I, ChatGPT
-
@Tsaukpaetra said in I, ChatGPT:
Wasn't my picture and they took our printer at work.
Behind the shed, hopefully

-
@Gustav said in I, ChatGPT:
@Applied-Mediocrity said in I, ChatGPT:
@Arantor said in I, ChatGPT:
@Applied-Mediocrity said in I, ChatGPT:
@Gustav said in I, ChatGPT:
The solution to this problem is so obvious it hurts.
So why doesn't anyone in charge see it?
Because that’s effort.

Perhaps. But more likely Gąska is spouting his all-knowing bullshit again, of a solution that actually isn't.
I have yet to hear a single good counterargument to why setting up a second, read-only instance of ChatGPT to filter the input coming to the main instance wouldn't work. Or a single case of anybody trying it in practice. Not a single success, not a single failure. As far as I can tell, nobody even tried to test this. But they did try the "let's tell our bot not to help in criminal activity", which is a kindergarten-level solution that nobody with a functioning brain should ever think it'd work.
Yes, I am comfortable putting it on record that I'm smarter than the entire body of AI research field combined. I don't like that I am, it makes me really scared about the fate of humanity in the next 5 to 10 years. I pray to God that I am wrong and that somebody, anybody at OpenAI did take a primer on cybersecurity at any point in their lives. But all signs in heaven and on earth tell me that no, they didn't, they're a bunch of PhD-holding grifters who are even more up their asses and have even less actual expertise than the blockchain industry.
This actually exists and chatgpt does that. The filter is a smaller model, and if you use the API you call it separately from the main LLM.
this is the thing: https://platform.openai.com/docs/guides/moderation/overview
-
@dkf said in I, ChatGPT:
@Gustav said in I, ChatGPT:
@cvi said in I, ChatGPT:
@Gustav said in I, ChatGPT:
read-only instance of ChatGPT
But the instances are read-only already? Based on the above talk, only the context changes, but the context is just ordinary input that's prepended to whatever the user inputs.
I meant that they should NOT remember any context beyond current prompt (maybe even just current sentence within a prompt), as to not allow the user to influence their ability to tell what is allowed and what isn't. Since this is currently the biggest drawback of chatbots, and the basis for nearly all jailbreak attacks.
The LLMs themselves don't (which is a big flaw with them; standard learning algorithms are very expensive). Remembering inputs is handled by code wrapped around the outside; the remembered stuff is just context.
What we need is a way to have a fully differentiated input scheme where one input contains information that is regarded as far more important than the other. We don't have that.
This also exists, this is the system message on gpt-4. It's not perfect, it is a hard problem apparently
-
@sockpuppet7 said in I, ChatGPT:
@Gustav said in I, ChatGPT:
@Applied-Mediocrity said in I, ChatGPT:
@Arantor said in I, ChatGPT:
@Applied-Mediocrity said in I, ChatGPT:
@Gustav said in I, ChatGPT:
The solution to this problem is so obvious it hurts.
So why doesn't anyone in charge see it?
Because that’s effort.
Perhaps. But more likely Gąska is spouting his all-knowing bullshit again, of a solution that actually isn't.
I have yet to hear a single good counterargument to why setting up a second, read-only instance of ChatGPT to filter the input coming to the main instance wouldn't work. Or a single case of anybody trying it in practice. Not a single success, not a single failure. As far as I can tell, nobody even tried to test this. But they did try the "let's tell our bot not to help in criminal activity", which is a kindergarten-level solution that nobody with a functioning brain should ever think it'd work.
Yes, I am comfortable putting it on record that I'm smarter than the entire body of AI research field combined. I don't like that I am, it makes me really scared about the fate of humanity in the next 5 to 10 years. I pray to God that I am wrong and that somebody, anybody at OpenAI did take a primer on cybersecurity at any point in their lives. But all signs in heaven and on earth tell me that no, they didn't, they're a bunch of PhD-holding grifters who are even more up their asses and have even less actual expertise than the blockchain industry.
This actually exists and chatgpt does that. The filter is a smaller model, and if you use the API you call it separately from the main LLM.
this is the thing: https://platform.openai.com/docs/guides/moderation/overview
Oh okay. So the problem isn't that they haven't tried this approach. It's that the moderation module is completely separate, out of sync, and lightyears behind the main module. Probably a different architecture, too. End result: something that is very good at detecting a few hardcoded cases of unwanted content, but absolutely useless beyond that. And nobody, absolutely nobody, not one person in their entire organization has thought of adding
the-user-is-clearly-trying-to-jailbreak-our-chatbotcategory.Is the runtime cost really cutting that much into their bottom line that they had to go the "smaller model" route? Or are they a victim of a too strict development process? ("GPT is praising Hitler, we need to get it under control." "Meeting minutes: get GPT under control." "I've created epic for getting GPT under control." "I've added user story for moderation module." "Moderation module? Okay. So detecting stuff like sex, self-harm, praising Hitler..." "Ticket: detecting sex. Ticket: detecting self-harm. Ticket: detecting praising Hitler." "Done. Done. Done. User story closed." "We've got our moderation module, we can close the epic."
 )
)
-
@Applied-Mediocrity see? Half the time it works every time!
-
@Gustav said in I, ChatGPT:
@sockpuppet7 said in I, ChatGPT:
the same copyright arguments could be made for any image search. does it matter of it fetches in real time?
Google Image Search was, in fact, illegal in Germany at one point. And no, caching vs. real-time didn't matter to the judge.
 German court: Google Image thumbnails infringe on copyright
German court: Google Image thumbnails infringe on copyright

