The Official Status Thread
-
@Gribnit said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
status: tracing unknown bacterial infection that has been slowly becoming more noticeable over the past few days. Why my immune system is not taking care of this I'm not sure...
It's because you died. That's called rot.
I constantly refresh my bits though, I can't be suffering rot!
-
@PleegWat said in The Official Status Thread:
I try to do it with partition drops whenever possible.
Admittedly, I've never worked with databases large enough for partitions to matter.
I'm reading up on what they are. I always thought they were used only for database sharding (ie, spreading data across more than one database instance), but apparently not necessarily?
-
@Zecc said in The Official Status Thread:
I always thought they were used
I thought they were used to store data in separate partitions, in the case of data going "cold" and being moved to archival situations/storage.
-
Stattus: Ugh. You know how to get SQL 2000 BULK INSERT to read a tab-delimited file separated by a line feed? Tell it the row terminator is "0x0A" instead of the "\n" used absolutely everywhere else including format files generated by SQL 2000's version of BCP.
In related news, when I run BCP, it says the file version is 9. Except SQL 2000's version number is 8, so it chokes on the file until it's manually fixed. My guess (
 ) is that, somehow, VS 2008 way back when installed enough SQL 2005 libraries to jump it ahead of SQL 2000 in the PATH variable.
) is that, somehow, VS 2008 way back when installed enough SQL 2005 libraries to jump it ahead of SQL 2000 in the PATH variable.Edit: Although maybe
 is that this is how I handled that...
is that this is how I handled that...DECLARE @Translate TABLE ([Character] VARCHAR(8), [Hexadecimal] VARCHAR(8)); INSERT INTO @Translate ([Character], [Hexadecimal]) VALUES ('\r', '0x0D'); INSERT INTO @Translate ([Character], [Hexadecimal]) VALUES ('\n', '0x0A'); INSERT INTO @Translate ([Character], [Hexadecimal]) VALUES ('\t', '0x09'); INSERT INTO @Translate ([Character], [Hexadecimal]) VALUES ('\f', '0x0C'); SELECT @TC = ISNULL([Hexadecimal], @TC) FROM @Translate WHERE [Character] = @TC; SELECT @TR = ISNULL([Hexadecimal], @TR) FROM @Translate WHERE [Character] = @TR;
-
@Tsaukpaetra said in The Official Status Thread:
I thought they were used to store data in separate partitions
I have done some research and I can confirm database partitions are indeed used to store data in different partitions.

Oh, I guess you mean file system partitions.


-
@Zecc said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
I thought they were used to store data in separate partitions
I have done some research and I can confirm database partitions are indeed used to store data in different partitions.
I had run through several iterations of my thought before writing it. It still left much to be desired, apparently.
Oh, I guess you mean file system partitions.
Well, maybe. Or different devices entirely.
-
@Zecc Correct answer: All of the above.
We use date range partitions to control data retention, dropping aged-out data a partition at a time. For performance and transaction isolation purposes this acts as a TRUNCATE rather than a DELETE; all data related to the partition (including associated index data) can be dropped at once. On oracle this counts as DDL rather than DML; it is not part of a transaction and I don't think it causes redo at all, though I'm not sure.
-
Status
Why is working with the soft keyboard so !#@$!#$@! annoying? Android is supposed to have a simple switch to keep inputs in view. Except that it...doesn't. At least not consistently. And the documentation just says "set this flag!" Which doesn't work.
And there's no easy hook to say "hey, when the keyboard pops up, scroll this view to <location>". In fact, there's no programmatic way of detecting the keyboard other than to check the height of the view and make assumptions (did it change by more than 25% is a common one...which fails for people with weird keyboards). You'd think there'd be a switch you could put on an element to say "hey, I want this element to always be in view." But no.
-
@Benjamin-Hall said in The Official Status Thread:
(did it change by more than 25% is a common one...which fails for people with weird keyboards).
 It's really fun, let me tell you...
It's really fun, let me tell you...I hear it's just as bad in iOS.
-
Status: Kinda proud of myself, I made a little stream helper that keeps a small amount of data after reading in case the consumer rewinds a bit for some reason.
This is for the specific purpose of directly reading zip files from S3, which of course has the TOC at the end, and which needs to rewind the stream all the time for raisins.
The SeekableS3Stream example code I found (Thanks mukunku!) would initiate a new GetObject http request for each and every seek operation, which was thus extremely costly in terms of number of requests and time (due to having to redo the connection for no reason).
So I added a (probably not optimal) buffer mechanism that cached the last 32k of bytes read from the stream and simply reused that if a seek of less-than-that was requested, and now it's quite a bit more effective!

