WTF Bites
-
@Gąska That's too many for me to keep track of. I can only work with the first, say, 128 or so
-
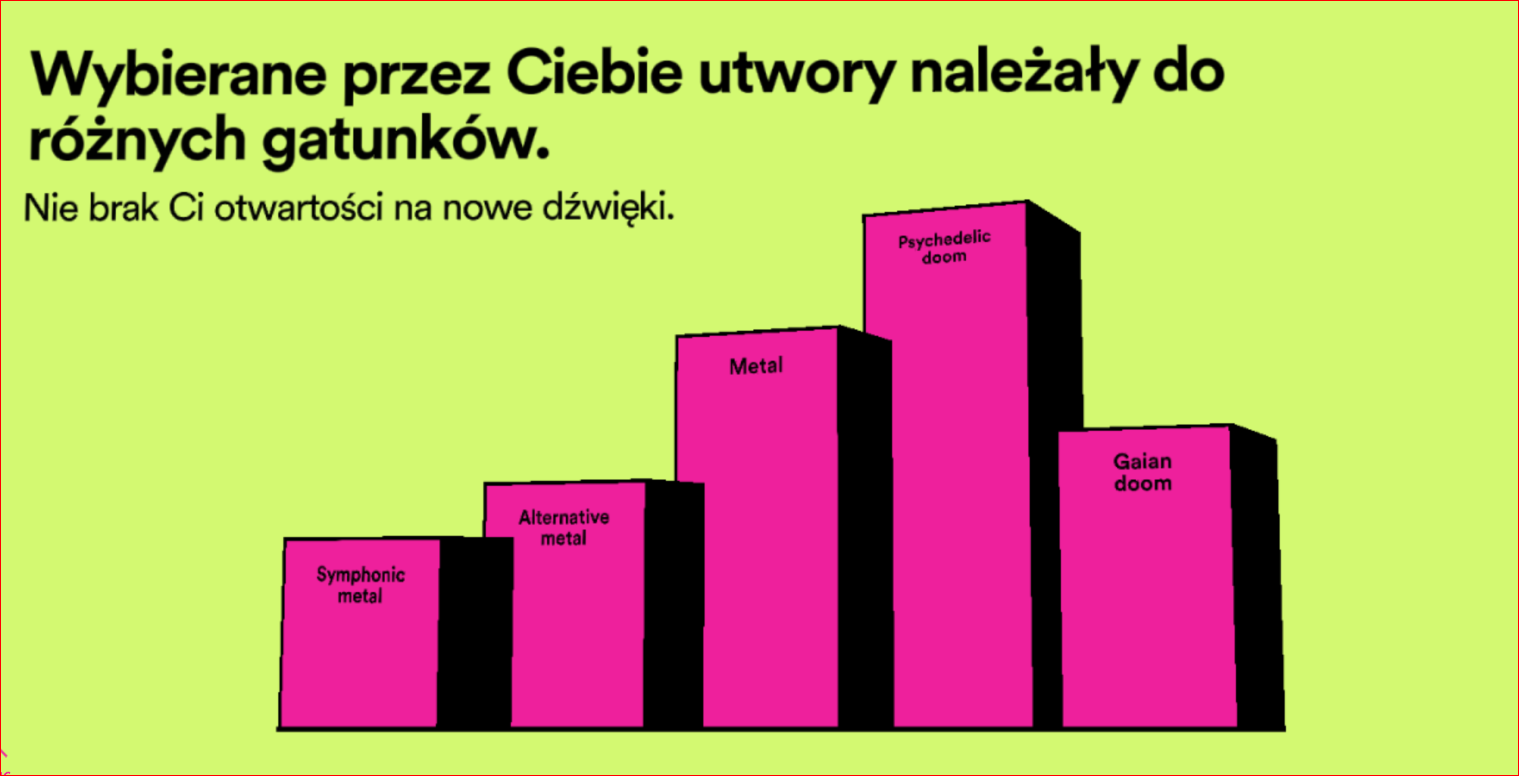
"You're open to new genres of music."
(lists 5 subgenres of metal)
Well, metal is very diverse.
Take
Avantgarde metal (Diablo Swing Orchestra)
Progressive metal (Tool)
Funeral metal (Monolithe)
Doom metal (Avatarium)Completely different.
