Linus RAID failure: suspense / horror thriller for IT professionals (video)
-
If he didn't say "Dell server" I would have assumed Mac. Apparently Mac power supplies have firmware settings and stuff....
-
Apparently Mac power supplies have firmware settings and stuff....
They're far from the only ones that do though.
-
If you have a mission-critical, single-point-of-enterprise-failure, not-properly-backed-up server (which, granted, you never should have, but we've all seen it happen) and it starts falling over, the first thing you do is not keep it running while putting extra load on it with a backup job. You don't know what's wrong with it yet; until you do, you have no idea what it's about to do to your data.
Yes! You explained this better than the rant that I was going to write.
There are so many wtfs in that video, as was pointed out with their initial setup and recovery procedure.
Another wtf that I will point out is using a second power supply to power some of the drives, but connecting the data cables to a different system. Unless you know for sure that the power supplies are the same and are both working correctly (like in a system designed for redundant power supplies), this is a bad idea.
I'm not an EE and don't know all of the intimate details, but "ground" and "n volts" lines coming out of any power supply may not be as expected. The ground line may be any voltage (like +2V) but the other power lines coming from the same supply are offset consistently and so the supply works.
By using two power supplies, one drive/mobo could be sending signals at, say, 7V relative to the ground of the other supply (for a really bad power supply), and receiving end of the signal is designed to receive 3.3V, which will fry the receiving end... leading to more data loss. Bonus points are awarded if he used the power supply out of the dying system, but that was not stated in the video.
Just like with their initial setup with the RAID cards, using cheap/incorrect parts to monkey something together is just asking for more trouble...
-
The thing I don't get about RAID controllers is hearing stories about how one failed sector can trigger an array rebuild, which then exposes other failed sectors that nobody noticed before, and now the whole array is burnt.
It seems to me that a failed sector should normally just get rewritten by itself after being reconstituted from the corresponding sectors on the remaining drives. In most cases this will cause the drive whose sector failed to spare it out, and then everything can just carry on as normal.
I would have expected the disks to take care of that themselves and the RAID controller to not even know about it. Of course, every computer from that era had every kind of reporting and diagnostics turned off (it makes IT's life simpler, you see). If nothing else, if the array is configured to properly refresh itself, it should catch this stuff before they accumulate to the point of bringing it all down...
Sure, sometimes a drive will indeed fail in a way that takes it entirely offline;
That's why I have a stash of mechanically failed, really really old drives around 'cause you never know when you'll have to transplant a disk controller.
-
you'll have to transplant a disk controller.
Sadly, I've actually gotten this to work a few times...

-
@smallshellscript said:
you'll have to transplant a disk controller.
Sadly, I've actually gotten this to work a few times...
As have I, regrettably. Though if you hit the disk with a mallet until the platters start making a tinkling noise, you can avoid having to try it.
-
Another wtf that I will point out is using a second power supply to power some of the drives, but connecting the data cables to a different system. Unless you know for sure that the power supplies are the same and are both working correctly (like in a system designed for redundant power supplies), this is a bad idea.
I'm not an EE and don't know all of the intimate details, but "ground" and "n volts" lines coming out of any power supply may not be as expected. The ground line may be any voltage (like +2V) but the other power lines coming from the same supply are offset consistently and so the supply works.
By using two power supplies, one drive/mobo could be sending signals at, say, 7V relative to the ground of the other supply (for a really bad power supply), and receiving end of the signal is designed to receive 3.3V, which will fry the receiving end... leading to more data loss. Bonus points are awarded if he used the power supply out of the dying system, but that was not stated in the video.
For that part, I'll admit I've done it before... not once but fourth.That's what you do if you need to power 10+ hard disk without high wattage power supply. You also have the luxury of able to connect 15 12-inch fans to make sure it's cool enough when you need to do replication overnight.
I was lucky enough that never had any of the IDE hard disks fried this way.
-
That's why I have a stash of mechanically failed, really really old drives around 'cause you never know when you'll have to transplant a disk controller.
One of my ex-company has maintained a collection of that too. They basically recollects any hard disk that fails but diagnosed not a controller problem. So when some staff's hard disk failed and suspected the problem is in the PCB, they will just fetch the controller board of corresponding model to replace it and try again.
-
Then you hit the italics button randomly in**emphasized text each of your sentences while lecturing a**emphasized text forum full of people who did not make this stupid**emphasized text backup mistake.
Discoursed that for you.
-
Though if you hit the disk with a mallet until the platters start making a tinkling noise, you can
avoid having to try itlock up Mission Control and take the PFY to the pub while the Beancounters whine ineffectually at your Boss.
-
Though if you hit the disk with a mallet until the platters start making a tinkling noise, you can avoid having to try it.
i remember the last time i had a platter shatter on me in a hard drive....
it was a 10,000 rpm drive, and it was spinning at full when the platters went.
sounded like there was a banshee in my computer case...
SCARY!
-
sounded like there was a banshee in my computer case...
https://www.youtube.com/watch?v=zMh6eyOIYdw
Banshees are actually surprisingly quiet. Sound like an airliner's background hum.
-
-
I wager the Halo one's more popular at this point.
-
-

