WTF Bites
-
@TimeBandit said in WTF Bites:
Why would your program care how memory is allocated?
You ask for a memory block, you get one. What happen in the back is irrelevant.Because memory and files are the only kind of resource. Nothing else. No sockets, no security descriptors, no synchronization primitives. Nothing at all. It's all just memory and files. And nothing will ever change in how memory and files are accessed, neither in API nor ABI, and especially not in internal ABI between OS components.
for w in "a socket" "a security descriptor" "a synchronization primitive"; do cat <<EOF; Why would your program care how $w is allocated? You ask for $w, you get one. What happen in the back is irrelevant. EOF done
-
If either API or ABI changes, it requires at least recompilation if not source-level changes of all applications
No.
Or at least not necessarily. There are ways to evolve APIs and ABIs that do not require recompilation when the library implementation is updated. For example, adding a new function to an API should not require code to be recompiled to use the software (unless it changes to use that new function, of course, since that wasn't possible before).
Sure, that should have said "in a non-backwards-compatible way". The way you describe it, there's no problem on upgrade either.
-
@loopback0 said in WTF Bites:
So I can collect tomorrow from a store NaN miles away which is never open? Excellent.
To be safe, I wouldn't go before {time}, then I'd have at least %d days to collect.
-
@ben_lubar said in WTF Bites:
I have found the smallest Go program that fails to compile. It has an empty main function and no other executable code.
IOW, it doesn't Go anywhere

-
Sure, that should have said "in a non-backwards-compatible way".
Well, if you deliberately set out to break things then you'll probably manage to break things. No real surprise there.
-
Sure, that should have said "in a non-backwards-compatible way".
Well, if you deliberately set out to break things then you'll probably manage to break things. No real surprise there.
Apparently that's what MS thinks is standard Windows programming practice

-
@boomzilla In OSGi-land, all modules may be unloaded or reloaded. This allows hot-loading arbitrarily large chunks of applications without necessarily incurring downtime. It's not a smell, it's a bracing scent.
However, to keep objects around, the API module can't be part of what's hotloaded, otherwise you'd not, of course, have the classes loaded for those instances.
-
@ben_lubar said in WTF Bites:
 runtime/cgo: -Werror=sign-compare prevents cross-compilation to Windows · Issue #27186 · golang/go
runtime/cgo: -Werror=sign-compare prevents cross-compilation to Windows · Issue #27186 · golang/go
Please answer these questions before submitting your issue. Thanks! What did you do? Compile a package that uses cgo with GOOS=windows set. For example: cat > foo.go <<EOF package main imp...
I have found the smallest Go program that fails to compile. It has an empty
mainfunction and no other executable code.Are you saying a 0-byte program compiles?
-
@ben_lubar said in WTF Bites:
I have found the smallest Go program that fails to compile.
Great! Now just extend that to the rest of the language.

-
@Zerosquare said in WTF Bites:
Before delving into complex solutions involving background updates and mixing different versions, how about a simple one?
The official reason for "you need to update right NOW!" is because of botnets, right?
So, when the timeout expires, don't reboot the machine forcefully. Just disable all network connections until the next restart, and display a clearly visible message stating so. That way, you don't lose any unsaved work. Sure, losing network connectivity may cause some problems, but:
- it's a condition software should be able to handle anyways
- it's still a lot better than force-rebooting the machine.
That's still a case of "it's not your machine and we'll tell you exactly what you can and cannot do with it." Screw that.
-
@ben_lubar said in WTF Bites:
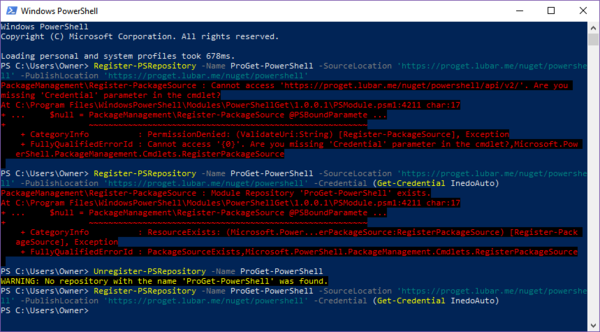
Zero commands were executed in other shells between these commands.
:the_goggles.png:
-
a case of "it's not your
machineinternet and we'll tell you exactly what you can and cannot do with it."FTFY
You can do whatever you want with your foul machine, but don't you go touch my network with it.