Gaian Doom
I think it's by R.E.M., and I feel fine about that.
Not really...
electric citizen, Black Math Horseman, Witchcraft, Alunah, Messa, Avatarium, Ruby the Hatchet, Purson, Trees of Eternity, Black Moth, Blood Ceremony
to name best ones I see there.
-
Trying to order some gifts online, facing incompetent
web devsorder forms. I've entered my name, email address, and phone number (bonus WTF: it only says "contact number". I assume this means phone).
Now for the shipping address: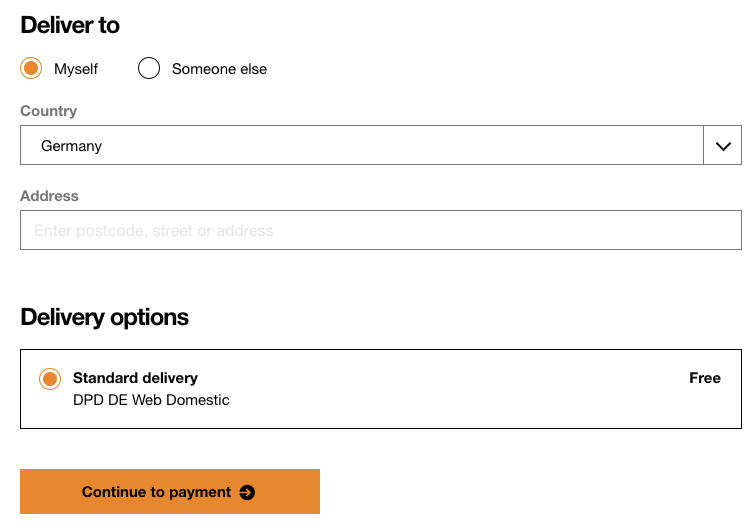
What, only one line? And don't you mean street and address? There's multiple cities with this street name, so that wouldn't exactly be unique.
Okay, suit yourself, I'll put it on one line then:
 Then what am I supposed to do?!
Then what am I supposed to do?!I abbreviate things a bit (i.e. Street -> St etc.), hope it's short enough, then click "Continue to payment".
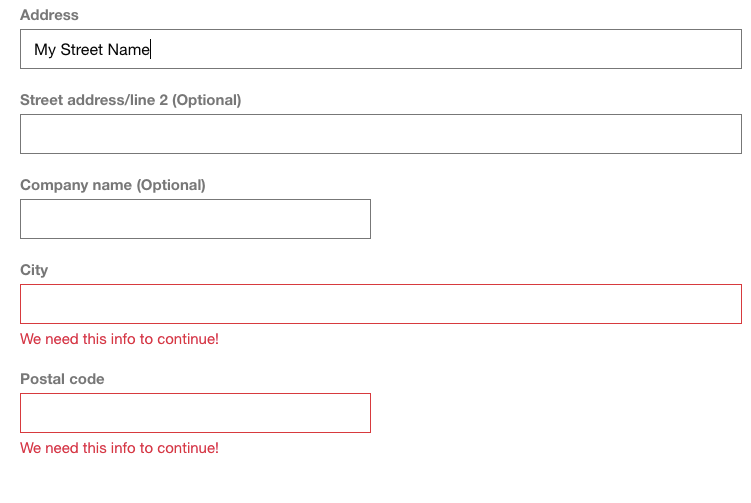

So now that the form verification has realized I haven't filled in the City and Postal code fields, it decides to finally display them.
MoronsCool. I can order now. Finish the order, get forwarded to the order complete form, which is just a blank page.I guess whether I've ordered something or not will be "surprise mechanics".
-
@levicki said in WTF Bites:
it's almost 2020 - why the hell do people still find it notable when text is Unicode!?
Because it still isn't easy to get it right on most platforms (and cross-platform) in most languages, and often doesn't work as easy as it should?
"Most" platforms and "most" languages - yes, obviously. But what if we look just at the stuff used by more than 0.1% of programmers? To the best of my knowledge, almost everything is either Unicode, can be enabled to support Unicode, or is completely encoding-agnostic and will happily work with UTF-8 text.
but I'm dead certain the first 1.1 million code points of any new encoding will be the same.
I wouldn't bet on that. See xkcd "there are 14 competing standards".