It's almost certainly not thread safe by any means, but it seems to work splendidly, taking what was a few hours download into a half minute at basically full speed!
-
@Tsaukpaetra said in The Official Status Thread:
@Benjamin-Hall said in The Official Status Thread:
(did it change by more than 25% is a common one...which fails for people with weird keyboards).
It's really fun, let me tell you...I hear it's just as bad in iOS.
Oh, it absolutely is. 100 and 10 percent.
Oh, and wile I was writing that parenthetical I almost tagged you. Because I knew you use a funky keyboard.
But then again, it shouldn't really matter. Because the point of this is to keep a particular input button from being covered up. Which your keyboard is unlikely to ever do.
-
@Benjamin-Hall said in The Official Status Thread:
Which your keyboard is unlikely to ever do.
One of the things I got it for, TBH!
-
@Tsaukpaetra said in The Official Status Thread:
So I added a (probably not optimal) buffer mechanism that cached the last 32k of bytes read from the stream and simply reused that if a seek of less-than-that was requested, and now it's quite a bit more effective!
It's the second time in a few days that you post something that's not just not-a-
 , but actually a good idea.
, but actually a good idea.Who are you, and what have you done to the real @Tsaukpaetra?!
-
@Zerosquare said in The Official Status Thread:
Who are you, and what have you done to the real @Tsaukpaetra?!
I'm feeling a little inspired is all. Not inspired enough to find a new job, mind you, but a little better than depressed.
-
Status: Of course, the moment I try to add a pre-fill mechanism to cache a few kb before the seeked position, this shit happens...
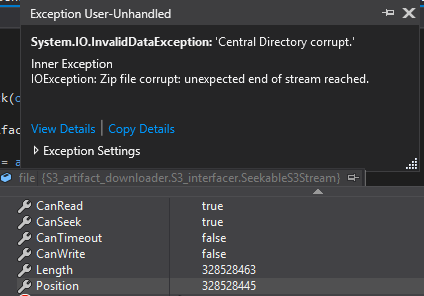
You're... not at the end of the stream? WTF are you talking about?
-
There must be something wrong with my pre-cache buffer logic.
In theory I simply request 32k extra preceding the requested position, read it (so that it fills the buffer), then hand-fiddle the position marker so it knows there's data in the buffer and thus the next read should be 32k after the buffer (i.e. need to actually retrieve more if you're going to start reading from the current position), but from this point if the position is seeked again it decides the data is incorrect.

Oh bother.
-
@Tsaukpaetra said in The Official Status Thread:
There must be something wrong with my pre-cache buffer logic.
Indeed there was. I forgot that the internal position was not necessarily the virtual stream position, and failed to find-and-replace places where it was referenced correctly.
Huzzah! Now it only performs two GetObject requests!
Next up: See if I can manually iterate the files and skip already-existing ones in the extraction, and if that therefore means I can download even less shit from the zip file!
Maybe. Probably yes at the expense of performing more requests for slices of data.

