So I decided to try to update part of my toolchain...
-
Question for the (G)UID-file people here... are the IDs supposed to be globally unique or just locally (= file system)? The former will introduce a ton of fun, in the DF sense. What happens if somebody maliciously (or otherwise) distributes a file that has the same ID as another already existing file? What happens if User A has a file with ID X to which User B has no access, but User B now introduces a file with the same ID?
If the IDs aren't globally unique, then I don't see why they would help anybody. An application will not be able to load a file by ID, because it no longer knows the IDs once they've been transferred to a different system.
You could of course go all Xanadu on our asses and require that the GUID is strictly tied to the contents of the file, and only two files with identical contents get to have the same ID. Not sure how you'd enforce that, though. Also, editing anything split into multiple files is going to be painful, because if you edit one part, something needs to update all the references (unless, of course, they should be actually immutable).
-
@cvi Oh, that could be fun!
- Opens file with editor program. Makes changes, saves. Editor updates its GUID knowledge when it saves so it can auto-open when started again.
- Opens file with viewer program: "ERROR: File not found, GUID does not exist."
Oh wait - the GFS can be source control too! So every GUID represents a different version of the file!
Oh shit. We just imposed Git on everybody.
-
@dcon Immutable file system FTW!
-
@cvi said in So I decided to try to update part of my toolchain...:
Question for the (G)UID-file people here... are the IDs supposed to be globally unique or just locally (= file system)?
Locally, of course. For the reasons you described (and more - for example, how would you install two instances of the same application side by side?)
If the IDs aren't globally unique, then I don't see why they would help anybody.
It would force programs to abandon the extremely error-prone string manipulation of filenames and paths.
An application will not be able to load a file by ID, because it no longer knows the IDs once they've been transferred to a different system.
That won't necessarily be a problem. As I imagine it, an application would be able to:
- Access its own storage and create files there, with whatever name tags it wants (so it doesn't need to know IDs of those).
- Access files it's been granted permission to - this would be the main mode of interaction between user and application: opening a file in file manager would grant temporary permission to access that file, and so would OS-provided save dialog - the file chooser would be spawned by outside shell through dedicated API, and that outside shell is able to grant temporary/permanent permission to those programs. From the user's perspective, it would function exactly like Windows functions today for most of the common tasks.
- Have the installer (not necessarily autonomous program, might be just package archive like on Linux or Android) set up permissions to communicate with other programs through some system-provided IPC infrastructure, or to access system APIs that are of interest to the application. For the IPC part, global IDs of some kind for applications would be necessary (so they can specify what they want to talk to), but they wouldn't have to unique. Not even locally unique.
This should cover most, if not all possible use cases. The only tricky part would be swapping disks (moving to another PC, cloning and restoring partitions, other shenanigans), but this can be solved too quite easily for the most part - make every partition have its own file UID namespace; make OS-level UIDs (which are a high-level abstraction over filesystem-level UIDs), the ones used by applications to actually access files, also include info about what partition the file is located in; create some administrative tool that would allow remapping partitions to different IDs (think: drive letters) so e.g. failed disks can be replaced seamlessly.
You're welcome to poke as many holes in my design as you want.
-
@levicki said in So I decided to try to update part of my toolchain...:
Does
jasonsex.jpgcontain a photo of:- Jason sex (i.e. his penis)?
- Jason having sex with someone?
- Jason's Ex (girlfriend or wife)?
Yes.
-
@Gąska said in So I decided to try to update part of my toolchain...:
You're welcome to poke as many holes in my design as you want.
(Not necessarily trying to poke holes, just trying to understand what you're suggesting. And thumbs-up for taking the time and writing this up.)
If I understand you right, you'd silo individual application somewhat similar to the way Android does, except even more for the filesystem, so that they'd only be able to access their "own" files, plus whatever global files they get special permission for.
Wouldn't it at that point make sense to namespace the IDs, so that applications can request their own files via an ID instead of a name tag? Less messing around with strings/names. And since the IDs are local to the application, there's no need to be concerned about collisions, and the local files would be either shipped with the application or created by it.
At that point you'd kind-of have a two-level hierarchy of (application[-instance], app-specific ID), I guess.
Might be workable. I'd personally hate it, since I don't really see "my" files belonging to a certain application, but that's maybe just me.
@levicki said in So I decided to try to update part of my toolchain...:
Git already solved that.