What are the other 13 encodings still relevant today that aren't subsets of Unicode? Sometimes, standardization does win.
-
 The most copied StackOverflow Java code snippet contains a bug
The most copied StackOverflow Java code snippet contains a bug
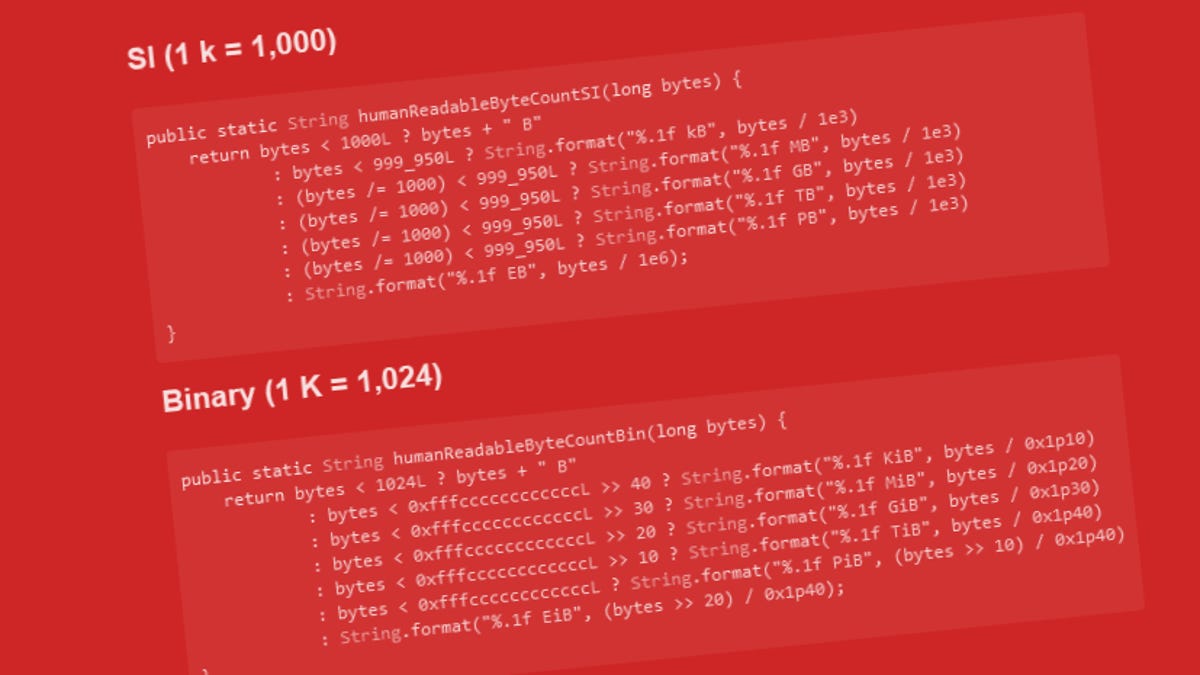
Nine years later, developer corrects code snippet.
-
@levicki said in WTF Bites:
But what if we look just at the stuff used by more than 0.1% of programmers?
You mean C++? It still doesn't have easy and efficient conversions -- not even from ANSI to Unicode and vice versa, not to mention other encodings.
You wouldn't need conversions if you had everything in Unicode to start with. Also - ANSI to Unicode? And back? You're trolling, right?
or is completely encoding-agnostic and will happily work with UTF-8 text.
For example,
strlen()will totally not work correctly with UTF-8 at least on Windows.That's news to me. Sure, the docs are full of lies - including the function name itself - but it still serves its main purpose: tells you how many bytes you need to allocate to copy the string (off by one). And it works as good on Windows as on the various *nices.
What are the other 13 encodings still relevant today that aren't subsets of Unicode?
Define subsets of Unicode?
Unicode except some codepoints are invalid. For example, ASCII.
There is a huge legacy of text written in those code pages, including a metric shit-ton of movie subtitles. As long as that text exists, the tools to work with it need to exist too.
No. You're wrong. Nobody needs any tools to work with them. They only need tools to convert them to Unicode so they can use a tool that properly supports Unicode. Everyone who still works directly in these legacy encodings, or anyone who enables such behavior by e.g. providing tools to do that, does a great disservice to the entire humankind.