Have I mentioned recently that Arbiter's interactions with his commanding officers was the best part of the Halo series by far, and their removing sidelining him in Halo 3 and then removing him altogether in Halo 4 was a huge huge mistake? Pfft. Still mad about that.
Loved Arbiter.
I also like how he continues to call Master Chief "demon" even after they ally.
OH NOES I guess I should be suddenly upset with myself for going off-topic, I guess, according to some morons on this forum.
-
-
OH NOES I guess I should be suddenly upset with myself for going off-topic, I guess, according to some morons on this forum.
No, you should just get this shit out of this thread.
-
i remember the last time i had a platter shatter on me in a hard drive....
it was a 10,000 rpm drive, and it was spinning at full when the platters went.
sounded like there was a banshee in my computer case...
SCARY!
Never actually had that happen to me. Did have a PS's caps or FETs or something explode and go shooting into the fans once when my boss plugged it into the wall to see why it was making the UPS complain of over-current...
-
@smallshellscript said:
Though if you hit the disk with a mallet until the platters start making a tinkling noise, you can
avoid having to try itlock up Mission Control and take the PFY to the pub while the Beancounters whine ineffectually at your Boss.Unfortunately my building lacks an elevator and/or <abbr title="our "server room" used to be something else so it's got sprinklers - can't wait until something catches fire in there">halon system so I've no way to remove management impediments to my becoming a BOFH.
-
Woe you small of mind.
-
-
Stuff like this can lower the odds of catastrophic data loss, but it can't eliminate it. That trusted server could still fail catastrophically
@anonymous234 is describing a filer (or a SAN array). Eliminating catastrophic data loss is why I have three of them, in a 2 synchronous DC+ async DR setup, with snapshots for the last week or month (depending on the data) . . . but I still have backups.
Or else I could buy an Axxana Phoenix. Think a hunking big barrel with ethernet and FC ports and some 3 TB inside, and the rest is UPS and shock protection and fire protection and what have you and a 4G antenna so that you can get at your data even if your datacenter is in the process of burning down. I'm wondering if it would have survived long enough being on the 95th floor of WTC1, but a bit higher or lower should have been doable.
Oh, and I'm not allowed to put my pr0n collection on my work machines, but you suspected that

-
I'm not allowed to put my pr0n collection on my work machines
Now you know what to add to your next work contract

