WTF Bites
-
I just love how
gitcan allow one developer to completely screw an entire group.We use LFS. Newby doesn't install LFS. Pushes PR that builds, so it gets successfully merged. All developers that have LFS are now screwed.
(Saw slack message from last night - guess I'm not going to rebase/merge for a while...)
Can you elaborate what happens, please, so I know what to look out for?
A message like "Encountered 1 file(s) that should have been pointers, but weren't: <list of files>"
Edit: Also, after merging/rebasing into a clean branch (for instance, your local copy of the main branch), you'll end up with a file that's modified. The only workaround I found (I'm sure there's some super wonky git cmd, but
 that - and
that - and  ) was to
) was to git reset HEAD^and then revert all those changes (assuming the bad file is in the last change).
-
I just love how
gitcan allow one developer to completely screw an entire group.We use LFS. Newby doesn't install LFS. Pushes PR that builds, so it gets successfully merged. All developers that have LFS are now screwed.
(Saw slack message from last night - guess I'm not going to rebase/merge for a while...)
What's LFS?
-
-
@boomzilla said in WTF Bites:
What's LFS?
It makes git work "better" with binary files.
Augh. So, branch protections may indeed do nothing. Well, unjust harm is still at least harm.
-
I just love how
gitcan allow one developer to completely screw an entire group.We use LFS. Newby doesn't install LFS. Pushes PR that builds, so it gets successfully merged. All developers that have LFS are now screwed.
(Saw slack message from last night - guess I'm not going to rebase/merge for a while...)
It's more of a LFS issue than a Git one, though it's true that all this clean&smudge business is not half-baked, it's completely raw.
I am still surprised it did build though. Why didn't LFS fail on the build server too?
-
@boomzilla said in WTF Bites:
What's LFS?
It makes git work "better" with binary files.
That's wrong. Git works just fine with binary files. It treats all files as binary anyway.
LFS is for huge files. If your files are not over a gigabyte, LFS is the wrong tool for you. And if they are over a gigabyte, do you actually need them associated with git and checked out on every developer machine? And do they change so much that this kludge really beats updating reference to the file server where the build shall get them?
-
-
@dcon If you fire them, yeah.
-
And do they change so much
Do UX designers ever stop changing images?
Do UX designers have a lot of images that are gigabytes in size each?
If not, just commit them in git and call it a fortnight and throw the LFS trash in the trash where it belongs. Images in git are perfectly fine. You can't diff them, but LFS won't help you with that. A gigabyte or two of them in total is no deal either. It is only with individual huge files that you get problems with memory consumption.
We had all UI graphics in git in the previous job. It weighed maybe ¾ GB, but in a huge set of smallish files a couple of kilobytes each, and was perfectly OK except the number of files was making status and related operations a bit slow on Windows—maybe five seconds with hot cache on Windows while on Linux it was still effectively immediate; with cold cache half a minute everywhere—which you can work around by
git update-index --assume-unchanged directorywhen you are not working with that part of the tree. But that's number of files, LFS wouldn't help with that either.
-
You can't diff them, but LFS won't help you with that.
Some people store uncompressed images in the VCS to make better use of the delta compression (since compressed bitstream may change a lot for small changes in the underlying data). Still no useful diffs, of course.
-
It weighed maybe ¾ GB, but in a huge set of smallish files a couple of kilobytes each
I assumed the point of LFS was to have the local size of the repository not unneccesarily blow up. Because, really, you don't need to keep the history of binary files in your local repo. I have no idea how that affects the speed of status operations etc. though.
-
Still no useful diffs, of course.
In theory, getting diffs for them should be possible (provided you're using sensible formats in the first place). But nobody's solved how to actually present them so far as I'm aware; it's a (genuine) GUI problem, not a data problem per se.
 's rant about GUIs being important would apply here, and correctly so.
's rant about GUIs being important would apply here, and correctly so.
-
You can't diff them, but LFS won't help you with that.
Some people store uncompressed images in the VCS to make better use of the delta compression (since compressed bitstream may change a lot for small changes in the underlying data). Still no useful diffs, of course.
