WTF Bites
-
@Arantor Don't mind him. He's just mad about having to read all those long German words.
Why does the word “schadenfreude” come to mind unbidden at this juncture?
-
@Arantor Don't mind him. He's just mad about having to read all those long German words.
Yes. All those long words, like
t,ej,div,m.
Here's a hint, free of charge: Test what your fucking button does and have a look at your server logs, which by now should show that everything gets a400 Bad Request.
-
80KB of JS and almost all of that is going to be DropZone
That's in there, too.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.
I thought we were friends.
-
80KB of JS and almost all of that is going to be DropZone
That's in there, too.
DropZone is convenient for handling big uploads in a user friendly way - I use it for this project because I need to handle 5MB files being sent directly to AWS without coming to my server (because serverless etc) and I couldn’t be arsed to roll it all from scratch, but I did wire up the error handling and actually test it.
I am a unicorn after all.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.I thought we were friends.
I briefly thought about phrasing it differently, but decided that’d ruin the dramatic effect.
-
I thought we were friends.
Being friends is about accepting each others flaws and looking past them. Such as being web devs and ... uh ... "shit-slinging morons", I guess.

-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.
You don't hate web devs enough. You think you do, but you don't.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.
You don't hate web devs enough. You think you do, but you don't.
I don't know if I should be flattered or offended.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.
You don't hate web devs enough. You think you do, but you don't.
I don't know if I should be flattered or offended.

-
By the way, the syntax generated by their transpilers or whatever makes me wonder if the point is backwards-compatibility to 1989 or if it's intentionally unreadable. Because it sure looks like the latter.
Well, it is intentional, but obfuscation isn't the main goal. It's part minification (!1 is 60% shorter than false), part asm.js trickery that's used in lieu of proper type system because guess what, optimizing JIT compilers work much better if they can ensure they're working with integers and not arbitrary objects with unknown properties.
-
(!1 is 60% shorter than false)
How much do you get out of this compared to actually compression? How much when combined with actual compression?
(Semi-serious question. I'm assuming somebody has actually looked at this.)
-
 GitHub - privatenumber/minification-benchmarks: 🏃♂️🏃♀️🏃 JS minification benchmarks: babel-minify, esbuild, terser, uglify-js, swc, google closure compiler, tdewolff/minify
GitHub - privatenumber/minification-benchmarks: 🏃♂️🏃♀️🏃 JS minification benchmarks: babel-minify, esbuild, terser, uglify-js, swc, google closure compiler, tdewolff/minify
🏃♂️🏃♀️🏃 JS minification benchmarks: babel-minify, esbuild, terser, uglify-js, swc, google closure compiler, tdewolff/minify - privatenumber/minification-benchmarks
Minification alone is consistently much worse (~50%) than gzip alone, except for lodash where it's much better. Minification+gzip is consistently much better (~50%) than gzip alone.
-
@Gustav Sounds like that's about code size. What about execution performance?
-
@Gustav Sounds like that's about code size. What about execution performance?
That's the user's problem. Tell them to get a better phone.
-
@PleegWat why would there be a difference in execution performance? It's the same code, just written differently. The JIT output is the same.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.
I very much agree. Spent all day trying to figure out why upgrading some packages makes a site break. OK, one of those packages was Vue, and the other was a significant GIS client, but the result is the stack blows up and the site doesn't work. It's blowing up in code that appears to be trying to deep-clone an object (which might be a map layer?) but the code is all minified and completely inscrutable. And I can't figure out how all our code fits together despite having the sources. I think there's code that is just never being called, code that appears to be installing itself as a singleton in an unrelated class, lots and lots of code just commented out, and other things like that.
I hate it all so much right now. I want to go back to just doing back-end stuff. Or even just doing reviews of organization policy documents.
-
@PleegWat why would there be a difference in execution performance? It's the same code, just written differently. The JIT output is the same.
There could be a bit of performance improvement as some member and variable references remain hash lookups and shorter strings are faster to compare. There could be a bit of performance degradation in case shit like
!1fails to constant-fold. And the minified code should load faster.
-
@Gustav Nice. At least there's a point to the whole mess.
-
-
-
I use it for this project because I need to handle 5MB files being sent directly to AWS without coming to my server (because serverless etc)
Story time. So this project that was recently scratched, it needs users to upload files. Not 5 MB, 5 GB. Or 20 GB, or 50 GB.
Of course the first time around, long ago, this was designed as going through the API server. With a single PUT, no chunking, resuming, ranges or anything similarly fancy was implemented. So first I had to increase the request body limit on the reverse proxy from the default of 100 kB or something like that to 20 GB, and then somewhere around 5 GB, depending on the humidity, phase of the moon and the value of the kilogramagesalad field, the proxy ends up returning a 504 gateway timeout anyway.
So one day I talked to the back-end dev, and we agreed that we can just point the front-end to the blob storage, give it a token and let it upload directly. So he implemented it, then the front-end dev started implementing it – and the architect didn't allow him to apply it for the initial upload, because he noticed a problem with an additional action (thumbnail generation) that has to follow. That would be trivial to fix, but he though it will be a big problem, and the right people just were not available at the critical moment. So for a while we had both methods.
And do you think anybody thought of using DropZone? No,
that would require the front-end devs to pull their heads out of their collective angular asses.it actually seems it does not support Azure blob storage (which has slightly different protocol from S3).
-
That would be trivial to fix, but he though it will be a big problem
IME, it's easy to convince such a manager that something is just an afternoon of dev time. But convincing them it's not going to sit in QA for two months is more difficult.
They are still to be preferred over the 'everything is easy' brand.
-
@TimeBandit said in WTF Bites:
big uploads ... 5MB files