-
@levicki said in So I decided to try to update part of my toolchain...:
Jason sex (i.e. his penis)?
(...)
How do you find out? By looking at it.I'd rather not, thank you very much.
-
@Zerosquare it's quite possible Jason is an unborn child and the image is ultrasound picture. Then, finding out sex by looking at it sounds much less... disturbing.
-
@acrow An app which won't show you the path is a shit app. Simple as that. 'Mandate' is silly.
-
@cvi said in So I decided to try to update part of my toolchain...:
Question for the (G)UID-file people here... are the IDs supposed to be globally unique or just locally (= file system)? The former will introduce a ton of fun, in the DF sense. What happens if somebody maliciously (or otherwise) distributes a file that has the same ID as another already existing file? What happens if User A has a file with ID X to which User B has no access, but User B now introduces a file with the same ID?
The OS assigns a GUID when the file arrives.
If the IDs aren't globally unique, then I don't see why they would help anybody. An application will not be able to load a file by ID, because it no longer knows the IDs once they've been transferred to a different system.
How's that make sense? An application can load my document because it knows how to open that kind of document; it doesn't care what document it is. An application can load my configuration file because the file GUID is different from the 'recognized file' GUID.
-
@acrow said in So I decided to try to update part of my toolchain...:
"Your software can open my file, but I can't find it. Haw can I get your software to tell me where my file is?"
Had this problem with step-grandmother literally two weeks ago.
Finding docs is hard, apparently.
-
@pie_flavor said in So I decided to try to update part of my toolchain...:
The OS assigns a GUID when the file arrives.
The simple mechanism is to use a pair: a filesystem ID (which can be computed at creation from a reasonable RNG) and a local ID that's only unique within the FS. You could pretend that the whole ID is the concatenation of these, or that you have a tuple: I don't care which. Oh, BTW: this is very much like how Unix filesystems really work, except that the filesystem ID usually exposed to programs is only per-OS (and most syscalls work with names, not IDs).
Generating the ID of the file from its contents gets you Git or Fossil (for people who can't get over how annoying Git is). That's the core of how they work: by remembering these historical IDs, what they map to, and how they relate to each other.
-
@pie_flavor said in So I decided to try to update part of my toolchain...:
How's that make sense? An application can load my document because it knows how to open that kind of document; it doesn't care what document it is. An application can load my configuration file because the file GUID is different from the 'recognized file' GUID.
How does the application learn of that file GUID, so that it can request the associated file to be opened? I.e., if you want to avoid mucking with paths and filenames, instead of requesting "/some/path/file.cfg" (or whatever) on startup, you'd want to request file 1234-567-etc. But if the IDs change, you need some mechanism to discover the new ID.
-
@cvi said in So I decided to try to update part of my toolchain...:
How does the application learn of that file GUID, so that it can request the associated file to be opened?
There could be a system call to convert a “path” into its corresponding ID…
-
@cvi said in So I decided to try to update part of my toolchain...:
If I understand you right, you'd silo individual application somewhat similar to the way Android does, except even more for the filesystem, so that they'd only be able to access their "own" files, plus whatever global files they get special permission for.
Yes.
Wouldn't it at that point make sense to namespace the IDs, so that applications can request their own files via an ID instead of a name tag? Less messing around with strings/names. And since the IDs are local to the application, there's no need to be concerned about collisions, and the local files would be either shipped with the application or created by it.
At that point you'd kind-of have a two-level hierarchy of (application[-instance], app-specific ID), I guess.
The downside is that:
- because you file ID would be fixed-size (for performance reasons), you'd either end up with very long IDs (increasing overhead of basically every file operation), or have a somewhat small, limited number of files available for each app, or a somewhat small, limited number of apps that can be installed in the system, or some combination of all three;
- it creates the risk that developers would start hardcoding IDs of their files (or even worse - outright encourage them to), which could make it a huge PITA to manipulate program files if there's ever need to.
And none of this is really necessary. A single flat ID-namespace for entire filesystem is absolutely workable, and having app's local storage accessed by names is much lesser problem than doing that with all files in existence, because as you said - since they're local to the application, there's no need to be concerned about collisions.
Might be workable. I'd personally hate it, since I don't really see "my" files belonging to a certain application, but that's maybe just me.
