Surrogate vs natural primary keys
-
I have a table like this:
CREATE TABLE accounts ( id serial NOT NULL, name character varying NOT NULL, CONSTRAINT pk_accounts PRIMARY KEY (id), CONSTRAINT uk_account_name UNIQUE (name) ); CREATE INDEX ix_accounts_name ON accounts USING btree (name);So, I have set up a serial
id(auto-increase int) as PK, but my actual primary key isname. I have an index and unique constraint set up on name, so it behaves as PK. I will almost always access the data through name (from two different API-s).Should I then switch to
nameas my PK?Reading the highest rated SO answer on the subject, here are the rules.
- Primary keys should be as small as necessary. Prefer a numeric type because numeric types are stored in a much more compact format than character formats. This is because most primary keys will be foreign keys in another table as well as used in multiple indexes. The smaller your key, the smaller the index, the less pages in the cache you will use.
- Primary keys should never change. Updating a primary key should always be out of the question. This is because it is most likely to be used in multiple indexes and used as a foreign key. Updating a single primary key could cause of ripple effect of changes.
- Do NOT use "your problem primary key" as your logic model primary key. For example passport number, social security number, or employee contract number as these "primary key" can change for real world situations.
Since these account names will come from a third party, I have no idea how large they'll be. Also whether there'll be rename issues. Then maybe I should keep surrogate Id-s... except, they look godawful ugly and superfluous.
So what do you think? Where is the dividing line for you between surrogate and natural id-s?
-
@cartman82 said in Surrogate vs natural primary keys:
I have a table like this:
...
So, I have set up a serialid(auto-increase int) as PK, but my actual primary key isname. I have an index and unique constraint set up on name, so it behaves as PK. I will almost always access the data through name (from two different API-s).Should I then switch to
nameas my PK?No, for reason #3 below (and to lesser extent, #2, if you cannot ensure that the name field won't change - this argument is mostly relevant to sort order; cascading the changes can be a short-term performance issue if it is used in several places as an FK but the update itself should occur on its own if your constraints are correct). While the specific argument presented for avoiding natural keys (that most natural data are not unique) is in some ways bogus - that particular sub-set of attributes wouldn't be a candidate key in the first place if it weren't unique, would it? - the basic point that you aren't in control of most natural candidate keys the way you would be with a surrogate key is right on the money.
Primary keys should be as small as necessary. Prefer a numeric type because numeric types are stored in a much more compact format than character formats. This is because most primary keys will be foreign keys in another table as well as used in multiple indexes. The smaller your key, the smaller the index, the less pages in the cache you will use.
This is BS, though the reasons it is BS are probably not the ones you expect me to say. First off, the size of the key is almost always negligible WRT the size of the relation as a whole, except for in a translation relation (lookup table). Similarly, on almost any modern RDBMS, the size of a single index is trivial compared to the size of the relation it indexes. More to the point, the argument is basically a call to commit premature optimization - you have no way of knowing yet whether such an optimization is necessary, or even that it would actually optimize the indices at all rather than pessimize them.
-
I always keep a
serialfield as the primary key. The biggest reason, even though the SO post you saw listed it second, is that you never have to worry about it changing. Even if you are absolutely certain that your natural primary key will never change, it will eventually change. It is possible to handle (e.g. with triggers), but if you don't get it perfectly correct, your data will end up corrupted.Having an index on the
namefield will make access bynamepretty much just as fast as access by theidfield. Also, in case that's the SQL that you're executing, you don't need to create an index onname; making it unique will create an index for you anyway.
-
@cartman82 said in Surrogate vs natural primary keys:
Where is the dividing line for you between surrogate and natural id-s?
I always avoid natural ids. You can still put a unique index on it (I assume your RDBMS supports that) if you really need to. But always have a surrogate key.
Worrying about data size always smells like premature optimization (or a really awful DB) to me.
-
There's no such thing as a "natural" key. There are only things that misleadingly look like natural keys, right up until they aren't and you're stuck with a HUGE data migration.
ALWAYS use a surrogate key. ALWAYS.
EDIT: Note you don't need to put a unique constraint on a key; you can put a unique constraint on any column. At least you can if your RDMS doesn't suck shit.
-
@Dragnslcr said in Surrogate vs natural primary keys:
I always keep a serial field as the primary key.