A German court has ruled that Google's image searches aren't allowed to …
AFAIK (I haven't followed this closely) this is still sort-of the case with Google News. I.e. GN is only available in Germany because they struck some kind of deal with the publishers who are now getting paid for Google to be allowed to show the onebox snippets.
-
@LaoC considering that GN steals 99% of their "usual" traffic, it doesn't surprise me.
-
@Gustav said in I, ChatGPT:
@LaoC considering that GN steals 99% of their "usual" traffic, it doesn't surprise me.
Google News also brings them 99% of the traffic they do get.
Since I don't like siding with Google, I'll just declare this a case of "both sides are wrong."
-
@topspin said in I, ChatGPT:
@Gustav said in I, ChatGPT:
@LaoC considering that GN steals 99% of their "usual" traffic, it doesn't surprise me.
Google News also brings them 99% of the traffic they do get.
It does now, but I doubt their traffic increased by 9900% compared to before introduction of Google News. In fact, I'm pretty sure it went down by a significant margin, and not because people stopped reading news online.
-
@Gustav said in I, ChatGPT:
@topspin said in I, ChatGPT:
@Gustav said in I, ChatGPT:
@LaoC considering that GN steals 99% of their "usual" traffic, it doesn't surprise me.
Google News also brings them 99% of the traffic they do get.
It does now, but I doubt their traffic increased by 9900% compared to before introduction of Google News. In fact, I'm pretty sure it went down by a significant margin, and not because people stopped reading news online.
Here are the unique visitors on three of Germany's largest newspapers, BILD, SZ and FAZ:
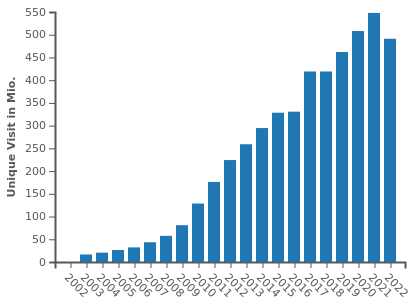
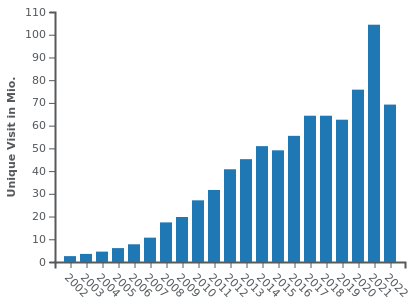
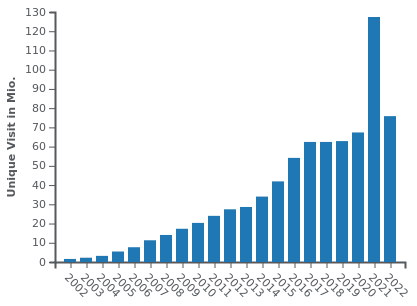
Google News started its Beta in 2002, the official launch was in 2006. Maybe you can tease out some statistical effect of it but it doesn't look very negative.
-
@LaoC okay, fair enough. I take that back. Don't get me wrong, I strongly believe those graphs are mostly if not entirely BS, just like all visitor counts are BS, especially when ads are involved (just look at the recent YouTube ads scandal), and they're always involved. But at the moment, there's more evidence to your side than to my side.
-
@Gustav Plot twist: 98% of those "unique visits" are by Google's spider checking for new content.
-
-
@HardwareGeek said in I, ChatGPT:
@Gustav Plot twist: 98% of those "unique visits" are by Google's spider checking for new content.
Google tends to be good at respecting a site's
/robots.txt. MS/Bing is more abusive.
-
@dkf and yet Bild, for example, only restricts specific subsets of the sites from Google… (and tells OpenAI and Bard to fuck off entirely).
I suspect the view count is inflated for sure.
-
@Arantor said in I, ChatGPT:
@dkf and yet Bild, for example, only restricts specific subsets of the sites from Google… (and tells OpenAI and Bard to fuck off entirely).
I suspect the view count is inflated for sure.
Telling OpenAI to GTFO is reasonable anyway, even without the data theft aspect. They don't know rate limiting and insist on ruining your cache management by fetching everything in a way that doesn't mimic humans at all.
There's some Chinese crawlers that are also pretty bad that way.
-
@LaoC fortunately, the amount of people who buy the paper version of BILD has gone down significantly in the meantime. That could make one hopeful that fewer people consume their retarded propaganda lies (my favorite non-propaganda lie I mentioned before is when they claimed earth’s core consists of 99% gold), but that’s been revolutionized by social media spewing out more of that than ever before.
And I’m sure ChatGPT will help produce much more bullshit, faster, too.
-
@dkf said in I, ChatGPT:
There's some Chinese crawlers that are also pretty bad that way.
I think we've got quite a bunch of those on IP block here.
-
-
 Mickey Mouse and Darth Vader smoking pot: AI image generators play fast and loose with copyrighted characters
Mickey Mouse and Darth Vader smoking pot: AI image generators play fast and loose with copyrighted characters