Well, you already mostly have that. What I'm talking about is essentially just extending and strengthening the existing convetion of Program Files/AppData/My Documents/etc. You'd still be able to browse all those files as you do now - it's just the organization of files would be a little different.
-
@pie_flavor said in So I decided to try to update part of my toolchain...:
@acrow An app which won't show you the path is a
shitwell within expectations of a normal B+ quality-level app. Simple as that. 'Mandate' issillyhow progress gets pushed to the field.
-
@acrow it's impressive how many non-problems you can make up. It seems to me that you just can't get rid of the idea that the file name somehow uniquely and permanently identifies a file and try to carry this concept over (which is the exact concept we're trying to get rid of); and this leads you to believe that renaming a file should have any influence whatsoever on program behavior.
@acrow said in So I decided to try to update part of my toolchain...:
Every program that remembers and opens a file on startup MUST display that file's GUID.
No. The user never, ever, sees any kinds of GUIDs or even has to know that any such thing exists, because it's completely meaningless to them; just as currently with inodes.
@acrow said in So I decided to try to update part of my toolchain...:
We've already seen servers getting misplaced. Still functional, but nobody knows where it is or how to get hold of it. Would this phenomenon then not happen with files? Imagine the support call: "Your software can open my file, but I can't find it. Haw can I get your software to tell me where my file is?"
Answer: "Please command-click on file name in the title bar of the program window where the file is open. This will show you the current location of the file". At least, this is how it worked in MacOS Classic, which did in fact implement many of the features we're discussing here.
Of course this whole scenario assumes that "the location of the file" is actually still a meaningful concept on this new file system, which in turn assumes that there's some canonical directory structure.
@acrow said in So I decided to try to update part of my toolchain...:
Clarification. Imeant this scenario:
Starting point:
myfile (GUID1)
State2:
myfile.backup (GUID1)
State3:
myfile.backup (GUID1)
myfile.backup - Copy (GUID2)
Last state:
myfile.backup (GUID1)
myfile (GUID2)
And, I repeat, this is a user behavior that I have seen in the wild.This is a highly illogical workflow which entirely relies on the thinking that two files are somehow interchangeable just because one happens to end up with a name another file previously had. Yes, that thinking will have to be unlearned, which would be a good thing because it's stupid and illogical. Your process is also unnecessarily convoluted, and the logical, simpler approach to do this same thing would in fact continue working:
Starting Point:
myfile (GUID1)Step 1: copy myfile
=> myfile (GUID1), myfile copy (GUID2)Step 2: rename "myfile copy" to "myfile.backup"
=> myfile(GUID1), myfile.backup (GUID2)Step 3: there is no step 3
@acrow said in So I decided to try to update part of my toolchain...:
So, definitely not for general PC use by the masses, then, I believe.
I think anyone who hasn't been poisoned yet by the current way of doing things would find this vastly easier and intuitive.
-
@cvi said in So I decided to try to update part of my toolchain...:
How does the application learn of that file GUID, so that it can request the associated file to be opened? I.e., if you want to avoid mucking with paths and filenames, instead of requesting "/some/path/file.cfg" (or whatever) on startup, you'd want to request file 1234-567-etc. But if the IDs change, you need some mechanism to discover the new ID.
Program says "Give me the file with tags: 'App: <My App ID>', 'Kind: Configuration', 'Name: global.cfg'." OS returns either the UID or directly a file descriptor.
-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
impressive how many non-problems you can make up
They are not "non-problems" if the users of the system trip on them. Thinking otherwise would be condescending towards users, and likely to get them to vote with their wallets.
Usability 101: program should conform to the mental model a user has, however human it may be.
that thinking will have to be unlearned, which would be a good thing because it's stupid and illogical
Good luck with teaching the great masses, then.
user never, ever, sees any kinds of GUIDs or even has to know that any such thing exists, because it's completely meaningless to them
I prefer to give the user all possible information when there is the slightest chance of leaky abstraction. It does wonders for the resolving speed of support calls, in my experience.
-
@acrow said in So I decided to try to update part of my toolchain...:
They are not "non-problems"
For many of these I can assure you they are non-problems because they existed on Mac OS Classic and they never ever were a problem, simply because users weren't already poisoned by the consequences of the edge cases of a kludgy system. ETA: And of course because the OS was designed around these concepts.