-
@dcon said in The Official Status Thread:
@HardwareGeek said in The Official Status Thread:
@Benjamin-Hall I buy not-cheap ergonomic mice, and the switches and encoders seem to wear out just as fast. The one I'm using now, the buttons are working fine, but the wheel is kaput. You don't realize how much you use it until it doesn't work.
My wireless MS ergo mouse is starting to die. When I click on something it doesn't always get focus. Of course, that could just be Ubuntu also...
Something something Linux hardware
-
@Tsaukpaetra maybe I’m misunderstanding you, but why don’t you download / cache the full file instead of doing seek operations on the server?
-
@Tsaukpaetra said in The Official Status Thread:
You're... not at the end of the stream? WTF are you talking about?
Having been staring at a ZIP decoder recently (it was what I found a SEGV in earlier this week), you most certainly can have such things occurring. The uncompressed length of a file is just some field in a data structure, and might be wrong if the file is corrupted or generated maliciously. The compression stream itself knows (sometimes) when it has got to the end. If it ends early, you can get that sort of error. Another sort of fault is if the compression stream doesn't end properly and tries to keep going over the ZIP central directory. There's a lot of different ways that things can go wrong.
-
@Tsaukpaetra said in The Official Status Thread:
Next up: See if I can manually iterate the files and skip already-existing ones in the extraction, and if that therefore means I can download even less shit from the zip file!
Maybe. Probably yes at the expense of performing more requests for slices of data.
You probably want to fetch the whole central directory. After that, picking the other bits you want should be “easy”.
-
@dkf said in The Official Status Thread:
The compression stream itself knows (sometimes) when it has got to the end.
I know in gzip, the compression stream definitely needs to be terminated correctly, and the same will apply to zip. However at least in gzip it is also possible to flush the stream, meaning you terminate the stream, discard the dictionary, and further data is basically a completely separate stream.
In gzip this means the following works, and the output will be the concatenation of
a.txtandb.txt:gzip a.txt gzip b.txt cat a.txt.gz b.txt.gz | gunzipObviously concatenating zip files doesn't work like that, but the flush mechanic is present in the underlying
deflateand so may occur in zip as well.
-
@PleegWat said in The Official Status Thread:
and I don't think it causes redo at all, though I'm not sure.
Correct, no redo or undo.
That is why it is fast, but also why it can't be part of a transaction.
-
@PleegWat said in The Official Status Thread:
Obviously concatenating zip files doesn't work like that
Yes, you'd need to merge the central directories too. Otherwise it's just like having the second ZIP with a bunch of junk on the front of it. (That's how self-extracting exes work.)
-
@dkf Indeed. It is, however, worthy to note that gzipped tarballs don't work that way either despite the absence of a central directory. The 1kb of NULL bytes terminating the first tarball is the spoiler here.
-
Status: possibly robbed while my house was under repairs for the flooding
Playstation 5 status: missing

(But according to my PS App, I've been playing The Last of Us Remastered. Spoiler: I haven't.)
-
@error said in The Official Status Thread:
Status: possibly robbed while my house was under repairs for the flooding
Playstation 5 status: missing
(But according to my PS App, I've been playing The Last of Us Remastered. Spoiler: I haven't.)
With all the constant tracking and spying nowadays, can it tell you the IP address it was last used at?
-
@topspin said in The Official Status Thread:
With all the constant tracking and spying nowadays, can it tell you the IP address it was last used at?
I'm sure it tells Sony that information. I'm not sure where I can see it.
-
@error said in The Official Status Thread:
@topspin said in The Official Status Thread:
With all the constant tracking and spying nowadays, can it tell you the IP address it was last used at?
I'm sure it tells Sony that information. I'm not sure where I can see it.
Have the cops subpoena them.

Filed under:

-
The contractors want to come back and "help search for" my missing possessions.
If they somehow reappear, I won't ask any questions.
-
As long as your games are exactly like you left them, that is.
-
@topspin said in The Official Status Thread:
@Tsaukpaetra maybe I’m misunderstanding you, but why don’t you download / cache the full file instead of doing seek operations on the server?
I'm having fun making a wish-it-were update mechanism that only downloads the portions of the zip file it needs.
-
@dkf said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
Next up: See if I can manually iterate the files and skip already-existing ones in the extraction, and if that therefore means I can download even less shit from the zip file!
Maybe. Probably yes at the expense of performing more requests for slices of data.
You probably want to fetch the whole central directory. After that, picking the other bits you want should be “easy”.
Yeah, except I'm not personally interpreting the zip at that level, I'm just passing the stream to Microsoft's compression library to do the needful. I just preload 24k before each seek request and Bob's your uncle.
-
@Tsaukpaetra said in The Official Status Thread:
I'm having fun making a wish-it-were update mechanism that only downloads the portions of the zip file it needs.
Instead of downloading the whole zip file, you want to download a single file from the zip?