-
Well yeah, that's definitely a concern.
Theoretically, if they're plugged in into the same place, the grounds should be the same, and you shouldn't have problems.
Theoretically.
If you're not OK with "theoretically" and "should" (which you should never, ever be with production stuff!) then you just need to get a better power supply and plug everything into it. No question. Otherwise, you're tempting Murphy
-
Ground potentials and damage to LAN equipment
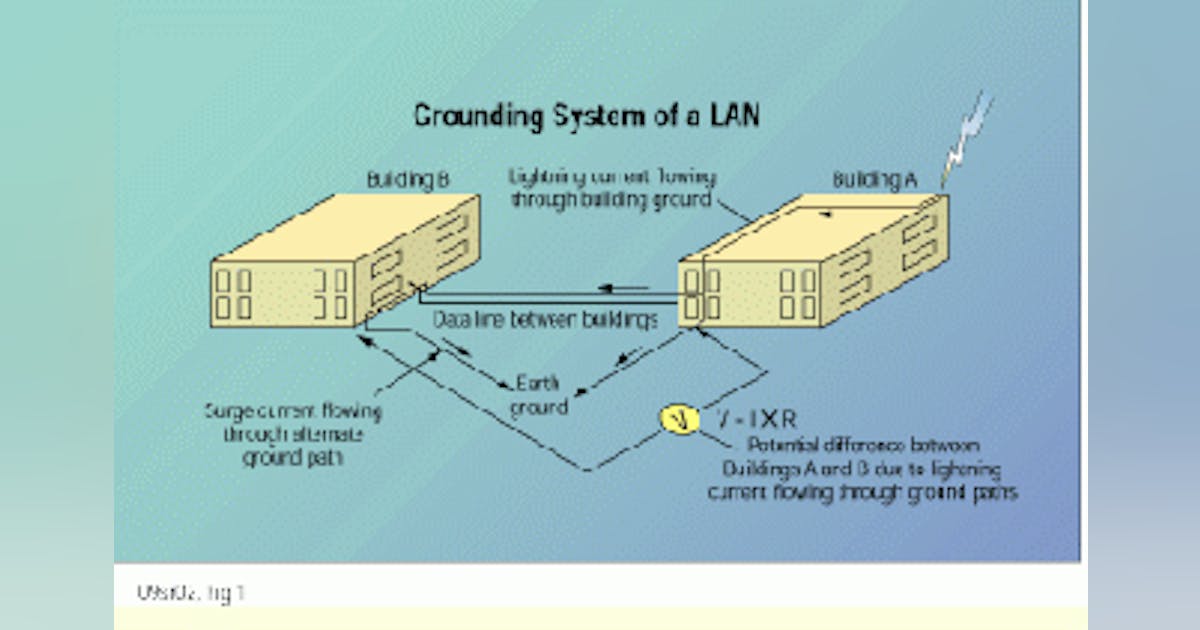
To protect network equipment from damage, surge suppressors should be installed at network ports, or isolators can be used to break the copper path that carries the surge current...
Pretty good example of what can happen when you have seperate power sources - just in a networking environment rather than inside a computer.
Not a good thing...
-
http://www.cablinginstall.com/articles/print/volume-4/issue-9/contents/special-report/ground-potentials-and-damage-to-lan-equipment.html
Haha, site improperly handles ad-blockers...
Filed under: The flip you can't load the content! I see it right there behind you!
-
Happened to me too