DropZone can handle big uploads just fine in the generic case.
In my case it can also handle 5MB uploads being sent directly to AWS (or Sharepoint if needed) because I can't accept 5MB being sent direct to me because PHP + Lambda has a smaller max upload than that.
-
@Bulb Have to admit that using Blob storage is the one use case I never tried it on - I've used it with S3, with Sharepoint, with direct uploads but not Azure because fuck Azure.
-
@Bulb Have to admit that using Blob storage is the one use case I never tried it on - I've used it with S3, with Sharepoint, with direct uploads but not Azure because fuck Azure.
Well, Maybe™ it can do it. From the documentation I can kinda guess it can be used with S3, because there is a link to some post describing it—in French, so approximately useless to me—but I do not see how to configure it with the others.
Well, if the file is small enough that chunking is not required, I suppose it will just work, because that's a plain PUT everywhere, but in our use-case, chunking is required (blob storage has 5 GB limit for unchunked upload, and 4 GB limit on chunk), because the chunked upload is specific to each storage. And I don't see anything in their documentation describing what the chunking will actually do.
-
@Bulb I'd have to check what our codebase does because I remember running into this in reverse for shoving crap at Shitpoint, because we do it in 320KB increments as per their manual and I remember getting annoyed that I had to manually assemble the Range-bytes header myself.
You can pass in your own function to modify that behaviour, but it's not intuitive if you have anything non-standard. S3 I get because of the vendor stack I have, Shitpoint I had to do myself.
-
-
@HardwareGeek said in WTF Bites:
fuck Azure
I'm not sure even @Tsaukpaetra is that desperate.
We may end up regretting you saying that...
-
I just got an appointment for the local version of the DMV on Friday morning. To everyone's surprise, I booked that online, without calling or faxing anyone. The website even helpfully provided an .ics file to download for the appointment.
So I did that and imported it into my calendar. Later on I checked the calendar on my phone and was a bit surprised. Did I mess up the time? It was supposed to be 8am, but the calendar says 9am.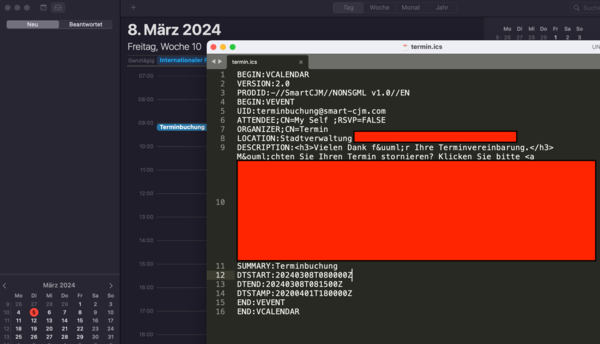
Oh look, the actual event file even says 0800. So Apple's calendar app is too stupid to do its one single job, do time stuff right? Of all the things, the one thing you'd expect not to have date/time bugs?
No, of course not, the file says20240308T080000Z. Roughly 3.5 seconds of googling will tell you theZmeans UTC. Germany is UTC+1. So whatever moron implemented the "let's have a downloadable calendar event" function didn't test it a single. fucking. time.
(And it's not even quite incompetent city administration to blame here, as it's apparently outsourced to an IT firm. Which would be reasonable if they were above crayon-muncher competent.)And what happened on the frist of April 2020 at 6PM UTC (
DTSTAMP)?
All Fools' Day, isn't it?
-
React/Vue/Svelte/Angular bollocks
Note that the bollocks are very much not equal. The biggest bollocks is by far Angular. According to comparison it weighs whopping 563 kB, and that's already minified and compressed. React and Vue are much leaner, the comparison gives 98 kB for React, which appears to be uncompressed, so corresponding to Vue's 91 kB minified uncompressed. And Svelte … well, Svelte does not have any runtime library, but instead compiles the templates to plan JavaScript, making it very lean if you just want a couple of interactive elements.
Also when I saw our front-end codes … the horror, the horror oh my eyes it hurts! In part this is because the apps were not founded with any semblance of a MVC pattern, but instead have the queries to backed spread all over. In part it is because it is completely unnecessarily split to a bunch of separate “libs”, making cross-referencing things way harder than it should be. But the abundance of of files that just contain some boilerplate and two references to some other files is … astounding, and largely directly Angular's fault.
Because of course our company had to choose the biggest bollocks.
-
@Arantor Don't mind him. He's just mad about having to read all those long German words.
Yes. All those long words, like
t,ej,div,m.
Here's a hint, free of charge: Test what your fucking button does and have a look at your server logs, which by now should show that everything gets a400 Bad Request.Did they use a library to make their javascript extra unreadable? I heard tehre is something called
Uglify(as if JavaScript really needed that on top)...
-
Note that the bollocks are very much not equal.
I know. I've written stuff for React, Vue and Angular, I hate them all but I hate Vue the least.
-
@BernieTheBernie that's usually a minification step - no point having long variable names when you can have short ones that make the uncompressed file smaller.
-
And I don't see anything in their documentation describing what the chunking will actually do.
Well, that
chmay be a Cherman pronunciation mistake, so perhaps you'd better think ofjunking.
-
It's part minification (!1 is 60% shorter than false)
I get the intention of minification, but that seems... more like an obfuscator than anything else.
Thankfully, I don't know the intricacies of the JavaScript type trinity, but surely if!1is just as good asfalse, then0is too. That's 50% shorter and makes sense.
-
@topspin !1 is actually false, not just falsy. Means it does survive some type shenanigans further up the chain that the original code might come to rely on.
-
-
@HardwareGeek said in WTF Bites:
makes sense.
Then it can't be valid JS.