@acrow said in So I decided to try to update part of my toolchain...:
Good luck with teaching the great masses, then.
As I said, that's easy for new users, it's only difficult for the "I cannot possibly adapt to any other kind of mindset than the one established in 1970" crowd. That crowd is currently slowly dying out. People whose experience with computing mostly comes from using their phones will not have any problem at all, because they have no notion of "file paths".
-
@Gąska said in So I decided to try to update part of my toolchain...:
because you file ID would be fixed-size (for performance reasons), you'd either end up with very long IDs (increasing overhead of basically every file operation), or have a somewhat small, limited number of files available for each app, or a somewhat small, limited number of apps that can be installed in the system, or some combination of all three;
From a quick googling, NTFS and BTRFS both seem have an upper limit of about 2^64 files per file system. That indicates that a 64-bit ID would be sufficient -- that's 8 bytes, which is probably less than the average file name length (especially if you include the extension in the name). I would hazard a guess that even at 128-bits, the lookup costs would still likely decrease compared to a variable-length string, simply because of the fixed size.
it creates the risk that developers would start hardcoding IDs of their files (or even worse - outright encourage them to), which could make it a huge PITA to manipulate program files if there's ever need to.
I would have encouraged hardcoding IDs. There's a bunch of files that programs need at startup (e.g., all the shared libraries, perhaps a config file or a manifest, various resources, ...). If the program can't run without those, what's the advantage in not hardcoding unambiguous IDs, especially if such exist? (You could still make them overrideable via command-line parameters, something like
LD_PRELOADor whatever.)@ixvedeusi How is that so much better than giving the OS a path? Especially if you allow multiple files with the same tags. What would happen with your example if two files match that request? (Also, if you were to require an indirection by first querying an ID and then getting the file handle, you've just introduced a whole new class of race conditions w.r.t. the file system.)
-
@cvi said in So I decided to try to update part of my toolchain...:
How is that so much better than giving the OS a path?
- No string manipulation, no mixing of data and structure, thus no issues about text encoding, no messing around with escaping, etc.
- You don't need to decide on any One True hierarchy (see also Jeff's article @kazitor posted above). You could define several hierarchies through the tags, each corresponding to a certain aspect of the files, or no hierarchy at all. An app could e. g. ask for all the files tagged with its app id, all configuration files with its app id, all its files belonging to a given user (config and data, or just config), etc.
- I think it could make sandboxing applications easier, which is something I'd absolutely want to have enforced in any hypothetical modern OS. Files which don't have specific tags to make them accessible for a given app would simply be visible to that app on lookup.
@cvi said in So I decided to try to update part of my toolchain...:
What would happen with your example if two files match that request?
I'd say that would be up to the application to decide. For example, it could merge all the settings from all the files, or just throw up its hands and show an error. The latter would IMHO make the most sense for config files, where only the app itself is supposed to create (and possibly manipulate) them.
-
This whole discussion is fascinating, but nobody's yet convinced me that any of it is an improvement over what we have now. That we'd be switching one type of mess for another, much less well-understood kind of mess, that's much more likely. Naturally, with changes of this class it'd be important to do some sort of demonstrator research OS to show how this might work in practice before anyone will commit serious resources to doing any of this for real…
-
@ixvedeusi Ok. Although, in your particular description, the IDs aren't really that central to your idea (from what I see). They could be left as an implementation detail (much like inode identifiers or whatever), the core seems to be more about the tagging and querying via tags/attributes/meta-data.
@dkf said in So I decided to try to update part of my toolchain...:
This whole discussion is fascinating
Same. But that's also why it deserves to be poked at a bit and seen what sticks and what doesn't. (And not about finding "contrived examples to make it fail" - ideas deserve to be tested, and if they don't hold up to a casual test, then it's either time to move on or to refine the idea. This discussion seems to move in the latter direction, which is what makes it interesting.)
-
@dkf said in So I decided to try to update part of my toolchain...:
with changes of this class it'd be important to do some sort of demonstrator research OS
Absolutely agreed on that point, and I've been impatient to get started with it for, like, forever. Never mind I have no actual experience or specific knowledge about writing operating systems, I sure will get on to it as soon as I can find the time!
