The Official Status Thread
-

I don't see myself needing this but at least it's finally here
-
@topspin said in The Official Status Thread:
Status:
 'Okay, looks like this application spends most of its time in this single function.'
'Okay, looks like this application spends most of its time in this single function.'
slaps #pragma omp parallel foraround the loop.
 uses 8x100% CPU instead of 1x100% CPU.
uses 8x100% CPU instead of 1x100% CPU.
processing time drops from ~100s to ~70s.Processing time of that one function, or total?
-
@Gąska said in The Official Status Thread:
@topspin said in The Official Status Thread:
Status:
'Okay, looks like this application spends most of its time in this single function.'
slaps #pragma omp parallel foraround the loop.
uses 8x100% CPU instead of 1x100% CPU.
processing time drops from ~100s to ~70s.Processing time of that one function, or total?
Assumed total.
-
@Gąska said in The Official Status Thread:
@topspin said in The Official Status Thread:
Status:
'Okay, looks like this application spends most of its time in this single function.'
slaps #pragma omp parallel foraround the loop.
uses 8x100% CPU instead of 1x100% CPU.
processing time drops from ~100s to ~70s.Processing time of that one function, or total?
Total. But since that one function takes about 80-90% total it’s not Amdahl’s law which is messing things up (that’d get me down to 20-30s).
-
@topspin maybe now that you've parallelized it, each thread is redoing the calculations that were previously cached by the optimizer. That, or memory access patterns, or some other kind of data dependency, or accidental synchronization. Of course I'm just guessing here; it might be something else entirely.
-
@Gąska said in The Official Status Thread:
@topspin maybe now that you've parallelized it, each thread is redoing the calculations that were previously cached by the optimizer.
I'm not sure what you mean by that.
That, or memory access patterns,
Are definitely different, since now I'm processing in chunks instead of going through linearly. I'd hope those chunks are large enough for access not to be completely random, but
 .
.or some other kind of data dependency, or accidental synchronization.
There's no locks that I'm aware of, so unless it's on
malloc(which would be bad but IDK) there shouldn't be lock contention.Not sure how to measure either of these things, and I forgot how to use those super-unintuitive Intel performance tools.
Of course I'm just guessing here; it might be something else entirely.
The things I've thought of as possibilities are:
- the synchronization overhead after the loop is too high.
- the individual threads don't get enough work scheduled.
I.e., while most of the time is spent in that function, individual function calls might not take long enough for parallelization to be efficient.
The function itself computes a time-step and for the 100s example that was 2000 steps, which are inherently sequential (causality is a bitch). So a single call is on the order of 50ms, which I thought is long enough to dwarf sync overhead, but maybe I'm wrong there.Any suggestions welcome.
-
@topspin said in The Official Status Thread:
@Gąska said in The Official Status Thread:
@topspin maybe now that you've parallelized it, each thread is redoing the calculations that were previously cached by the optimizer.
I'm not sure what you mean by that.
With single threaded code, the compiler can do more optimizations than in multithreaded code. Maybe one of those optimizations was critical for performance. If you feel adventurous, maybe you could try comparing the machine code of the compiled loop, with and without multithreading, and see if there are significant differences? You might also try timing just a single iteration, again with and without threading.
That, or memory access patterns,
Are definitely different, since now I'm processing in chunks instead of going through linearly. I'd hope those chunks are large enough for access not to be completely random, but
.You might want to try out different chunk sizes. CPU cache isn't freeform scratchpad - particular memory locations can only be read into particular cache lines. In result, certain strides in concurrent reads cause cache collisions even if there's plenty of cache memory left. Especially dangerous are powers of two. So making chunks a little bit larger or a little bit smaller might improve performance.
The things I've thought of as possibilities are:
- the synchronization overhead after the loop is too high.
- the individual threads don't get enough work scheduled.
I.e., while most of the time is spent in that function, individual function calls might not take long enough for parallelization to be efficient.
There's this possibility too, unfortunately.
-
@Gąska said in The Official Status Thread:
@topspin said in The Official Status Thread:
@Gąska said in The Official Status Thread:
@topspin maybe now that you've parallelized it, each thread is redoing the calculations that were previously cached by the optimizer.
I'm not sure what you mean by that.