There you also have a problem if someone does not have the clean+smudge filters installed, but with cautious application (clean only re“compresses” with “store” so the format is still valid) nothing should really break and you should only end up with unnecessarily big binaries and/or still compressed files checked in.
-
you should only end up with unnecessarily big binaries and/or still compressed files checked in
Version control systems need the uncompressed data. Compressing the data for final delivery can easily be part of doing a build, of course.
-
Still no useful diffs, of course.
In theory, getting diffs for them should be possible (provided you're using sensible formats in the first place). But nobody's solved how to actually present them so far as I'm aware; it's a (genuine) GUI problem, not a data problem per se.
's rant about GUIs being important would apply here, and correctly so.Git has pluggable diff and merge, so someone could implement a diffing tool for images. The question is more what kinds of displays would be actually useful.
(and if desired, textual version can be presented using AAlib or libcaca (or here))
-
you should only end up with unnecessarily big binaries and/or still compressed files checked in
Version control systems need the uncompressed data. Compressing the data for final delivery can easily be part of doing a build, of course.
It basically is the reason why git has the
cleanandsmudgefilters, but the feature is incomplete in two ways:- There is no utility for deploying the configuration when or before you clone the repository that uses them.
- If they are not defined, instead of loudly complaining and telling you to define them, git will silently ignore them, which is how someone could use LFS-enabled repository without LFS in the first place.
-
Some people store uncompressed images in the VCS to make better use of the delta compression (since compressed bitstream may change a lot for small changes in the underlying data).
Kinda sucks when the difference between baked+uncompressed data is 20x and more (example: original ~3.5GB, baked ~150MB, and here ~2GB of the originals consists of compressed PNG and JPEG images). Consuming uncompressed data would additionally seriously affect load times.
Compression also isn't that fast (10s of minutes to hours), so doing that as part of a local build step would be ... inconvenient.
-
It basically is the reason why git has the
cleanandsmudgefilters, but the feature is incomplete in two ways:- There is no utility for deploying the configuration when or before you clone the repository that uses them.
- If they are not defined, instead of loudly complaining and telling you to define them, git will silently ignore them, which is how someone could use LFS-enabled repository without LFS in the first place.
We have standard scripts for setting up repositories; run the script and everything gets set up right. (OTOH, we don't have much in the way of images to worry about; different application domain.)
-
Some people store uncompressed images in the VCS to make better use of the delta compression (since compressed bitstream may change a lot for small changes in the underlying data).
Kinda sucks when the difference between baked+uncompressed data is 20x and more (example: original ~3.5GB, baked ~150MB, and here ~2GB of the originals consists of compressed PNG and JPEG images). Consuming uncompressed data would additionally seriously affect load times.
Compression also isn't that fast (10s of minutes to hours), so doing that as part of a local build step would be ... inconvenient.
The trick is that the files are not lying around uncompressed anywhere. You put it in the versioned directory compressed, the
cleanfilter will decompress it, git will take advantage of the possibility of delta-compression, and compress it again, because it stores everything deflated. And when you check it out, thesmudgefilter will convert it to the compressed form again. So you'll only be doing the recompression on commit and on update for the files that have changed.The downside is that it uses the same
cleanandsmudgefilters LFS does, so you still need to make sure everybody has their systems set up correctly. But if not, and done properly, it will only reduce efficiency, but shouldn't cause any hard failures.
-
You put it in the versioned directory compressed, the clean filter will decompress it, git will take advantage of the possibility of delta-compression, and compress it again, because it stores everything deflated. And when you check it out, the smudge filter will convert it to the compressed form again. So you'll only be doing the recompression on commit and on update for the files that have changed.
Ok, fair. That's a bit better, but still doesn't really deal well with long compression/baking times.
E.g., BCn, ASTC and whatnot compression can easily take in the order of minutes per image. Even with relatively irregular updates, that's still pretty annoying. Baking the other data also takes a few minutes for larger data sets. (Non-standard file formats will additionally need the software to build those to be available, which is a bit annoying if that's part of the repository in question.)
-
E.g., BCn, ASTC and whatnot compression can easily take in the order of minutes per image.
