In other hostile takeover Tweets...
-
Good news! They're increasing the limit for actual tweets to 4000!
-
-
@loopback0 said in In other hostile takeover Tweets...:
Good news! They're increasing the limit for actual tweets to 4000!
That might make twitter more useful, which ... I guess I can't support.

But definitely a long overdue decision.
-
@topspin I kinda like Twitter's 300 or whatever character limit. Some stuff's easier to read broken into a thread of tweets than it would be in the wall of text that's permitted everywhere else.
-
@loopback0 LOL, a technical solution for inability to make paragraphs.
It will definitely make twitter different.
-
@boomzilla said in In other hostile takeover Tweets...:
@loopback0 LOL, a technical solution for inability to make paragraphs.
It will definitely make twitter
differentdie.
-
@topspin said in In other hostile takeover Tweets...:
Good news! They're increasing the limit for actual tweets to 4000!
developers, knowing that the limit is basically hardcoded in a million different places:

-
@Zerosquare said in In other hostile takeover Tweets...:
@topspin said in In other hostile takeover Tweets...:
Good news! They're increasing the limit for actual tweets to 4000!
developers, knowing that the limit is basically hardcoded in a million different places:
Who wants to bet that they'll be internally breaking up longer posts into dozens of tweets, then combining them again on the front-end?
-
I wouldn't be surprised if someone told me that's how they handled the 140-to-280 characters transition.
-
@Zerosquare Well ... they could always store a magic GUID in the original tweet to indicate that it's a long tweet with the data stored elsewhere.
Filed under: Discourse best practices.
-
@cvi said in In other hostile takeover Tweets...:
Discourse best practices
Filed under: self-contradictory statements
-
@Zerosquare OT: That reminds me, I found a nearby makerspace today. To join requires installing 3 apps and joining their forum. Their forum runs on — you guessed it — Dicksores. Ick.
-
Sounds like the kind of "makerspace" where people make NodeJS abominations instead of tangible, real things

-
@Zerosquare Actually, it's very well equipped for making tangible, real things — welding shop, machine shop with manual and CNC lathe, mill, etc., very well equipped woodworking shop, laser cutters, CNC router, a bunch of 3D printers of various types, electronics lab, and industrial sewing machine. It's just getting access to it that requires bowing down to the eldritch NodeJS abominations. And a lot of gold.
-
@cvi said in In other hostile takeover Tweets...:
@Zerosquare Well ... they could always store a magic GUID in the original tweet to indicate that it's a long tweet with the data stored elsewhere.
Combine it with blockchain and we get NFTs!
-
@Bulb said in In other hostile takeover Tweets...:
… and I would also say that moderation bias is really a bigger deal. Poor engineering practice could easily sink the company, but most users don't have particularly sensitive data at twitter, so even a big leak wouldn't hurt them too much.
I'm of two minds on that. I agree with what you said, on the user-experience side moderation bias (and more generally, cultural things in how the company is run, i.e. "people problems" matter more).
But on the other hand, technical stuff can make changing things almost impossible -- sure, Musk et al. "just" need to write code, but given the crowd here I don't think I need to add more than that to make that point. Twitter might be so terminally badly built that the only way to significantly change things is to throw away all the code, and we can all remember (well... some of us can...
 ) how that went for Netscape. From what I read, some other companies (e.g. Facebook) managed better the change of technology needed to go from startup to megacorp (not that Facebook doesn't have its share of
) how that went for Netscape. From what I read, some other companies (e.g. Facebook) managed better the change of technology needed to go from startup to megacorp (not that Facebook doesn't have its share of  , both from the cultural and technical sides, but I get the feeling that the technical side is less insane than at Twitter).
, both from the cultural and technical sides, but I get the feeling that the technical side is less insane than at Twitter).But on the third hand (
 ), technical problems might be crippling but the whole thing can be rewritten from scratch (especially since I don't think the actual idea of Twitter is that hard to code, it's not like there are bazillions of features), even if it's costly and hard. People problems can only be resolved by throwing out the people, which Musk is doing, but ultimately you're also throwing out the knowledge of the technology and that effectively means that you're only left with the brand name and none of everything else that makes up the company (neither the people/knowledge nor the technology since no one is left who knows how to use it). So it might be even worse than technological problems.