Nowadays, it's more future-proof to use a GUID (or "uniqueidentifier" in MS SQL-speke).
-
@blakeyrat said in Surrogate vs natural primary keys:
There's no such thing as a "natural" key.
Meh, like with so much of RDT, most people don't really get the idea of a candidate key in the first place, or understand their importance beyond the idea of 'this is how you sort things' and 'this bit can be used as a name for the rest of it, so we copy that one piece instead of the whole table'.
Admittedly, neither do I, but at least I'm in the 'informed incompetence' group. Too many people in general simply accept the first set of Lies To Children they are given and assume that they are the literal truth rather than an allegory meant to enable later understanding (which, as an aside, is also my biggest beef with fundamentalist religion; if you can't understand that all religious illumination is passed down through allegory - because there is simply no way of expressing the numinous experience more directly than that - then you aren't practicing a Belief System at all).
-
@thegoryone Sarcastic much?
If you really are confused by this, which part is it you are having trouble with?
-
Get some sleep (and maybe some ethanol) and read it again when your brain is functional, then.
-
It's always bothered me that surrogate keys are something you have to design-in yourself. Like the developers of SQL Server, etc. don't know that that's how almost every table is designed. You have to declare the id column. You have to add the uniqueness constraint. You have to reference it in joins. Can't that just be built in so it's always done right?
Is there anything that lets you do that or is there some reason why it's impossible/bad idea?
CREATE TABLE accounts WITHID ( name character varying NOT NULL unique, )select blah, blah, blah from joinall (accounts, otherTable, maybeAnother) where blah
-
@Bort (You mean like MS Access? ... or MongoDB, for that matter?)
-
I work with a state-wide data system for all students. The state student unique identifier, sort of like an SSN, uses first name, middle name, last name, birth date and birth order to establish uniqueness when you enter them. In the district I work in we've got 8,000 students with roughly 700 (somewhat above 1 in 13) turning over every year. Looking up these names is a job that requires human interaction. A computer can't do it alone, because there's no way for a computer reliably match names. It's close, but it's actually surprisingly bad at it because they try to err on the side of caution. About once every 2 years we get a student matched up with another student in the state because their names and dates of birth match or almost match so that the state resolves them incorrectly, and several times a year we have to merge unique identifiers because extra ones get generated in error due to miskeyed names or dates or legal name changes.
Natural keys can work just fine, but they're a lot more rare than you'd think. Consider a file system. On Windows, the path is the unique identifier. That's why Windows won't let you rename or move a file that's open. The handle is to that path. It's also why you can't have a file and a folder with the same name in the same folder. On Linux, however, the path isn't guaranteed to be unique. You can have file and folder names with the same name in the same folder (which is often confusing and is generally discouraged) because Linux uses a hidden surrogate id. Of course, this means you've got to store that extra identifier on disk, too, and because it's hidden you're never exactly requesting what the OS presents to the user.
The biggest problem with surrogate keys is just that they don't have any meaning. If you want to resolve the value back into data that has meaning to the user, you've got to do a join. That doesn't mean bad performance, but it's not a free operation, either.
-
@Bort Actually, this is one thing RoR gets right; IIRC, every data table the ORM creates has an
idfield for an SK automagically, though I'm not sure if you can override it or not - in general, translation relations don't need one, and since RoR special-cases lookup tables, I expect that they avoid them there, but I don't know if they can be turned off in general.
-
@blakeyrat said in Surrogate vs natural primary keys:
@Dragnslcr said in Surrogate vs natural primary keys:
I always keep a serial field as the primary key.
Nowadays, it's more future-proof to use a GUID (or "uniqueidentifier" in MS SQL-speke).
Eh. I'd never use them as a primary key. A GUID can be generated at any point in time if you need to serialize or integrate two data systems.
ALTER TABLE [dbo].[MyTable] ADD [GUID] uniqueidentifier NOT NULL DEFAULT NEWID();Pre-generating them just means storing and managing extra data. If every data system generates a GUID, you still have to build a map between the two systems.
You're certainly not exhausting BIGINT. You can generate 3 billion records every second and you'll need almost 100 years to run out. You'd need over 67,000,000 TiB of storage just to store the keys with no overhead. One year of keys alone would be about ten times the estimated size of the entire Internet.