Still, it describes the threat (ground potential difference, current over the data line - commonly referred to as "Oh shit, why is my computer making 'hot smells'?") pretty well
-
pretty well
Yeah. I remember reading an article detailing how to obtain "free energy" by using this exact phenomenon. Never did try it though...
-
o.O
What do they think you need energy for, to power an LED?
The whole point of the article is that high currents makes networking things behave abnormally... How did they propose you use the power?
-
How did they propose you use the power?
to power an LED?
Actually, another article in the same publication was how to build a lightning detector from a (large) antenna and an LED connected to the ground.
-
now that is cool.
I wanna do that...
-
how to build a lightning detector from a (large) antenna and an LED connected to the ground.
If the LED is vaporized, you detected lightning hitting your antenna.
-
@Tsaukpaetra said:
how to build a lightning detector from a (large) antenna and an LED connected to the ground.
If the
LEDeverything is vaporized, you detected lightning hitting your antenna.FTFL
-
Maybe you didn't request the content, but the site owners sure did.
-
relevant news story: http://www.theguardian.com/news/oliver-burkeman-s-blog/2014/may/21/everyone-is-totally-just-winging-it
-
@TFA said:
In fact, though, everyone is totally just winging it.
For further evidence, consult this popular Reddit thread
Hm.
-
Nice story. I worked on a big clustered data grid with nodes in geographically dispersed locations, data replicated and sharded in various ways and all in all designed to be as resilient as possible to partial failures. Based on software by a small conpany which have now been bought out by "Guru".
One day the entire system crashes instantaniously. Turns out that if you feed a certain odd character code into the system, the disk reading portion of the code crashes and stalls. Since replication and sharding can proceed, this little poison pill gets copied all over the place. Enough nodes stall to trigger failovers, which copies the pill to the last nodes and the total stall is a fact.
You really need separate inplementations of the same functionality for true redundancy. And even do, you are never truly safe. Every coherent system has some coupling between its components which might cascade failures. Total CDN and AWS region failures are nice examples of this.
-
Oh dear god. You say this guy has a popular youtube channel? God only knows why. My recommendation to the company who hires this guy. Fire him. Now. No, wait, fire him LAST WEEK. He has no idea what the hell he is doing. I take that back, he has enough basic IT knowledge to be fooling around on his own, but by no means should he be in charge of a companies back end.
Let me count the ways:
His server was a pile of junk. God knows how many thousands of pounds (dollars, whatever) of SSDs in a hand-built server, cheap-ass RAID cards, the wrong sized backplane and I'm willing to bet some cheap non-server motherboard lacking things like ECC memory and redundancy in PSU, etc. So you're a guy who likes building custom computers? Fine, build desktops, hell even build non-critical or backup servers, but core critical stuff, you buy proper server hardware from people who specialise in it. Full Step. The End.
Mixing hardware and software RAID? Moron.
His backup strategy. One single backup routine which operates by deleting the old backup and then writing a new one. And that's it. No offsite, no media rotation. Dear god. Get him away from the server room right now and never let him back in.
It took him THREE WEEKS to recover that data. He's lucky that the company didn't fold. Notice in the shots when they were all 'the data is back!" everyone was feigning excitement for the camera? That'll be because it was pretty much redundant at that point. Anything on that server which was actually critical data they've already worked around, reshot, whatever.
A LONG time ago (>15y) I was called into a company on a friday morning. Their IT manager had had a disk fail in a very similar RAID50 setup (but, being 15 years ago, we're talking SCSI) the previous afternoon, had popped in a spare disk, triggered the rebuild and gone home. He came in on Friday morning to discover a second disk in the same RAID5 had failed during the rebuild. He had also discovered his backup system (which was decent in concept, proper full/incremental, grandfathering, offsite) had been failing and his last backup was from nearly a month ago.
I had their data back on Monday morning, the company lost 1 day of work. After trying a variety of tricks all weekend and none of them working, I took one of the failed disks which was exhibiting signs of bearing failure in the motors, connected it to a 3m SCSI cable, plugged one end into the SCSI backplane where the drive had been, wrapped the other end in plastic, dragged a fridge/freezer from the company kitchen into the server room, drilled a hole through the side of the freezer and ran the SCSI cable through the hole so the wrapped drive was inside the freezer. This shrunk the bearings in the motor enough that it ran long enough to rebuild the other bad disk, and from there I could rebuild the 'freezer' disk and recover the whole array.
I'm not suggesting this guy should have used a freezer, because SSD, but in my 20 years of IT consultancy and disaster recovery, the only situation I've had similar to his, it took me 3 days (and thankfully over a weekend), compared to his 3 weeks, and he's celebrating like he's done a good job?
-
drilled a hole through the side of the freezer and ran the SCSI cable through the hole so the wrapped drive was inside the freezer.
You destroyed their freezer? You couldn't have just run the cable through the crack in the door?
-
You destroyed their freezer? You couldn't have just run the cable through the crack in the door?
Yep, after getting permission to do so. We're not talking thin ribbon cables here, we're talking old thick SCSI cables, around 2cm in diameter, and a 12-14h rebuild time. I didn't trust the freezer to remain cold enough with the door cracked open that far for that long. Their IT manager agreed and the freezer was sacrificed, this was my last chance of getting the data back for Monday morning.
-
Did you at least eat all the ice cream first?
-
Btw, he only come to rescue the failure in that company. There's nothing in the video show that he built the system, and you normally don't buy server hardware from data rescue services, right?
-
No, that guy was data rescuing his company's own internal server.
A case of the cobbler's kids having the worst shoes, I'm sure, but yikes that server was a disaster.
-
Btw, he only come to rescue the failure in that company. There's nothing in the video show that he built the system, and you normally don't buy server hardware from data rescue services, right?
I don't know what video you were watching, because it's all explicitly stated that it's his company, and he's the IT guy who built the server and maintains it. He even reminisces about his reason for using 3 RAID cards in the build.
Anyway, I just realised an extra reason why this video makes me mad, and that's because he's the kind of IT guy who makes users mistrust IT and encourages bad habits. You know what his users all learned from that experience? That saving work on the server is bad, and they should save their work locally because it's safer and more reliable.
And then when they go to work for a company with an IT department that actually knows its shit and has a good server infrastructure and proper backup procedures, they become the asshole user that IT hate because they insist on never saving their work on the server.
-
Oh, I didn't notice that because I jump watching parts that I'm interested in (say, there's little point spend time on watching how frustrated he/his colleagues was)
I assumed this is those "someone cried for help and the protagonist come to save the day" type of video.
-
they become the asshole user that IT hate because they insist on never saving their work on the server.
Maybe if our throughput to the server wasn't 600 Kbps on average, I might store my stuff on the server more often. As it stands, I just have a nightly backup of critical stuff. They wanted to have us put our copy of the source control tree on a network drive, and I could only shrug in confusion.
Sure, I get the idea the critical stuff shouldn't be stuck on local machines, but if it takes 40 seconds to load a 400 kb Word document....
-
Wow, gotta love that selective quote there.
-
-

 Banshee - Wikipedia
Banshee - Wikipedia



 Holy Non Sequitur, Batman!
Holy Non Sequitur, Batman!