Sounds like there's a reason for having the assets in a separate repository to the code and then doing an overnight bake task. Most of the time, the assets and code aren't going to be that intertwined that that'd be a problem.
-
Trying to transfer my safed passwords from Firefox to another computer. Without using Mozilla "Sync", of course.
Should be a 3 minute task: export, copy file, import. Go toabout:logins, click the 3 dots that mandatorily hide all features and export the passwords to a file. Great, just as planned. Open the same page on different computer and try to select the corresponding "import" function. But wait, there's only "Import from a different browser"?
Try that and of course that only let's me select Safari.Wait, if there's an export to file function, then surely there's got to be an import from file function, right?

This feature is currently disabled by default, due to performance issues (bug 1701660). To enable it, see below.
And on the bug page:
Importing a CSV file with 1000 logins takes between 3 to 10 minutes.
So you did the old Shlemiel during CSV import and instead of fixing the performance bug decided to disable the feature until it's fixed???
Are you fucking retarded? I'd rather have a slow import than no import at all.
Enabled the stupid option and the oh-so-dangerous import feature took roughly 0 seconds to complete.
-
-
You put it in the versioned directory compressed, the clean filter will decompress it, git will take advantage of the possibility of delta-compression, and compress it again, because it stores everything deflated. And when you check it out, the smudge filter will convert it to the compressed form again. So you'll only be doing the recompression on commit and on update for the files that have changed.
Ok, fair. That's a bit better, but still doesn't really deal well with long compression/baking times.
E.g., BCn, ASTC and whatnot compression can easily take in the order of minutes per image. Even with relatively irregular updates, that's still pretty annoying. Baking the other data also takes a few minutes for larger data sets. (Non-standard file formats will additionally need the software to build those to be available, which is a bit annoying if that's part of the repository in question.)
Image baking is part of the build? Congratulation on avoiding an Enterprise DAM system.
-
I assumed the point of LFS was to have the local size of the repository not unneccesarily blow up.
This can actually become an issue. Before we converted to LFS, I remember a couple of people running out of space. (Like corporate overlords ever like to give lowly developers the actual resources they need...)
Git has pluggable diff and merge, so someone could implement a diffing tool for images. The question is more what kinds of displays would be actually useful.
We use Bitbucket - it does actually show both images in the code review.
-
The question is more what kinds of displays would be actually useful.
Most likely answer seems to be
subtract, for image diffing.
-
Importing a CSV file with 1000 logins takes between 3 to 10 minutes.
I'm spoilt for choice in
 selection here. How are they reducing a modern computer to running like it is a mouldy potato? And why are people having a thousand logins in the first place?
selection here. How are they reducing a modern computer to running like it is a mouldy potato? And why are people having a thousand logins in the first place?
-
@dkf VMs per session running this new industry hotness called SwampySearch
-
Importing a CSV file with 1000 logins takes between 3 to 10 minutes.
I'm spoilt for choice in
selection here. How are they reducing a modern computer to running like it is a mouldy potato?As mentioned, I suspect the O(n^2) Shlemiel. Although I'm wondering if even that would be faster for "only" 1000 entries. Maybe they managed to go O(n^3).
Actually, wasn't there a gaming thread recently where a benign use of
sscanfcaused quadratic behavior because the C library was being retarded? Maybe it's not even too stupid on their side.And why are people having a thousand logins in the first place?
Probably amassed over many years. Also, every stupid shit site wants a login nowadays.
-
And why are people having a thousand logins in the first place?
Probably amassed over many years. Also, every stupid shit site wants a login nowadays.
Spread over my various password databases (yes, that's a separate
on my part) but deduplicated, I've likely got 1k logins.Job searches, especially back before everyone started to use unified services, are really bad that way. Each and every company wants a separate login, and when you apply to 10 a day...
-
As mentioned, I suspect the O(n^2) Shlemiel. Although I'm wondering if even that would be faster for "only" 1000 entries. Maybe they managed to go O(n^3).
Yeah. 1000^2 still isn't that much. To make it run that slow with that few (relatively speaking) elements, they had to dumb it up good.
-
I clicked New Query.