-
@BaconBits said in Surrogate vs natural primary keys:
@blakeyrat said in Surrogate vs natural primary keys:
Nowadays, it's more future-proof to use a GUID (or "uniqueidentifier" in MS SQL-speke).
Eh. I'd never use them as a primary key.
You'll have to if you have a clustered/distributed database (I forget which it is that requires GUID keys)
-
@boomzilla said in Surrogate vs natural primary keys:
I always avoid natural ids. You can still put a unique index on it (I assume your RDBMS supports that) if you really need to. But always have a surrogate key.
The cost and time involved in making a surrogate key and doing it correctly is so negligible that the only reason you could possibly have for not doing it right is that you hate the company/people you work for and desire for the product to fail at some future date when things need to be updated/changed.
edit - quoted
 only as an extension of his line of thought. The "you" in my reply references
only as an extension of his line of thought. The "you" in my reply references 
-
@BaconBits said in Surrogate vs natural primary keys:
Eh. I'd never use them as a primary key. A GUID can be generated at any point in time if you need to serialize or integrate two data systems.
Why wouldn't you use a GUID as a key?
-
@boomzilla said in Surrogate vs natural primary keys:
Why wouldn't you use a GUID as a key?
Slower comparison than using an integer is the only reason I can think of
-
If you allow your "primary key" to be altered. Keep the surrogate.
In my project I'm working on now, the only thing that's a natural primary key is Kelvin temperature, but it's also a single column table.
Because, obviously, if those values change meaning, that whole table will change anyway.
The only time I'd recommend natural keys is on a table that doesn't allow the key to update, and preferably doesn't allow updating at all.
-
@xaade said in Surrogate vs natural primary keys:
Kelvin temperature, but it's also a single column table
....wat.
-
@RaceProUK and necessitates adding another column (depending on the DB, some have that built into the DBMS) to easily determine order of insertion, if you cared about that.
Though I have no problem with the use of GUIDS for keys, I usually go with ints (or bigints) personally.
-
@Yamikuronue i am also.
To what do you join the Kelvin table that makes its existence have any point at all if it only has one column?
-
@darkmatter said in Surrogate vs natural primary keys:
easily determine order of insertion, if you cared about that
The only times I've found order of insertion to be important, there's been a timestamp column that serves a business-relevant purpose already
-
@RaceProUK said in Surrogate vs natural primary keys:
@boomzilla said in Surrogate vs natural primary keys:
Why wouldn't you use a GUID as a key?
Slower comparison than using an integer is the only reason I can think of
Has anyone ever measured this? Like I said, sounds bogus to me.
-
@boomzilla An integer is 4-8 bytes, a GUID is 16 bytes; more bytes == slower.
In the real world, the difference is negligible.
-
The most useful instance I can think of regarding natural keys is if you work with a distributed system in which rows are eventually aggregated (think of a single patient visiting multiple health care providers and the insurance ID number being used to aggregate all those visits into a single history on some central server). Even in systems like that, use of surrogate keys at each node isn't precluded, even though the insurance ID is the replication key. With respect to using natural keys everywhere, that can be dispelled with a single question: do you want to update one, or 20, or 200, or 2000 tables every time X changes?
-
@boomzilla said in Surrogate vs natural primary keys:
Why wouldn't you use a GUID as a key?
Sequential IDs are a nice-to-have when your table doesn't have a timestamp column and you want to see the last entered record when debugging or something like that. Other than that... *shrug*. For most purposes, there's no difference - unless there's a risk of IDs colliding, or you have a really huge data set and the key length counts.
-
@cartman82 said in Surrogate vs natural primary keys:
Where is the dividing line for you between surrogate and natural id-s?
An interesting topic. My take is a bit different from other people's here: there can be times when you get an ID from the external world that really is an ID (as in “it always refers to the same thing”) and those times are when a natural ID is actually possible. We have such a case in my current project, where we generate IDs for all sorts of bits of DNA and RNA and cell samples and stuff like that generated in our lab. Each of these physical things gets assigned an ID and that then persists even if the database was to be destroyed. For various reasons, our IDs consist of a code indicating the lab (because there's a habit of sometimes sending things to other labs), a second code that indicates what the heck the thing is in general (because otherwise one tiny little frozen tube looks very much like another one) and then a sequence number. The lab manager adamantly insists that sequence numbers be really sequential. Will the ID ever change or be reused? No, but the understanding of the ID might (as in we might go from thinking “this is our 73rd test run” to “this is the one that works and earns us $10M”). We can also give names to things, but they're non-unique; the IDs really are IDs and have to be because cross-contamination would just turn all the results to BS or end up causing us headaches with tracking the provenance of the sample (which also matters a lot for complicated reasons).
