Circle of Size
-
 Death By a Thousand Microservices
Death By a Thousand Microservices
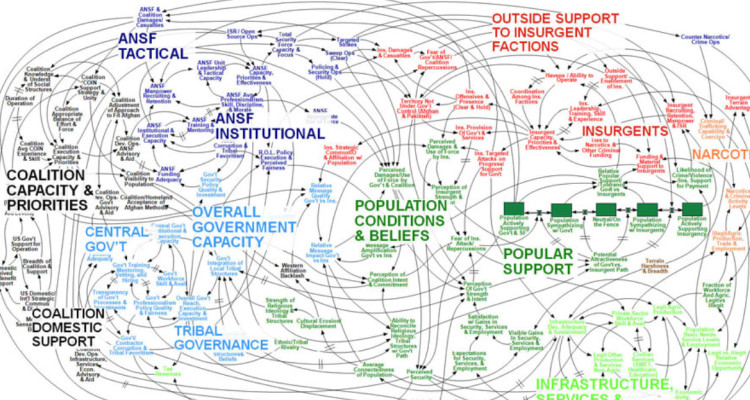
The software industry is learning once again that complexity kills
Good stuff, starting with this video illustrating the
 :
:Regarding recent discussions about unbelievable employment overhead at some companies:
WhatsApp went supernova with their Erlang monolith and 50 engineers. How?
WhatsApp consciously keeps the engineering staff small to only about 50 engineers.
Individual engineering teams are also small, consisting of 1 - 3 engineers and teams are each given a great deal of autonomy.
In terms of servers, WhatsApp prefers to use a smaller number of servers and vertically scale each server to the highest extent possible.
Instagram was acquired for billions - with a crew of 12.
Lots of other good stuff in there.
-
@boomzilla
One of the linked articles from early in TFA is also really good.
-
And do you imagine Threads as an effort involving a whole Meta campus? Nope.
Of course not. Their whole campus is busy trying to finally ship legs.
They followed the Instagram model, and this is the entire Threads team:
But “threads” is a vaporware product. You could’ve built that with half of the WTDWTFers too bored to build real stuff.
-
There is a dogma attached to not starting out with microservices on day one - no matter the problem. “Everyone is doing microservices, yet we have a single Django monolith maintained by just a few engineers, and a MySQL instance - what are we doing wrong?”. The answer is almost always “nothing”.
The whole thing is pretty interesting.
I’m not in this domain at all and have absolutely no clue about this stuff, i.e., on the very left side of the Dunning Kruger scale: I know that I don’t know these things.
To me, pretty much all of that stuff sounds stupid. That probably comes from my ignorance, since at least some of it surely makes at least some amount of sense. But I can’t really tell apart what is or isn’t idiotic. First time I heard that an AWS “lambda” is a micro-service for a single function I thought that’s insane. I have so many functions in my code, and it’s a tiny code base compared to what people out there in the real world are dealing with. Surely, that makes no sense at all. But since I don’t see the point of micro-services to begin with, it’s all the same to me.
-
@topspin The article mentions an image resizing service, which seems to me like the perfect use for a (micro?) service or Lambda-like function. Instead of tying up your main app to do that task, send it off to the cloud and get back to showing to-do lists or whatever. The service gets spun up, takes care of the image resizing, puts the result back into your file bucket and the next time you care, you have a resized image available. But I think those types of problems are a lot fewer than the actual projects that explode everything into microservices
-
@hungrier yeah. In my world, the choice would be to fire off a separate process (and deal with the fragility of IPC / error handling) or just put it on a background task. Assuming it’s not a separate executable in the first place, then it’s just “run image magick”.
ETA: also, obligatory mention of letter CDN, which an idiot like me could’ve avoided with 20 lines of non-retarded stuff.
