This guy's ignorance of the OS he's using is pissing me off
-
-
Apparently Notepad appends a .txt to the stream name? Huh. That's odd.
-
Apparently Notepad appends a .txt to the stream name? Huh. That's odd.
Notepad loves to append .txt to file names.
-
Yeah! People shouldn't be allowed to use operating systems if they aren't aware of all of the hidden details of the underlying file systems and historical bits of trivia and shit!
-
@Maciejasjmj said:
Apparently Notepad appends a .txt to the stream name? Huh. That's odd.
Notepad loves to append .txt to file names.
Unless you quote the filename in which case it doesn't.
-
@FrostCat said:
"dir test.txt:blakeyrat" will show that stream.
No repro:

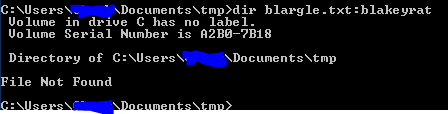
You left /R off the second time. Not sure if that matters, but I think it might.
Additional experimentation: You can't show the stream by including any part of its name. You can show it by
DIR /R blargle.txt
-
You left /R off the second time. Not sure if that matters, but I think it might.
That's what he was demonstrating

-
Okay, I guess I misunderstood. But it wouldn't have shown it with his search pattern, even if he'd included /R. DIR doesn't work that way, I guess.
I've never been interested enough to dig into how these work...beginner.
-
-
If the information is critical, it should stay with the file. Not be bunged into some hidden file that might or might not stay with it.
In general, the safest way to deal with that is by using an application-specific structured file format. Doing it by creating idiosyncratic filesystem facilities risks bad trouble with interworking, as anybody who ever actually worked in a shop that had both Mac Classic and IBM PC machines will well remember.
-
I've never had NTFS corrupt itself, either.
I've seen one workstation some of whose NTFS directories mysteriously forgot that they were directories and become zero-length files instead, along with the loss of everything linked from them.
To be fair, that might have been caused by a RAM fault.
But yes, in general, journalled file systems are more resilient.
-
In general, the safest way to deal with that is by using an application-specific structured file format
Only if that information is application specific.journalled file systems are more resilient.
Journalling is not a panacea. It's designed to do one thing, and one thing only. Checksummed file systems spot (and largely solve the issue of) bit rot; that's where the finger has been pointed at HFS+.FWIW, the worst data loss issue with Ext3 is to do with interruptions to journal replay. Total filesystem corruption is possible. That - umm - "stings".
-
AmigaOS managed to do everything that its Mac contemporaries required resource forks for, without separate data and resource forks, using IFF. The overall format is actually quite similar to that of a Mac resource fork, except that anything that the Mac would have put into the data fork, IFF instead defines a chunk type for so it can go in the same data stream as everything else.
-
AmigaOS managed to do everything that its Mac contemporaries required resource forks for, without separate data and resource forks, using IFF. The overall format is actually quite similar to that of a Mac resource fork, except that anything that the Mac would have put into the data fork, IFF instead defines a chunk type for so it can go in the same data stream as everything else.
Six of one, half-dozen of another.
The only difference is that the Amiga guys "lucked out" and just so happened to pick a scheme compatible with shitty Unix servers, and the Apple guys did not. Neither company was thinking about Unix servers when they started designing their OSes.
And since Amiga was stone-dead before the Internet became popular, their "success" doesn't really matter anyway.
Still, it'd be a great example to follow if anybody in the future designs a new OS from scratch. But more likely they'll just do what, say, Office does and run the .zip compression algorithm on a folder tree in a specific format. That seems to be the modern way of solving that problem.
-
Neither company was thinking about Unix servers when they started designing their OSes.
Apple was clearly not concerned about interworking with any other computer (not even their own Apple // series) when they designed the Mac.
-
more likely they'll just do what, say, Office does and run the .zip compression algorithm on a folder tree in a specific format. That seems to be the modern way of solving that problem.
It's a good way, too. I have quite often had reason to be glad of the fact that you can frequently mess about inside one of those files using standard archiving, text editing and image editing tools without doing it too much damage.
-
Six of one, half-dozen of another.
More like a dozen of one, two half-dozens of another.