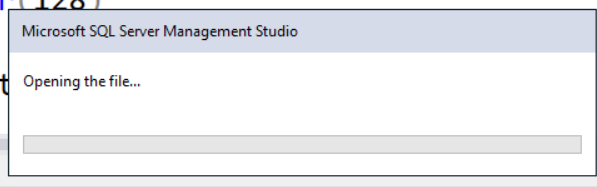
 What file?
What file?Edit: It's been opening the "New Query" file for several minutes now (and this is a modal popup). I'm going to have to call the Task Manager.

-
I clicked New Query.
What file?Edit: It's been opening the "New Query" file for several minutes now (and this is a modal popup). I'm going to have to call the Task Manager.
It's a new feature of Management Studio. It creates new query based on everything you ever wrote.
Powered by AI.
-
@MrL just use their command-line client, then
-
-
Fuck Zoom. Again.
So, until recently(tm), Zoom's been working. However, recently, it has started losing audio output. Both with the in-browser version and the dedicated client. Other tabs in the browser are happy to make noises, i.e. Discord or Teams or indeed a Youtube video in the background. Just that Zoom refuses to do anything.
The dedicated client isn't much better. It'll work if I quit out of the browser(s), but as soon as I start up either Chromium or Firefox, it will lose audio again. Quitting the browser(s) and changing+reselecting the audio output in the dedicated client makes it work again.
Both browsers are happy to coexist with no problems and do audio concurrently, and playing via other additional sources at the same works as well.
Wtf, yo.
-
 Virginia just sent out an "emergency" message to tell us that anyone 16 and over can get vaccinated. Moment of panic that the weather was about to get violent.
Virginia just sent out an "emergency" message to tell us that anyone 16 and over can get vaccinated. Moment of panic that the weather was about to get violent.
-
@boomzilla VA would have been my last guess, their tourism board had convinced me never to look for you there.
-
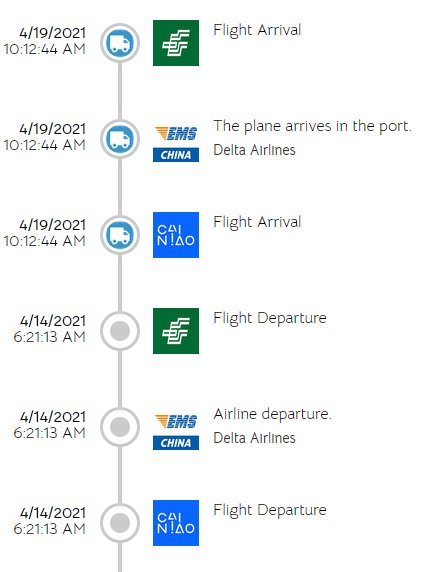
Did China send my package on the plane from Manifest?
-
Would be so cool if everyone normalized these pesky data leaks, says data-leaking Facebook in leaked memo

Blundering mouthpiece sent arrogant line to journalist by accident
-
@Zerosquare To be fair, by “normalize” they “only” mean to make it look normal by comparing it to leaks from other companies, not make sure it happens regularly.
-
-
they “only” mean to make it look normal by comparing it to leaks from other companies
Because other companies regularly have worse leaks that affect more than 500 million people. Yeah, sure.
-
-
I am trying to debug a piece of lua. I have one log message, then an
if (bit32.band(bit32.rshift(requestId), 0xff) ~= respAddr or bit32.band(bit32.rshift(responseId), 0xff) ~= reqAddr) thenwith just another log message in the body, and immediately third log message. The first log message prints, the other two don't.
… of course there is an error in that condition, but it does not say a ň, it just dies.
(bonus
: the ~=operator)
-
@Bulb uh. is that the Elvis
~=, the approximating~=, or the regex-matching~=?
-
@Gribnit Neither, of course. Lua is a
 .
.
-
bit32.rshift
According to the manual
there should be 2 parameters.
-
@BernieTheBernie is there a default value for the second? J Random Lua Interpreter may of course, be bork too...
-
@BernieTheBernie Yup. But when there are not, it just throws an exception and exception handling in Lua sucks and the sample code I used for the test was particularly retarted about it.