-
@topspin said in Circle of Size:
First time I heard that an AWS “lambda” is a micro-service for a single function I thought that’s insane.
functionnot in the meaning of a function in your favorite programming language, but rather a "job". It gets called with a series of parameters, and returns a result (so similar to a function); it is stateless (independent of previous calls). But the main point is that you do not need a virtual machine for it, not even a container, it is "serverless", and hence has virtually zero overhead for starting when you need it (and it gets cleaned off afterwards - no resource costs when you do not need it). Of course, you get tied to your cloud provider - enjoy this extra lock-in.
-
@BernieTheBernie that makes some amount of sense.
-
@BernieTheBernie said in Circle of Size:
It gets called with a series of parameters, and returns a result (so similar to a function); it is stateless (independent of previous calls).
That is literally the definition of a function in all languages I'm familiar with that differentiate between
functionandprocedure. How it gets from input to output ought to be completely transparent to the user.
-
@GOG Well, think of that "function" to be rather large, not a couple of lines of code, as clean code enthusiast would insist on. Better imagine something like @topspin 's "run imagemagic".
-
@BernieTheBernie There's no actual rule as to how big a function is supposed to be.
It would be fairer to say that the service offered is the ability to transparently spin up a separate server-side process for asynchronous (I assume) execution of some stateless operation intended to produce a result.
-
@GOG Marketing needs more shinier words.
-
This also isn't my kind of thing, so same disclaimer as @topspin.
Take the image resizing service. You're now passing an image over the network twice, encoding and decoding it into various protocols on the way, instead of just doing the thing. Besides overheads, the network is high latency and slow bandwidth (OK, you might already be in ${whatever} datacenter, so the impact of that is somewhat mitigated). Is it really worth it?
-
@boomzilla I really need to use the "Delivering this feature goes against everything I know to be right and true and I will sooner lay you into this barren earth than entertain your folly for a moment longer." quote more often, and unironically.
-
There's also the
 -scalability thing. If the mean time between requests to "scale image" is less than the mean time it takes to "scale image" then you want more instances of the job to be running concurrently without slowing each other down — enough that (time to process)/(number of instances) < (time between requests). Otherwise the backlog will keep growing.
-scalability thing. If the mean time between requests to "scale image" is less than the mean time it takes to "scale image" then you want more instances of the job to be running concurrently without slowing each other down — enough that (time to process)/(number of instances) < (time between requests). Otherwise the backlog will keep growing.Ditching the overhead of VMs or containers makes firing up a "function" for every request that comes in more attractive. The network latencies and bandwidth are a cost (but the former doesn't, for example, affect the request rate), so the time to execute the function has to be significant enough that adding the lag doesn't affect "time to process" much.
The toy example I've seen was a high-resolution fractal renderer. The client would render a sampling of pixels and, based on how long those pixels took, may chop the image into pieces and submit the pieces to a cloud service to be rendered there; does the time saved by cutting the image in four and quartering the rendering time justify the extra back-and-forth? Especially if it retains one quarter to continue rendering locally?
-
@cvi said in Circle of Size:
This also isn't my kind of thing, so same disclaimer as @topspin.
Take the image resizing service. You're now passing an image over the network twice, encoding and decoding it into various protocols on the way, instead of just doing the thing. Besides overheads, the network is high latency and slow bandwidth (OK, you might already be in ${whatever} datacenter, so the impact of that is somewhat mitigated). Is it really worth it?
Whenever the network latency is a small percentage of the time it takes to do the whole thing, and the encode/decode overhead a small percentage of the total CPU time.
@GOG said in Circle of Size:
spin up a separate server-side process for asynchronous (I assume) execution
It's still synchronous in the sense that something opens a connection, sends a request, and then has top hang around until eventually the result comes back over the same connection.
Although it would probably be and worthy of a maximize-the-WTF challenge to design it truly asynchronously so the requester fires off the request with a return address, closes the connection, and the other services have to use a DHT to find the way back. Hey, it's like neurons firing, it must be the natural way to do things, right? I should trademark a fancy name for when it becomes the next big thing!
and worthy of a maximize-the-WTF challenge to design it truly asynchronously so the requester fires off the request with a return address, closes the connection, and the other services have to use a DHT to find the way back. Hey, it's like neurons firing, it must be the natural way to do things, right? I should trademark a fancy name for when it becomes the next big thing!