Try this:
(...)
3. Open it in IENow tell me what characters you see?
I'm not a fan of running random ActiveX snippets from the internet, so thanks, but no thanks. But whatever you see, I'm 99.9% sure it's IE's fault, not JS's as defined by Ecma. Show me how a modern browser behaves.
-
@TimeBandit it might not be Unicode anymore, but I'm dead certain the first 1.1 million code points of any new encoding will be the same.
Are you kidding? They'll intentionally break it to force everyone to upgrade. Oh, and the only place to get a proper working library is from "them" and if you have to ask how much it costs, you can't afford it.
-
@TimeBandit it might not be Unicode anymore, but I'm dead certain the first 1.1 million code points of any new encoding will be the same.
Are you kidding? They'll intentionally break it to force everyone to upgrade.
Nah, they won't have the balls to pull that. Look how long it took Windows to drop 16-bit support - and unlike 16-bit apps, Unicode is still used for new things!
-
He then reset my router and told me that they'd do a statistic on my line. As that would take a bit,
The fuck? Statistics are collected continuously and automatically. Kinda similar to how your OS tracks packets sent/received.
-
The most copied StackOverflow Java code snippet contains a bug
Nine years later, developer corrects code snippet.
What a shit article! I couldn't even find the codez!
-
@levicki said in WTF Bites:
Also - ANSI to Unicode? And back? You're trolling, right?
I am not. Write an example if you think it's so trivial.
Oh, okay. You just have no idea what you're talking about. Again.
but it still serves its main purpose: tells you how many bytes you need to allocate
So, how is that going to help you learn how many CHARACTERS are in the string you need to process? How are you going to say remove (or copy) individual characters from that string when 1 UTF-8 character != 1 byte?
Depends. TL;DR: a single code point usually isn't what you want to delete.
They only need tools to convert them to Unicode
And burn them back to DVD-R, right?
If they own an ancient medium using ancient data formats, they surely have an ancient device to play it with as well.
Seriously. You should be more specific by what you mean by "work with" legacy encodings. I was damn sure you mean editing subtitles, not just playing them. Of course reading legacy formats is alright. Just convert them internally to Unicode as soon as possible. There are libraries for that. Stop whining.
I'm not a fan of running random ActiveX snippets from the internet, so thanks, but no thanks.
That's filesystemobject COM interface and it's used just to read the fucking file contents.
I know what it is - I still won't run it. Mostly because there would be no point because you already know what it shows and I already know it means nothing (because you specifically requested IE which is anything but a modern browser).
I'm 99.9% sure it's IE's fault, not JS's as defined by Ecma. Show me how a modern browser behaves.
Except it's not, and you are free to devise your own "modern browser" test equivalent.
Uh-uh. You say there's a problem, you prove it. I've used Unicode extensively in multiple JS projects and never had any issues.
-
@levicki said in WTF Bites:
I've used Unicode extensively in multiple JS projects and never had any issues.
Unicode or UTF-8?
Both.
Have you ever worked with UTF-8 data in Javascript which was not encoded in the source file itself?
Of course! SPAs make heavy use of AJAX.
-
@levicki said in WTF Bites:
Again, you said:
or is completely encoding-agnostic and will happily work with UTF-8 text.
I say most programming languages (with the exception of Swift it seems) can't handle UTF-8 as happily as you say.
They will handle them to the full extent possible without knowing the encoding. Which is enough for 99% of programs, and also enough to build libraries that handle the remaining 1% flawlessly.
-
@levicki said in WTF Bites:
My impression is that JS has very poor native support for UTF-8
Words. What do they mean?
Ok, then why don't you demonstrate how easy is to work with UTF-8 by writing a function to reverse UTF-8 encoded string so "🐶💩" shows as "💩🐶". I'll be waiting.
What do you imagine should be done with combining characters under such a scenario?
Reversing the sequence of Unicode codepoints is easy. Reversing the characters (or, worse, the glyphs) is very much not.
But this is all still easier than working with Shift-JIS. Never had that dubious pleasure? Bully for you...
-
@levicki said in WTF Bites:
Of course! SPAs make heavy use of AJAX.
My impression is that JS has very poor native support for UTF-8 because it internally stores strings in Unicode, and third party libraries such as punicode exist for that reason.