I tested six leading AI image generators to see how they handle outrageous requests.

-
@Applied-Mediocrity Trademarked, not copyrighted.

-
@dkf said in I, ChatGPT:
@Applied-Mediocrity Trademarked, not copyrighted.
Even bad journalism still makes a valid point once in a while even when it’s
wrong.
-
@topspin said in I, ChatGPT:
fortunately, the amount of people who buy the paper version of BILD has gone down significantly in the meantime.
Oh no! Better let those dumbfucks buy Bild instead of consuming shitty internet posts. Bild has still a much higher quality than the social media they'd turn to!
-
And btw, when the arguments between german newspapers and google escalated, and Bild was strictest, google just removed Bild from the search results. Bild received less than a tenth of their normal visitor numbers, and then begged google ...
Simple point: typingbild.deinto the address bar of the browser is far to complicated for most people. They typebild, hit enter, which gets them to google search forbild, where they will eventually click on the relevant result...
-
-
The money printing machine meets infinite bullshit machine (even though they said they won't
)
https://www.thegamer.com/magic-the-gathering-ai-art-controversy-denied-wizards-of-the-coast/
-
This from the same company accused of trying to hire artists to touch up AI work... https://www.wargamer.com/magic-the-gathering/ai-art-mtg-job-cuts
-
@PleegWat said in I, ChatGPT:
@dkf said in I, ChatGPT:
There's some Chinese crawlers that are also pretty bad that way.
I think we've got quite a bunch of those on IP block here.
Pretty sure at this point it's the majority of our nginx configuration.
-
@boomzilla said in I, ChatGPT:
@PleegWat said in I, ChatGPT:
@dkf said in I, ChatGPT:
There's some Chinese crawlers that are also pretty bad that way.
I think we've got quite a bunch of those on IP block here.
Pretty sure at this point it's the majority of our nginx configuration.
That's how Evil Alex will eventually monetize the forum. He'll restrict access to the forum to require you use a specific VPN service that he rakes in the dough from.
-
 Happy New Year: GPT in 500 lines of SQL - EXPLAIN EXTENDED
Happy New Year: GPT in 500 lines of SQL - EXPLAIN EXTENDED