-
@Watson said in Circle of Size:
Ditching the overhead of VMs or containers makes firing up a "function" for every request that comes in more attractive. The network latencies and bandwidth are a cost (but the former doesn't, for example, affect the request rate), so the time to execute the function has to be significant enough that adding the lag doesn't affect "time to process" much.
Especially when stuff is written in JS it sounds very much like quarter-century-old FastCGI wine in new fancy, serverless™ bottles.
-
A lot of the “but serverless” arguments come down to “I pay for exactly what I use rather than a set amount of resources every month” which in startup mode can be useful, or not.
As for microservices, a lot of it is the myth that black boxing bits of functionality somehow improves maintainability (it can but it does not guarantee that it will, especially because most of the architecture astronauts build it like the video).
I continue to be #monolithforever and may even write a book about this shitshow, “Monolith Forever: Developer Bullshit Unplugged” or some such.
-
@LaoC said in Circle of Size:
Especially when stuff is written in JS it sounds very much like quarter-century-old FastCGI wine in new fancy, serverless™ bottles.
JavaScripters saying they've come up with something new?!
I just keep coming back to this video:
-
@Arantor said in Circle of Size:
@boomzilla I really need to use the "Delivering this feature goes against everything I know to be right and true and I will sooner lay you into this barren earth than entertain your folly for a moment longer." quote more often, and unironically.
From the comments:
I'm a backend developer and this inspires me a lot to become a cooking chef.
My kind of guy.
-
-
@cvi said in Circle of Size:
Is it really worth it?
You are a heretic. Any
Cloud Evangelist
 will tell you that it is.
will tell you that it is.
Because when you run that job within your main äpp, it competes with it for resources: the CPU, memory, disk IO, ... etc.
And it gets "tightly coupled" (Why does it make me think of dogs at the end of mating?) to your äpp, which means that when your main äpp crashes, the extra job also crashes with it (the other way round may be prevented with app domains, but that is duh too much effort, too).So, now do it correctly. Send a request into some message queue (RabbitMQ, Kafka, Azure Event Grid, ... you name it), let the cloud spin up the serverless function, let the function return its result to another message queue, which then somehow gets back to a service which will do something with the result (maybe your main app, but not necessarily the same instance), ...

-
@LaoC said in Circle of Size:
It's still synchronous in the sense that something opens a connection, sends a request, and then has top hang around until eventually the result comes back over the same connection.
I was rather thinking of the calling process resuming execution until the remote service calls back with the result.
-
@LaoC said in Circle of Size:
Whenever the network latency is a small percentage of the time it takes to do the whole thing, and the encode/decode overhead a small percentage of the total CPU time.
But that's BS. That just means the additional overhead is small compared to the work, but it doesn't make it worth it. It hasn't yet added anything of utility.
-
@cvi said in Circle of Size:
@LaoC said in Circle of Size:
Whenever the network latency is a small percentage of the time it takes to do the whole thing, and the encode/decode overhead a small percentage of the total CPU time.
But that's BS. That just means the additional overhead is small compared to the work, but it doesn't make it worth it. It hasn't yet added anything of utility.
Sure, always assuming you've identified a thing that needs more CPU than you have locally. Or that it makes stuff significantly easier to write.
I wrote this toy system in the late noughties when I had a shared 256kbit line and wanted to browse a forum with a lot of gifs. So I wrote a Greasemonkey script that would do a HEAD on each gif in a page and if it was bigger than a few kB, rewrite it to a request to my own web service. That downloaded the picture and returned a new URL for a local copy that would have the image transcoded to jpg or mp4. For the web service I was basically just running curl and ffmpeg, but I delegated it to Gearman. Mostly just to try that out, but it also made the whole thing very convenient to write because I didn't have to care about process management. Only file names and URLs get passed back and forth because I wanted to cache stuff on disk anyway, and compared to the latency of downloading from remote and potentially transcoding, the added latency was completely irrelevant, too, so it worth it to me even if I never had to add any workers.
