Too many pumps
-
I've lost myself in some strange weeds...
So I'm making an uploader that in theory can track progress of the upload (you know, so it's not just sitting there indeterminate until it's done).
To do this, I'm using a pass-through stream class I made that simply counts the bytes written/read through a base stream. This works fine when downloading.
Now I'm trying to make the uploader version, and it seems the HttpClient just kinda... dies? I think it's assuming that once
Read()doesn't return any bytes it's never going to do so ever and just continues its merry way, and closes the source stream. But only if I actually return 0 bytes read from the stream, if I hang the stream until there's data to be read, deadlock occurs.This is a problem because there is shit it needs to read, but apparently just doesn't know it yet, and there's no way to tell it to hang back and try again until Stream.canRead is false.
I can't find a way to get it to read from my stream but only as it needs to, instead of the whole thing all at once.
Teh codez
async System.Threading.Tasks.Task DoUploadAsync() { HttpRequestMessage req = new HttpRequestMessage(new HttpMethod(target.Method), target.Url); EchoStream outputStream = new EchoStream(1); PassThroughStream contentStream = new PassThroughStream(data); req.Content = new StreamContent(outputStream, 16384); //req.Content.Headers.ContentEncoding.Add("gzip"); long totalSize = data.Length; bool writtenFully = false; Task uploader = Task.Run(() => { { long totalRead = 0L; long totalReads = 0L; byte[] buffer = new byte[16384]; Stream processingStream = outputStream; //processingStream = new GZipStream(processingStream, CompressionMode.Compress, true); do { var read = contentStream.Read(buffer, 0, buffer.Length/*, stopTransfer.Token*/); if (read == 0) { writtenFully = true; } else { processingStream.Write(buffer, 0, read); totalRead += read; totalReads += 1; if (totalReads % 20 == 0) { Console.WriteLine(string.Format("total bytes read for uploading so far: {0:n0}", totalRead)); } } } while (!writtenFully && !stopTransfer.IsCancellationRequested); outputStream.Flush(); outputStream.Close(); } }); Task<HttpResponseMessage> reqWaiter = client.SendAsync(req, stopTransfer.Token); await Task.WhenAll(uploader, reqWaiter); ... Blah blah, get the result from reqWaiter etc. }EchoStream is a class I ripped from This SO answer, and only modified it so it doesn't return
-1when the stream is closed and you're trying to read from it.My question is: Is it even possible to "slow down" the reading of the stream from HttpClient?
Or rather, get it to actually start reading as if it was a stream and not copying the whole fucking thing to memory before actually processing?
I have the feeling I must be doing something wrong...
-
This might be related to needing to know the size of a HTTP 1.0 request in advance, and the client not being willing to a priori assume HTTP 1.1 is supported.
If this is a HTTP file upload (mime multipart message) then httpclient will also need to inspect the entire input file in order to determine a suitable part separator.
-
@Tsaukpaetra Does this link help? https://thomaslevesque.com/2013/11/30/uploading-data-with-httpclient-using-a-push-model/. For your scenario maybe derive from
HttpContentyourself and overrideSerializeToStreamAsync?
-
@PleegWat said in Too many pumps:
If this is a HTTP file upload (mime multipart message)
I hope not, I certainly haven't told it to chunk in any case.
But this page seems to hint that it should be chunked...

@robo2 said in Too many pumps:
@Tsaukpaetra Does this link help? https://thomaslevesque.com/2013/11/30/uploading-data-with-httpclient-using-a-push-model/. For your scenario maybe derive from
HttpContentyourself and overrideSerializeToStreamAsync?Did that
class MyStreamContent : HttpContent { Stream readStream; private byte[] buffer; public MyStreamContent(Stream inStream, int bufferSize = 4096) { readStream = inStream; buffer = new byte[bufferSize]; } protected override async Task SerializeToStreamAsync(Stream stream, TransportContext context) { bool done = false; while (readStream.CanRead && !done) { try { int read = await readStream.ReadAsync(buffer, 0, buffer.Length); if(read > 0) { await stream.WriteAsync(buffer, 0, read); } await stream.FlushAsync(); await readStream.FlushAsync(); } catch (Exception) { done = true; } } } protected override bool TryComputeLength(out long length) { length = -1; return false; } }It... strangely didn't help at all.
