python might have some other reasons for yielding faster resultsThat's actually really interesting, and adding
LC_ALL=C helps a great deal. sort -u takes 3.8 seconds and sort takes 5.8 seconds, which argues against my earlier hypothesis.
Python still wins though, by more than 3x.
(The numbers above are with cat demo | sort rather than sort demo because they are actually faster. sort demo takes 5.2 seconds, and sort -u demo takes 6.2 seconds. So fun?)
The question is, how else to grab unique values from a set. ... (which makes sense, but may be tough to implement) ...Wut? I showed you how to do it in two lines including an
import! And it's demonstrably faster by several times, even after Python instead of C. And that's with next to zero effort on my part. Would a balanced tree be better? What about an array-based heap? Sorted array? How must faster could you get it ? Who knows!
sort -u does exactly what sort | uniq does, assuming you don't have any special sorting comparison function. That's how it's defined.That's... kind of my point. That's the WTF. One of the main reasons that the Unix approach of composing a bunch of small tools isn't always the right thing to do is because of performance. In this case, if I issue
sort | uniq then sort can't know what the reader is going to do and has to sort. But sort -u has that knowledge. It can optimize! Why else put the -u switch into sort in the first place if I might as well just pipe it into uniq? Because it saves three characters?
And this ignores the fact that I would be mildly surprised if uniq was used (intentionally) without a sorted input (or other knowledge that if there are duplicates then they'll be adjacent), which means I'm not talking about an edge case but the common use case of uniquifying a file.

 Hollywood accounting - Wikipedia
Hollywood accounting - Wikipedia



 Town Of Davenport, Iowa Descends Into Hell Following Gay Marriage Ceremony
Town Of Davenport, Iowa Descends Into Hell Following Gay Marriage Ceremony

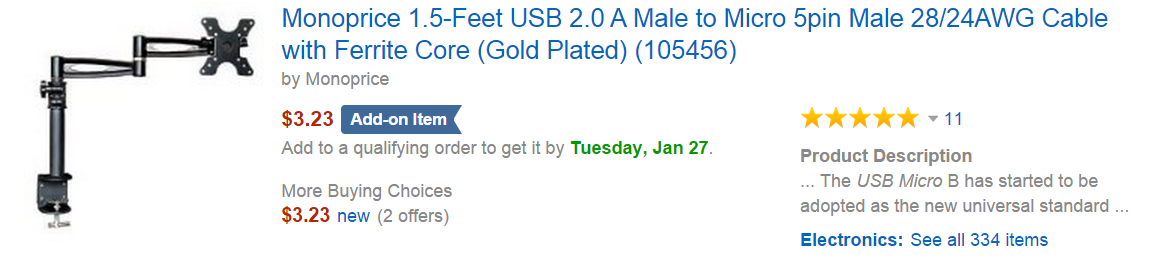
 Amazon.com
Amazon.com
{kind=link}