-
@Arantor said in Circle of Size:
A lot of the “but serverless” arguments come down to “I pay for exactly what I use rather than a set amount of resources every month” which in startup mode can be useful, or not.
We already have a similar discussion, and I have already given my example: I am running a small "web application" that is actually implemented as AWS Lambda (ie: HTTP request is served as lambda function). So we pay for the CPU spent processing. Which is actually $0, because the everything fits in the "Free Tier".
We do pay for some services without Free Tier, but it is like $30/month in total and totally worth it in my book.But it was designed that way.
If you just start spinning lambdas, doing intensive processing AND sending lots of data over the network.... well, someone is needed to make Jeff Bezoz's richest man on Earth again.
-
@topspin said in Circle of Size:
@hungrier yeah. In my world, the choice would be to fire off a separate process (and deal with the fragility of IPC / error handling) or just put it on a background task. Assuming it’s not a separate executable in the first place, then it’s just “run image magick”.
That is basically it, except that you don't have to worry about the infrastructure where it runs. Well, you should, but don't have to (see my previous post).
ETA: also, obligatory mention of letter CDN, which an idiot like me could’ve avoided with 20 lines of non-retarded stuff.
I am not sure how to take it... it is quite likely that you don't need CDN, so you can avoid it with even 0 lines. But if you need it, you absolutely cannot do it with any lines of anything, because it needs a lot of hardware (well, ok, I suppose the network cables could be called "lines",
 ).
).But the very fact that you feel the need to mention it suggest that someone is selling CDN without having well-equipped datacenters around the planet, which sounds like a nice scam. Could you share the story as a mini-
?
-
@Kamil-Podlesak the letter CDN is a specific piece of idiocy from Discourse.
If you have a user with no set avatar, they have a letter on a coloured background. Instead of having this as text+CSS or even “generate an image on registration and treat that as an uploaded avatar”, Discourse literally rolled out a CDN whose sole purpose is serving letter-on-coloured-square images.
For example:
https://avatars.discourse-cdn.com/v4/letter/k/b487fb/288.png
Taken from the first example I could find on meta.discourse.org just now, so it’s still live.
-
@Arantor said in Circle of Size:
@Kamil-Podlesak the letter CDN is a specific piece of idiocy from Discourse.
Thanks, I have never seen that. This is indeed silly and very specific
-
No, it's not worth it.
-
@topspin said in Circle of Size:
In my world, the choice would be to fire off a separate process (and deal with the fragility of IPC / error handling) or just put it on a background task. Assuming it’s not a separate executable in the first place, then it’s just “run image magick”.
It's "run image magick... as a service!"
-
@topspin said in Circle of Size:
First time I heard that an AWS “lambda” is a micro-service for a single function I thought that’s insane. I have so many functions in my code, and it’s a tiny code base compared to what people out there in the real world are dealing with. Surely, that makes no sense at all. But since I don’t see the point of micro-services to begin with, it’s all the same to me.
For a lot of things in corpo land it's a good fit. You tend to have a lot of batch processes that run nightly or hourly and instead of having servers sitting around doing nothing most of the time, it's cheaper to punt them there. They're also on a much smaller scale than microservices and you can get away from the cruft of old systems.
That's the ideal. What you get is enterprise-level overly complicated shit and an outdated diagram that's missing a few steps. In one of the diagrams here, the latest iteration introduced a redis cache to reduce lambda calls.
I suspect any savings made would be outweighed by the time it takes development teams to figure out how it all works.
*edit the service I mentioned here hasn't been developed and run yet and they're already optimisting.
-
After decades of teaching developers to write Don’t Repeat Yourself code, it seems we just stopped talking about it altogether.
To be honest, we didn't even settle this argument. The response to this was patterns, shared libraries or codegen and they turned into an overly complicated crock of shit.
Number one justification for microservices in corpo is usually getting away from the old garbage that DRY introduced.
It's not funny to see a developer die a little more inside when business/tech lead/architect mandates that some old libraries be used on a greenfield, now shitfield, microservice.