), technical problems might be crippling but the whole thing can be rewritten from scratch (especially since I don't think the actual idea of Twitter is that hard to code, it's not like there are bazillions of features), even if it's costly and hard. People problems can only be resolved by throwing out the people, which Musk is doing, but ultimately you're also throwing out the knowledge of the technology and that effectively means that you're only left with the brand name and none of everything else that makes up the company (neither the people/knowledge nor the technology since no one is left who knows how to use it). So it might be even worse than technological problems.IOW,
 and
and  .
.
-
@remi said in In other hostile takeover Tweets...:
But on the third hand (
),The gripping hand!
The Mote in God's Eye (by Niven and Pournelle) was a fun book.
-
@remi My understanding of that thread is that it's not so much the code is bad as the engineering practices are. The code itself mostly works, even if not very efficiently. It's things like pushing bugs straight into production because there are no tests and no testing environment to run them on, or fixing things up directly in the production database without any audit trail or properly working restore, so if some data gets lost, it is truly lost.
And those things can be gradually introduced into a project. Build deployment pipelines, restrict direct access to production, create a staging environment, start adding integration tests … and then one can proceed to cleaning up the code from bloat, module by module.
(My current project is pretty much that, though on much smaller scale—the infrastructure was built haphazardly in Azure, scattered across two subscriptions, many parts don't have proper test instances, functions were written as C# scripts directly in the portal and such, and I am now creating deployment pipelines and trying to introduce infrastructure-as-code, and we are moving things around to consolidate them)
-
@Bulb said in In other hostile takeover Tweets...:
And those things can be gradually introduced into a project. Build deployment pipelines, restrict direct access to production, create a staging environment, start adding integration tests … and then one can proceed to cleaning up the code from bloat, module by module.
Fair enough. Though after some point, bad engineering practices are likely to end up producing bad code.
Or, more to the point here (i.e. relative to how hard it'll be to fix it), bad code structure (stuff that should be separated and that isn't, or conversely stuff that far too fragmented, making it impossible to know what does what). Bad code itself isn't a big problem, it can fixed bit by bit, but the wrong architecture is harder to change without breaking everything.
In a sense, that would be even worse, given how Musk he firing everyone, because that kind of bad structure is only understandable by people who've been immersed in it for a long time. Bring in a new team, without that knowledge (and likely, given Musk's personality, with a lot of cocky cowboy rock star coder mentality), and they'll struggle to even know which bits can be progressively fixed.
Also, some of the bad practices are likely to have encoded even more knowledge in, erm,
 surprising places. "Everyone can access prod," "everyone can put whatever they want on their computers" and "no backups" is almost guaranteed to end up with a critical bit of code where the actual authoritative source is in
surprising places. "Everyone can access prod," "everyone can put whatever they want on their computers" and "no backups" is almost guaranteed to end up with a critical bit of code where the actual authoritative source is in C:\dev\foo_project_1_new_fixed_joe_smith_copied_from_archive_newrather than in a sane place. Loose that laptop (because you've fired someone -- and no, that someone isn't Joe Smith, that would be far too easy!), and suddenly no one knows why the code in prod doesn't match anything anywhere else.
-
@dkf said in In other hostile takeover Tweets...:
@remi said in In other hostile takeover Tweets...:
But on the third hand (
),The gripping hand!
The Mote in God's Eye (by Niven and Pournelle) was a fun book.
You make that joke too often. I will read the book eventually though.
-
@remi said in In other hostile takeover Tweets...:
no one knows why the code in prod doesn't match anything anywhere else.
BTDT. In hardware. We couldn't implement bug fixes or proper derivative products, because we couldn't recreate the chips we were making.
-
@topspin said in In other hostile takeover Tweets...:
@Zerosquare said in In other hostile takeover Tweets...:
@topspin said in In other hostile takeover Tweets...:
Good news! They're increasing the limit for actual tweets to 4000!
developers, knowing that the limit is basically hardcoded in a million different places:
Who wants to bet that they'll be internally breaking up longer posts into dozens of tweets, then combining them again on the front-end?
