Good luck, Tim Berners-Lee
-
Creator of the World Wide Web wants to fix all the problems:
World wide web creator Tim Berners-Lee targets fake news

Social media sites and search engines must be pushed to do more to combat the problem, he says.
All I can say is: Good luck mate, you're gonna need it.
-
@RaceProUK It is kinda ironic that the creator of the internet doesn't really understand it anymore.
-
Fake news has become so prevalent that the Commons Culture, Media and Sport Committee is now investigating concerns about the public being swayed by propaganda and untruths.
People being swayed... by propaganda and untruths?!?!?!?!?!?
-
@anonymous234 said in Good luck, Tim Berners-Lee:
People being swayed... by propaganda and untruths?!?!?!?!?!?
That's kinda the entire point of propaganda.
-
@HardwareGeek But we have meme magic now.
-
This tag made me think Berners-Lee was launching a dubstep career. I am disappoint.
-
@lucas1 He hasn't actually made any comments that imply he thinks he's the Official King of the Internet. He just said "Yeah Google needs to do something I guess".
-
@anonymous234 The problem is for me is that he thinks he still has any relevancy to its direction. He doesn't.
It is like Henry Ford Telling Enzo Ferrari about how cars should be built. It is an irrelevance to Ferrari.
I am a web developer and I give zero fucks what Tim Berners-Lee thinks.
-
@anonymous234 The real issue is, should Google censor the internet?
Anything can be called Fake News by anyone to dismiss it.
Most media outlets are biased.
e.g. the Guardian and BBC NEWS haven't lied by have misrepresented the facts a lot. Some of the events I was actually there or online at the time listening to the stream. I know that they left key parts out, to make a narrative fit.
-
When I've heard of an article, and I google for it and click "news", I get all kinds of random sites before I find an actual paper. Many of them are reporting that another paper has reported on a story, or three levels deep. Google could probably do better at prioritizing the sources so the ones with actual information come before the tertiary sources.
-
@Yamikuronue Yeah they do this. But that why you gotta check out loads of sources.
But when I go to the new outlet that I pay for (We have to pay for BBC in the UK if you own a television) I expect them to be impartial and accurate. They aren't. I know they tell half the story because I have either been at the place where the event was happening, or more recently I was listening to a youtube live stream and looking at what was going on with twitter in realtime and looking at their reporting after the fact.
EDIT: There has been at least three times they have told me (I have complained via email) that what I saw with my own eyes didn't happen.
-
The thing is... if we're leaving Google (or any other party) to remove the fake news from results then we're leaving them to decide which is fake and potentially which sources are trustworthy. I'd sort of rather they just publish everything and leave the reader to decide what to believe.
-
@lucas1 Yeah, news sources suck. But there's the usual set of crappy sources, and there's the no-content clickbait sites that are all "You won't BELIEVE what Trump just did!" and then link you to a slideshow with fifteen pictures of Trump as they slowly, three words at a time, dole out the story. Those are just stupid.
-
@Yamikuronue I appreciate what you are saying. However there is always the scenario where "a broken clock is right twice a day".
-
@loopback0 I'm not saying remove anything; I'm saying, they already do a good job of prioritizing the information I want (like "what movies has Denzel Washington been in lately") from the information I'm not searching for (fansites about how hot Denzel Washington is) based on my search terms. They should be better at doing that for news.
-
@Yamikuronue And people will SEO optimise their way up the list once they work out how the algorithm works. People will abuse the ranking algorithm whatever rules you put in place. Unless you want the all seeing eye out of "Electric Eye", it not going to work.
Also a lot of the click bait is pretty obvious on most sites. Just don't go back to those sites.
-
@Yamikuronue said in Good luck, Tim Berners-Lee:
Google could probably do better at prioritizing the sources so the ones with actual information come before the tertiary sources.
Ehhh... not sure that's what people look for. If there's a report on a scientific breakthrough, do you think Google should prioritize the 100-page original paper over a newspaper's digest of it? Sure, the latter may be wrong or inaccurate, but ain't nobody going to read the former.