-
@blakeyrat said in WTF Bites:
The point of locking the executable/library code while it's running is to prevent exactly what you're proposing: the version on disk being different than the version in memory. Especially important since shared libraries can be loaded or unloaded at any time. It's a safety feature, ensuring that if a program loads foo.dll, then unloads it, then later loads it again, the second time it gets the same version as the first.
No, when a shared library is unloaded, it is also unlocked. It can't be loaded again. Library from the file in the same path may be loaded again, but it may contain a different library at that time. It does not matter, because there was no trace of anything related to the library in between.
But vast majority of programs don't unload shared libraries. Unloading shared libraries requires explicit call to
FreeLibrary(windows) ordlclose(POSIX).All programs can have executable pages unloaded—which applies to all executable pages, whether loaded from shared libraries or the executable itself. As the system does this on its own, it is responsible to ensure the same page is loaded when it is reloaded.
And it does. It could probably be done by anonymising the pages when the file is modified. However, Linux will simply not let you overwrite them. That's right, Linux will not let you overwrite the contents of a file mapped as executable into a running process no more than Windows will.
However, Linux will let you replace the directory entry pointing to the file. The running application keeps the old, now unnamed, file, any new instance will get the new one. Windows could do it as well. There is no hard technical reason they can't. They just chose not to. It is making updates harder. It is also causing problems when programmers forget to close files, because it applies to all open files, not just mapped ones.
@blakeyrat said in WTF Bites:
As I've explained every time some idiot moron Linux user spews out their stupid wrong positions on this matter.
You have serious misconceptions about how it actually works in Linux.
-
Yet, in practice, that doesn't seem to be much of a problem.
Because Blakey confused unloading a library and unloading pages from it.
-
@ixvedeusi said in WTF Bites:
a case of "it's not your
machineinternet and we'll tell you exactly what you can and cannot do with it."FTFY
You can do whatever you want with your foul machine, but don't you go touch my network with it.
If your ISP decides to cut you off because your machine misbehaves, that's fine. But not when your OS decides it won't let you do what you want.
-
No, when a shared library is unloaded, it is also unlocked.
In other words, the scenario of "locking the file prevents version problems" is completely non-sensical.
Windows' file locking doesn't prevent replacing files between unloading and reloading again, and Linux's lack of locking the files of loaded libraries doesn't affect what running programs see of the library at all. They're both equivalent in that regard, just one makes updating files harder than the other.
-
@Bulb That's fair. Wasn't it also a completely separate blakeyrant about how programs are stupid for using file IDs instead of filenames?
-
@pie_flavor said in WTF Bites:
Wasn't it also a completely separate blakeyrant about how programs are stupid for using file IDs instead of filenames?
I thought it was the other way around.
-
@boomzilla Yes, I mistyped.
-
No, when a shared library is unloaded, it is also unlocked.
In other words, the scenario of "locking the file prevents version problems" is completely non-sensical.
As far as I can tell it is nonsensical, yes.
Windows'
filedentry locking doesn't prevent replacing files between unloading and reloading again, and Linux's lack of locking thefilesdentries of loaded libraries doesn't affect what running programs see of the library at all. They're both equivalent in that regard, just one makes updating files harder than the other.It is important to use a termitology that makes the right distinction here. The files, meaning inodes, themselves are locked in both systems, because that is necessary. But Windows also locks the dentries. It is presumably done to avoid potential confusion when a file in use goes away, but in practice when the file is open, there is little reason to look it up again in the filesystem and when it is closed, it can be moved or deleted anyway. So this locking of dentries causes trouble more often than it prevents them.
I also thought that the original reason was that FAT does not have separate inodes, but given that deleted files in FAT just have the first character replaced and otherwise stay around, it seems it should still be possible to make sure the sector chain does not get overwritten or reused while the process is using it at the driver level.
-
@boomzilla said in WTF Bites:
Scenario:
- Main process opens
liba, getsliba.1 libais updated (a la Linux, so the file on disk is nowliba.2but the main process still has the old version in memory)- Main process opens
libb libbloadsliba(what does it get?)- Main process and
libbtry to uselibato communicate
It's been a while since I've fooled around at this level and I've never played with exactly these circumstances but it seems like if
libbgotliba.2then the main process couldn't uselibato talk tolibbsince they'd be talking to differentlibas.I guess that, in theory, it should be possible for the system to keep track of the memory pages where
libais stored, and when a process requires that file again, fetch it from there instead of reading it again from disk?I mean, this is obviously what is done when no update happens in between (
libbrequestsliba, gets the copy that is already in memory, not a brand new copy read from disk), so it looks to me as if the system already has all the info needed to do that in case of update. Of course it can also detect that the version in memory is not the same as the one on disk, and at this point I imagine it's a design choice to provide one or the other. From the discussion of updates here, providing the version in memory might make more sense, but there are maybe other use cases...