To me, 4000 is a very specific number. I don't know what kind of DB they use, but that's the limit on a normal Oracle text field, at least. Any bigger and you have to go to a CLOB.
-
@HardwareGeek When I joined my current company, they were using a piece of software that everybody agreed was reaching retirement age. There was one person who remembered having worked on it before but was no longer in a development role for quite some years already. There also was one developer who, at some point, had had access to the source code and copied some bits in another software, but wasn't really sure which version that was. But everyone agreed that the software was not going to be updated again, ever, and we had working binaries so all was fine, right?
The software kept being used, marginally and by a couple of people, while we regularly talked about replacing it, but since it was so low-use it never was a priority. And then one day we moved to a new version of the OS and the software didn't work anymore. There was some talk about checking the old source code that this one developer had, or maybe actually start the replacement. But then that developer (or another, can't remember, and it may even have been myself!) noticed that actually we could just copy one missing library from the old OS and the software kept running.
So we did that, because essentially IT upgraded all systems without telling us so we didn't have time to plan for it
 and needed an immediate solution. Of course only as a very temporary and short term stop-gap measure...
and needed an immediate solution. Of course only as a very temporary and short term stop-gap measure...  ... who am I kidding?
... who am I kidding?This went on for yet another couple of OS releases, and 15 years or more.
Last time I heard about it, there was still one user who still was able to run the software on one specific computer.
And we're still talking about writing a replacement, one day.
(though to be fair we know at this point it's not gonna happen, it's more a running gag than a serious idea, and across the years all the
usefulused features of that software have been moved elsewhere, so the problem is actually already solved)
-
@remi said in In other hostile takeover Tweets...:
why the code in prod doesn't match anything anywhere else
On that note, we just had an issue where something we'd just deployed didn't work. Brought up a testing environment...works perfectly there. In production, it's just not even beginning to write to the tables that were added....eventually we figured out that the deploy person hadn't actually pushed the right deploy button. They'd deployed all the other changes in that release...just not that one. Thankfully it was self-contained enough that it only broke that one feature. But it took like 15 man-hours (3 hours among 5 people) to figure it out, because it took a long time for someone who actually had production access to be pulled in so we could check what was actually running in production.
-
@Benjamin-Hall said in In other hostile takeover Tweets...:
Thankfully it was self-contained enough that it only broke that one feature. But it took like 15 man-hours (3 hours among 5 people) to figure it out, because it took a long time for someone who actually had production access to be pulled in so we could check what was actually running in production.
Stuff like this is why I have always argued for all devs to have access to production.
-
@Dragoon said in In other hostile takeover Tweets...:
@Benjamin-Hall said in In other hostile takeover Tweets...:
Thankfully it was self-contained enough that it only broke that one feature. But it took like 15 man-hours (3 hours among 5 people) to figure it out, because it took a long time for someone who actually had production access to be pulled in so we could check what was actually running in production.
Stuff like this is why I have always argued for all devs to have access to production.
I mean...in practice we do have enough access to figure it out in roundabout ways (grepping the logs for things we know we added in that particular version). But it's a sign of how far we've come as a company that deploys are stable enough that it wasn't our first assumption.
Some of the old-timers were talking about how things used to be (before I joined). Everything from:
- There is no local environment, all development takes place live in production by ssh'ing in and directly editing files in production.
- Development takes place locally, but QA is just someone else with the entire stack running on their machine. Deployment is "ssh into prod and do
git pull. - Weekly "deploy death marches" where you've got a fixed, top-down quota of "things to get done by week end" and you stay late on Friday until "QA" (ie the guy with it all running locally) approves it and then you deploy at 0:00 Saturday morning.
By the time I joined, we actually had a persistent QA environment not running on someone's local machine and some semblance of a deploy path and an SDLC. QA and local stacks still weren't totally the same as production, but closer.
Now we have development environments that are substantially closer to production and a mostly automated deploy process (requires a couple manual button presses), as well as a real QA team with resources enough to do things.
So...progress.