-
@Maciejasjmj That's why I said secondary over tertiary. A secondary source is useful, summing up the primary for people who don't have the time or the background to appreciate it. But tertiary sources, reporting on reporters? Eh.
-
Google are already filtering a lot of result regarding child porn, ISIS etc, Copyright infringement and also (if you are in the EU) not being able to find out about a persons former life (EU privacy law).
If they start censoring more it is going to start censoring real information.
Song it relevant to thread btw:
https://www.youtube.com/watch?v=EQ96oEwYrE8
Up here in space
I'm looking down on you
My lasers trace
Everything you doYou think you've private lives
Think nothing of the kind
There is no true escape
I'm watching all the timeI'm made of metal
My circuits gleam
I am perpetual
I keep the country cleanI'm elected electric spy
I'm protected electric eye
Always in focus
You can't feel my stareI zoom into you
You don't know I'm there
I take a pride in probing all your secret moves
My tearless retina takes pictures that can prove
I'm made of metalMy circuits gleam
I am perpetual
I keep the country clean
Electric eye,…
-
@Yamikuronue Yeah fair point. Makes me wonder if news stories might get prioritised differently on Search results than they do on News results?
Not enough to actually find out though.
-
@Yamikuronue said in Good luck, Tim Berners-Lee:
@lucas1 Yeah, news sources suck. But there's the usual set of crappy sources, and there's the no-content clickbait sites that are all "You won't BELIEVE what Trump just did!" and then link you to a slideshow with fifteen pictures of Trump as they slowly, three words at a time, dole out the story. Those are just stupid.
-
The solution to fake news is to get rid of the Facebook. Good riddance to bad rubbish.
-
@loopback0 They also remove malware and phishing. Even though a smart user won't fall for them.
-
@dse so nobody will ever click a phishing mail ....
-
@Maciejasjmj said in Good luck, Tim Berners-Lee:
@Yamikuronue said in Good luck, Tim Berners-Lee:
Google could probably do better at prioritizing the sources so the ones with actual information come before the tertiary sources.
Ehhh... not sure that's what people look for. If there's a report on a scientific breakthrough, do you think Google should prioritize the 100-page original paper over a newspaper's digest of it? Sure, the latter may be wrong or inaccurate, but ain't nobody going to read the former.
It should at least appear on the first page, though.
-
@Rhywden How does it appear on the first page? Google have said they don't know how their algorithm works anymore.
-
@lucas1 said in Good luck, Tim Berners-Lee:
@Rhywden How does it appear on the first page? Google have said they don't know how their algorithm works anymore.
And that's a valid excuse exactly since when...?
-
@lucas1 said in Good luck, Tim Berners-Lee:
Google have said they don't know how their algorithm works anymore.
I find that hard to believe.
-
@RaceProUK I am only repeating what they have said.
-
@lucas1 said in Good luck, Tim Berners-Lee:
@RaceProUK I am only repeating what they have said.
Ah, "The Google" has spoken. Is that a first or last name?
-
Google Admits They Fully Don't Understand RankBrain

At SMX West last week, Google's Paul Haahr, a top engineer involved in core ranking, had a keynote Q&A with Danny Sullivan. He said many interesting things including that Google doesn't fully quiet understand RankBrain...
Stop trying to be clever when you aren't otherwise I will post more music vids (btw that was a joke as I know you are a humourless cunt).
-
@lucas1 That's a great example of a useless article. "A guy tweeted! Isn't that important! View our ads."
-
@Yamikuronue And provides zero context to boot. Was it a joke or was he actually serious? And if serious, does he mean the usual neural-net-problem of "We know the rules but we don't know the exact steps for the results we're seeing"? Or something else completely?
-
@Yamikuronue This was a big thing about 2 years ago I remember seeing the same thing on the BBC.