-
@cvi said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
because you file ID would be fixed-size (for performance reasons), you'd either end up with very long IDs (increasing overhead of basically every file operation), or have a somewhat small, limited number of files available for each app, or a somewhat small, limited number of apps that can be installed in the system, or some combination of all three;
From a quick googling, NTFS and BTRFS both seem have an upper limit of about 2^64 files per file system. That indicates that a 64-bit ID would be sufficient -- that's 8 bytes, which is probably less than the average file name length (especially if you include the extension in the name). I would hazard a guess that even at 128-bits, the lookup costs would still likely decrease compared to a variable-length string, simply because of the fixed size.
Still, why limit yourself when you can not limit yourself?
it creates the risk that developers would start hardcoding IDs of their files (or even worse - outright encourage them to), which could make it a huge PITA to manipulate program files if there's ever need to.
I would have encouraged hardcoding IDs. There's a bunch of files that programs need at startup (e.g., all the shared libraries, perhaps a config file or a manifest, various resources, ...). If the program can't run without those, what's the advantage in not hardcoding unambiguous IDs, especially if such exist?
Because those hardcoded IDs won't be real IDs if they have to be first tied to app ID. You either end up with two separate file access APIs - one for "own" files that don't take prefixed IDs and apply the app prefix internally, and one for "foreign" files that uses full IDs - or you force the applications to insert the prefixes themselves, increasing the number of things that can go wrong.
(You could still make them overrideable via command-line parameters, something like
LD_PRELOADor whatever.)And now you're introducing indirection mechanism that causes the same file ID to not always refer to the same file.
Note: I'm NOT agreeing with what @ixvedeusi says. His query design has many unnecessary problems and has no advantages over the much simpler "open my appdata and gimme handle"/"list file names and their IDs inside directory from this handle"/"open file with specified ID". But still...
Also, if you were to require an indirection by first querying an ID and then getting the file handle, you've just introduced a whole new class of race conditions w.r.t. the file system.
It's not like we don't already have plenty of exactly this problem. I'm of a firm belief that all programs should be prepared for all I/O operations to fail at any moment - because sooner or later, it will fail.
-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
You don't need to decide on any One True hierarchy (see also Jeff's article @kazitor posted above). You could define several hierarchies through the tags, each corresponding to a certain aspect of the files, or no hierarchy at all. An app could e. g. ask for all the files tagged with its app id, all configuration files with its app id, all its files belonging to a given user (config and data, or just config), etc.
Are you trying to sell us SharePoint?
-
@dkf said in So I decided to try to update part of my toolchain...:
demonstrator research OS
I propose we call it TempleOS
-
@Gąska said in So I decided to try to update part of my toolchain...:
Note: I'm NOT agreeing with what @ixvedeusi says. His query design has many unnecessary problems and has no advantages over the much simpler "open my appdata and gimme handle"/"list file names and their IDs inside directory from this handle"/"open file with specified ID".
AFAICT, that's just a special case of what I'd proposed. What's the unnecessary problems you're alluding to? I don't really see much (on the conceptual level at least) that couldn't be solved with suitable conventions, just as we need suitable conventions (e. g. path to AppData) with current path-based systems.
And, I don't agree about the "no advantages" part. Personally I find the notion that there must be One True File Hierarchy extremely constraining, not particularly useful or clear, and not very suited to how computing devices are used these days. For example, should I put my holiday photos from my trip to Rivendell into the "Photos" folder, or into the "Trip to Rivendell" folder, or into a "Rivendell" folder in my "Trips" folder, or into the "Proof for the existence of Elves" folder? Why can't I do all of these?
ETA: Of course you could solve some of this by adding support for tags as a separate system in addition to having a "canonical" file hierarchy, but once you're there I'm not sure what you'd still be needing the canonical file hierarchy for.
-
@Luhmann said in So I decided to try to update part of my toolchain...:
Are you trying to sell us SharePoint?
I have barely used SharePoint, but from what I heard its problems don't seem to stem from anything related to my proposition. Care to elaborate?
-
@dkf said in So I decided to try to update part of my toolchain...:
This whole discussion is fascinating, but nobody's yet convinced me that any of it is an improvement over what we have now.
- Badly written programs stop shitting all over themselves and the entire machine when they encounter spaces in paths (because there are no paths).
- Badly written programs stop shitting all over themselves and the entire machine when they encounter non-ASCII characters in paths (because there are no paths).
- Badly written programs stop shitting all over themselves and the entire machine when they fuck up building a path from string fragments (because there are no paths).
