In which I show how referential integrity is not a thing here
-
Who cares, anyway. To fuck with that.
-
@wft we're not even running a RDBMS...
-
@Onyx that's the point.
I'm now working in a project where the dumbfucks chose Mongo instead of a database for data that's... well, relational in its nature. They imported some data into a test environment and they cannot even make the data match even on a single screen. I mean, it was all cool and dandy on generated data, but wherever there's data migrated from a live customer, there's a lot of BS.
Fuck. Kill 'em with fire, won't shed a single tear.
-
@wft said in In which I show how referential integrity is not a thing here:
they cannot even make the data match even on a single screen
Maybe I'm TR
 but... how does your backing storage engine play into this issue? I mean, when you need the same data in multiple places, shouldn't you store it in an accessible place in memory anyway, instead of going back to the DB multiple times?
but... how does your backing storage engine play into this issue? I mean, when you need the same data in multiple places, shouldn't you store it in an accessible place in memory anyway, instead of going back to the DB multiple times?
-
Yes, you are TR
. Local cacheing is irrelevant.If your data model allows you to have inconsistent, committed, data, it's fucked. That follows not only for the persistent part of your application (which may be a database, flat files, whatever), but also for the in-memory data you might be holding.
One of the ways you police the consistency of the persistent stuff is via referential integrity constraints on your database. Because no matter how good your coders might be, their code will try to insert invalid data. It will try to update existing data into an invalid state. So you might start from some wonderful data model, but within minutes, you've got a database that's effectively corrupt.
-
If we have no other sort of integrity, why should we have referential integrity?
-
@tufty said in In which I show how referential integrity is not a thing here:
If your data model allows you to have inconsistent, committed, data, it's fucked.
Sure. But why are you storing the same data in multiple places at all? That's a modelling issue, not a storage engine issue, isn't it?
Or does Mongo not let you use any key references to stitch together on the client?
-
@tufty
 tra-la eventually consistent tralala!
tra-la eventually consistent tralala!
-
@Yamikuronue I don't think anyone but you has suggested that the same data was / is being stored in multiple places, let alone that it should be.
@Mikael_Svahnberg said in In which I show how referential integrity is not a thing here:
eventually consistent
A link to Wikipedia? Where data might be "eventually correct"?
-
@tufty So then how did it end up different in multiple spots on a screen? If you're not doing multiple data dips, and it's not being stored in multiple places in the database, how did you end up with two answers to the same question?
-
@wft what did you expect from a document DB emulating a key value store emulating an RDBMS poorly?
-
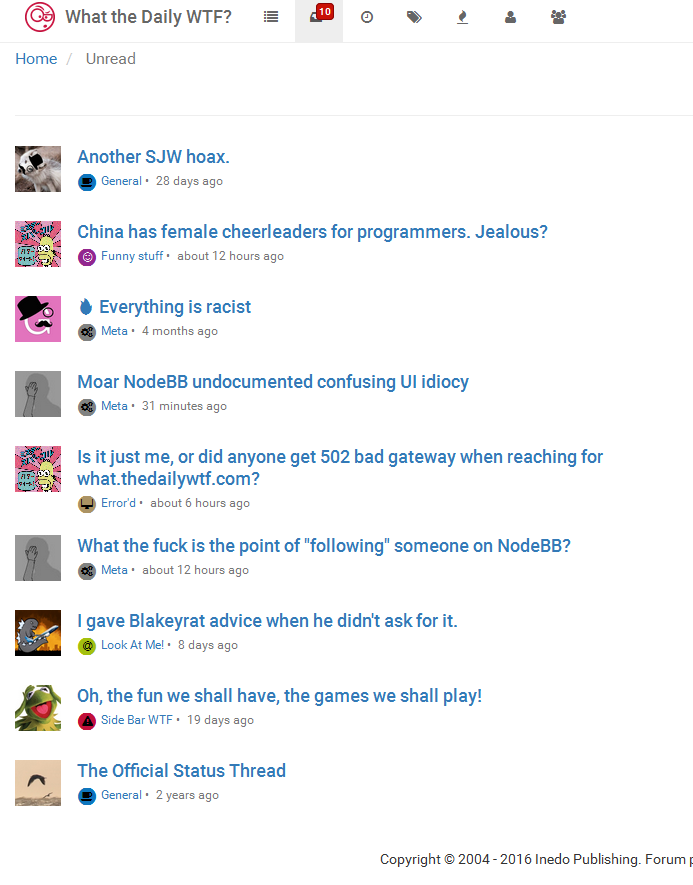
@Yamikuronue how does it end up with 2 unread notifications when there's only 1 unread notification in the list? (well, in the case of the unread notifications, it happens when 2 notifications combine... it counts a ghost notification until you do a hard refresh)
-
@anotherusername I have no idea
 Some terrible practice, I'm sure.