- Main process opens
-
@boomzilla said in WTF Bites:
Scenario:
- Main process opens
liba, getsliba.1 libais updated (a la Linux, so the file on disk is nowliba.2but the main process still has the old version in memory)- Main process opens
libb libbloadsliba(what does it get?)- Main process and
libbtry to uselibato communicate
It's been a while since I've fooled around at this level and I've never played with exactly these circumstances but it seems like if
libbgotliba.2then the main process couldn't uselibato talk tolibbsince they'd be talking to differentlibas.I guess that, in theory, it should be possible for the system to keep track of the memory pages where
libais stored, and when a process requires that file again, fetch it from there instead of reading it again from disk?@boomzilla I actually tried it, and it does seem that
libbgets the oldliba. Which is the behaviour I would be expecting, and looks rather sane.(I had issues somewhat like you describe when mixing static libraries in there, but of course these are handled very differently, so it's not a surprise)
- Main process opens
-
@Bulb what? You can edit open files in Linux.
-
@boomzilla said in WTF Bites:
Scenario:
- Main process opens
liba, getsliba.1 libais updated (a la Linux, so the file on disk is nowliba.2but the main process still has the old version in memory)- Main process opens
libb libbloadsliba(what does it get?)- Main process and
libbtry to uselibato communicate
It's been a while since I've fooled around at this level and I've never played with exactly these circumstances but it seems like if
libbgotliba.2then the main process couldn't uselibato talk tolibbsince they'd be talking to differentlibas.I guess that, in theory, it should be possible for the system to keep track of the memory pages where
libais stored, and when a process requires that file again, fetch it from there instead of reading it again from disk?@boomzilla I actually tried it, and it does seem that
libbgets the oldliba. Which is the behaviour I would be expecting, and looks rather sane.(I had issues somewhat like you describe when mixing static libraries in there, but of course these are handled very differently, so it's not a surprise)
That confirms what @dkf and @Bulb were saying.
Filed Under: Science says blakey is wrong
- Main process opens
-
@Bulb what? You can edit open files in Linux.
If they are merely open, yes, you can. But if they are mapped as executable, any attempt to open them for writing will result in the
ETXTBSYerror—and so will an attempt tommapit asPROT_EXECif it is open for writing.
-
@Bulb Your use of italics makes me physically ill.
-
@Bulb ah, TIL.
-
@blakeyrat You are welcome.
-
It is important to use a termitology that makes the right distinction here. The files, meaning inodes, themselves are locked in both systems
I certainly hope the termites are locked safely away from my files!
-
WTF of my day: So, we have a bunch of Office 365 license for my school - after all, one branch of my school is a commercial school and we all know that there are quite a number of businesses where at least having come into contact with Office is a plus.
As a result, every pupil at my school is eligible for an Office 365 account.
I've been shown the ropes recently and the guy "training" me only showed me the "Add a single user" form. Which gets old fast if you have to add about 30 pupils per class (each year we have about 15 new classes).
So I dug a bit and discovered the "Add multiple users with a .CSV" Promptly stumbled about Excel lying to me because it says "Export Sheet As A Comma Separated CSV" (yes, I know, redundancy...) but it actually used semicolons. But, since it's basically a text file, nothing a "Search and replace all" can't fix.Importing the users then went fine, assigning of licenses works as well but then we get to the username/password issue. Somehow the users have to be notified of their usernames and (one-time) passwords, right?
Naw, the csv doesn't provide a "Send username/password to this email address" column. But I can send all the usernames and passwords to me!
But does this list arrive as an attachment in the form of another
csvso I could automate sending the individual data to the respective user (or at least create a printable file with the info for each individual user on one page each)?Fuck, no. It's not even a plain text list inside the email. It's a fucking formatted HTML list.
Thanks a bunch, guys.
-
@Rhywden you could scrape the html

I did that for a project to pull information from a site rather than retype hundreds of entries. Would have helped if the source was actually consistent about its formatting for the entries--they used different containers/classes/ids on different entries despite the outward formatting being the same.
-
@ben_lubar said in WTF Bites:
runtime/cgo: -Werror=sign-compare prevents cross-compilation to Windows · Issue #27186 · golang/go
Please answer these questions before submitting your issue. Thanks! What did you do? Compile a package that uses cgo with GOOS=windows set. For example: cat > foo.go <<EOF package main imp...