- Badly written programs stop shitting all over themselves and the entire machine when they are run on a different Windows version, or the same Windows version but in different language, and it turns out their bullshit assumptions about certain system paths are wrong (because there are no paths).
Etc. etc. etc. Basically - paths are extremely error-prone, and getting rid of them at every level of the operating system would dramatically increase reliability of all software. It's like moving from manual memory management to smart pointers and garbage collectors, except paths are much more ingrained in all our software and less isolated than
malloc, so getting rid of paths would be much, much, much harder. It would require an entirely new platform that's completely separated from the old systems and forgetting about any backwards compatibility whatsoever. Like smartphones in 2007. The only reason they could improve the app management, data isolation and permission systems so much compared to earlier platforms is because there were zero backwards compatibility concerns. We will never be able to do that in desktop space. But I can still dream~~~
-
I'm not talking about it's flaws or issues, there are plenty but core thing about SharePoint and similar document management stuff is that it takes documents and instead of just dumping them in a folder structure it gives you meta data to organize them.
-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
@dkf said in So I decided to try to update part of my toolchain...:
with changes of this class it'd be important to do some sort of demonstrator research OS
Absolutely agreed on that point, and I've been impatient to get started with it for, like, forever. Never mind I have no actual experience or specific knowledge about writing operating systems, I sure will get on to it as soon as I can find the time!
Actually, you may be able to get some measure of real-world acceptability sooner than that. First, let's consider this:
@Gąska said in So I decided to try to update part of my toolchain...:
Absolutely for general PC use by the masses. Android and iOS have both shown beyond any doubt that most users don't care about paths. And both those platforms are already halfway through with what I proposed.
Now, if Android finds its way to productive work (and I don't mean e-mail), then the filesystem
improvementparadigm shift may be viable, and may find its way to PCs. And then that path will play to its conclusion, which may or may not be what was proposed in this thread.On the other hand, if Android won't end up on the desktops of offices, despite it's popularity on phones and tablets, then I'm inclined to assume that productive work needs something that Android does not offer. Of course, debate will arise on whether that something is the traditional file system.
Edit:
 'd by Gąska's dream.
'd by Gąska's dream.
-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
I don't really see much that couldn't be solved with suitable conventions
That also applies to filenames, FWIW.
-
@Gąska said in So I decided to try to update part of my toolchain...:
Badly written programs stop shitting all over themselves and the entire machine when…

-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
Note: I'm NOT agreeing with what @ixvedeusi says. His query design has many unnecessary problems and has no advantages over the much simpler "open my appdata and gimme handle"/"list file names and their IDs inside directory from this handle"/"open file with specified ID".
AFAICT, that's just a special case of what I'd proposed. What's the unnecessary problems you're alluding to? I don't really see much (on the conceptual level at least) that couldn't be solved with suitable conventions, just as we need suitable conventions (e. g. path to AppData) with current path-based systems.
Upon re-reading your post, yes, we kinda said the same thing. But I don't think just having conventions is enough. Those conventions need to be enforced by the system, by disallowing any action that doesn't follow convention. And for this to be practical, the conventions need to be flexible enough to accommodate every type of application and every use case, and also easy enough for programmers not to complain on every step of the way. Specifically in case of what you presented - if the app knows that there's
global.cfgfile assigned to it that it created and it can use, why does it need to specifyKind: Configuration? Is this special for the system, or just random example of what the app might do but not necessarily has to do? Is app ID in your example an app-provided GUID or system-provided LUID? If it's GUID, what if the same program gets installed twice, possibly in different versions? If it's LUID, is it managed by app or system? If by app, what if it gets it wrong? If by system, what if the app doesn't want its ID to be stored there for whatever reason?It is definitely useful feature to find files from entire OS by text tags, but for a main method of accessing program's own files, this has too many problems to be practical. Compare to a dedicated API call for retrieving dedicated storage directory/other special folders for a given app, which avoids all mentioned problems entirely.
And, I don't agree about the "no advantages" part. Personally I find the notion that there must be One True File Hierarchy extremely constraining, not particularly useful or clear, and not very suited to how computing devices are used these days.
Agreed. But having One True Appdata Directory is a very good idea regardless.
-
@dkf said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
Badly written programs stop shitting all over themselves and the entire machine when…
When was the last time you had stack corruption in Java? C#? Python? Ruby? JavaScript? Compare to C.