-
@Benjamin-Hall said in In other hostile takeover Tweets...:
There is no local environment, all development takes place live in production by ssh'ing in and directly editing files in production.
I used to do that on my personal website, but for a safety-critical commercial product?

-
@HardwareGeek said in In other hostile takeover Tweets...:
@Benjamin-Hall said in In other hostile takeover Tweets...:
There is no local environment, all development takes place live in production by ssh'ing in and directly editing files in production.
I used to do that on my personal website, but for a safety-critical commercial product?
Yeah...it was a dark time.
-
@Benjamin-Hall In college in the early 00's I was in a student-run group that would host official department websites. Most of the business-critical ones were hosted in an actual server room managed by actual professional sysadmins, but we sometimes got to host certain lesser departments on our own server kept in the development office.
There was always this one regular old Dell headless desktop in the corner, though that was always running. And someone told me before he graduated that it hosted... something. And he forgot what it was. But he didn't seem too worried about it. Some time after we were moving offices, and we got to that desktop. By then I was the manager, and I asked the other manager what we should do.
"Best thing to do is unplug the ethernet and see who calls."
And that's what we did. Some 2 hours after we unplugged it, the webmaster came in and said we had to investigate why the campus gym's website mysteriously went down. We had our answer.
-
@Dragoon said in In other hostile takeover Tweets...:
@Benjamin-Hall said in In other hostile takeover Tweets...:
Thankfully it was self-contained enough that it only broke that one feature. But it took like 15 man-hours (3 hours among 5 people) to figure it out, because it took a long time for someone who actually had production access to be pulled in so we could check what was actually running in production.
Stuff like this is why I have always argued for all devs to have access to production.
Twitter manglement approves of this idea.
-
@HardwareGeek said in In other hostile takeover Tweets...:
@Benjamin-Hall said in In other hostile takeover Tweets...:
There is no local environment, all development takes place live in production by ssh'ing in and directly editing files in production.