Some terrible practice, I'm sure.
-
@Yamikuronue it's semantically the same data, but physically it's extremely denormalized across multiple collections in multiple contexts.
-
@wft Ah, so it is stored in multiple places, as I expected. That clears it up
-
@Weng well, I'd expect it to not eat my sanity, but I think now it's rather stretching.
-
@Mikael_Svahnberg you're misusing the term in this context, methinks.
-
@anotherusername said in In which I show how referential integrity is not a thing here:
@Yamikuronue how does it end up with 2 unread notifications when there's only 1 unread notification in the list? (well, in the case of the unread notifications, it happens when 2 notifications combine... it counts a ghost notification until you do a hard refresh)
Shitty, shitty, very very shitty shit-filled shitty "queries".
I'm willing to bet there WHERE clause is different between the unread notification counter, and the unread page. An off-by-one, or they forgot that /unread ignores certain posts.
-
@Lorne-Kates I was assuming a race condition between two separate database dips myself.
-
@Lorne-Kates said in In which I show how referential integrity is not a thing here:
Shitty, shitty, very very shitty shit-filled shitty "queries".
I'm willing to bet there WHERE clause is different between the unread notification counter, and the unread page. An off-by-one, or they forgot that /unread ignores certain posts.The fact that hard refresh fixes the notification count discrepancy suggests to me that it's not actually getting a fresh count from the DB each time, rather it's client-side Javascript "counting" each incoming notification and getting off-by-one whenever an incoming notification combines with an existing one. And if a 3rd notification comes in and also combines, the count will be off by one more, so off by 2...
-
Isn't it just the list of unread topics failing to update while the "bubble" updates in real time?
-
@wft said in In which I show how referential integrity is not a thing here:
I'm now working in a project where the dumbfucks chose Mongo
No; they started with a key/value store (Redis? I think) then "ported" it to Mongo when they realized that Redis loses data ALL THE FUCKING TIME.
By "ported" what I mean is "use Mongo as a key/value store and ignore literally everything else about it". (Including the vastly smaller document size limitation which, I've said it before and I'll said it again, is sooner or later going to cause this forum to come crashing down.)
-
@Yamikuronue It could just be a matter of the data point (stored in a JavaScript object) got updated while the DOM (the part printed to the screen) did not.
-
@Yamikuronue said in In which I show how referential integrity is not a thing here:
@tufty said in In which I show how referential integrity is not a thing here:
If your data model allows you to have inconsistent, committed, data, it's fucked.
Sure. But why are you storing the same data in multiple places at all? That's a modelling issue, not a storage engine issue, isn't it?
Or does Mongo not let you use any key references to stitch together on the client?
Mongodb actually a) told you to de-normalize your data1) and b) only released the $lookup-function2) mere months ago.
1) Look at this little fun and dance where they tell you how to make MongoDB behave like a relational db: http://blog.mongodb.org/post/87892923503/6-rules-of-thumb-for-mongodb-schema-design-part-2
2) Said $lookup is a poor man's LEFT OUTER JOIN. Also, this here is simply hilarious: https://www.mongodb.com/blog/post/revisiting-usdlookup
-
@wft said in In which I show how referential integrity is not a thing here:
@Mikael_Svahnberg you're misusing the term in this context, methinks.
How so? It seems to fit, especially given my understanding of how Ben has set things up.
Granted, you would normally expect one particular view to be consistent with itself...
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
is sooner or later going to cause this forum to come crashing down.)
It already does that several times a day. We'd never be able to tell that it's the db's fault.
-
@Rhywden said in In which I show how referential integrity is not a thing here:
Mongodb actually a) told you to de-normalize your data
ArticleThe goal is reasonable - if you do a lot of reads and few writes, cache the JOINs.
But the suggested implementation is terrible - creating the cached JOINed results yourself in the application.
They could make progress here - give you the ability to specify which joins to cache, and make the DB automatically recalculate the cache if the other object is changed. But no, they give you nothing.And relational DBs have materialized views, which could be used for JOIN cacheing, without breaking integrity.
