@rad131304 said:Edit: To create a self-signed script for codesigning:Wait, do you need to sign the self-signed script for self-signing scripts?
Filed Under: Yo Dawg
Do'h - i meant cert.
@rad131304 said:Edit: To create a self-signed script for codesigning:Wait, do you need to sign the self-signed script for self-signing scripts?
Filed Under: Yo Dawg
...so what is this about?Connecting to remote server failed with the following error message : The client cannot connect to the destination specified in the request. Verify that the service on the destination is running and is accepting requests. Consult the logs and documentation for the WS-Management service running on the destination, most commonly IIS or WinRM. If the destination is the WinRM service, run the following command on the destination to analyze and configure the WinRM service: "winrm quickconfig". For more information, see the about_Remote_Troubleshooting Help topic. + CategoryInfo : OpenError: (System.Manageme....RemoteRunspace:RemoteRunspace) [], PSRemotingTransportException + FullyQualifiedErrorId : PSSessionOpenFailedThis doesn't seem to be permissions...
Looks like WS-Management service isn't running the server you're trying to talk to.
Windows Remote Management (WS-Management)
It's set to manual start by default; plus it's probably not configured properly so it may not start for you. You said these were web servers, and, by default, the service listens to port 80 IIRC.
```
$exe = "C:\Program Files\TortoiseSVN\bin\svn.exe";
&$exe switch "$to" "$workingCopy" --username [redacted] --password [redacted] --no-auth-cache --non-interactive --trust-server-certFrom inside Script 2.</blockquote> Maybe try using Invoke-Command instead? & is an alias for Invoke-Expression which might not be passing Session information.
but that is being run from a script being run with Invoke-Command.... should it matter?
I have no idea, unfortunately.
@rad131304 said:Client devices could be anything - right now laptops, but we need to support mobile devices in the future.Can you guarantee they all speak TCP/IP and HTML? "Mobile devices" is still pretty goddamned vague.
You have to set SOME kind of limit here.
All our devices will transmit json messages over HTTPS. They will all be communicating to the same API.
Our issue is how do we deal with a corrupt data set when the server doesn't know what's actually in the data? Generally it's just syncing an encrypted blob.
Should we just force devices to check for updates before any data modifications are allowed?
"highly unlikely" means your solution can be inefficient, it doesn't mean the solution can be non-existent.
I'm not sure I understand this statement.
Since they're all communicating over HTTPS, presumably with a valid cert, why not ditch the client-side encryption altogether? The transmissions back-and-forth will be secure, and now you can store real diffs and the server can do some kind of data consistency checking for you.
The data we are transiting is PII, and we would prefer that, in the event of our compromise, any data acquired to be difficult to turn into something usable.
@rad131304 said:If we are compromised, those storage encryption keys can be taken when the data is taken.If you are compromised, the client's encryption keys can be taken as well. If you're compromised, the game is basically up.
We don't hold those.
If the thief can crack Bitlocker (or equivalent), they deserve access to the data. You're roughly 47,324,342 times more likely to be compromised via social engineering.
This is actually the biggest concern and why we want client-side encryption. If one of our (meaning the company's) employees who has access to the servers gets compromised through some sort of social engineering attack, we'd rather that failure not leak our client's data. If the compromised employee can lead to privileged, that's game over in your encryption scenario.
@rad131304 said:What? People make mistakes programming APIs and end up giving users access to data they're not supposed to have all the time. Remember AT&T when they leaked Apple IMEIs? Or any time you could just increment the id of a query string by 1 to get to the next user's account?You're already sharing the encryption key among ground of "client devices", so that any one of them can decrypt the messages of any other of them. I don't see the practical difference between that and not doing client-side encryption at all, risk-wise.
I think you've misunderstood the architecture. Each user is only authorized to have access to their own data. Though there are multiple users, there should not be a way for user B to ever see user A's data. Though a user may wish to view or change their own data on multiple devices, we have no need for visibility into it, and we would prefer to provide our users with assurances that a compromise of the servers does not leak data in an unencrypted form.