-
AmigaOS's support for resources was shite, it resorted to the old "2 files" approach. If AmigaOS's file system had supported forks, rather than being a sack of rancid pig spunk, they probably would have stored their IFF files in a resource fork. The IFF file format itself looks remarkably similar to the Mac's resource file structure, down to the type coding.
-
they probably would have stored their IFF files in a resource fork.
It's arguable that they did. And then stored the data fork in there as well, as a chunk of its own, thereby achieving all the advantages of forked files while avoiding filesystem interchange hassles.
The IFF file format itself looks remarkably similar to the Mac's resource file structure, down to the type coding.
Totally not an accident. It's a reasonable structure, well worth ripping off.
-
Apple was clearly not concerned about interworking with any other computer (not even their own Apple // series) when they designed the Mac.
In 1984, nobody was.
If Mac Classic had been built on firmer foundations, you could easily imagine a scenario where it could transparently "translate" files in its own format to BinHex (or some other encoding schema) when sent to an external server, and transparently check retrieved files to see if they had been encoded that way and un-encode them. It wasn't an insolvable problem. It could even have "encoded" them by making a directory tree, DOCX-style-- just make a subfolder for every 4-character resource type, and a file for every resource ID.
Since Apple spent the last decade of Mac Classic's existence doing little but planning to replace it with something else entirely, and never gave a shit about backwards-compatibility, that never happened. But there's no reason it couldn't have. By OS 8.5/OS 9, computers were well fast enough to do that encoding transparently.
Totally not an accident. It's a reasonable structure, well worth ripping off.
I know I've mentioned this somewhere on this forum before, but the Gamebryo/Creation Engine database files used by Skyrim, Fallout 4, etc. are in the exact same format as a Macintosh Resource Fork.
-
Sure. But I distinctly remember the pain of having to explain to customers that even after their Macs got the ability to read and write IBM floppies, there were certain files that just would not survive a round trip through one of those.
It got sorted out, because it had to, but it was a real pain in the arse for at least two years.
-
Yes it was, but computers at that time were also too slow to be able to do any kind of real-time encoding. Or maybe even then it would have been worthwhile. Who knows. I don't run Apple.
I totally forgot this detail before, but before the DOS-compatibility code was added in the OS (I think 7.1?), you had to use BinHex even on your StuffIt archives-- otherwise Mac Classic would have no way to know what to do with a double-clicked StuffIt file. File extensions meant nothing to Mac Classic, until they added that file extension -> creator code mapping stuff.
-
It's arguable that they did. And then stored the data fork in there as well, as a chunk of its own,
From memory, and I really can't be fucked to go to wankypeado to check, the resources lived in a separate ".info" file.
-
Given the consistent use of IFF for pretty much everything, that's a design decision I never really understood. I guess it would be kind of a reasonable thing to support if the files concerned had come from outside AmigaOS, were therefore not in IFF, and you still wanted a non-generic icon for them. But putting icons for IFF files outside those files did always strike me as weird.
A related kind of bullshit turns up in Windows, with desktop.ini files. Those things are nothing but trouble.
-
that's a design decision I never really understood
It's easy to understand. Metadata is not the data itself. It's intimately related to it, and should be kept with it, but it's not the data itself. As such, it needs to kept with, but separated from, the data.MacOS did that through separate data and resource forks. AmigaOS couldn't do that, and so had to make do with the hack of having 2 files, and then all the extra hacky work of making sure they stay together and up-to-date, detecting orphans, and all the other jazz that comes from having shit underpinnings to your OS.
On the other hand, MacOS arguably misused resource forks as well. I would argue that an application is defined by its
CODEresources, for example.
-
On the other hand, MacOS arguably misused resource forks as well. I would argue that an application is defined by its CODE resources, for example.
What pissed me off is when they made the switch to PPC and decided that the PPC binary, instead of going into a CODE resource as had been done for decades, should go into the Data Fork of the file.
You went so far as to design an APPL file so forward-thinking that even the actual binary code itself could be easily swapped-out in a Resource-- and then when it came time to switch CPUs, you didn't use that capability!? Idiots.
-
On the other hand, MacOS arguably misused resource forks as well. I would argue that an application is defined by its CODE resources, for example.