There is a case where traditional relational DBs fail - deeply recursive data, like graphs - there the noSQL DBs could be useful.
But a forum is definitely not one of those cases.
-
@Yamikuronue said in In which I show how referential integrity is not a thing here:
So then how did it end up different in multiple spots on a screen? If you're not doing multiple data dips, and it's not being stored in multiple places in the database, how did you end up with two answers to the same question?
You've managed to identify two possible ways this could be being done. Here's a non-exhaustive list, off the top of my head. Your two are first.
- race condition between two database round trips
- multiple storage of the same item on the database due to denormalisation
- multiple storage of the same item client side
- push of data to client missing some local state, leaving stale data in memory
- push of data to client missing certain interface elements, leaving stale data onscreen
- different code paths calculating differently leading to obiwan errors, either in memory, on screen, or on database.
- update collisions combined with failure to transaction properly and lack of referential integrity constraints leading to corrupt data on database
- update collisions combined with failure to correctly handle rollbacks client side leading to corrupt and / or stale data client side
- network dropouts leading to missed or partially missed updates.
That's just a few off the top of my head. Given that this "platform" doesn't actually have any meaningful tests, and can barely manage to struggle through posting, it would not surprise me in the slightest to find all of these issues and more.
It's suffering from web scale. It seriously needs some descaler.
-
@Weng didn't you try to implement this in mssql? Did you never get around to that?
-
@swayde I developed brain cancer trying to learn node to write the driver. And really, it wouldn't gain much without building a huuuuuge shim layer to work around the brain damage from starting with redis.
-
@Weng said in In which I show how referential integrity is not a thing here:
I developed brain cancer trying to learn node
I think that's a requirement

-
@loopback0 said in In which I show how referential integrity is not a thing here:
@Weng said in In which I show how referential integrity is not a thing here:
I developed brain cancer trying to learn node
I think that's a requirement
Start off in the shallow end learning Discourse and work your way up?
-
Developing brain cancer whilst trying to develop arse cancer. Must be some sort of record there.
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
(Including the vastly smaller document size limitation which, I've said it before and I'll said it again, is sooner or later going to cause this forum to come crashing down.)
Possibly, but I think it will be very very much later. The things that exist that could keep growing (OK, there could be stuff I'm not aware of or that get added in the future, but hey...) grow very slowly relative to the limit that you're worried about.
I think it's way down on the list of things that anyone should be worried about.
-
@boomzilla Oh well the software's broken but the breakage won't take effect for a little while so nothing to worry about! I R SOFTWARE ENGINEERS!!!!!W@
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
@boomzilla Oh well the software's broken but the breakage won't take effect for a little while so nothing to worry about! I R SOFTWARE ENGINEERS!!!!!W@
Fascinating. You really have no concept of prioritization and tradeoffs.
-
@boomzilla What trade-off? The code's either correct or not, and right now it's not.
Like... what are they trading this time-saving against? The UX is awful. The stability is awful. The MongoDB implementation critically flawed. So where did the time saved by coding it wrong go exactly?
How about I ask an opposite question, why does this forum have moronic features, like being able to set the background image of the header of your user page nobody looks at, before it has a working persistent database layer? These are your priorities? They ain't mine.
This has nothing to do with "priorities", it has everything to do with lazy developers who don't give a shit.
-
@Weng said in In which I show how referential integrity is not a thing here:
@swayde I developed brain cancer trying to learn node to write the driver. And really, it wouldn't gain much without building a huuuuuge shim layer to work around the brain damage from starting with redis.
I think you'd need to take their lookup keys (
_key) and break them up into table / id. I say break them up because stuff tends to get mixed in:So this:
'uid:' + uid + ':followed_tids'I think some get more complicated that that.
Then you'd need to understand how they deal with sets, sorted sets, scores, etc (I don't fully grok how all that works).
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
boomzilla What trade-off? The code's either correct or not, and right now it's not.
Seriously?
@blakeyrat said in In which I show how referential integrity is not a thing here:
ow about I ask an opposite question, why does this forum have moronic features, like being able to set the background image of the header of your user page nobody looks at, before it has a working persistent database layer? These are your priorities? They ain't mine.
It has a working persistent DB layer. Unless this is all a mass hallucination.
-
@boomzilla said in In which I show how referential integrity is not a thing here:
It has a working persistent DB layer.