Most things in life aren't IDs, true. Names definitely aren't, and nor are US SSNs apparently. But most is not the same as all; genuine keys can sometimes be found in the wild, often because somewhere actually really cares about detailed tracking of the identity of things.
Our computational biologists on staff are happy with using GUIDs or UUIDs for their things. Our lab staff aren't, in part because you can't legibly fit a GUID on the labels that go on the side of the tubes…
-
@boomzilla said in Surrogate vs natural primary keys:
@BaconBits said in Surrogate vs natural primary keys:
Eh. I'd never use them as a primary key. A GUID can be generated at any point in time if you need to serialize or integrate two data systems.
Why wouldn't you use a GUID as a key?
- GUID is 16 bytes and int is 4; if your table is wide but isn't expected to have billions of rows, this can add up to a lot of savings since every row in every index on the table needs to contain the clustering key (at least in SQL Server).
- GUIDs are generally random, and inserting random data leads to fragmented indexes, which if not rebuilt will cause accesses to become less efficient. This can be remedied somewhat using
NEWSEQUENTIALID(), but that's still not as predictable as a monotonically increasing integer.
Now, GUIDs are great for replication keys, but in tables where I use them as such, I typically also have int identity as the clustering key.
-
@boomzilla said in Surrogate vs natural primary keys:
@BaconBits said in Surrogate vs natural primary keys:
Eh. I'd never use them as a primary key. A GUID can be generated at any point in time if you need to serialize or integrate two data systems.
Why wouldn't you use a GUID as a key?
In SQL Server, usually the primary key is a clustered index. That means they're stored in sorted order on disk. So, if you have a table with IDs like 1, 3, 4, 5, 8, 9. Now you insert a 6. It doesn't insert it at the end. The DB actually moves the data to make room for ID 6. You can pad the index (leave gaps) to help compensate for this issue, but it still happens.
You can have tables that have only nonclustered indexes (known as heaps) or tables that have the clustered index as a unique key instead of the primary key, but clustered indexes must be unique and can significantly improve performance, especially if your clustered index is done correctly and you're retrieving data from rows that are grouped together on disk.
Now. think about GUIDs. They're essentially random. Indeed, the
NEWID()function in SQL Server generates a v4 GUID, which is almost entirely random (106 bits are static). So if your uniqueidentifier column is the primary key and has the clustered index, then inserting data in your table means the server will essentially always have to move other data out of the way in the index. You can work around it usingNEWSEQUENTIALID(), but I tend to just avoid them because GUIDs are kind of a pain in the ass to work with.Finally, as a DBA and systems analyst the last thing I want to do is stare at a list of GUIDs. Developers may not ever see a primary key. Users may not ever see a primary key. I do. I look at them and use them all day. I can deal with lists of numbers. If they're 10 digits or less, I can even remember them well enough to recognize them sometimes. A list of GUIDs, however, will make your eyes bleed. There's no hexadecimal keypad on my keyboard. The value of a GUID doesn't have any implications, either, while ye olde
BIGINT IDENTITY(N,1)means I can tell by looking roughly how long that ID has been in the system. If IDs are staggered, say with employees beginning at 500000, students begin at 1000000, state student IDs are 10 digits, and state staff ids are 5 digits, then you know immediately by looking at the ID if it's a teacher or a student. And if it's a number that doesn't fit one of those schemes, then you can say, "Ah, I know what this is: an error." If everything is a GUID, then even that meager level of meaning is totally lost. I can't validate what a GUID even is until I search through everything. Hell, maybe it's some GUID saved in the IIS logs, but if I've got half a dozen systems and their keys are all GUIDs... it's basically impossible to tell what the value is.That's why business IDs are so essential, and why a basic incrementing integer is good enough for a business ID. Sure, you can stick a letter or three on the front of it if you want, like PO- for purchase order or R- for requisition, too, but ultimately I want a human readable number, not a binary string.