I have found the smallest Go program that fails to compile. It has an empty
mainfunction and no other executable code.Are you saying a 0-byte program compiles?
"Fails to compile" as in "should be able to compile but can't".
-
@ben_lubar said in WTF Bites:
Zero commands were executed in other shells between these commands.
:the_goggles.png:
is there a way to tell PowerShell not to do that? It's super hard to read red text over remote desktop.
-
@boomzilla said in WTF Bites:
@pie_flavor said in WTF Bites:
Wasn't it also a completely separate blakeyrant about how programs are stupid for using file IDs instead of filenames?
I thought it was the other way around.
Fun fact: you can have a hard drive be in use even with no files open on it if there are unnamed files open on it. Which sucks.
-
@ben_lubar said in WTF Bites:
even with no files open on it
@ben_lubar said in WTF Bites:
files open on it

-
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
even with no files open on it
@ben_lubar said in WTF Bites:
files open on it
Yes, it makes exactly as little sense as it sounds like.
-
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
even with no files open on it
@ben_lubar said in WTF Bites:
files open on it
Yes, it makes exactly as little sense as it sounds like.
Not true! I hear you can make a killing in support!
-
Status: Arduino IDE is retarded (in more ways than one) But the one I want to lament about is handling of preprocessor directives.
So, say I have a sketch that starts like so:
//Disable debug output functionality #define DebugHelperDisable #include <DebugHelper.h> //Blah blah whatever code, not importantAnd the DebugHelper.c file looks like this:
#include "DebugHelper.h" #if defined DebugHelperDisable //Dummy-ize the functions DebugHelper::DebugHelper(){} DebugHelper::DebugHelper(bool enable){} void DebugHelper::println(String msg){} #else //snip real function codes #endifThis code as specified will fail to link with things like
undefined reference to `DebugHelper::DebugHelper()'.Either I'm doing C wrong or something is fucking screwy here...
-
Make Your PowerShell Errors Less Harsh By Changing Their Color
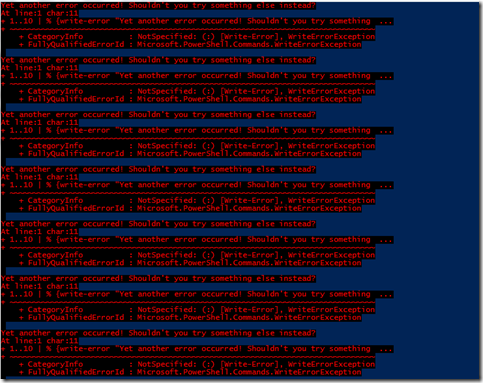
Ok, so errors are never actually pleasing regardless of what color they are. But maybe you’ve been working with PowerShell for a while and or are just dipping your toes in the water and for one rea…
-
@Tsaukpaetra said in WTF Bites:
Either I'm doing C wrong or something is fucking screwy here...
So, apparently, included libraries are compiled before the "Sketch", so setting any
#defines in the sketch doesn't work. Ever. No matter what.However, certain board configs can set defines, so I'm abusing a Debug Level menu option at the board level instead. How fun.
-
@Tsaukpaetra said in WTF Bites:
//Disable debug output functionality
#define DebugHelperDisable
#include <DebugHelper.h>@Tsaukpaetra said in WTF Bites:
DebugHelper.c
You're basically asking why downloading a webpage and modifying it didn't modify the place you downloaded the webpage from.
-
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
//Disable debug output functionality
#define DebugHelperDisable
#include <DebugHelper.h>@Tsaukpaetra said in WTF Bites:
DebugHelper.c
You're basically asking why downloading a webpage and modifying it didn't modify the place you downloaded the webpage from.
Your selective quoting is obtuse and (I believe) wrong.
#defineing something in a header file should always be applicable to the things that include said header file.Unless, like I said before:
@Tsaukpaetra said in WTF Bites:
Either I'm doing C wrong or something is fucking screwy here...
-
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
//Disable debug output functionality
#define DebugHelperDisable
#include <DebugHelper.h>@Tsaukpaetra said in WTF Bites:
DebugHelper.c
You're basically asking why downloading a webpage and modifying it didn't modify the place you downloaded the webpage from.
Your selective quoting is obtuse and (I believe) wrong.