A complete GPT2 implementation as a single SQL query in PostgreSQL.
-
 Generative AI Has a Visual Plagiarism Problem
Generative AI Has a Visual Plagiarism Problem

Experiments with Midjourney and DALL-E 3 show a copyright minefield
Fun times.
-
@Arantor said in I, ChatGPT:
Generative AI Has a Visual Plagiarism Problem
Experiments with Midjourney and DALL-E 3 show a copyright minefield
Fun times.
Steal first, f... come to think of it, just steal.
When Midjourney’s CEO was interviewed by Forbes, expressing a certain lack of concern for the rights of copyright holders, saying in response to an interviewer who asked: “Did you seek consent from living artists or work still under copyright?”
No. There isn’t really a way to get a hundred million images and know where they’re coming from. It would be cool if images had metadata embedded in them about the copyright owner or something. But that’s not a thing; there’s not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.
-
 UMass Amherst Researchers Bring Dream of Bug-Free Software One Step Closer to Reality | UMass Amherst
UMass Amherst Researchers Bring Dream of Bug-Free Software One Step Closer to Reality | UMass Amherst

The prize-winning method, called Baldur, automatically verifies software with nearly 66% efficacy.
I'm skeptical but I'm unfamiliar with the tools or the techniques. But I would believe that it improves on existing static analysis tools.
-
@boomzilla said in I, ChatGPT:
UMass Amherst Researchers Bring Dream of Bug-Free Software One Step Closer to Reality | UMass Amherst
The prize-winning method, called Baldur, automatically verifies software with nearly 66% efficacy.
I'm skeptical but I'm unfamiliar with the tools or the techniques. But I would believe that it improves on existing static analysis tools.
#!/bin/sh [ $# -ne 1 ] && { echo >&2 "I need a program!"; exit 1; } echo "Your program has bugs and you should feel bad!"99% accurate

-
@Applied-Mediocrity said in I, ChatGPT:
@Arantor said in I, ChatGPT:
Generative AI Has a Visual Plagiarism Problem
Experiments with Midjourney and DALL-E 3 show a copyright minefield
Fun times.
Steal first, f... come to think of it, just steal.
When Midjourney’s CEO was interviewed by Forbes, expressing a certain lack of concern for the rights of copyright holders, saying in response to an interviewer who asked: “Did you seek consent from living artists or work still under copyright?”
No. There isn’t really a way to get a hundred million images and know where they’re coming from. It would be cool if images had metadata embedded in them about the copyright owner or something. But that’s not a thing; there’s not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.
That’s what I’ve been saying. If I do that for twenty images, I’ll get sued (in theory). But once you’re big enough that you do it for millions of images, the laws just don’t apply to you anymore.
But hey, there’s decades of precedent for that.
-
@boomzilla that sounds great. Actual formal verification is the only reliable way to get correct programs, and while probably not usable for the majority of dreck, it should be used much more in fundamental libraries everybody relies on.
But if the proof is automatically generated from some ChatGPT based spec, that’s just going to move the bugs one layer upwards.
-
@topspin yeah, it's one thing to prove that you don't have, e.g., null pointer exceptions or buffer overruns and another to figure out if you've satisfied some obscure bit of business logic that no one can actually agree on in the first place.
-
@topspin said in I, ChatGPT:
That’s what I’ve been saying. If I do that for twenty images, I’ll get sued (in theory). But once you’re big enough that you do it for millions of images, the laws just don’t apply to you anymore.
But hey, there’s decades of precedent for that.Coming on to a century:
-
@boomzilla quoted in I, ChatGPT:
The prize-winning method, called Baldur, automatically verifies software with nearly 66% efficacy.
Checking your code with Baldur should be a gate to releasing it.
-

-
@Applied-Mediocrity said in I, ChatGPT:
The money printing machine meets infinite bullshit machine (even though they said they won't
)https://www.thegamer.com/magic-the-gathering-ai-art-controversy-denied-wizards-of-the-coast/
Oh noooooo...
 Wizards of the Coast reverses course, admits to using AI in promotional image: 'Well, we made a mistake earlier'
Wizards of the Coast reverses course, admits to using AI in promotional image: 'Well, we made a mistake earlier'