-
@dkf said in Surrogate vs natural primary keys:
We have such a case in my current project, where we generate IDs for all sorts of bits of DNA and RNA and cell samples and stuff like that generated in our lab. Each of these physical things gets assigned an ID and that then persists even if the database was to be destroyed.
But aren't you basically generating the ID as a surrogate key? The ID you made in your case is designed as a human-made surrogate key and has no other purpose other than as an ID to refer to some bit of information.
As an aside, I'd never heard using a unique bit data itself as a key called a "Natural Key". Always heard it called an "Intelligent Key" - maybe just the background in OLAP Data Warehousing more so than OLTP production systems?
And I just remembered that I'm thinking of the wrong definition here. An "Intelligent Key" (or "Smart Key") is when you reuse an existing unique production key (whether that key was a surrogate or not) in your Data Warehouse system.
-
One of the things that conventional RDBMS systems don't make clear is that in RDT, relations are sets of tuples - they have no 'natural' ordering to them, so all ordering in a relational database is (or should be) through an index. Keys are not themselves a means for ordering a relation, though any index entry will (or at least should) map to a candidate key. Tuples themselves (which are usually visualized as a row in a table) also have no fixed order, and the mapping of attribute values in a relvar tuple to attribute (column) names in the relation has no fixed order - attribute names can be seen as a specialized sort of indexing.
Also, a candidate key is any set of one or more attributes in a tuple whose values, taken as a whole, are guaranteed to uniquely identify that tuple. A relation (usually visualized as a table structure - though an actual value-containing table would be a relvar in modern terms) can have several candidate keys, any of which can be used as the primary key if consistency is ensured.
That last part is where things most often break down in practice, hence the advice of adding a surrogate key instead of using one of the candidate keys from the natural data. The whole point of using an automatically generated surrogate key is that it gives the relvar's tuples unique identifiers which are independent of the consistency of the data itself. Consistently using a SK for data that has to be uniquely identified (i.e., pretty much everything except translations, which contain only keys and don't usually need to be ordered, and derived relvars (views), which are just runtime presentations of data in other relvars) is a defensive programming practice which, while not absolutely necessary, is almost always wise.
-
@Groaner said in Surrogate vs natural primary keys:
inserting random data leads to fragmented indexes,
For certain specialized DB systems (think Netezza), GUIDs are not even a thing, and therefore terrible in performance because it's just a string/char there.
But I think most of us discussing here are excluding DBs that don't even do GUIDs, since clearly they wouldn't be a wise option there. And Netezza isn't an OLTP system anyway.
-
@darkmatter said in Surrogate vs natural primary keys:
The ID you made in your case is designed as a human-made surrogate key and has no other purpose other than as an ID to refer to some bit of information.
It's the other way round. The information in the database is considered to be secondary to the physical entity; and we could (with much cost and annoyance) rebuild 40–50% of the info in the database even if we lost the DB entirely and had no backups, possibly more (depending on how much is in lab notebooks). The other way round — having the database but not the physical — would be astonishingly worse; the data is almost entirely valueless without the physical; I only know of one lab that works that way (in Boston) and they're a total outlier in this business.
I think I did say that ours was not a typical case.

-
@BaconBits said in Surrogate vs natural primary keys:
You can have tables that have only nonclustered indexes (known as heaps) or tables that have the clustered index as a unique key instead of the primary key, but clustered indexes must be unique and can significantly improve performance, especially if your clustered index is done correctly and you're retrieving data from rows that are grouped together on disk.
 Effective Clustered Indexes - Simple Talk
Effective Clustered Indexes - Simple Talk
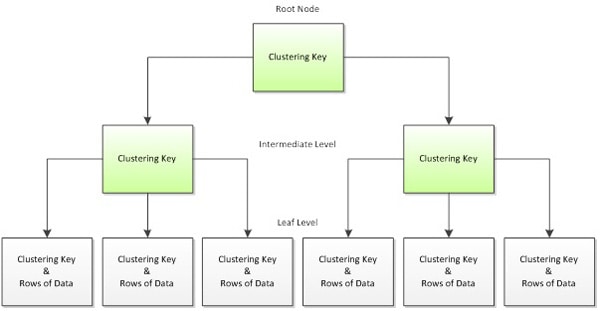
As a guideline, clustered Indexes should be Narrow, Unique, Static and Ever Increasing (NUSE). Michelle Ufford Explains why.
apropos here - one of the examples includes an GUID key and an int surrogate key (i assume the GUID is a foreign key to a different table), suggesting that the clustered index should go on the int column.