 Google teaches “AIs” to invent their own crypto and avoid eavesdropping
Google teaches “AIs” to invent their own crypto and avoid eavesdropping

Neural networks seem good at devising crypto methods; less good at codebreaking.
Considering this is true, it is likely the other is true IMO.
-
@lucas1 It doesn't mean they can't tweak or change the system. From the comments:
The context of Paul's comments was that rankbrain was choosing which factors to weight for a particular query and that they can still measure the satisfaction of the results for the user without necessarily knowing what rankbrain chose to weight in each particular case.
-
@Rhywden If you have ever tryed munging input so it can be parsed after the fact it is not trivial. I would imagine filtering afterwards would be equally as challenging.
Half my life is spent cleaning data before it comes into a system.
-
@Rhywden That doesn't mean they know how it works does it. They just know how it responds most of the time.
-
@lucas1 That article has nothing to do with search rankings. It's interesting, but not really relevant to the subject at hand.
-
@Yamikuronue All I am saying is that I remember quite clearly that Google engineers said at some point they aren't sure how it works.
I've been googling to find the exact article but I get mostly SEO sites.
So you will have to take it on good faith.
-
@lucas1 said in Good luck, Tim Berners-Lee:
Google engineers said at some point they aren't sure how it works
Sounds like one of these neural network things. They're amazing in what they can do (especially once you go to deep networks with many layers) but really hard to understand. You end up with software that works magically, and yet where you don't really know why it works at all (since the core of it is a whopper of a differential equation solver; comprehending the meaning in that collection of equations is just awful).
-
@dkf I did some stuff in Uni towards the end of it that was to do with something about "priori" But that was 8 years ago and I can't remember anything about it.
But what I did remember was the big Database Warehouse stuff and they ran the algorithms over it to get relationships between certain products e.g. how amazon matches products to you.
I was hoping that course was about RDMS systems and how to make them fast as I was interested in that at the time. But it ended up to be about how to sort data out for predictive systems.
-
@dkf said in Good luck, Tim Berners-Lee:
Sounds like one of these neural network things. They're amazing in what they can do (especially once you go to deep networks with many layers) but really hard to understand. You end up with software that works magically, and yet where you don't really know why it works at all
Neural networks and machine-learning methods in general give answers based on similarities to the given training data.
For example, the k-nearest neighbours algorithm stores all training points and finds the ones closest to your query.
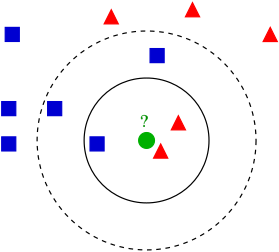
Other approaches, like NNs, do not store the data set, but instead fit a function to the training data (for example, gaussian probability distribution) and store the function parameters (for gaussian: mean and covariance).In the case of NNs, this function is a very complex one and stores a big number of parameters - but this is a deliberate choice as this function is very flexible and can solve hard problems.
Of course, we know how it works - the function is defined, the parameters are known - but the complexity reduces the explanatory power, we can't say which properties of the input contributed the most to the answer.
Let's consider the task of deciding if a picture contains a cat:
-
In a nearest-neighbour approach, we would find the most similar picture in the database and if it was labeled as cat, we would say there is a cat. This offers a great explanation: this is a cat, because its similar to a known cat. But this is a weak method - we would have to store all possible images to always have a similar image in the DB.
-
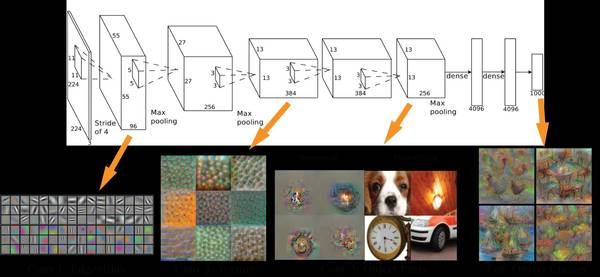
A convolutional neural network approach has been proven effective in such recognition tasks.