I used to do that on my personal website, but for a safety-critical commercial product?
Why not? It works even for some companies as big as Twitter

-
@boomzilla said in In other hostile takeover Tweets...:
To me, 4000 is a very specific number. I don't know what kind of DB they use, but that's the limit on a normal Oracle text field, at least. Any bigger and you have to go to a CLOB.
I believe it's the same in SQL Server, apparently dictated by maximum row size of 8 KB. It upgrades to BLOB transparently, though. And Postgres default block size is also the same.
-
Lots of censorship related posts jeffed to the appropriate thread:
https://what.thedailywtf.com/topic/28454/why-does-twitter-censor
-
@boomzilla Ah, that's why

 's idea of my last read post in that thread was so far off. I suspected something like that.
's idea of my last read post in that thread was so far off. I suspected something like that.
-
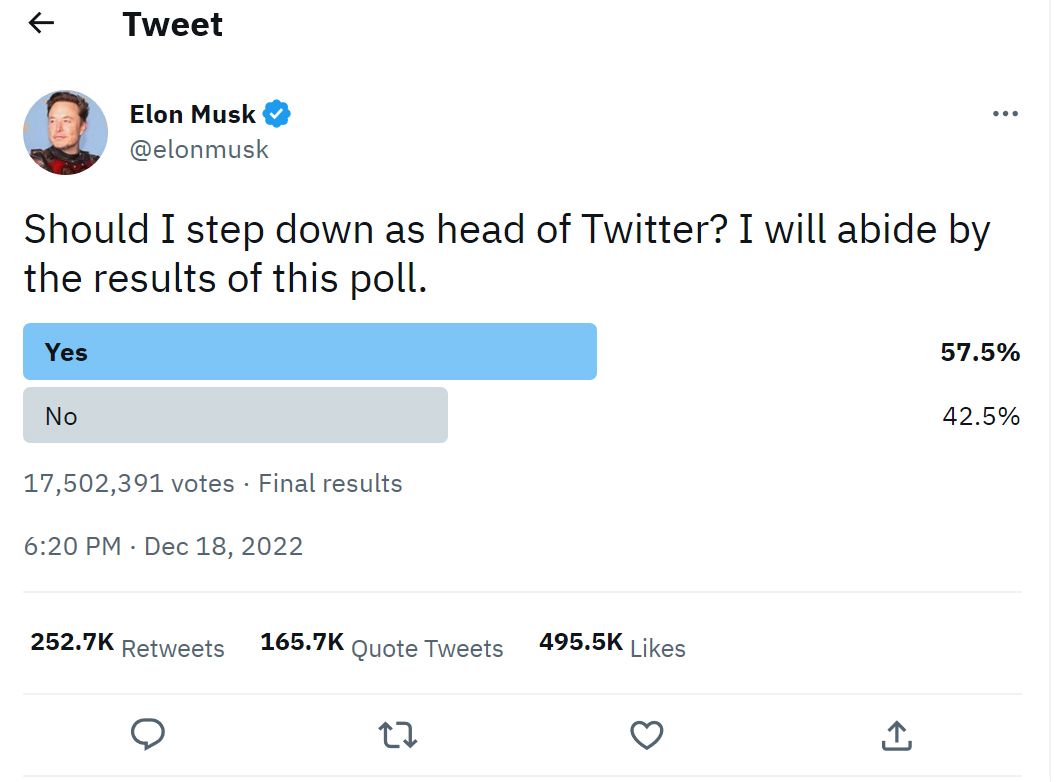
Meanwhile, Musk wrote yesterday that Twitter will rely on polls for major policy changes in the future.

-
@cvi said in In other hostile takeover Tweets...:
GUID
Snowflake. They're nearly 1/(2^32) as good as a GUID!
-
@The_Quiet_One this approach is highly effective - it can be used to demonstrate that a grasshopper hears with its legs.
-
@Gern_Blaanston said in In other hostile takeover Tweets...:
Meanwhile, Musk wrote yesterday that Twitter will rely on polls for major policy changes in the future.
How long until 3 million user accounts are created in an instant to adjust the poll numbers "properly"?
-
@PotatoEngineer said in In other hostile takeover Tweets...:
@Gern_Blaanston said in In other hostile takeover Tweets...:
Meanwhile, Musk wrote yesterday that Twitter will rely on polls for major policy changes in the future.
How long until 3 million user accounts are created in an instant to adjust the poll numbers "properly"?
Eh, that'll happen organically when the RIA folks wake up.
-
@Gern_Blaanston He apparently didn't watch this
or maybe he never planned to honour it anyway. He is a master troll after all.
-
@Bulb on the contrary, he already has a replacement for in a few months, so either option will look like he’s honoring the poll.
-
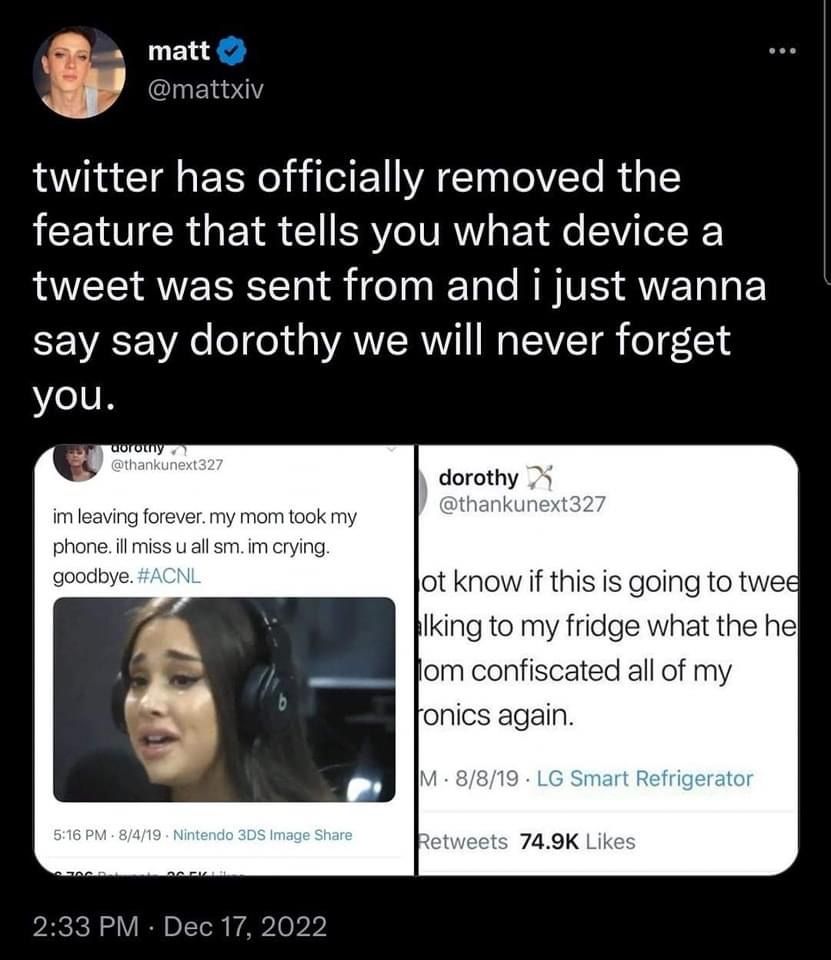
Filed under: Sent from my light bulb.