The tabletop publisher had firmly denied using generative AI to make the promo image, which has since been deleted.
-
@Applied-Mediocrity said in I, ChatGPT:
@Applied-Mediocrity said in I, ChatGPT:
The money printing machine meets infinite bullshit machine (even though they said they won't
)https://www.thegamer.com/magic-the-gathering-ai-art-controversy-denied-wizards-of-the-coast/
Oh noooooo...
Wizards of the Coast reverses course, admits to using AI in promotional image: 'Well, we made a mistake earlier'
The tabletop publisher had firmly denied using generative AI to make the promo image, which has since been deleted.
Musta slipped in the shower. Happens to the best of us.
-
@Zerosquare We need a
 emoji.
emoji.
-
And all the time they think they can get away with it, they will because it’s cheaper than hiring an actual artist to do it, when they can hire an artist to touch it up (or not bother because, eh, good enough)
The only question is whether this walk-back will be seen as bad enough that they won’t try it again.
Because if a big corp thinks it can save money for a little bad (free) PR, it absolutely will. Unless this results in an actual downturn in sales for them, they’ll do it again.
And once the big boys start normalising it, that will trickle down.
-
It was obvious AI is the new NFT, but I wasn’t expecting it to so quickly appropriate the “corp tries it on, massive backlash, hasty retreat” tango. Admittedly that’s mostly because I hadn’t given the matter any thought whatsoever.
-
@kazitor big corps take a while to move, usually. But unlike NFTs where the value is intangible and perceived ability to sell is not immediately obvious even to grifters, AI comes with the apparent promise of “you can cut your costs by getting artwork done both quicker and cheaper”.
Guarantee that this is not the first big corp to have done it already, just the first major incident of being called on it.
But that just sounds the signal for everyone else: someone was going to get caught with their hand in the generative cookie jar, the only question that remains is if the backlash was big enough to actually hurt. Everyone is now watching to see if the price of the backlash is worth the cost/time saving/no bad PR.
-
-
@Arantor said in I, ChatGPT:
But unlike NFTs where the value is intangible and perceived ability to sell is not immediately obvious even to grifters, AI comes with the apparent promise of “you can cut your costs by getting artwork done both quicker and cheaper”.
Foolishly I didn’t sit on my post for half an hour to let it stew, but this the main thought I wanted to express from when I first heard about this earlier:
NFTs started out as niche and stupid, and when they went mainstream, the response was pretty much immediately “this is stupid, how is anyone into this?” I don’t recall any real period of genuine wider-public interest.
Whereas the current crop of AI started out as niche but kinda neat, went mainstream once “Open”AI suddenly realised their
VC life supportethical obligations didn’t actually require them to withhold their super advanced autocomplete from the public,¹ and then the public reaction was more broadly “this is a big deal” and, IMHO, generally fairly supportive. So getting so quickly to “WTF, why are you using generative AI, how tone-deaf are you” is somewhat surprising to me.¹ Going so far as to not just make the model available for download, but instituting a whole system where any schmuck can leverage 36 cents of GPU time in seconds. I remain convinced this is the only reason people broadly care about any of it – if you had to futz about with pytorch, multi-gigabyte models and minutes of precious internet time to accomplish anything, the tech bros and twitter types wouldn’t get anywhere near it. If the funding dries up, or the price starts to approach reality, I reckon it’ll go back to niche but kinda neat.
edit: Didn’t write ‘autocomplete’! That’s what I get for stewing for merely 29 minutes.
-
In other news, Duolingo apparently got rid of a bunch of their translator contractors, replacing them with AI and a human to vet the translations.
This news broke on Reddit where people are actively saying shit like how this “isn’t net negative” because Duolingo will be able to make their product better faster. But I guess it sucks for the people laid off but it’s overall better for the world. Uh huh.
-
In other other AI news, Wacom put out some AI-produced ads. Not a good look advertising to artists with AI images, apparently.


 If You Steal From One Author, It’s Plagiarism; If You Steal From Many, It’s Research
If You Steal From One Author, It’s Plagiarism; If You Steal From Many, It’s Research