With single threaded code, the compiler can do more optimizations than in multithreaded code. Maybe one of those optimizations was critical for performance. If you feel adventurous, maybe you could try comparing the machine code of the compiled loop, with and without multithreading, and see if there are significant differences? You might also try timing just a single iteration, again with and without threading.
Because of the way things are set up, the loop body (the function called in the loop body) just sees a different (continuous) range to work on. I might try, if I get around to it, but I doubt there’s much to optimize there.
That, or memory access patterns,
Are definitely different, since now I'm processing in chunks instead of going through linearly. I'd hope those chunks are large enough for access not to be completely random, but
.You might want to try out different chunk sizes. CPU cache isn't freeform scratchpad - particular memory locations can only be read into particular cache lines. In result, certain strides in concurrent reads cause cache collisions even if there's plenty of cache memory left. Especially dangerous are powers of two. So making chunks a little bit larger or a little bit smaller might improve performance.
What I actually did was set the chunk size to basically
N / omp_get_num_threads()in an effort to make them as close to the single thread case as possible, i.e. there’s only 8 chunks at most. I’ll try playing around with different sizes, maybe it helps.
There’s a good chance both single and multi-threaded versions have crap memory access patterns.The things I've thought of as possibilities are:
- the synchronization overhead after the loop is too high.
- the individual threads don't get enough work scheduled.
I.e., while most of the time is spent in that function, individual function calls might not take long enough for parallelization to be efficient.
There's this possibility too, unfortunately.
In which case I unfortunately don’t know how to improve things. :(
-
@topspin said in The Official Status Thread:
There's no locks that I'm aware of, so unless it's on malloc (which would be bad but IDK) there shouldn't be lock contention.
Malloc almost always has locks unless you've gone to the trouble of getting a lock-free one.
-
@heterodox I read that Linux's default malloc uses multiple memory arenas with independent mutexes specifically to avoid waiting for locks between threads. I'd be surprised if Windows was any different, too.
-
@heterodox said in The Official Status Thread:
@topspin said in The Official Status Thread:
There's no locks that I'm aware of, so unless it's on malloc (which would be bad but IDK) there shouldn't be lock contention.
Malloc almost always has locks unless you've gone to the trouble of getting a lock-free one.
That’s why I mentioned it. There’s definitely lock free ones, but I don’t know off-hand what the default is. What I meant is that even if it’s not lock-free, if the code bottle-necks on malloc then there’s a lot more wrong with it.
-
@topspin said in The Official Status Thread:
What I meant is that even if it’s not lock-free, if the code bottle-necks on malloc then there’s a lot more wrong with it.
Oh, okay. I thought you meant it'd be bad if malloc had locks (understandable misconception).
-
@topspin said in The Official Status Thread:
so unless it's on
malloc(which would be bad but IDK)Malloc has a lock inside. It has to, since it can't assume that only one thread ever allocates, that two threads never allocate at once, or that what was allocated in one thread will also always get freed in that thread. It can keep per-thread pools, but that's complex in other ways. (It's a good rule of thumb to assume that malloc is expensive.)
-
@dkf See above. I might have been unclear about that.
-
-
Status: to the beat of Adventure Time
Baking cheesecake, baking baking cheesecake...
-
Status: wet.
-
@Benjamin-Hall said in The Official Status Thread:
status the appropriate time to start cataloguing my fiction collection would have been a while ago, before I had books on 3 platforms (including physical). Not as many duplicates as I feared, but it will be annoying getting everything documented in the same place.
Edit: not that I have tons, maybe 110 physical and about that (?) in ebook format on Kindle and Google play books.
Lightweight. I have a barcode scanner (it was only about $20, what the hell...) and went thru all my books and scanned them. Used Calibre to do the ISBN lookups (yeah, some failed so required manual updating). I have 965 books documented (I use it to also keep track of what Kindle books I've checked out of the library).
-
@dcon said in The Official Status Thread:
I have a barcode scanner (it was only about $20, what the hell...)
Sounds like a phone app problem.
-
@PleegWat said in The Official Status Thread:
@dcon said in The Official Status Thread:
I have a barcode scanner (it was only about $20, what the hell...)
Sounds like a phone app problem.
yeah. I have a phone app that does the lookup itself and stores everything
-
Status: It took an extra 3½ hours to get into work today, all because of one idiot chaining himself to a bridge at a station.