-
@darkmatter said in Surrogate vs natural primary keys:
As an aside, I'd never heard using a unique bit data itself as a key called a "Natural Key". Always heard it called an "Intelligent Key" - maybe just the background in OLAP Data Warehousing more so than OLTP production systems?
And I just remembered that I'm thinking of the wrong definition here. An "Intelligent Key" (or "Smart Key") is when you reuse an existing unique production key (whether that key was a surrogate or not) in your Data Warehouse system.
-
@darkmatter said in Surrogate vs natural primary keys:
For certain specialized DB systems (think Netezza), GUIDs are not even a thing, and therefore terrible in performance because it's just a string/char there.
Meh. I use Oracle and they seem to perform just fine as strings (
varchar2(32)in fact).
-
@boomzilla said in Surrogate vs natural primary keys:
@darkmatter said in Surrogate vs natural primary keys:
For certain specialized DB systems (think Netezza), GUIDs are not even a thing, and therefore terrible in performance because it's just a string/char there.
Meh. I use Oracle and they seem to perform just fine as strings (
varchar2(32)in fact).Hm. I thought Oracle GUIDs were stored as
RAW(16)since that's what the Oracle GUID function returns. Or is dealing with RAW got some caveats? I've only got passing exposure to Oracle.
-
@BaconBits said in Surrogate vs natural primary keys:
You're certainly not exhausting BIGINT. You can generate 3 billion records every second and you'll need almost 100 years to run out.
The point isn't "running out" of BIGINT.
The point is with GUID IDs you can run two entirely separate databases, and then cleanly merge their data back together at any time. Call it "poor man's clustering".
With a serial numbering system, the two databases would have the coordinate with each other and negotiate which ranges of serial number they're allowed for each table, etc. It's certainly possible to do (Twitter, for example, does that-- considering the number of records they have, a pretty impressive technical achievement), but it's a million times more complex than simple using a GUID as your key in the first place.
-
@boomzilla said in Surrogate vs natural primary keys:
Has anyone ever measured this? Like I said, sounds bogus to me.
My kneejerk also is that there's no measurable performance impact, as long as the key is fixed-width (which both BigInt and UniqueIdentifier are). But admittedly I haven't measured it.
EDIT: I should also note that, in MS SQL at least, UniqueIdentifier isn't simply a Char(16) or whatever. It's a distinct type. Meaning: it's quite possible it has some optimizations applied to it that wouldn't apply to an equivalent Char(16) key.
-
@dkf said in Surrogate vs natural primary keys:
and nor are US SSNs apparently
People thinking SSNs are unique is a HUGE pet peeve of mine. All of the following are true:
- There exist US Citizens with no SSN
- There exist multiple US Citizens with the same SSN
- SSN was never intended to be a unique identifier of US Citizens in the first place; it's exactly what it says it is: a number to identify an eligible recipient of social security benefits
- Your application will, sooner or later, almost certainly have to deal with a person who is not a US Citizen and thus wouldn't even be expected to have an SSN
That said, most US States have an ID number that's guaranteed to be unique for each citizen of that State. (Except rule 1 still applies: not all citizens will have one; you can go your entire life without ever registering for a State ID.)
The US isn't big on the whole "numbering people" thing. Basically. Despite the TSA's best efforts, we still just don't really do it.
-
@BaconBits said in Surrogate vs natural primary keys:
Hm. I thought Oracle GUIDs were stored as RAW(16) since that's what the Oracle GUID function returns. Or is dealing with RAW got some caveats? I've only got passing exposure to Oracle.
I remember proposing to do it that way (nearly a decade ago), but got overridden as strings being easier to deal with in many situations (which is probably true). So we use
sys_guid()when we need to generate one using sql (most of them at this point are generated for us by hibernate) and I guess the raw value gets turned into a varchar2 automatically.
-
@BaconBits said in Surrogate vs natural primary keys:
In SQL Server, usually the primary key is a clustered index.