-
@DogsB To be fair, DRY is - in my experience - a good practice that helps ensure that shared functionality is maintained throughout changes for all users. Whether you implement it through a library, service, or whatever, it's nice to know you're unlikely to run into "we changed things to match the new requirements everywhere except this one seldom-used bit of functionality that everyone forgot about".
The biggest problem is that you need someone who understands how the entire architecture works, and how it may be used, at all times (and while you're at it, have this one person/group be responsible for the inevitable changes to same).
In practice, there's a good chance that the, also inevitable, personal changes will result in understanding of the plumbing being lost, to the point where nobody's willing to touch the thing, lest something important breaks. Safer to just write your own, ad hoc thing, that you're sure will do what you need it to, and won't affect anything else.
-
From the same guy.
Quinn, a cloud services expert, mentioned a running prank that he sometimes pulls on Amazon engineers: Quinn inserts a fictional AWS service name into the conversation, with the AWS person not batting an eye. Even Amazon’s employees do not have the complete grasp of all the vast Cloud offerings their own company provides. And what chance do the rest of us have?

Ken Kantzer, of the startup auditing firm PKC, mentioned in the Changelog podcast a common case of software developers not understanding that JWT tokens are not encrypted by default. Developers were shown plain-text version of their own JWT tokens, to their amazement - with sensitive information right there for anyone to read.
JWT is a crock of shit for the most part. How do you feel about what is essentially 70kb cookies and passing it to every fucking service you have to ignore reading the audience property.
Who gets to validate that rebuilding your entire application in Lambda is not just someone’s resume-driven development effort but a pragmatic decision, not resulting in nasty performance and cost surprises?
-
@DogsB and so I continue to be #monolithforever for both of these reasons - you don’t need JWT when you can authenticate with a single cookie to rule them all and you can authorise everyone centrally without needing to carry scope around in a blob, plus when you have one codebase you can find things in it without needing a stellar map produced by an architecture astronaut.
-
@Arantor said in Circle of Size:
#monolithforever
I do not believe that your monolith is a
True Monolith , I am sure that the database was outsourced to a standard database system (mysql, MS SQL Server, ...), and perhaps runs on a dedicated machine. Since you do web programming, you likely use a standard web server product (Apache, IIS  , ...). File storage is generally taken for granted as part of an OS, but you may have considered NAS or something like that. Monitoring of the system may be outsourced to Nagios and their ilk. And perhaps even more such points.
, ...). File storage is generally taken for granted as part of an OS, but you may have considered NAS or something like that. Monitoring of the system may be outsourced to Nagios and their ilk. And perhaps even more such points.
Many such services are just integrated nowadays.
-
@DogsB said in Circle of Size:
Ken Kantzer, of the startup auditing firm PKC, mentioned in the Changelog podcast a common case of software developers not understanding that JWT tokens are not encrypted by default. Developers were shown plain-text version of their own JWT tokens, to their amazement - with sensitive information right there for anyone to read.
Classic
people are surprised that MAC is not the same as "encryped". No surprise here - it's a cryptography, so it's the same, right? 
JWT is a crock of shit for the most part. How do you feel about what is essentially 70kb cookies and passing it to every fucking service you have to ignore reading the audience property.
Second
 is that people are putting data in their JWT. I mean, the T stands for Token, and 70kB cookie does not really look like TOKEN.
is that people are putting data in their JWT. I mean, the T stands for Token, and 70kB cookie does not really look like TOKEN.
-
@Kamil-Podlesak said in Circle of Size:
@DogsB said in Circle of Size:
Ken Kantzer, of the startup auditing firm PKC, mentioned in the Changelog podcast a common case of software developers not understanding that JWT tokens are not encrypted by default. Developers were shown plain-text version of their own JWT tokens, to their amazement - with sensitive information right there for anyone to read.
Classic
people are surprised that MAC is not the same as "encryped". No surprise here - it's a cryptography, so it's the same, right? I once got a task from a contracted tech lead to encrypt values sent from js to an endpoint that was already over https. He was actually promoted a few months later but I never got around to implementing that ticket.