The problem is your metadata could be my data. As rule of thumb, metadata should be simple and small. If its size is anything comparable to data, then you are
 . If it is larger (the problem of the OP) then
. If it is larger (the problem of the OP) then 
-
... arguably true, but for an application I think the capability for the OS to have a "fat application" (i.e. one that runs natively in 68k or PPC in the same file on disk) is worth the small inconvenience and lack of "idealistic purity".
-
I actually quite like the fat binaries in OSX, but they are self-contained. Application bundles could be used to the same effect too.
-
AmigaOS's support for resources was shite, it resorted to the old "2 files" approach. If AmigaOS's file system had supported forks, rather than being a sack of rancid pig spunk, they probably would have stored their IFF files in a resource fork. The IFF file format itself looks remarkably similar to the Mac's resource file structure, down to the type coding.
Interestingly (?), if you are using COM, you can use Structured Storage, which gives you (roughly) the same feature that Office uses now with the extended formats: an IStorage can contain multiple streams.
Of course it's more complicated to use, but at least you can store multiple distinct "files" in one disk file.
-
I've seen one workstation some of whose NTFS directories mysteriously forgot that they were directories and become zero-length files instead, along with the loss of everything linked from them.
They've lost the directory attribute, but they can be recovered with special tools. They still have the$I30alternate data stream that's an index of file names.
-
The problem is your metadata could be my data. As rule of thumb, metadata should be simple and small.
Not necessarily. One could argue that the change history of a version control system is metadata, and that can, and often does, dwarf the size of the version controlled objects themselves.the capability for the OS to have a "fat application" … is worth the small inconvenience
I'd agree under MacOS, but by the time they'd moved to PPC Apple had totally lost the plot.
@dse said:fat binaries in OSX
which are a function of Mach-O. Application bundles could not be used to the same effect, which is part of the reason why multi-platform NT was such a fiasco. Yes, we had Alphas that MS had somehow sold management the idea of running NT on.
-
One could argue that the change history of a version control system is metadata, and that can, and often does, dwarf the size of the version controlled objects themselves.
One could. But it would not make it true. The history in VCS is everything, there is nothing but the history. Otherwise why would I want any VCS.
-
Resource forks predate hidden files.
Depends.Hidden files that are hidden because they have a ATTRIBute flag on them to say "this file is hidden" predate resource forks - PC-DOS 1.0 had them. (And CP/M probably had them. I'm too lazy to go to Google to check.)
Hidden files that are hidden because their name contains a wart of some sort (leading dot being the main culprit). These, too, go back a long way - the 1970s.
And resource forks in the form we are discussing saw the light of day in 1984.
-
CP/M probably had them
The CP/M filesystem allowed files to have a System attribute, which did hide files from the DIR command but also added some extra semantics.
In any case, the first version of Unix to include pathnames, which is AFAIK the first version to hide dotfiles, was written in 1970 and predates CP/M by about four years.
CP/M was heavily influenced by DEC's TOPS-10. I don't know whether the TOPS-10 filesystem also supported System attributes.
-
The history in VCS is everything, there is nothing but the history.
So what would you export from a version control system. What would you want to save, if there was one thing to save?Commit messages?
Who made the changes?
Date and time of changes?
What tags have been applied?
Diffs from version X to version Y where X is random and Y is X+1?Or, just maybe, the latest version of the stuff that is being version controlled?
-
These are all part of the history. I would choose Diffs if I have to select (assuming X is a complete set with known order), but will be very sad and if it is in my power will fire whoever did not take a backup.
-
CP/M was heavily influenced by DEC's TOPS-10. I don't know whether the TOPS-10 filesystem also supported System attributes.
[url=http://bitsavers.informatik.uni-stuttgart.de/pdf/dec/pdp10/TOPS10_softwareNotebooks/vol02/AA_0916F_Operating_System_Commands_Manual_Oct88.pdf]It doesn’t look like it[/url]. Searching the manual for hide or hidden produces no hits, attributes does but only in one place is the word used in relation to files, and that’s to say that you can change file attributes with theRENAMEcommand — even the section that refers to doesn’t use the word. (System gives 875 hits, so I’m not going to read through all of those :) ) In any case the section about file names etc. (around page 1-13 and beyond) doesn’t mention the ability to hide files.
-
change file attributes with the
RENAMEcommandI don't seem to be grokking this correctly. So, to add a created attribute I could just
RENAME MyFile.txt MyFile.txt_C,151207.121500?