#defineing something in a header file should always be applicable to the things that include said header file.Unless, like I said before:
@Tsaukpaetra said in WTF Bites:
Either I'm doing C wrong or something is fucking screwy here...
Unless
DebugHelper.hactually defines or un-defines DebugHelperDisable, DebugHelper.c will never know about that.
-
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
//Disable debug output functionality
#define DebugHelperDisable
#include <DebugHelper.h>@Tsaukpaetra said in WTF Bites:
DebugHelper.c
You're basically asking why downloading a webpage and modifying it didn't modify the place you downloaded the webpage from.
Your selective quoting is obtuse and (I believe) wrong.
#defineing something in a header file should always be applicable to the things that include said header file.Unless, like I said before:
@Tsaukpaetra said in WTF Bites:
Either I'm doing C wrong or something is fucking screwy here...
Unless
DebugHelper.hactually defines or un-defines DebugHelperDisable, DebugHelper.c will never know about that.Why not? It is being defined before I include
DebugHelper.h, so that should be sufficient, no?
-
@HardwareGeek said in WTF Bites:
I certainly hope the termites are locked safely away from my files!
Try to avoid making your files out of wood (or paper). That helps a lot.
-
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
@ben_lubar said in WTF Bites:
@Tsaukpaetra said in WTF Bites:
//Disable debug output functionality
#define DebugHelperDisable
#include <DebugHelper.h>@Tsaukpaetra said in WTF Bites:
DebugHelper.c
You're basically asking why downloading a webpage and modifying it didn't modify the place you downloaded the webpage from.
Your selective quoting is obtuse and (I believe) wrong.
#defineing something in a header file should always be applicable to the things that include said header file.Unless, like I said before:
@Tsaukpaetra said in WTF Bites:
Either I'm doing C wrong or something is fucking screwy here...
Unless
DebugHelper.hactually defines or un-defines DebugHelperDisable, DebugHelper.c will never know about that.Why not? It is being defined before I include
DebugHelper.h, so that should be sufficient, no?Think of it this way: every
.cfile is compiled separately. None of them know what any of the others are doing apart from information they get via#include(which is literally just reading the file you tell it to in place of that line).
-
@Tsaukpaetra said in WTF Bites:
Why not? It is being defined before I include DebugHelper.h, so that should be sufficient, no?
Which files did you tell us about? If you showed us the main program and
DebugHelper.c, then it doesn't help because there isn't magic under the covers to communicate between the uses ofDebugHelper.h. If you want to defineDebugHelperDisableand have everywhere make use of it, do so using project-level settings and rebuild from all the sources. (This is the sort of thing where that is actually the right approach.)Also, this is very much not C as it has
::in identifier names. It's C++.
-
do so using project-level settings and rebuild from all the sources.
That was going to be my first approach, but Ar-fucking-duino doesn't seem to allow you to do this in any sensible way, at all. Well, technically I could define a whole new boardConfig thing and that would let me do it, but I was depending on the idea that I could easily disable a large swath of the debugging print-strings with a
#Define, and it seems this is frankly impossible without hacks.It's
 anyways, I just switched libraries and ran with it.
anyways, I just switched libraries and ran with it.
-
@Tsaukpaetra said in WTF Bites:
That was going to be my first approach, but Ar-fucking-duino doesn't seem to allow you to do this in any sensible way, at all.
I've no idea what weird wrappers you're using around an ordinary cross-compiling C++ compiler to do all this, but you're getting yourself in a mess in the process. It's supposed to be just like working with a normal C++ compiler except you can't run the result on the machine you're compiling upon (and have different libraries available; that's a more fundamental change than most programmers are used to).
-
@Tsaukpaetra said in WTF Bites:
That was going to be my first approach, but Ar-fucking-duino doesn't seem to allow you to do this in any sensible way, at all.
I've no idea what weird wrappers you're using around an ordinary cross-compiling C++ compiler to do all this, but you're getting yourself in a mess in the process. It's supposed to be just like working with a normal C++ compiler except you can't run the result on the machine you're compiling upon (and have different libraries available; that's a more fundamental change than most programmers are used to).
Unfortunately, "supposed to be" and "is actually" seems far from the truth.
For instance, with a nominal toolchain I'd be able to find out what the compile command outside the IDE is with relative ease. With Arduino, magic things happen to the ino file and it gets transformed into an intermediate file, magic library defines depending on the installation location, and then of course an
avr-gccinvocation using the frankenfiles.It almost reminds me of Unreal Engine's builder, but kinda simplery?
Who cares, right, the important thing is getting the implementation, damn the system's underlying design...