Random thought of the day
-
UNWIND!
I thought it was "Rewind!"

I DO NOT SUPPOSE YOU HAVE GIVEN THOUGHT TO AMON?
Well, no, not usually.
I DO SUPPOSE NOT YOU HAVE THOUGHT GIVEN TO ANON?
What? Can't they think for themselves? And why should I care whether someone else donated braincells to them anyways?
SUPPOSE YOU GIVEN HAVE DO I NOT TO AMON THOUGHT?
REPENT!
Of what?
-
@remi said in Random thought of the day:
Also, why are the two most common standards multiples of each other (110/220)? Again, was it just the convenience of having twice as much loops on one side of a transformer than on the other (but that would mean people were designing for both standards at the same time), or was there some thought process about it?
One group just installed their transformers backwards.

-
@djls45 anything pending pentance, I suppose. I repented of a bottle of water just today.
-
@djls45 said in Random thought of the day:
@remi said in Random thought of the day:
Also, why are the two most common standards multiples of each other (110/220)? Again, was it just the convenience of having twice as much loops on one side of a transformer than on the other (but that would mean people were designing for both standards at the same time), or was there some thought process about it?
One group just installed their transformers backwards.
This is true – rather than dropping 11000 V to 400 V, most residential transformers provide 302500 V instead.
For a real answer to this part of @remi’s question:
It’s called “split-phase power” and is only compatible with inHg·lbf/Btu electrons.Warning! Serious comment inside. Read at own risk.
North America uses pole-mounted transformers similar to those used on Earth, but the middle of the winding is earthed so they instead produce 120 V-to-ground, twice.
-
@kazitor said in Random thought of the day:
most residential transformers provide 302500 V
Wow! I've never seen a residential transformer that provides 300kV.
-
@HardwareGeek said in Random thought of the day:
I've never seen a residential transformer that provides 300kV.
So your name isn't Victor Frankenstein. Good to know.
-
@HardwareGeek said in Random thought of the day:
@kazitor said in Random thought of the day:
most residential transformers provide 302500 V
Wow! I've never seen a residential transformer that provides 300kV.
I guess if you wire it backwards? Though I hazard it won't do so for very long.
-
@dkf said in Random thought of the day:
@HardwareGeek said in Random thought of the day:
I've never seen a residential transformer that provides 300kV.
So your name isn't Victor Frankenstein. Good to know.
It's also not Mike Patton, afaik.

-
@dkf said in Random thought of the day:
@HardwareGeek said in Random thought of the day:
I've never seen a residential transformer that provides 300kV.
So your name isn't Victor Frankenstein. Good to know.
 Frankenstein was the doctor's name.
Frankenstein was the doctor's name.
 The creature's last name might have been Frankenstein as well.
The creature's last name might have been Frankenstein as well.
 Victor Frankenstein was the real monster.
Victor Frankenstein was the real monster.
-
@Zecc said in Random thought of the day:
Victor Frankenstein was the real monster.
The real monster is the small-mindedness of the scientific establishment!
-
I wonder how many gigabytes we could free in this forum's storage server if we did deduplication of uploaded images.
Actually, that would be an interesting side project. Visually hash the pictures, run some image diff algorithm on matching hashes, generate a list of found duplicates for manual review, replace files with symlinks... Should be doable.
-
That's how you end up losing two weeks of posting

Seriously, though. Are there really so many duplicated images, and are they big enough to make a significant difference?
-
@Gąska said in Random thought of the day:
Visually hash the pictures
This is the tricky bit. If you want the easy gain, just do a brittle hash. Or maybe hash (still brittly) the raster vs the file. But visual hashing isn't easy.
-
@Zerosquare I always upload my memes and Twitter screenshots so they don't get lost after years, and I often repeat the memes. But I CBA to keep track of my uploads. I'm pretty sure about 90% of my uploads are duplicates. Of course I don't know if other people do the same thing or not.
-
@Gąska just do a strict equality without visual hash shenanigans. Fewer things to go wrong, and you never know what part of the difference might matter.
Simple example: someone might compain about the jpeg artifacts , the context of which will be lost if you replace with "similar".
, the context of which will be lost if you replace with "similar".