-
They've lost the directory attribute, but they can be recovered with special tools. They still have the $I30 alternate data stream that's an index of file names.
That explains what happened to the one of the update service client directories on an XP machine I had to beat back into shape last week. That caused seriously odd behaviour.
-
I'm just saying, "why didn't they implement that with hidden files?" is kind of like the Raymond Chen example of the guy asking, "why didn't they rescue Apollo 13 with the space shuttle?"
Because the Space Shuttle doesn't have the delta-V budget for a translunar injection, much less a lunar rendezvous, and inadequate heat shielding for the return trip!
-
-
You solution would be fine as long as it's only .file.txt.icon. What happens when you've also got .file.txt.pgp.sig and .file.txt.created-by and .file.txt.open.with and .file.txt.collaborators and …
https://archive.ubuntu.com/ubuntu/pool/main/g/gcc-5/
I agree, this would be much simpler to manage if it was only one file and you had to download GCC for every architecture at once.
-
Fat binaries don't have to contain every possible architecture, you know.
On my machine, which is OSX 10.11 64-bit only
$ file `which clang` /usr/bin/clang: Mach-O 64-bit executable x86_64On my wife's machine, which is OSX 10.6 on intel, 64/32 bit
$file `which clang` /usr/bin/clang: Mach-O universal binary with 2 architectures /usr/bin/clang (for architecture x86_64): Mach-O 64-bit executable x86_64 /usr/bin/clang (for architecture i386): Mach-O executable 1386
On my old powermac under 10.6, I would regularly see 4 architectures.You can use
lipoto remove or add architectures. If, for some reason, you actually needed all architectures for gcc (for example, on a network install accessed by workstations with different architectures), there's absolutely no reason why you couldn'tlipothe binaries together.
-
Yes, but if we're going to store every single file that has the same name but a different suffix in a single "file", either you have to operate on the whole thing as a unit or you've just invented a new name for directories.
-
but if we're going to store every single file that has the same name but a different suffix in a single "file"
A file's name is not its identity. It's merely a piece of metadata, a textual label (potentially one of many) that has been given to a collection of related data. Likewise, a filename suffix is an anchronistic, but sadly widespread and seemingly unkillable, representation of another piece of metadata, viz: the type of data stored in the file.In the case of binaries, it may be useful to store binaries for multiple platforms in the same "file". In the case of a file we might name "foo", it would make no sense to store, for example, the C source code from "foo.c", the C header file from "foo.h", some random and potentially unrelated (maybe fat) binary "foo", and the different images "foo.jpg", "foo.png" and "foo.gif" in the same file. That would be absurd.
What was being argued is that it makes sense to keep file metadata in that file, without affecting the data itself. HFS𝓍 forks and NTFS alternate streams allow that to be done, and as long as you don't need to move that file to a non-fork-supporting filesystem, you're golden.
Another option is to store the metadata in one or more separate files, according to some ad hoc "standard" which is exactly the case with the fallback for HFS𝓍 files exported to a non-fork-supporting filesystem such as FAT, and then used on a non-fork-supporting OS such as anything other than MacOS; everything in the workflow has to support that ad-hoc standard or you risk losing metadata, data, links between the two, or all of the above.
-
A file's name is not its identity. It's merely a piece of metadata, a textual label (potentially one of many) that has been given to a collection of related data.
Linux-using people don't understand that. Believe me, I've had that discussion before.
-
Linux-using people don't understand that. Believe me, I've had that discussion before.
You've just been talking to the wrong linux people.
-
You've just been talking to the wrong linux people.
The OS itself doesn't even see a difference between moving an file and renaming a file.
So no. All Linux people either: 1) wouldn't be using Linux, because that's shit, or 2) simply do not understand the concept that a file's name is metadata, not data.
-
So no. All Linux people either: 1) wouldn't be using Linux, because that's shit, or 2) simply do not understand the concept that a file's name is metadata, not data.
Wow. Broad sweeping arguments about all linux people? Awesome!
Just because someone I had no interaction with designed it a way they felt best doesn't mean I'm as wrong as they are for using their product.
And to counter your point 1 directly: ALL operating systems are shit, just for different reasons.
Lastly, all people are idiots, smart people are just less idiotic than the idiots. Doesn't matter what OS they use!