Well, you're wrong. Punycode was invented for compatibility with things that existed before JavaScript.
Also, it's not the same to receive UTF-8 string from web server and have it converted by the browser using OS API into Unicode for you so you don't even notice
Doing thing any other way is completely wrong and you should burn in hell if you do. Play stupid games, win stupid bugs.
They will handle them to the full extent possible without knowing the encoding. Which is enough for 99% of use cases, and also enough to build libraries that handle the remaining 1% flawlessly.
Ok, then why don't you demonstrate how easy is to work with UTF-8 by writing a function to reverse UTF-8 encoded string so "🐶💩" shows as "💩🐶". I'll be waiting.
auto str = "🐶💩"_s; std::string out; utf8::utf32to8( std::make_reverse_iterator(utf8::iterator(str.end(), str.begin(), str.end())), std::make_reverse_iterator(utf8::iterator(str.begin(), str.begin(), str.end())), std::back_inserter(out) ); printf("%s\n", out.c_str());Was it really that hard?
-
there is no other encoding but Unicode
There are no encodings then, because Unicode isn't an encoding.

-
@Rhywden, @topspin (special mention @Polygeekery)
I never buy physical goods online.
Thank you for making me feel better about it.
-
there is no other encoding but Unicode
There are no encodings then, because Unicode isn't an encoding.
There are no other encodings but those defined by Unicode. Better?
Edit: although please, don't use UTF-7, okay?
-
@levicki said in WTF Bites:
Ok, then why don't you demonstrate how easy is to work with UTF-8 by writing a function to reverse UTF-8 encoded string so "🐶💩" shows as "💩🐶". I'll be waiting.
-
-
@PleegWat Though, we really should make it more fitting to the theme of the forum:
bool isPackageDelivered { true, false, RETURN_TO_SENDER }Raku can do real schroedingerish superpositions:
> my $status = "delivered"|"not delivered"|"return to sender" any(delivered, not delivered, return to sender) > say $status eq "delivered" any(True, False, False) > say so¹ $status eq "delivered" True > say so $status eq "package not found" False¹
sois what most C-like languages would express as!!
-
@PleegWat Though, we really should make it more fitting to the theme of the forum:
bool isPackageDelivered { true, false,RETURN_TO_SENDEREATEN_BY_TIMEFALL }:kojima:
-
-
although please, don't use UTF-7, okay?
But, but... how else should I send my Unicode strings over MIDI??

-
@ixvedeusi said in WTF Bites:
although please, don't use UTF-7, okay?
But, but... how else should I send my Unicode strings over
MIDISMS??FTFY.
-
There are no other encodings but those defined by Unicode. Better?
Edit: although please, don't use UTF-7, okay?And, while we're at it, also forget about UTF-16.
-
There are no other encodings but those defined by Unicode. Better?
Edit: although please, don't use UTF-7, okay?And, while we're at it, also forget about UTF-16.
They can release UTF-10 and make it the final version.
-
There are no other encodings but those defined by Unicode. Better?
Edit: although please, don't use UTF-7, okay?And, while we're at it, also forget about UTF-16.
Easier said than done.
-
There are no other encodings but those defined by Unicode. Better?
Edit: although please, don't use UTF-7, okay?And, while we're at it, also forget about UTF-16.
Easier said than done.
*click* Uh, what are we talking about again?
-
auto str = "🐶💩"_s;
std::string out;
utf8::utf32to8(
std::make_reverse_iterator(utf8::iterator(str.end(), str.begin(), str.end())),
std::make_reverse_iterator(utf8::iterator(str.begin(), str.begin(), str.end())),
std::back_inserter(out)
);
printf("%s\n", out.c_str());Was it really that hard?
Jeez, and people complain about Java being verbose.
-
-
@loopback0 said in WTF Bites:
They can release UTF-10 and make it the final version.
But then we'd have to periodically stop to reinstall font updates, even if mid string composition.
-
@Rhywden, @topspin (special mention @Polygeekery)
I never buy physical goods online.
Thank you for making me feel better about it.I try to do that as well but some specialized stuff you simply do not get offline. For example, plastic filament for 3D printing.
-
No. Just no. Stop being smart. Text is Unicode. No exceptions. There is no ASCII. There is no EBCDIC or JIS. There is no ISO-8859. There are no codepages other than 65001. Everything is Unicode and the rest doesn't exist.