Listen, I tried to apologize for not giving you enough information; criticism of our business requirements is unhelpful.
You do realize that the Chrome stable branch is already at 44, right?
All I was saying is that the problem isn't likely to be the NPAPI sunset since the problem should have cropped up in Chrome 42 when they made the last changes to NPAPI support according to the roadmap.
@Maciejasjmj said:@Yamikuronue said:Traveller should be injected as well.With a mechanic? Kinky stuff thread, etc...
Depends on whether or not
TravellerimplementsHeroinAddict. That's some dependency injection!
Don't you mean implements ISucks? In DI, Traveler would just accept Heroin - though Traveler would probably need to implement IAddict<Heroin> in order for that to work.
Edit: now that I think about it, Traveler should accept IEnumerable<ITolerance> - you'd never do dependency injection for Heroin since the drug itself is just a visitor.
for future reference, a great place to find out browser support:
We've successfully set up the proxy the relevant portion of the proxy.conf file is below
<VirtualHost>
<IfModlue>
SSLProxyEngine on
SSLProxyProtocol +SSLv3 +TLSv1
SSLProxyCipherSuite "SSLv3 TLSv1 LOW MEDIUM HIGH"
ProxyPass / balancer://example
</IfModlue>
</VirtualHost>
<Proxy balancer://example>
BalancerMember https://example.com
</Proxy>
EDIT: also @rc4 was a great help over PM regarding this issue. Their help was instrumental in us correcting the problem.
EDIT2:
We had 2 issues, first was the lack of the SSLProxy* directives; second was that we had originally planned to do SSL stripping at the proxy and we discovered that a dll on the host was configured to require an SSL connection to function properly. When we originally wrote the balancer, we directed it to http instead of https (and the host had a hard-coded https redirect that we were not allowed to change), which caused a redirect loop resulting in a 500 error.
@cabrito I'm fine with build on every push; I just wanted CI.
Bug: post length is limited during Editing
Expected: inform the user when the post length is reached and prevent them from typing anymore
Actual: Post editor continues to allow characters beyond the post limit, but the preview pane stops updating. When Save is clicked, the UI appears to save however it does not occur successfully. On subsequent attempts to edit the post, the UI asks if changes should or should not be abandoned.
Repro: http://what.thedailywtf.com/t/markdown-tutorial/382
@Polygeekery I'm usually not either, but 6.5 only had "container visibility" by extension. My home farm was acting like a schizophrenic gerbil regarding stats, and I finally decided to rebuild it a week ago, and saw 7 was out, so I just said "fuck it" and rebuilt on it.
Edit: Everything spun down and up like a dream, which was awesome.
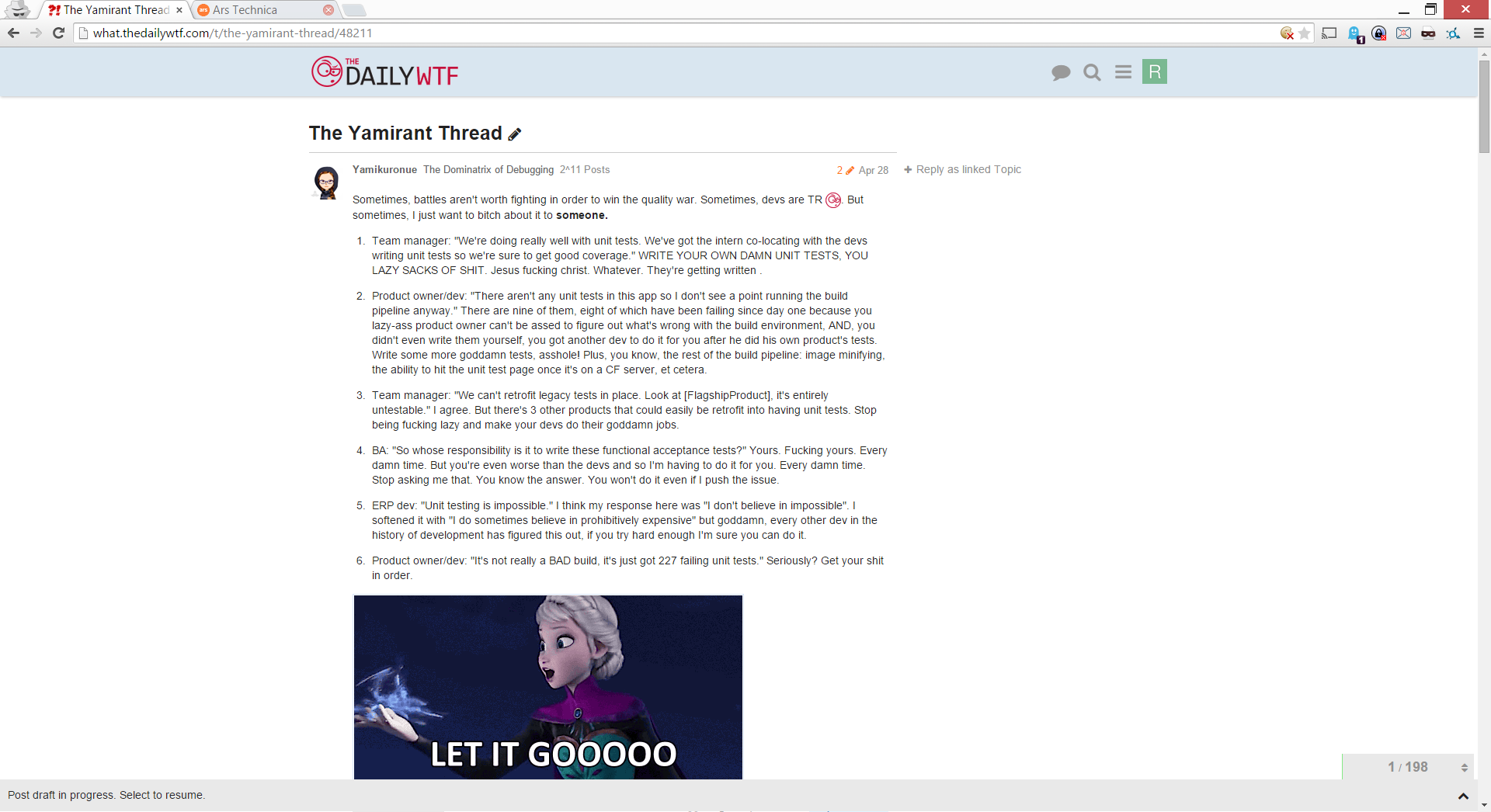
##Experienced:
If an anonymous user scrolls down in a thread, the Sign Up button disappears
##Expected:
Sign Up button should remain visible
Top of Thread:
After Scroll:
##Repro:
##Environment:
Browser: Chrome 41
OS: Windows 8.1 64bit
Scrolling in topics seems to cause discourse to request the favicon over and over and over:
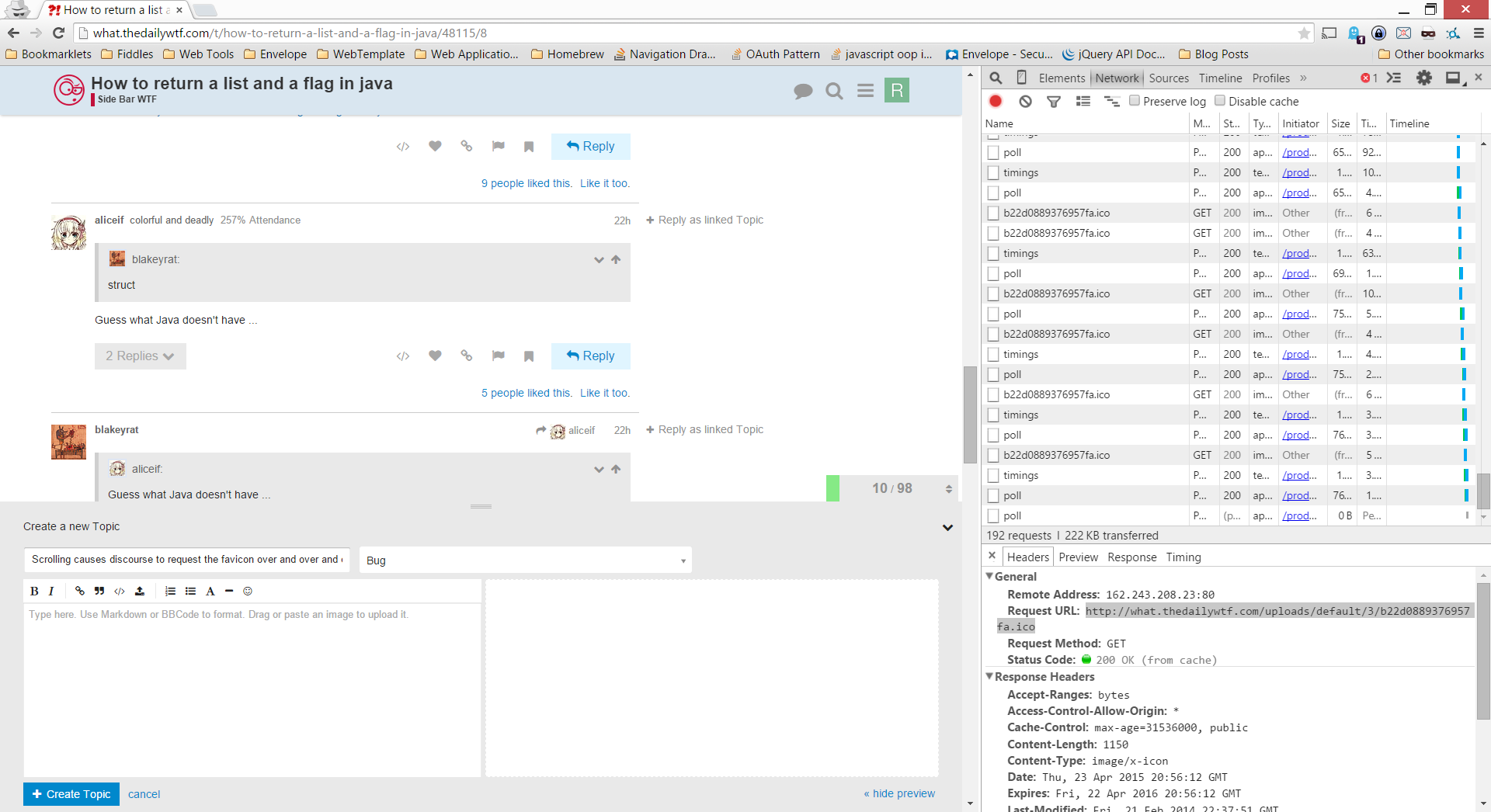
It gets loaded from the device cache, so it's not a bad hit on data, but it seems kind of odd to constantly reload it like that.
EDIT: This has been nailed down to the URL change after scroll instigating the browser to re-request the favicon. I have no idea if symlinking the favicion as favicion.ico instead of setting the relative link in the HTML would solve the problem, but it might help. Browsers might not obey your request to cache the file.
##Solution (On Chrome):
It's definitely related to the icon link in the HTML on Chrome. It can be fixed by somehow putting the favicon at favicon.ico, e.g. symlink the favicon file to protocol://domain.tld/favicon.ico.
Test bad HTML:
<!DOCTYPE html>
<html>
<head>
<link rel="icon" href="favicon/favicon.ico" />
</head>
<body>
<script>
var i = 0;
var url = window.location;
setInterval(function() {
history.replaceState(window.location + "#" + i++);
console.info(window.location + "#" + i);
}, 1000);
</script>
</body>
</html>
Test good HTML:
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<script>
var i = 0;
var url = window.location;
setInterval(function() {
history.replaceState(window.location + "#" + i++);
console.info(window.location + "#" + i);
}, 1000);
</script>
</body>
</html>
You'll have to supply your own favicon, sorry.