-
@TimeBandit said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
I'm having fun making a wish-it-were update mechanism that only downloads the portions of the zip file it needs.
Instead of downloading the whole zip file, you want to download a single file from the zip?
Or whatever is different from what the zip file contains, yes.
In theory it's a simple task of bashing the existing files and comparing them to their entries in the zip, replacing at will.
-
-
@TimeBandit said in The Official Status Thread:
To be fair, now that I get what he's trying to do it does make sense to download, say, 1MB part of the zip file instead of the whole 3GB file.
-
@TimeBandit said in The Official Status Thread:
I think it's much simpler than the binary-differential packet compression things the likes of Steam does,,.
-
@topspin said in The Official Status Thread:
To be fair, now that I get what he's trying to do it does make sense to download, say, 1MB part of the zip file instead of the whole 3GB file.
Yes, but then wouldn't it be a lot more simple to not zip the files on the server and only download the ones that changed?
I know I'm not a game developer, I'm just looking at it from my side of the fence
-
@TimeBandit said in The Official Status Thread:
Yes, but then wouldn't it be a lot more simple to not zip the files on the server and only download the ones that changed?
Or to download a zip containing only the parts that have changed? That should be doable, and the files could be kept pre-compressed (in something like an SQLite database or somesuch so as to reduce local I/O on the server). Building the delivery package would be a matter of concatenating the compressed files and building the central directory, and you'd have all the metadata you need for that. ZIP archives don't include the compressed file sizes and offsets within what they checksum. It'd be a bit messy, but it would also be very fast, as long as you have a good way of identifying what subset of files to deliver in the first place.
-
Status: A brief internet outage right when my sister was taking a school test. She is not happy.
-
@error said in The Official Status Thread:
The contractors want to come back and "help search for" my missing possessions.
If they somehow reappear, I won't ask any questions.
Contractors have agreed that it appears to be missing; they're blaming subcontractors. I found my other electronics shoved into contractor bags, some damaged, but present and accounted for.
They've offered to buy me a brand new PS5 on eBay (at market price, well above MSRP). I... Can accept that.
-
@dkf said in The Official Status Thread:
as long as you have a good way of identifying what subset of files to deliver in the first place.
Yeah, these zip files are being provided as the result of a JIRA build, which is wholly discognizant of prior builds in a way that would could be used to generate such metadata. I would have to build up at even more complicated glove to bolt that together...
-
@Tsaukpaetra said in The Official Status Thread:
I would have to build up at even more complicated glove to bolt that together...
Which means you'll do it, right?

-
@error said in The Official Status Thread:
They've offered to buy me a brand new PS5 on eBay (at market price, well above MSRP).
In other words, they know it was done by one of their guys, they just don't want to tell you the truth.
-
Status: Went to pay my CenturyLink bill this afternoon and it's still e-mailing the receipt to somebody else. Turns out the Hindus dindu the needful and it's still broken
 . Back to mailing paper checks I guess.
. Back to mailing paper checks I guess.
-
@Tsaukpaetra said in The Official Status Thread:
which is wholly discognizant of prior builds in a way that would could be used to generate such metadata
The metadata for bolting together a ZIP? It's literally the info in the ZIP central directory (except you'll have to adjust the file offsets on reassembly). The metadata for figuring out what to deliver from the deconstructed ZIP? Well, that's the more difficult bit.
On one level (with a very poor view of the details!) it looks like you're trying to reinvent what git and rsync are already good at…
-
@dkf said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
which is wholly discognizant of prior builds in a way that would could be used to generate such metadata
The metadata for bolting together a ZIP? It's literally the info in the ZIP central directory (except you'll have to adjust the file offsets on reassembly). The metadata for figuring out what to deliver from the deconstructed ZIP? Well, that's the more difficult bit.
On one level (with a very poor view of the details!) it looks like you're trying to reinvent what git and rsync are already good at…
Isn't there an old thread in this forum with exactly this discussion? Like 10-15 years old?
-
@Carnage said in The Official Status Thread:
Isn't there an old thread in this forum with exactly this discussion? Like 10-15 years old?
I have no idea. But I have had wine, so the amount I'm going to do to learn more about this is zero.
-
@dkf said in The Official Status Thread:
@Tsaukpaetra said in The Official Status Thread:
which is wholly discognizant of prior builds in a way that would could be used to generate such metadata
The metadata for bolting together a ZIP? It's literally the info in the ZIP central directory (except you'll have to adjust the file offsets on reassembly). The metadata for figuring out what to deliver from the deconstructed ZIP? Well, that's the more difficult bit.
No, the differences between build artifacts, which would be used to generate the zip of changed files between arbitrary builds. Which is quite a difficult bit!
On one level (with a very poor view of the details!) it looks like you're trying to reinvent what git and rsync are already good at…
I've been told by many different people that using git for large binary change differencing is an extremely bad idea.
I am also unaware of how to use
rsyncto selectively extract a zip file from an S3 bucket.