-

-
Yes, you should definitely use "the cloud" and not "data centers".
 It Took Just Four Days From Elon Gleefully Admitting He’d Unplugged A Server Rack For Twitter To Have A Major Outage
It Took Just Four Days From Elon Gleefully Admitting He’d Unplugged A Server Rack For Twitter To Have A Major Outage

I know, I know. Some of the more angry commenters around here keep insisting that I should stop talking about Elon Musk and Twitter, and I want to do exactly that. I planned to do exactly that and …
there have been reports that Musk decided (with little to no notice, and almost no planning) to shut down its Sacramento data center and massively downsize their Atlanta data center. Twitter only has one other data center in the US, in Portland, Oregon.
Twitter’s use of data centers rather than the cloud is something that’s been discussed over the years, and two years ago the company did sign a deal to start using Amazon Web Services, though I don’t think the company relies too heavily on it yet
Because Amazon Web Services magically uses something other than servers in data centers
-
@Gern_Blaanston said in In other hostile takeover Tweets...:
Twitter’s use of data centers rather than the cloud is something that’s been discussed over the years, and two years ago the company did sign a deal to start using Amazon Web Services, though I don’t think the company relies too heavily on it yet
Because Amazon Web Services magically uses something other than servers in data centers
The terminology might be silly, but established and the message itself is not
at all.Twitter's practice to build and run their own data centers instead of renting them from other subjects...
-
@Kamil-Podlesak said in In other hostile takeover Tweets...:
@Gern_Blaanston said in In other hostile takeover Tweets...:
Twitter’s use of data centers rather than the cloud is something that’s been discussed over the years, and two years ago the company did sign a deal to start using Amazon Web Services, though I don’t think the company relies too heavily on it yet
Because Amazon Web Services magically uses something other than servers in data centers
The terminology might be silly, but established and the message itself is not
at all.Twitter's practice to build and run their own data centers instead of renting them from other subjects...

-
@Gern_Blaanston TBF... He's fired so many people and Twitter is such a mess the only to figure out what anything does is to turn it off and see what breaks.
Something taking four days to break instead of immediately should be a bigger cause of concern.
-
@DogsB said in In other hostile takeover Tweets...:
Something taking four days to break instead of immediately should be a bigger cause of concern.
It's not like stuff never broke at Twitter before. Also consider that he's continuing to make changes so the breakage probably has less to do with paring down their server footprint and more with whatever they did in the following four days.
Let's not forget that they have a single environment. Well, had, but it's probably not been long enough to get something else up and running for testing.
-
@boomzilla said in In other hostile takeover Tweets...:
It's not like stuff never broke at Twitter before.
See! I told you it was all about continuity!
-
@DogsB said in In other hostile takeover Tweets...:
Something taking four days to break instead of immediately should be a bigger cause of concern.
Depends what sort of worldwide caches they've paid for (probably operated by a different company; there are a few big specialists in that area) and what the expiration policy on those is.