Some topics in Meta have no categories associated with them. I have no idea what would even cause this ....
See:
https://what.thedailywtf.com/t/thats-below-the-belt-apple/49572/23
Only one reply happened, but two are counted because of nested quoting.
Did you even read the OP?
I was able to edit in IE but not Chrome.
Yes, Ghostery, and HTTPS Everywhere in incognito w/ some pretty draconian cookie rules. Something in that is probably the problem, though it's not been an issue previously since I've had this setup since before Discourse was launched.
It might be a side effect of constantly changing the URL ....
EDIT: Yeah that looks like the issue - the Referer header is different in each request, causing the favicon "request". Thankfully it looks like Chrome is smart enough not to actually send that request, it just lists it as a 200 (probably because it's not even bothering to ask if it was modified from the server so 304 would be inappropriate).
EDIT2: Yeah, fiddler isn't showing the requests, so they're not being made, but only because Chrome is being smart. I wonder how other browsers behave.
What happens when you click on Yamirant? Where do you go?
It shows the topic, but there's no category information
Agreed.
It's instigated by the call to Backburner.end() in ember.prod line 570.
-2; lacks bellbottoms and acid.
EXPECTED:
When typing, and the line wraps beyond the end of the screen, that line should come int o view.
ACTUAL:
When typing, and the line wraps beyond the end of the screen, the cursor drops below the screen in the pane.
Browser: Chrome 49 (Porn Mode)
OS: Windows 7 x64
SCREENSHOT:
that is.... ugly.but, i'm with spiny norman, it's a parser bug
the spec:A comment declaration starts with <!, followed by zero or more comments, followed by >. A comment starts and ends with "--", and does not contain any occurrence of "--".so yes, it's all comment until the
>
Well, it probably gets parsed wrong, but, until the >, it's all comment. The bug is that what is between the first -- and the > should probably just be discarded and probably is being included in the comment, but that's hardly an important bug. I'm not sure it doesn't fall into undefined behavior though. Could it just be included as a second comment and be valid?
Edit: 
Filed Under: Why isn't that :ninja:??
He typo'd 104. Probably <abbr title="can't be arsed to find the thread where he keeps getting cut, copy and paste mixed up">forgot where the 0 and 1 keys were</abbr>.
Maybe he just forgot to turn numlock on while using the number pad?
@rad131304 said:So, you're telling me the cake is a lie?Get out of the timepod.
But I don't want to do any more testing today!
I'm betting your disk is now being viewed as "removable" by the OS. IIRC this is a firmware thing on the disk.
Try using: http://www.partition-tool.com/easeus-partition-manager/removable-device-partitioning.htm
Edit: note the link is about resizing partitions, but that's because the "removable" flag prevents resizing in windows, so it was the best place to go looking for software that could fool with that flag.
And it even offered me the option to not purge all the things!
I'm mostly just shocked I didn't need to do a full nuke and pave ... brave new world of Windows I guess? I was doing precautionary reformats even in Windows 8.
@Tsaukpaetra Removing webroot is easy in Safe Mode ... but, somehow, impossible - from a UI sense - if you don't hold the original user* and password* that installed the crapware. It's my first time purging this program from OOBE (or SysPrep if you prefer, or whatever, fuck off @blakeyrat ) - if I could escape the boot loop and force a full, normal boot, I could actually fix the problem ....
* held on their website, because raisins
cc4f9c96-ed6f-416f-b8ae-86af07ee27a8
e2e0431e-3ee4-4b6a-a92b-1bc5acefbaf6
99f9a7a2-b80a-4582-82bd-2a2c9662d6ef
... I can do this all day ...
Many of these are actually antithetical to TDWTF. WTF.
Closed: Duplicate of: Is the FAQ a joke?
You could probably implement this through jQuery ... use the page onload event to inject another li element - possibly by cloning the search button - and just modify the onclick to fire the ? keypress event oh and use the fontawesome icon I referenced "fa-keyboard-o".