-
@Gąska said in So I decided to try to update part of my toolchain...:
When was the last time you had stack corruption
As if that's the only kind of bug that's possible.
-
@dkf it's the most common kind of bug in C, on par with invalid pointer accesses (which are also prevented by GC).
-
@Gąska said in So I decided to try to update part of my toolchain...:
it's the most common kind of bug in C
Maybe on your computers…
-
@Gąska said in So I decided to try to update part of my toolchain...:
Still, why limit yourself when you can not limit yourself?
With 128 bits, you're the same size as a GUID. Are you proposing an even larger ID? Is 128bits really a limit in any real-world use case?
Because those hardcoded IDs won't be real IDs if they have to be first tied to app ID. You either end up with two separate file access APIs - one for "own" files that don't take prefixed IDs and apply the app prefix internally, and one for "foreign" files that uses full IDs - or you force the applications to insert the prefixes themselves, increasing the number of things that can go wrong.
OK. For me the interesting use case is easily and unambiguously locating well-known files. But this doesn't seem to be solved by the system you're proposing. (Actually, it seems worse, because somebody could introduce additional files with the same tags. Or only disambiguated by additional unknown tags.)
Secondly, the same comment as above seems to apply. Why so much noise about the file IDs, when this seems to be an implementation detail at best?
-
@dkf said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
it's the most common kind of bug in C
Maybe on your computers…
Yes, I'm talking about semiconductor computers. Maybe it's different on quantum computers, or whatever other contraptions you're working with, but in semiconductor world, they really are.
 Microsoft: 70 percent of all security bugs are memory safety issues
Microsoft: 70 percent of all security bugs are memory safety issues
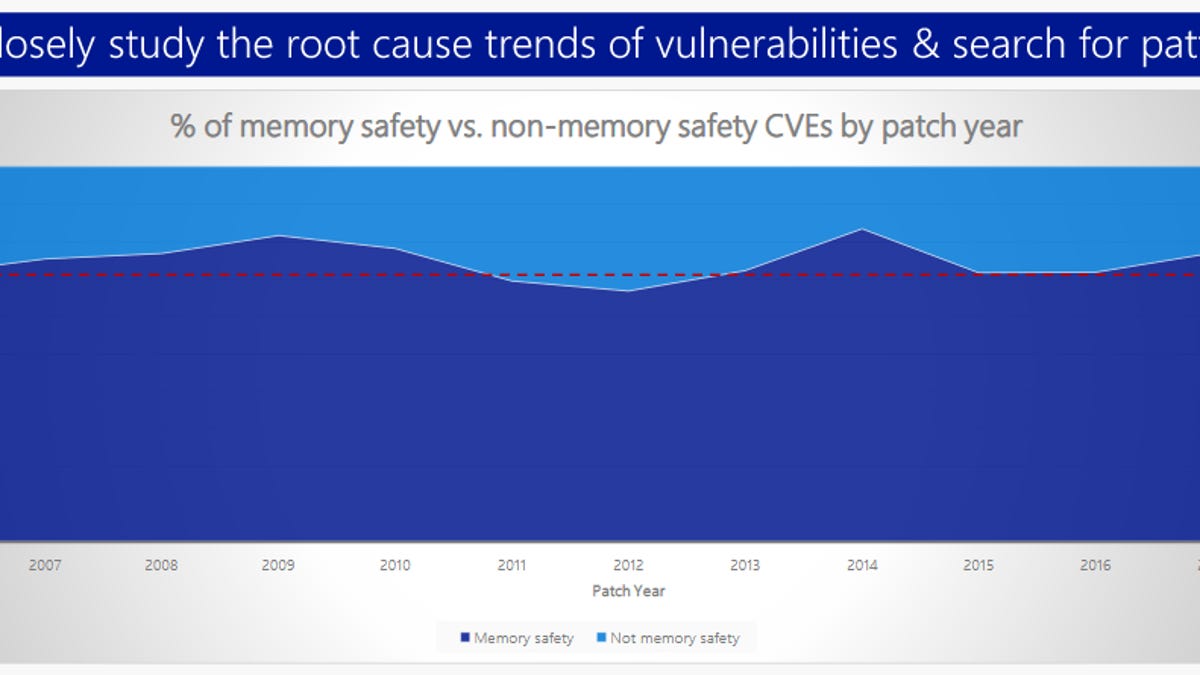
Percentage of memory safety issues has been hovering at 70 percent for the past 12 years.