-
@topspin said in Random thought of the day:
@Gąska just do a strict equality without visual hash shenanigans. Fewer things to go wrong, and you never know what part of the difference might matter.
Simple example: someone might compain about the jpeg artifacts , the context of which will be lost if you replace with "similar".I've used a tool in the past to eliminate "duplicate" pictures. It can identify pictures scaled to different sizes, pictures with/without borders, with/without embedded captions, cropped, and rendered at different resolutions. Occasionally it would pick up a false positive of, say, two shots of the same model in the same costume and similar pose taken a few seconds apart, but it did offer the chance to inspect such pairs manually before deletion.
Was never able to find a similar program for audio files that could overlook different lead-in/out intervals, slight changes in playback speed, or minor static/interference.
-
@da-Doctah said in Random thought of the day:
I've used a tool in the past
I shall ask specifics, if can you recall them. Because my own attempts to find such a tool have failed. In fact they are all patently shit, and so are the libraries available on Nuget, which I used to roll my own. The number of absolutely wrong false positives they pick up if the match percentage is adjusted high enough to actually find proper matches was daunting.
-
@da-Doctah said in Random thought of the day:
I've used a tool in the past to eliminate "duplicate" pictures. It can identify pictures scaled to different sizes, pictures with/without borders, with/without embedded captions, cropped, and rendered at different resolutions. Occasionally it would pick up a false positive of, say, two shots of the same model in the same costume and similar pose taken a few seconds apart, but it did offer the chance to inspect such pairs manually before deletion.
I've used a similar tool, ages ago. It claimed all line art images were equal.
-
@PleegWat said in Random thought of the day:
I've used a similar tool, ages ago. It claimed all line art images were equal.
From my limited experience, many use a very naïve approach that goes more or less like this:
- Get a single channel from color data (desaturate, luminosity)
- Divide it into a constant number of macroblocks
- Massage the individual macroblock pixel data down to a single value (average, blur)
- Do cross-correlation
This is how it manages to see through size and aspect ratio differences, added text, saturation changes and minimal amounts of displacement or crop that doesn't exceed 1/2 of macroblock width. I believe you can imagine how your line drawings became equal. Edge information was never even considered.
There are other methods, but ultimately they rely on some "clever" compression function.
So I wonder if there's something better these days. Maybe some mAcHiNe lErNiNG or something?
-
@topspin said in Random thought of the day:
@Gąska just do a strict equality without visual hash shenanigans.
Resolution, file formats, compression artifacts... Most of my duplicates wouldn't be a match with your method.
Fewer things to go wrong, and you never know what part of the difference might matter.
Simple example: someone might compain about the jpeg artifacts , the context of which will be lost if you replace with "similar".Hence manual review. Also, it's not like any of it is mission critical.
-
@Applied-Mediocrity said in Random thought of the day:
@da-Doctah said in Random thought of the day:
I've used a tool in the past
I shall ask specifics, if can you recall them. Because my own attempts to find such a tool have failed. In fact they are all patently shit, and so are the libraries available on Nuget, which I used to roll my own. The number of absolutely wrong false positives they pick up if the match percentage is adjusted high enough to actually find proper matches was daunting.
It was called dpeg. A brief Google search suggests that it's no longer available.
-
@PleegWat said in Random thought of the day:
It claimed all line art images were equal.
They are, they're about a lightish gray
-
@da-Doctah I was trying to roll my own a few years ago using a Python library I found to do the heavy lifting, but I never got anywhere with it. Probably, I think, because I never managed to get numpy installed successfully.
-
@HardwareGeek in other words, it was a bleeding-edge visual processing experiment under fast-fail innovation breeder practice

-
@dkf it's pronounced fraunk-enn-shteen.
-
I suspect a parallel and in fact continuation of the core theme from The Brothers Karamazov into Pynchon and specifically into Gravity's Rainbow. Dostoevsky's resolution is more recognizable and better understood, but they are addressing the same problem. The Infernal Machine device from Against The Day, the space from which God is excluded, also expresses this problem of preterition.
-
@Gąska said in Random thought of the day:
@Zerosquare I always upload my memes and Twitter screenshots so they don't get lost after years, and I often repeat the memes. But I CBA to keep track of my uploads. I'm pretty sure about 90% of my uploads are duplicates. Of course I don't know if other people do the same thing or not.