Damn, I completely forgot about that when I posted in another topic. I've even seen it mentioned, but it is so unintuitive to me that I never even thought of it. I was going to say "typing random non-control characters to navigate text is completely unintuitive," but vi. Doing that in a web browser, however, is something I have never done, and is unexpected behavior, at least in my experience.
I never said that I wanted to use them - I said they were not discoverable (mostly because it really does feel like unexpected behavior) and that adding the option would make them discoverable.
Bug: Expand button does not work properly
Expected: Expand button on quote should make it longer, not shorter
Actual: Expand button shrinks quote size
Repro: http://what.thedailywtf.com/t/poll-infinite-scrolling/364/20
True. @Buddy seems to be advocating for a 1984esque world.
A post is not a thought. A post is an object that exists in our shared reality. You are not responsible for the creation of posts that you did not create. You are responsible for the continued existence of a post exactly as much as you are able to influence its continued existence.According to this logic, everyone who could have killed Hitler before he became fuhrer is equally responsible for the holocaust. That is an absurd position, and rather offensive as well.
Not to mention, you are now demanding that we delve into every possible meaning of every post to determine if there is something potentially offensive, and remove any post that could be offensive. Guess what? <s>Some</s> Many of the posts here can be viewed as attempts to give offense. As long as no-one goes over the line, we aren't going to begin policing based on whether some potential new blood can take the heat or not.
In fact, I did not intentionally offend you, and if any offence was taken, I'm afraid that's rather your problem than mine.This. More often than not, in order for someone to be offended, that person must choose to be offended. As I've already pointed out, many posts here can be viewed as attempts to give offense, but offense is usually not taken because the target chooses to not take offense.
Did it really take 391 posts on this topic to go Godwin? Or did I miss something earlier?
For private categories/threads, what about something like eye-slash from fontawesome?
Eye Slash icon in the Solid style. Make a bold statement in small sizes.. Available now in Font Awesome 6.
I'm not going over to meta.d to suggest it, but it seems like a better icon than a lock to me since it indicates non-visibility ....
:shockedface
I mean, why should we use icons that have semantic meaning, when everything can just be a quintuple entendre? Isn't that what people WANT from the internet?
As for the intentional bugs, infiniscroll (as one example) isn't limited to this forum. Sites like LinkedIn and Facebook who have millions of subscribers use this "feature" too, so I don't see us realistically convincing Jeff to stop using it - especially if his target customer audience are PHBs who want the look and feel of a Facebook or LinkedIn, not "old 90's paging style" (even though it works better).
Except Facebook's scroll bar, AFAICT, actually works in telling me where I am in the feed; thought I don't think you ever jump to the middle of the scroll like in a forum, but the unloading of posts that were loaded is not a feature no matter what Jeff says.
Not that you in particular were raging, but others definitely have.I disagree about that, too. It does work. Just not how you think it should. Some people just want to complain. I imagine if it worked the way these guys think it should, their complaints would reverse.
The fucking scrollbar guesses wrong and then it goddamned pauses while more stuff is loaded or unloaded. Just let the browser do its job and scroll based on what's there.
OK, that's an exaggeration, but probably not by too much.
Fair enough; though it seems to behave in a strange enough way that it was a significant topic of discussion here for a while. Though the problems people complained about are conflated with unloading of DOM elements (which IMO is too aggressive), which is probably the real issue. IIRC we relaxed DOM unloading and things got a bit better. Like I said, I don't have good solution.
In most cases, but that falls apart when you start doing a lot of heavy lifting client-side. (Like Discourse) If you are still serving the same shit, but just setting CSS rules as to what you will display, it may not be good enough. (Like Discourse)If you use screen width in order to decide whether to send mobile or desktop versions, then I would agree that it is good enough.
Until someone with raspbipan decides to browse your site and it shits a brick.
 Can I use... Support tables for HTML5, CSS3, etc
Can I use... Support tables for HTML5, CSS3, etc