Working by accident, not by design. Which means it could fail to work at any moment.
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
Working by accident, not by design. Which means it could fail to work at any moment.
 No, it's not breaking for that reason "at any moment."
No, it's not breaking for that reason "at any moment."
-
@boomzilla At the exact moment a MongoDB document exceeds the document limit. It's not "any" moment, you pedantic dickweed, but it's 100% unpredictable to me at least, so it might as well be.
I still want to hear what great benefits we got from this supposed trade-off you claim happened. Although I highly suspect you just pulled that out of your ass because:
- I don't believe you were involved with the NodeBB project before the MongoDB "support" was added
- I highly doubt that the incompetent developers of this shitty open source ball of crap actually had a discussion about priorities. They don't even use pull requests, and you think they actually do planning? They don't have any process at all.
-
@boomzilla Yeah. Thats the plan. Access to sorted sets would be transformed to queries on base tables, etc.
Actually bending my brain in the ways necessary to write that shit in JS doesn't seem to be coming easily, though. I suppose I could recruit somebody on whom the brain damage has already taken.
-
@Weng said in In which I show how referential integrity is not a thing here:
Actually bending my brain in the ways necessary to write that shit in JS doesn't seem to be coming easily, though.
Yeah, I'm starting to get used to it. Probably too late for me.
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
At the exact moment a MongoDB document exceeds the document limit. It's not "any" moment, you pedantic dickweed, but it's 100% unpredictable to me at least, so it might as well be.
Like how it's 100% predictable that if the DB is as big as your disk space stuff will stop working?
@blakeyrat said in In which I show how referential integrity is not a thing here:
I still want to hear what great benefits we got from this supposed trade-off you claim happened
It's work that would have been done for something that's extremely unlikely to happen, duh. I thought I already made that clear.
-
@boomzilla said in In which I show how referential integrity is not a thing here:
Like how it's 100% predictable that if the DB is as big as your disk space stuff will stop working?
I don't have access to find out the size of the DB, or the size of the disk. For me, it's 0% predictable.
@boomzilla said in In which I show how referential integrity is not a thing here:
It's work that would have been done for something that's extremely unlikely to happen, duh.
16 MB is minuscule. Why do you say it's "unlikely to happen"? If all the thread titles end up in a single MongoDB document (and I have no idea if they do, just an example), I wager that's already close to the limit.
@boomzilla said in In which I show how referential integrity is not a thing here:
I thought I already made that clear.
I don't know how, because the post I'm replying to now is the first time you've ever said it. I don't receive your telepathic vibes, remember?
And yes I noticed you ignored my "trade-off" question. I still want to know what we gained by the time saved implementing MongoDB wrong and broken. Sock it to me. What was the trade-off? Or admit you fucking made it up, because we all know you did.
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
the vastly smaller document size limitation
Pfffffft. MongoDB is web scale.
-
@blakeyrat said in In which I show how referential integrity is not a thing here:
16 MB is minuscule. Why do you say it's "unlikely to happen"? If all the thread titles end up in a single MongoDB document (and I have no idea if they do, just an example), I wager that's already close to the limit.
Why do you think all the thread titles will end up there? What if they put all the images in a single document? What if they put all of the access logs in a single document?
ZOMG, there are so many things you could add to a document. I'll bet they did them all.
@blakeyrat said in In which I show how referential integrity is not a thing here:
What was the trade-off?
Read the post.
-
@boomzilla I think the question is: what were the benefits of using Mongo instead of relational DB in the first place, and whether these benefits (if they exist at all) are enough to justify Mongo's flaws?
-
@boomzilla said in In which I show how referential integrity is not a thing here:
Why do you think all the thread titles will end up there? What if they put all the images in a single document? What if they put all of the access logs in a single document?
I wouldn't be surprised by any of those things.
@boomzilla said in In which I show how referential integrity is not a thing here:
Read the post.
I've read all your posts. You've never explained what this mythical trade-off was trading-off against. But, since you made it up, whatever.
@Adynathos said in In which I show how referential integrity is not a thing here:
I think the question is: what were the benefits of using Mongo instead of relational DB in the first place, and whether these benefits (if they exist at all) are enough to justify Mongo's flaws?
I don't even think Mongo's that bad a choice for an application like this. But if you write Mongo code without keeping it's weird arbitrary limit in mind, you're going to have troubles.