*edit
He was looking at the network tab in Chrome devtools wondering why the values were in plain text. Could never get him to understand that the backend would have to be updated too. Or if the user was that badly compromised the attacker had better things to look at than our analytics.
-
@BernieTheBernie my sweet summer child.
I do PHP programming on commodity hardware. I get given a folder on a VPS which is the sum total of all I see. Database is connected on 127.0.0.1, all my files are right there on the server unless I explicitly choose to wire them up outside, including my code, my uploaded files, everything. Even having something like Redis or Memcache can be exotic.
If there is NFS, all my files are together on it.
Monitoring? MONITORING? Uptime.com is the best I have.
I’ll give you that I don’t compile everything into a single executable which is the web server as well as the app, but that’s a slightly
 interpretation and not usually what people think of when they talk about monolith vs serverless even if I’ll grant you that it’s not a “real” monolith.
interpretation and not usually what people think of when they talk about monolith vs serverless even if I’ll grant you that it’s not a “real” monolith.
-
-
@dkf this is the time we need that Pawn Stars meme with the pendant icon going, “best I can do”.
But yes, no true monolith fallacy lurks around the corner

-
@DogsB said in Circle of Size:
*edit the service I mentioned here hasn't been developed and run yet and they're already optimisting.
I worked on a web app for time tracking software, they had implemented Redis (poorly) for a site that had a few hundred users, half of which were internal staff for the company writing the software. Redis was added to try to resolve their database load/cost issues (that were caused by a bad reporting rollup stored procedure and not actual website load anyway, but that's a different story). But nobody ever really looked that closely into the billing end to see whether it really helped. And eventually, like all poorly implemented caching solutions do, it led to stale page loads and a cross-client data leak.
As we're all working on the hair-on-fire P0 to solve the issue, the person who originally set up Redis is no longer on the team and nobody else really knows much about the software at all. So about 30 minutes in, we finally get the original architect on the conference bridge, and I have the temerity to suggest "why not rip Redis out and see if we really need it? from what we've found so far, it doesn't look like it's really accomplishing much, maybe we're just spending money on Redis for no actual benefit anyway." Ex-architect gave me the stink eye but was like "well, that seems like a good step for the current spot, and it's y'all's project now
 "
"And lo, they saw that going back towards monolith was blessed. And it was evening, and morning, the next business day.
-
So, now do it correctly. Send a request into some message queue (RabbitMQ, Kafka, Azure Event Grid, ... you name it), let the cloud spin up the serverless function, let the function return its result to another message queue, which then somehow gets back to a service which will do something with the result (maybe your main app, but not necessarily the same instance)
I once had to write a service to wake up another service by pushing a message onto a queue. Once the second service received this message it made a rest call to my service and if successful would then send the acknowledgement.
I think I might need to leave this profession.
-
@DogsB I’m working on a diversified exit strategy for this reason.
-
@Arantor said in Circle of Size:
@DogsB I’m working on a diversified exit strategy for this reason.
My "become a lottery winner" strategy is fairly stalled out

-
@topspin said in Circle of Size:
You could’ve built that with half of the WTDWTFers too bored to build real stuff.
Only
 stands between us and world domination.
stands between us and world domination.
-
@Arantor said in Circle of Size:
But yes, no true monolith fallacy lurks around the corner
Most examples given of fallacies are not true fallacies.
-
-
@dkf said in Circle of Size:
@Arantor said in Circle of Size:
that’s a slightly
interpretationDuh! That's the best we can do on
No, it's not. We routinely do very
, and on good days we get to extremely .
 Learnings from 5 years of tech startup code audits - Ken Kantzer's Blog
Learnings from 5 years of tech startup code audits - Ken Kantzer's Blog
 All About Polymorphics : Thompson Ramo Wooldridge, Inc. : Free Download, Borrow, and Streaming : Internet Archive
All About Polymorphics : Thompson Ramo Wooldridge, Inc. : Free Download, Borrow, and Streaming : Internet Archive