 Like, it still read the whole thing until I signaled completion in
Like, it still read the whole thing until I signaled completion in SerializeToStreamAsyncand didn't actually start uploading until then.
-
@Tsaukpaetra said in Too many pumps:
But this page seems to hint that it should be chunked...
 That was it. Smashing a
That was it. Smashing a req.Headers.TransferEncodingChunked = true;into the request made it work as planned (though naturally the read-out buffer was somewhat ahead of the actual upload, it actually more-or-less followed the actual progress).Also, loving the auto-gen docs...
-
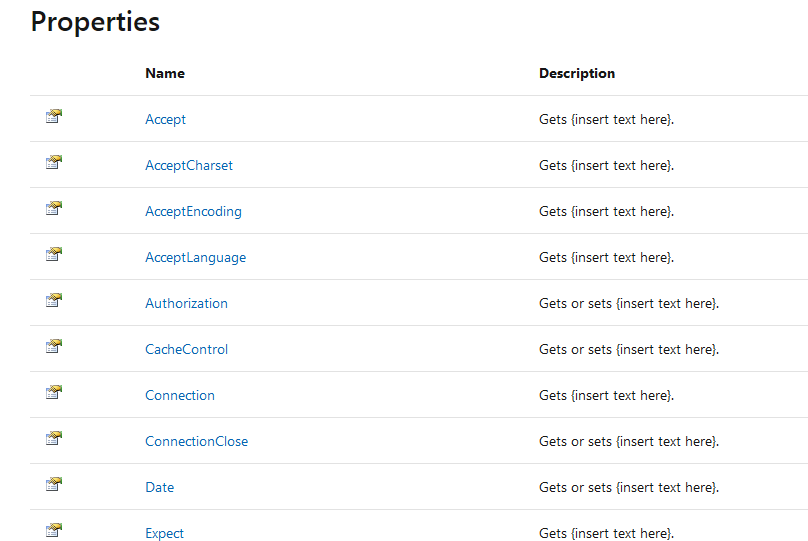
@Tsaukpaetra That's what you get for looking at the old docs per the header at the top. Current version of that page has correct descriptions:
HttpRequestHeaders Class (System.Net.Http.Headers)

Represents the collection of Request Headers as defined in RFC 2616.
-
@Tsaukpaetra said in Too many pumps:
Also, loving the auto-gen docs...
It's hosted by Microsoft. You need to take a screenshot so people in 6 months can still see it.
-
@Zecc said in Too many pumps:
It's hosted by Microsoft. You need to take a screenshot so people in 6
monthsdays can still see it.FTFY
-
@Tsaukpaetra said in Too many pumps:
@Tsaukpaetra said in Too many pumps:
But this page seems to hint that it should be chunked...
That was it. Smashing a req.Headers.TransferEncodingChunked = true;into the request made it work as planned (though naturally the read-out buffer was somewhat ahead of the actual upload, it actually more-or-less followed the actual progress).Fuck, now that I'm testing it with more than a few KB of data, I'm discovering it's not uploading the files correctly?

Somehow it's the same number of bytes as expected, but the content... changes...
I tried it with a copy of War and Peace so the visual effects would be more apparent, and I got this bar:

Shit just disappearing or moving place on a whim... But only for a while, the rest of the file is fine!
And if I don't do Chunked (thereby skipping the pass-through pipe that counts bytes) it works great.
Sigh.
-
@Tsaukpaetra said in Too many pumps:
Sigh.
Ah, I did a dumb and foolishly re-used the transfer buffer array instead of allocating a new one for each read/write cycle? Maybe?
Moving the
byte[] buffer = new byte[16384];from outside the loop to inside it fixed it (despite logic and the code saying it shouldn't matter) so whatever...
-
@Tsaukpaetra Your GC is happy that it has a lot of work in these trying times

-
@Tsaukpaetra said in Too many pumps:
Ah, I did a dumb and foolishly re-used the transfer buffer array instead of allocating a new one for each read/write cycle? Maybe?