Is it trolling if one is merely speaking the truth?
-
That would be trivial to fix, but he though it will be a big problem
IME, it's easy to convince such a manager that something is just an afternoon of dev time. But convincing them it's not going to sit in QA for two months is more difficult.
He's not a manag… actually, he used to be a manager in previous job, but he is now an architect. And the problem is that he thinks he understands the code a lot better than he actually does.
It was fairly simple to test and the QA was part of the team so that wasn't a problem.
-
-
There could be a bit of performance degradation in case shit like
!1fails to constant-fold.In practice this will never happen, because V8 and all its ripoffs have mastered the art of type inference and compile time evaluation. It's the entire reason why asm.js works at all, and it's over a decade old at this point - JITers only got better in that time.
-
@HardwareGeek said in WTF Bites:
fuck Azure
I'm not sure even @Tsaukpaetra is that desperate.

Meh. She seems perfectly adequate.
-
but he is now an architect. And the problem is that he thinks he understands the code a lot better than he actually does.
I'm in this scenario, except it kinda goes the other way. The architect became the CTO, hasn't done any code or even looked at the codebase in years, but still thinks he knows the One True Way.
-
I hate web devs. All of them. They're all a bunch of shit-slinging morons.I thought we were friends.
You can hate friends.
-
@HardwareGeek said in WTF Bites:
He's not a man … he is now an architect.
Quote not really Out of Context

-
-
@Bulb I'd have to check what our codebase does because I remember running into this in reverse for shoving crap at Shitpoint, because we do it in 320KB increments as per their manual and I remember getting annoyed that I had to manually assemble the Range-bytes header myself.
You can pass in your own function to modify that behaviour, but it's not intuitive if you have anything non-standard. S3 I get because of the vendor stack I have, Shitpoint I had to do myself.
In case this helps, @Bulb, and it might not - I never touched S3 directly for this…
So there is a params option in DZ configuration, you pass a function to it that accepts (files, xhr, chunk)
files is an array of file objects, xhr is the XmlHttpRequest you’re going to send the chunk with, and chunk is an object representing the chunk you’re going to send, if you’re going to send a chunk.
Since I needed to pass in a proper Content-Range header, and pass the content in the body rather than multipart, which is probably what you’ll end up needing to do, here’s what I have for it:
(CHUNK_SIZE is previously declared as a const reflecting the size of chunk you send per PUT)
params: function(files, xhr, chunk) { if (chunk) { const chunk_start = (chunk.index * CHUNK_SIZE); xhr.setRequestHeader('Content-Range', 'bytes ' + chunk_start + '-' + (chunk_start + chunk.dataBlock.data.size - 1) + '/' + files[0].size); var _send = xhr.send; xhr.send = function() { _send.call(xhr, chunk.dataBlock.data); }; } else { // If not chunking, still need to send it in the raw body, just without a Content-Range header var _send = xhr.send; xhr.send = function() { _send.call(xhr, files[0]); }; }I’m explicitly only targeting a single file here, and pulling the necessary bollocks to overload the XmlHttpRequest send method to send it how it needs to be sent. Annoying but there you go.
I mean, really, having to munge the XHR like this really should be considered a WTF.
-
I mean, really, having to munge the XHR like this really should be considered a WTF.
Overloading
sendlike that? Awful. There must be a better way! (No idea what it is.)
-
@Arantor That's way lower level than called for here. There is a client library for the Azure blobs that takes a
File(or otherBlobI think) and does the chunking and retrying and shit. And if you didn't want to use it, the above still wouldn't cut it, because the way chunked upload works in azure blobs is that you first put the chunks (I don't remember which side makes up the IDs) and then you post a request to the final resource URL listing the chunks you want to assemble as the content. So a per-chunk callback isn't enough, you need a finalization step.