I made myself a Launchy plugin to keep track of my reused memes so I can just paste in the image tag rather than re-uploading
-
Aw. I have a downbot follower. That's adorbz.
-
@HardwareGeek said in Random thought of the day:
Probably, I think, because I never managed to get numpy installed successfully.
We've found numpy a lot easier to install in recent years as there's been pre-built binaries (“wheel”s) for it for about 4–5 years now, at least for the platforms we support. That's great, because building numpy from source was always a miserable PITA with a large list of compile-time dependencies. (Even worse was its sibling scipy.)
-
@dkf said in Random thought of the day:
building numpy from source was always a miserable PITA with a large list of compile-time dependencies.
Yup. It's been quite a while, but IIRC that's exactly the issue I had. I couldn't find anything precompiled, and never managed to compile it myself. I still have the same need for deduplicating I had then, so I may revisit the project someday.
-
@dkf said in Random thought of the day:
@HardwareGeek said in Random thought of the day:
no idea why that name was picked for pre-built binary library distributions for Pythonwheel
hoopwould be more apropos, but bad marketing. It's a self-contained snake... :sad_rimshot:
-
@HardwareGeek When you revisit it, we do this (in a virtual environment because the system python is usually bust weirdly anyway):
python -m pip install --upgrade setuptools wheel python -m pip install pip # Actually this: # python -m pip install pip==21.1.3 # But that's our tools being finicky # From here on, you've got a working pip properly on the virtual environment path and can do this pip install numpyThat's extracted from our unit tests and documentation. The main things seem to be to get
setuptools,wheelandpipinstalled and working properly first, and definitely to work in a writable virtual environment.Gory numpy version details
We actually use a requirements file that says this:
numpy > 1.13, < 1.20; python_version == '3.6' numpy > 1.13, < 1.21; python_version == '3.7' numpy; python_version >= '3.8'That's because we support — and test with — rather old versions of Python still and have minimum versions that go quite a long way back. You probably don't need that sort of complexity.
If you're not used to requirements files, you can probably ignore this.

-
@dkf said in Random thought of the day:
@HardwareGeek said in Random thought of the day:
Probably, I think, because I never managed to get numpy installed successfully.
We've found numpy a lot easier to install in recent years as there's been pre-built binaries (“wheel”s) for it for about 4–5 years now, at least for the platforms we support. That's great, because building numpy from source was always a miserable PITA with a large list of compile-time dependencies. (Even worse was its sibling scipy.)
Definitely, just trying to install python and numpy using
brew, which is supposed to work automatically, spit out about a million errors compiling stuff.
-
@topspin said in Random thought of the day:
python
Yeah, although 2.7 is supposed to go away with 12.3.
-
@dkf said in Random thought of the day:
no idea why that name was picked for pre-built binary library distributions for Python
Because little babies need training wheels on their projects so they don't fall over and hurt themselves, until they learn how to do everything the proper way.
-
@HardwareGeek said in Random thought of the day:
I still have the same need for deduplicating I had then, so I may revisit the project someday.
Still on the subject of existing solutions. While digikam is way more than you probably need (it's way more than I need, too, fortunately), it does have a deduplication utility (based on Haar wavelet transforms) that I've found to be pretty effective. Plus, as well as having a GUI, its results are stored in a MySQL or SQLite database that isn't too hard to dig around in.
-
@Watson said in Random thought of the day:
While digikam is way more than you probably need
Probably, but it's free and it's way easier than writing my own, so it's definitely worth investigating.
-
@Gribnit said in Random thought of the day:
I suspect a parallel and in fact continuation of the core theme from The Brothers Karamazov into Pynchon and specifically into Gravity's Rainbow. Dostoevsky's resolution is more recognizable and better understood, but they are addressing the same problem. The Infernal Machine device from Against The Day, the space from which God is excluded, also expresses this problem of preterition.
Okay
boomerhumanities major.
-
@Gąska that sounds more like a Go wheel than a Python wheel.
-
@da-Doctah theology, actually, specializing in theomachia and the attendant deicide.
-
Ace Combat 2 is a Japanese video game from the 90s. Like most Japanese games from the 90s, the English is a little awkward.
When you finish the whole game, after a short epilogue, the credit sequence and maybe a victory round if you're good enough, you are presented with this question.