Moving the
byte[] buffer = new byte[16384];from outside the loop to inside it fixed it (despite logic and the code saying it shouldn't matter) so whatever...That that works is pretty worrying. Somewhere inside the chunked implementation is an assumption that isn't being surfaced in the API description.
@Applied-Mediocrity said in Too many pumps:
Your GC is happy
It would be happy if it wasn't required to work this way. Instead, there's probably something pretty awful in there and the GC might be actually needing to work fairly hard. Especially if what's actually happening is the buffering getting handed across threads or other asynch processing; that stuff can really mess with memory usage patterns.
-
@Applied-Mediocrity said in Too many pumps:
@Tsaukpaetra Your GC is happy that it has a lot of work in these trying times
Watching the memory Profiler thing seems to indicate it doesn't?
I need to try uploading something bigger than 80 mb I think...
-
@Tsaukpaetra said in Too many pumps:
I need to try uploading something bigger than 80 mb I think...
The GC probably hasn't bothered to wake up yet for that small an amount of memory to reclaim.
-
@dkf said in Too many pumps:
@Tsaukpaetra said in Too many pumps:
I need to try uploading something bigger than 80 mb I think...
The GC probably hasn't bothered to wake up yet for that small an amount of memory to reclaim.
It did to reclaim a few kb when the window appeared, but then never again after...!

-
@Tsaukpaetra said in Too many pumps:
@dkf said in Too many pumps:
@Tsaukpaetra said in Too many pumps:
I need to try uploading something bigger than 80 mb I think...
The GC probably hasn't bothered to wake up yet for that small an amount of memory to reclaim.
It did to reclaim a few kb when the window appeared, but then never again after...!
It's the observer effect.
-
@dkf said in Too many pumps:
@Tsaukpaetra said in Too many pumps:
Ah, I did a dumb and foolishly re-used the transfer buffer array instead of allocating a new one for each read/write cycle? Maybe?
Moving the
byte[] buffer = new byte[16384];from outside the loop to inside it fixed it (despite logic and the code saying it shouldn't matter) so whatever...That that works is pretty worrying. Somewhere inside the chunked implementation is an assumption that isn't being surfaced in the API description.
You mean that the API lazily holds on to the offered buffer until it can be sent, instead of making its own copy?
How does C# pass array arguments to functions again? As a reference?@Applied-Mediocrity said in Too many pumps:
Your GC is happy
It would be happy if it wasn't required to work this way. Instead, there's probably something pretty awful in there and the GC might be actually needing to work fairly hard. Especially if what's actually happening is the buffering getting handed across threads or other asynch processing; that stuff can really mess with memory usage patterns.
I suddenly feel happier that I'm working in C/C++.
-
@acrow Arrays are passed by reference in C# yes. So something internal is making a 'copy' of the array for later processing in another thread or something I guess. Which you should definitely not do.
The language is almost irrelevant here, the broken library code would be broken in just the same way in C++ and you'd have to apply the same hack (creating a new array for each chunk) if you were using this library code there too.
-
And I almost suggested allocating 16K once, outside, and then calling
RtlZeroMemoryinside the loop
-
@bobjanova said in Too many pumps:
The language is almost irrelevant here, the broken library code would be broken in just the same way in C++ and you'd have to apply the same hack (creating a new array for each chunk) if you were using this library code there too.
That's not a hack. Copying the data to an internal buffer before returning from the function call is the only safe way to handle that. Unless you're passing the data in an object with an explicitly stated copy-on-write mechanism. Like, say, Qt's QByteArray.
Or, otherwise, the array should be both created and destroyed by the same API. Having memory reserved outside a library, and consumed inside it, is bad design, and may lead to memory corruption (unless this API is part of the standard library for this language, but it's still bad design).
-
@acrow I think what I'm saying is that a stream handling library should have a copy-on-write contract for writing to a stream (at least theoretically), because it's bad for the calling code to have to deal with that.
