that.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
Two more wrong sentences!
-
@Tsaukpaetra said in WTF Bites:
I hope using pedantic terminology straight from academia will clear things up.
Nah, better use acronyms instead!
PK is SK of CK and that's FUBAR?
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
Does sound kind of dumb when you say it like that that. Also seems irrelevant to the previous discussion (or maybe I didn't go back far enough), but whatever.
It's not my fault everyone else talks about everything except the original topic.
Putting small WTFs into this mega-thread?
No - one specific small WTF.
Today I had discussion with a colleague about a database that has a primary key consisting of an UUID together with an user-entered identification.
I asked if there is any chance that you can have two entries with the same UUID but a different user-entered identification. We could not come up with any scenario. My colleague also couldn't imagine anything better than a fear that a UUID might not be really unique.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
Two more wrong sentences!
I'd say words have meaning but you're too far gone and I'll never be able to make you use "wrong" correctly.
-
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
Does sound kind of dumb when you say it like that that. Also seems irrelevant to the previous discussion (or maybe I didn't go back far enough), but whatever.
It's not my fault everyone else talks about everything except the original topic.
Putting small WTFs into this mega-thread?
No - one specific small WTF.
Ah. Yes, we'd gotten too far from the context.
Today I had discussion with a colleague about a database that has a primary key consisting of an UUID together with an user-entered identification.
I asked if there is any chance that you can have two entries with the same UUID but a different user-entered identification. We could not come up with any scenario. My colleague also couldn't imagine anything better than a fear that a UUID might not be really unique.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
Two more wrong sentences!
I'd say words have meaning but you're too far gone and I'll never be able to make you use "wrong" correctly.
You just took what turned out to be a super roundabout way of pointing out what you meant because you remembered the context and I didn't and gave a very
 level vague response that would seem nonresponsive to someone who had lost the context. And I definitely did go up several replies but obviously it wasn't far enough.
level vague response that would seem nonresponsive to someone who had lost the context. And I definitely did go up several replies but obviously it wasn't far enough.So...communication failures all around. I remember reading that @Grunnen post now that I've seen it but the connection was broken after two days.
-
@boomzilla said in WTF Bites:
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
Two more wrong sentences!
I'd say words have meaning but you're too far gone and I'll never be able to make you use "wrong" correctly.
You just took what turned out to be a super roundabout way of pointing out what you meant because you remembered the context and I didn't and gave a very
level vague response that would seem nonresponsive to someone who had lost the context. And I definitely did go up several replies but obviously it wasn't far enough.When you play blakeyrat, expect to be treated like blakeyrat. Or: don't be an asshole and I won't be either.
Seriously. How was I supposed to know how much context you're missing if you haven't said it - especially when you entered your usual insult-only-no-merit mode that you always go to when you think you know everything and the other person is demonstrably wrong? (You even straight up told me I'm wrong several times!) Communication is two-way street; both people have to actively try to understand each other. And by actively, I mean asking for clarifications when something sounds amiss - instead of sarcastic quips that only make misunderstandings worse. And it's not just now. You do this all the time. Every argument we ever have ends in the same way - you grossly misunderstand something I say and you never ask WTF I'm talking about, instead posting endless stream of generic insults that makes neither of us any wiser about where we missed each other. That's why I hate talking with you more than almost everyone else on this forum.
-
@boomzilla said in WTF Bites:
@Zecc my original point was that too loose primary key constraint is dangerous even if "it can never happen".
Like, the DB wouldn't notice that you tried to insert a duplicate key and refuse to commit your transaction?
Or do you mean too "loose" of a PK generation algorithm?
I mean the primary key is a superkey of a candidate key and that's bad.
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.

Glad to see you did that intentionally.
-
@topspin what I like the most about it is that it's not a random chain of words, but an actual precise description of the problem. But only someone who's recently taken relational database course in college will understand.
-
@topspin what I like the most about it is that it's not a random chain of words, but an actual precise description of the problem. But only someone who's recently taken relational database course in college will understand.
I’ve taken one. In... let’s say... 2005-ish. Would I have understood it then? No idea. I guess those concepts existed back then?!
(Academia doesn’t exactly move fast when it doesn’t come to ML garbage)
-
@topspin academia doesn't move fast about anything. I've written a thesis on type inference half a year ago, and out of 15 citations I put there, only 5 were from this century, and they were all tutorial books about various programming languages that I only inserted there to bump references count.
Side note - it was "fun" trying to decipher J. Roger Hindley's paper from 1969. He talked about things that didn't have agreed upon names until mid-80s, so he had to make up his own terminology that's completely different from modern one. The lambda calculus in [Milner 1978] also looked like a moon language the first few dozen times.
-
@boomzilla said in WTF Bites:
WORDS MEAN THINGSI hope using pedantic terminology straight from academia will clear things up.
In that you're apparently admitting that you used the wrong word, yes.
I never used any wrong word. You just can't read.
Two more wrong sentences!
I'd say words have meaning but you're too far gone and I'll never be able to make you use "wrong" correctly.
You just took what turned out to be a super roundabout way of pointing out what you meant because you remembered the context and I didn't and gave a very
level vague response that would seem nonresponsive to someone who had lost the context. And I definitely did go up several replies but obviously it wasn't far enough.When you play blakeyrat, expect to be treated like blakeyrat. Or: don't be an asshole and I won't be either.
Oh go fuck yourself. I wasn't being an asshole. I just made a blakey joke.
-
@topspin what I like the most about it is that it's not a random chain of words, but an actual precise description of the problem. But only someone who's recently taken relational database course in college will understand.
Haha! Wrong. I understood it just fine, except that (as I pointed out) I had forgotten that the original thing was a GUID plus some other random stuff, especially since at that point the conversation had drifted to talking about the uniqueness of GUIDs, so at this point I'm thinking that you got your contexts messed up somewhere and are now being an asshole to cover up for that.
 When you start talking about numbers as small as 2⁻¹²², you have to start looking more closely at the things you thought were zero - The Old New Thing
When you start talking about numbers as small as 2⁻¹²², you have to start looking more closely at the things you thought were zero - The Old New Thing