The NetBeans vs UTF-8 thread is
 . (Although it stopped being about codepage fuckery about 2 posts in.)
. (Although it stopped being about codepage fuckery about 2 posts in.)
-
@levicki said in WTF Bites:
internally stores strings in Unicode
It surprises me that you'd be the one to make this mistake, seeing how you have endless rants about
peoplemillennials not knowing stuff and being vague to the point of illiteracy when they speak and write.Unicode isn't an encoding, and the confusion really comes from the fact that Windows uses "Unicode" to mean UTF-16LE, which is (AFAIK, perhaps it's really UCS-2 - not a JS programmer) actually the encoding also used internally by JavaScript. That doesn't mean calling it "Unicode" is OK, though, since it just broadens the confusion.
-
@strangeways said in WTF Bites:
@levicki said in WTF Bites:
internally stores strings in Unicode
It surprises me that you'd be the one to make this mistake, seeing how you have endless rants about
peoplemillenials not knowing stuff and being vague to the point of illiteracy when they speak and write.He's been raised on Win32. For him, Unicode only means UTF16-LE. And ANSI means whatever happens to be the local codepage. Microsoft says so in its thoroughly incomplete and misleading documentation, so it must be true.
-
-
No. Just no. Stop being smart. Text is Unicode. No exceptions. There is no ASCII. There is no EBCDIC or JIS. There is no ISO-8859. There are no codepages other than 65001. Everything is Unicode and the rest doesn't exist.
The NetBeans vs UTF-8 thread is
. (Although it stopped being about codepage fuckery about 2 posts in.)The golden rule of WTDWTF is that every thread is about X except the "X thread is
" one.
-
@topspin I think Blakeyrat linked that thread as an example of how every thread on WTDWTF eventually ends up being about C and/or C++ language details. Because it did not take long for people to start debating that in that one...
-
@topspin I think Blakeyrat linked that thread as an example of how every thread on WTDWTF eventually ends up being about C and/or C++ language details. Because it did not take long for people to start debating that in that one...
I think it's about time that we add an corollary to it, which is whenever somebody shows something in C/C++, that one rust guy will appear out of the woodworks with a Rust Playground link.
-
@loopback0 said in WTF Bites:
They can release UTF-10 and make it the final version.
That has to come sometime after UTF-95...
-
@loopback0 said in WTF Bites:
They can release UTF-10 and make it the final version.
That has to come sometime after UTF-95...
Finally a bit-width large enough to hold all emoji characters in a single word!

-
@topspin I think Blakeyrat linked that thread as an example of how every thread on WTDWTF eventually ends up being about C and/or C++ language details. Because it did not take long for people to start debating that in that one...
FWIW, nobody mentioned the ISO standard yet.
-
@loopback0 said in WTF Bites:
They can release UTF-10 and make it the final version.
That has to come sometime after UTF-95...
Finally a bit-width large enough to hold all emoji characters in a single word!
Hahaha you wish.
-
@levicki said in WTF Bites:
printf("%s\n", out.c_str());Was it really that hard?
First, no idea why you did the conversion to UTF-8 when you said Unicode is better.
LOL.
Second, that won't print the characters you want in Windows unless you
go through special trouble to configure console for UTF-8 output and unless the user has not messed with the fonts to select a non-Unicode (not to mention non-True Type is possible as well) font.r input is encoded in the way you expect.Duh? Do you also complain when people do math tricks that only work on little endian numbers?
So what exactly did you solve
Your challenge, literally as you wrote it.
and was it in a portable manner?
As portable as can be. UTF8-CPP is very small header-only library that works with every compiler.
If it were that easy, Unicode would be the only standard used by everyone.
Unicode is the only standard used by everyone. It's just shitheads like you who paused their development in 2002 that still insist on using non-Unicode encodings.
-
@levicki said in WTF Bites:
First, no idea why you did the conversion to UTF-8 when you said Unicode is better.
-
-
@Gąska I read that, I'm just fascinated he didn't.
-
@topspin he probably did but didn't understand.
-
Finally a bit-width large enough to hold all emoji characters in a single word!
How many codepoints can you stuff into a family emoji?
It's a trick question. Limiting the number of parents you can specify is discrimination.