-
@Benjamin-Hall said in The Official Status Thread:
I have a phone app that does the lookup itself and stores everything
But it's much more fun to build one yourself

-
Status: it begins....

-
@Cursorkeys said in The Official Status Thread:
it's go for resigning
That was really painful. Both my boss and the MD were sad and also very complimentary.
Anyway, new opportunities. And I'm going to seize the hell out of them.
-
Status: fucking hell. (
 ) There's a set of lights I pass through every day, and I swear I'm not exaggerating if I say that at least one third of the time I get there, it's just turned red.
) There's a set of lights I pass through every day, and I swear I'm not exaggerating if I say that at least one third of the time I get there, it's just turned red.
-
@kazitor said in The Official Status Thread:
Status: fucking hell. (
) There's a set of lights I pass through every day, and I swear I'm not exaggerating if I say that at least one third of the time I get there, it's just turned red.You're obviously not going the speed limit. If you were, it would barely be turning yellow by the time you got there.
-
@Tsaukpaetra This is cycling to a pedestrian crossing. If the lights were yellow, I might have just enough time to smash the button.
What also annoys me is that, even though the crossing signal goes off three seconds after the light goes red, pressing the button within those three seconds doesn't actually let you cross until the next cycle.

-
@kazitor said in The Official Status Thread:
What also annoys me is that, even though the crossing signal goes off three seconds after the light goes red, pressing the button within those three seconds doesn't actually let you cross until the next cycle.
Correct, due to how they designed the state machine, inputs are only considered at the beginning of state change cycle. Once that cycle is in progress, nothin' ain't gonna change it. Not even cops.
-
Status: Deafuq?
NextStatus: How the hell do I check mail in unix-likes?
-
@Tsaukpaetra said in The Official Status Thread:
Once that cycle is in progress, nothin' ain't gonna change it. Not even cops.
It takes a man with a control system to do that. That might be possible remotely, or might require physically opening a discreet cabinet near the junction. (Wireless control is possible, but unlikely.)
-
@Tsaukpaetra said in The Official Status Thread:
How the hell do I check mail in unix-likes?
mailIt's horrible.
-
@dkf Luckily, I think the only thing sending me mail in such mailboxes is
crond.Hm, wonder if I can redirect that…
EDIT: Just add
MAILTO=pleegwat@what.thedailywtf.comat the top of the crontab file.
-
@Tsaukpaetra said in The Official Status Thread:
How the hell do I check mail in unix-likes?
cat /dev/null >/var/spool/mail/root
-
@topspin
That's a lot of waiting there:
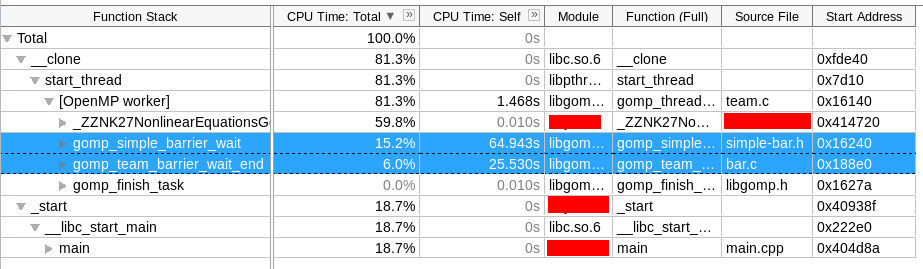
-
Status: One more hour in the office before I take a half-day to go get my car inspected. I can't be arsed to do anything else substantial for the day.
-
status RIP SLASH BURN!!!
I love deleting obsolete code. (murdering those tentacles is what the compiler is for)
-
-
@hungrier said in The Official Status Thread:
tentacles
Are you sure you're not just shooting aliens?
I feel like it... Trying to verify I didn't break something and the test I'm doing is failing. But I don't think it's because of the code I killed...
Edit: recompile (and login using a different user) and it works now. Whew.
-
@dcon said in The Official Status Thread:
status RIP SLASH BURN!!!
For a moment, I was like "who the hell is Slash Burn?"
-
@Gąska said in The Official Status Thread:
@dcon said in The Official Status Thread:
status RIP SLASH BURN!!!
For a moment, I was like "who the hell is Slash Burn?"
Sounds like an Alicorn OC. Likely red and black, with scars all over.
-
@Tsaukpaetra RIP red and black alicorn OC.
-
Status: What the fuck did Facebook do now that “request desktop site” doesn’t work?! Show me the fucking desktop site, because you’re not going to make me install your fucking messenger app when I know it works perfectly well using just the website.
Fuckers.
-
Microsoft: ".NET core is a stable product"
.NET core:

-
@anonymous234 That's stable as in "it's in the stable"
-
Status: I've been
Please wait for a moment...ing for about an hour now. I think it's dead.
-
Status: Resisting the urge to post Garage-y replies in non-Garage topics.
-
@HardwareGeek said in The Official Status Thread:
Status: Resisting the urge to post Garage-y replies in non-Garage topics.
I thank you.
-
Status: One hour to go. Bored.
-
Status: Fucking docs.
http://api.unrealengine.com/INT/API/Runtime/Core/Containers/operatornew/3/index.html

Sweet! What does that look like, to someone who doesn't know what that means?
Offending code:

I think it means it should instead be:

???

-
@Tsaukpaetra I don't think those are the same at all. The first puts the
FTexture2DMipMapobject directly atTextureToApplyTo->PlatformData->Mips, and the second presumes that there's an object already there that you add the newly-createdFTexture2DMipMap(which was allocated on the general stack) to. The layout of the two in memory is different.