There is still some explanation available: inspecting the trained convolution kernels shows us that initial layers find simple features like lines or edges, while the higher layers combine those in more complex and meaningful objects.
-
Humans are still the best at recognition tasks. Even if the images are different graphically, the meaning is obvious. But can you explain why you know there is a cat in the picture?



-
-
@Adynathos I don't like any of that shit.
-
@Adynathos said in Good luck, Tim Berners-Lee:
Neural networks and machine-learning methods in general give answers based on similarities to the given training data.
That's OK for relatively shallow NNs, but as you add more levels of processing and feedback between the input and output then you get other stuff too. Deep nets are weird; I say this because I'm working on systems to simulate those critters and get to see what some of the researchers in the area are really up to.
-
@dkf said in Good luck, Tim Berners-Lee:
That's OK for relatively shallow NNs, but as you add more levels of processing and feedback between the input and output then you get other stuff too. Deep nets are weird; I say this because I'm working on systems to simulate those critters and get to see what some of the researchers in the area are really up to.
Oh, and what kind of NNs do you work with?
I am trying to start being a "researcher in the area" :)Yes, I described the standard supervised learning approach of minimizing loss function over the training set.
But indeed other approaches, like adversarial networks (method used in this "Google AI invents its own cryptographic algorithm" article) have a loss function also depending on the network weights.
-
@dkf said in Good luck, Tim Berners-Lee:
Deep nets are weird
I used to disagree with you 5-6 years back. I thought they are just extremely slow (to train) optimization techniques, that did not even work better than say SVM. The fact that there are so many stupid papers in AI did not help, and stupid researchers focused on stupid things like playing with complex composition functions. But deep nets are in fact weird, you train them with billions of input and then they show real signs of intelligence.
@Adynathos said in Good luck, Tim Berners-Lee:
m trying to start being a "researcher in the area"
Brace for the AI overlords, be a good servant.
-
@loopback0 said in Good luck, Tim Berners-Lee:
I'd sort of rather they just publish everything and leave the reader to decide what to believe.
Isn’t that exactly what’s lead to fake news being so prevalent?
-
@Adynathos said in Good luck, Tim Berners-Lee:
Oh, and what kind of NNs do you work with?
Spiking neural networks, which work by simulating the firing of synapses. Standard NNs are much more about trying to treat the whole thing as one gigantic collection of ODEs. Well, spiking NNs do that too, but the DEs are split up into lots of little pieces. The neuroscientists are much happier with spiking systems, as they're a lot more like what neurons really do.
We specifically work with PyNN. Alas, PyNN's implementation is a steaming pile of
 internally. And the ways in which it is commonly used are also steaming piles of . And their website has a tendency to too. But the basic science is pretty sane.
internally. And the ways in which it is commonly used are also steaming piles of . And their website has a tendency to too. But the basic science is pretty sane.
-
@dkf said in Good luck, Tim Berners-Lee:
Spiking neural networks
I see, that is a completely different kind.
Do you train spiking nets (how would you even train them?) or create an architecture to see what it does?We specifically work with PyNN. Alas, PyNN's implementation is a steaming pile of internally. And the ways in which it is commonly used are also steaming piles of .
Some people at my uni also do neuromorphic nets, and they have dedicated hardware for that.
-
@Adynathos said in Good luck, Tim Berners-Lee:
Do you train spiking nets (how would you even train them?) or create an architecture to see what it does?
Yes, the usual method is to use STDP — Spike Timing Dependent Plasticity. The idea is that if one spike tends to come shortly after another one, the strength of the connection between the two is increased, but if they go the other way then the strength is decreased. It works pretty well, and is a decent way of describing how short-term memory works in biological neural networks too.
There's a separate level of plasticity that is a better description of long-term memory, and that's where the structure of the network itself is modified; it corresponds to the creation of new synapses and the pruning of old ones. There's a (very smart indeed) student at work doing his PhD on making that work in a form that is simulatable at speed.