Only if you're an idiot. If you want insert performance, don't define a clustered index and have a heap. Insert performance is better for heaps than for tables with a clustered index on a sequential key. The latter sometimes has advantages (e.g. smaller row references in non-clustered indexes), but not nearly enough to make it a good idea in most cases.
In most cases, the best choice for a clustered index is either a foreign key or a date column that is often used for range searches.
-
@cartman82 said in Surrogate vs natural primary keys:
Since these account names will come from a third party, I have no idea how large they'll be. Also whether there'll be rename issues. Then maybe I should keep surrogate Id-s... except, they look godawful ugly and superfluous.
That should be lightning striking you the bollox inspiration for having a surrogate key.
Also what @blakeyrat said.
-
@blakeyrat said in Surrogate vs natural primary keys:
The US isn't big on the whole "numbering people" thing. Basically. Despite the TSA's best efforts, we still just don't really do it.
The UK's pretty much the same, to be frank. I've got a SSN and I guess it's unique enough for government, but I can never remember it as it is only for tax and benefits purposes. Every so often a politician decides to try to clean up the horrible mess that's ensued from that, and every time they give up on it after a while as being far too hot a political potato…
-
@Bort said in Surrogate vs natural primary keys:
Is there anything that lets you do that or is there some reason why it's impossible/bad idea?
CREATE TABLE accounts WITHID ( name character varying NOT NULL unique, )select blah, blah, blah from joinall (accounts, otherTable, maybeAnother) where blahThat's disturbingly similar to the syntax many database vendors used for joins before there was an ANSI standard. It turned out to be an awful idea to have the list of tables in the FROM clause and the join criteria in the WHERE clause.
-
My thinking is that you should treat natural keys as "identifiers", but don't make programmatic assumptions, eg about uniqueness or staticness. If you need a completely unique key to identify a record, make an "id" field. You can "control" that field, and can assume anything you want about it.
Natural keys are great, but to use them as keys, you need to take into account the semantics of how/why/when they can change. And then you need to model that in the database. YAGNI.
Just get on with it, and worry about the semantics of natural keys when you write queries.
-
@Bort said in Surrogate vs natural primary keys:
Is there anything that lets you do that or is there some reason why it's impossible/bad idea?
CREATE TABLE accounts WITHID ( name character varying NOT NULL unique, )Of all engines, oracle allows you to do this (with UNIQUE, PRIMARY KEY, REFERENCES <table.column>, and others). Of course you'd probably be using
VARCHAR2(255).select blah, blah, blah from joinall (accounts, otherTable, maybeAnother) where blahIsn't that called a 'natural join'? I think I've seen them in Access, and they had the weak spot that if no suitable relation existed you got a cartesian product instead.
@Maciejasjmj said in Surrogate vs natural primary keys:
Sequential IDs are a nice-to-have when your table doesn't have a timestamp column and you want to see the last entered record when debugging or something like that.
On oracle again, I've seen a sequence field and a timestamp column disagree on the appropriate record order. Both were generated on insert.
-
@dkf The newest thing is TSA imposed standards on State ID cards (driver licenses, usually, although most States issue non-driver-license ID cards) which States were required to follow, on the theory that then the State ID number could be used as a national ID number.
Washington State, and a few others, said "screw you". Basically the TSA was trying to force this through, but completely unwilling to pay for implementation of any of it, and so we didn't. There was a lot of fear-mongering from the Feds about "Washington State citizens won't be able to fly, they'll be rejected by the TSA at the security line!" but guess what? Much ado about nothing. They ended up "extending" the deadline, as everybody knew they would.
From that link:
State law currently prohibits the expenditure of state funds to comply with the REAL ID Act. See RCW 46.20.191 and 43.41.390.
(Not only do we not comply, but we don't comply by law, to the TSA's requirements.)
Strangely, the article calls-out a foreign issued passport as valid ID (if the TSA does make good on their threats), but does not talk about a US-issued passport. Huh?
-
@Maciejasjmj said in Surrogate vs natural primary keys:
Sequential IDs are a nice-to-have
… and also a potential security / privacy hole. Keys should not be guessable.
The comparison overhead of 16 bytes vs 4 is trivial, especially if you consider a tree structured index based on GUIDs vs sequential IDs. In most cases, you could probably get away with a good 32 bit hash of some unique string, but you're risking hash collisions as well as string collisions, and guids obviate that entirely.