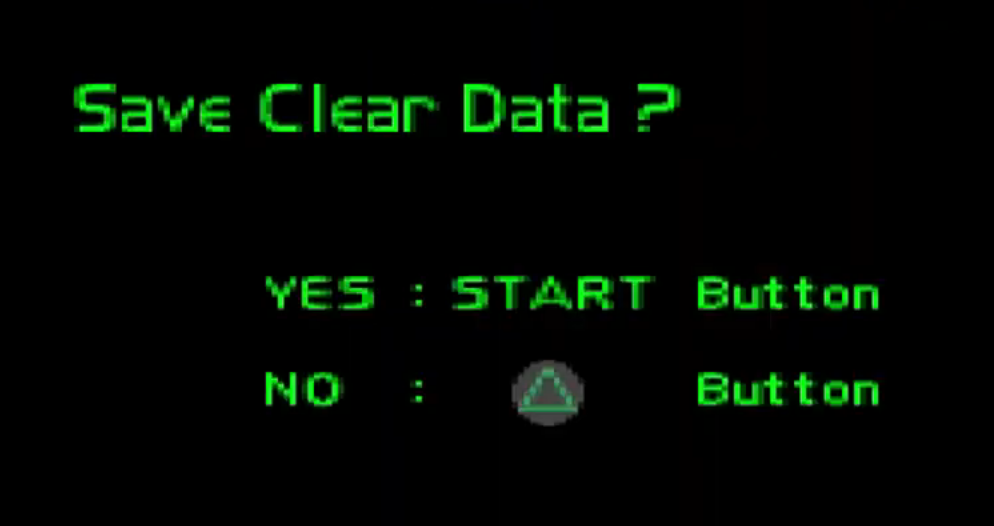
There's nothing wrong with it. It's proper English. They didn't typo or mess up the word order. It asks exactly what they meant to ask. It's just... they could word it a little better. So it doesn't sound like it's going to clear save data.
-
@Gąska said in Random thought of the day:
So it doesn't sound like it's going to clear save data.
It's not a Yoko Taro (I think I have that right, the weird dude who directed the Nier games) game, so you're probably safe.
-
@Gąska Training to become the Ghost of Chi-cław?
-
@Gąska said in Random thought of the day:
They didn't typo or mess up the word order. It asks exactly what they meant to ask.
But what are they asking about???
The only way I can make some syntactic sense out of that sentence is by assuming that there is some sort of data produced by the game that is called "clear data" and they're asking you if you want to save that data, but I have no idea what a "clear data" can be.
(I could easily imagine that they're asking you whether you want to save or clear data, but then the whole thing would be wrongly worded and you said it isn't, so I have to assume that's not it)
-
My random guess is that by "clear" data, they mean "whatever levels you cleared (completed)" data.
-
@Zerosquare That seems quite far-fetched to me but I'm not familiar with broken-English-90's-Japanese-video-games, so maybe in that context it's something that everyone knows.
-
@remi said in Random thought of the day:
@Zerosquare That seems quite far-fetched to me but I'm not familiar with broken-English-90's-Japanese-video-games, so maybe in that context it's something that everyone knows.
Considering the context of "When you finish the whole game", it does seem to mean exactly that.
-
@topspin If anything, that context makes it even less understandable to me -- if you've finished the game then you must have cleared all the levels, so why would it makes sense to ask whether you want to save the "cleared" ones (as opposed to... nothing else because there is nothing that you haven't cleared??).
But I'll take your word for it. Again, I'm not familiar at all with that jargon so if it makes sense to people who actually play the game, then I'll accept it as such.
-
@remi said in Random thought of the day:
if you've finished the game then you must have cleared all the levels
Not necessarily. Some games have optional or hidden levels.
Also, some games unlock extra content after you finished them once.
-
@remi have I mentioned it's a PSX game? Because it's a PSX game therefore there's no autosave. When you beat the game, you unlock a few bonus features depending on how good you were. So it makes sense to save the fact that you completed - ie. cleared - the whole game. Also, the game keeps track of best times on each level, and this is the only opportunity to save the time from the final level. That's your opportunity to record your time to the memory card.
Yes, the translation is very bad - it confused the hell out of 5 year old me - but it is technically correct.