I don't think any sane user would expect
byte[] buf = (something);
stream.write(buf, 0, buf.length);resetToZero(buf, 0, buf.length);
... to write those zeroes into the stream. Even if stream.write is internally asynchronous and therefore has to make a copy to avoid it.
-
@bobjanova We agree then.
Although, (
 time ), in practise, copy-on-write is often passed on in favor of zero-copy mechanisms, if going for extremes of performance or minimalist embedded systems. (Read: C libraries for networking.)
time ), in practise, copy-on-write is often passed on in favor of zero-copy mechanisms, if going for extremes of performance or minimalist embedded systems. (Read: C libraries for networking.)
-
@bobjanova said in Too many pumps:
I think what I'm saying is that a stream handling library should have a copy-on-write contract for writing to a stream (at least theoretically), because it's bad for the calling code to have to deal with that.
The problem with that is that it forces another copy step on the data, and one of the main metrics for working out where performance problems are in the I/O path are the number of copies required. This stuff tends to matter a lot when pushing a lot of data around, even on modern computers.
Better would be a callback you could pass in so that you get notified when the buffer you handed in is finished with. That would let you recycle the buffer in a small pool, which is the most efficient approach (since you'd be able to be preparing one buffer while others are being sent).
-
@Tsaukpaetra said in Too many pumps:
I've lost myself in some strange weeds...
So I'm making an uploader that in theory can track progress of the upload (you know, so it's not just sitting there indeterminate until it's done).
To do this, I'm using a pass-through stream class I made that simply counts the bytes written/read through a base stream. This works fine when downloading.
Now I'm trying to make the uploader version, and it seems the HttpClient just kinda... dies? I think it's assuming that once
Read()doesn't return any bytes it's never going to do so ever and just continues its merry way, and closes the source stream. But only if I actually return 0 bytes read from the stream, if I hang the stream until there's data to be read, deadlock occurs.This is a problem because there is shit it needs to read, but apparently just doesn't know it yet, and there's no way to tell it to hang back and try again until Stream.canRead is false.
I can't find a way to get it to read from my stream but only as it needs to, instead of the whole thing all at once.
Teh codez
async System.Threading.Tasks.Task DoUploadAsync() { HttpRequestMessage req = new HttpRequestMessage(new HttpMethod(target.Method), target.Url); EchoStream outputStream = new EchoStream(1); PassThroughStream contentStream = new PassThroughStream(data); req.Content = new StreamContent(outputStream, 16384); //req.Content.Headers.ContentEncoding.Add("gzip"); long totalSize = data.Length; bool writtenFully = false; Task uploader = Task.Run(() => { { long totalRead = 0L; long totalReads = 0L; byte[] buffer = new byte[16384]; Stream processingStream = outputStream; //processingStream = new GZipStream(processingStream, CompressionMode.Compress, true); do { var read = contentStream.Read(buffer, 0, buffer.Length/*, stopTransfer.Token*/); if (read == 0) { writtenFully = true; } else { processingStream.Write(buffer, 0, read); totalRead += read; totalReads += 1; if (totalReads % 20 == 0) { Console.WriteLine(string.Format("total bytes read for uploading so far: {0:n0}", totalRead)); } } } while (!writtenFully && !stopTransfer.IsCancellationRequested); outputStream.Flush(); outputStream.Close(); } }); Task<HttpResponseMessage> reqWaiter = client.SendAsync(req, stopTransfer.Token); await Task.WhenAll(uploader, reqWaiter); ... Blah blah, get the result from reqWaiter etc. }EchoStream is a class I ripped from This SO answer, and only modified it so it doesn't return
-1when the stream is closed and you're trying to read from it.My question is: Is it even possible to "slow down" the reading of the stream from HttpClient?
Or rather, get it to actually start reading as if it was a stream and not copying the whole fucking thing to memory before actually processing?
I have the feeling I must be doing something wrong...
Seems like you need the opposite direction stream? Oh, .Net, ew.
Although many frameworks do drain the input stream surprisingly early.
-
@Gribnit said in Too many pumps:
Although many frameworks do drain the input stream surprisingly early
Yeah. Maybe. I forget what I eventually resulted to.