-
@cvi said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
Still, why limit yourself when you can not limit yourself?
With 128 bits, you're the same size as a GUID. Are you proposing an even larger ID? Is 128bits really a limit in any real-world use case?
Yes, modern computers are powerful enough that you can overcome almost every computing problem by throwing more resources at it - I agree. But still, why would you choose a solution that's slightly inferior and has no upsides over a solution that's slightly superior and has no downsides?
Because those hardcoded IDs won't be real IDs if they have to be first tied to app ID. You either end up with two separate file access APIs - one for "own" files that don't take prefixed IDs and apply the app prefix internally, and one for "foreign" files that uses full IDs - or you force the applications to insert the prefixes themselves, increasing the number of things that can go wrong.
OK. For me the interesting use case is easily and unambiguously locating well-known files. But this doesn't seem to be solved by the system you're proposing. (Actually, it seems worse, because somebody could introduce additional files with the same tags. Or only disambiguated by additional unknown tags.)
Yes, I'm not entirely convinced either that duplicate names are a good idea. But even without duplicate names, ID-based files are a huge win - and none of the problems you're talking about apply then.
Secondly, the same comment as above seems to apply. Why so much noise about the file IDs, when this seems to be an implementation detail at best?
It's not implementation detail. It completely changes how all the system APIs work. And it's not just about low-level APIs either - this change would be reflected in every layer of abstraction from the very bottom to the very top. File paths would just stop being a thing. Entirely. Absolutely. Everywhere. This is not implementation detail.
-
@cvi said in So I decided to try to update part of my toolchain...:
@pie_flavor said in So I decided to try to update part of my toolchain...:
How's that make sense? An application can load my document because it knows how to open that kind of document; it doesn't care what document it is. An application can load my configuration file because the file GUID is different from the 'recognized file' GUID.
How does the application learn of that file GUID, so that it can request the associated file to be opened? I.e., if you want to avoid mucking with paths and filenames, instead of requesting "/some/path/file.cfg" (or whatever) on startup, you'd want to request file 1234-567-etc. But if the IDs change, you need some mechanism to discover the new ID.
There's an ID for the file, and an ID for the 'recognized file.' A program has the latter hardcoded, and can open files by either.
-
@levicki said in So I decided to try to update part of my toolchain...:
Also, how is that different to receiving 42 emails with subject "Notes"?
Seriously? Because every email program I've used also includes the sender. I know who's email is who's. I'm not forced to use yet-another-tool to discover things.
-
@ixvedeusi said in So I decided to try to update part of my toolchain...:
No string manipulation
It really isn't - because you still need to present the user with a meaningful-to-them name. Which means strings. Well, until we're all assimilated into the collective...
-
@Gąska said in So I decided to try to update part of my toolchain...:
Badly written programs stop shitting all over themselves and the entire machine when they encounter non-ASCII characters in paths (because there are no paths).
etc...
LOL. Badly written programs will shit all over themselves no matter what! And they'll still shit over non-ASCII chars because they still need to present the user with a meaningful string.
-
@dcon said in So I decided to try to update part of my toolchain...:
@Gąska said in So I decided to try to update part of my toolchain...:
Badly written programs stop shitting all over themselves and the entire machine when they encounter non-ASCII characters in paths (because there are no paths).
etc...
LOL. Badly written programs will shit all over themselves no matter what!
But they can do it in more destructive way, or less destructive way.
"rm -rf " + variableThatMightBeEmpty + "/",executeOrder.exe C:\Program Files\Something something, andconst string DLL_INSTALL_LOCATION = "C:\\Windows\\system32";are among the most destructive.And they'll still shit over non-ASCII chars because they still need to present the user with a meaningful string.
And the worst that can happen when presenting to user is that some characters would get mangled. Compare to accidentally removing entire filesystem.
-
@cvi said in So I decided to try to update part of my toolchain...:
Is 128bits really a limit in any real-world use case?
mumblemumble 640K mumble.
-
@dcon with 128 bits, you can generate million new IDs every femtosecond, and by the time the Sun becomes a white dwarf, you'd still have a good chunk of unused IDs left. For in-partition file identifier, 128 bits really is enough for everybody.