Unicode 14 finalised; Disco Horse now recognised
-
Five weeks ago (2021-09-14) the UnicodeⓇ Consortium announced Version 14.0 of The UnicodeⓇ Standard:
https://home.unicode.org/announcing-the-unicode-standard-version-14-0/It adds support for UnicodeⓇy things with new scripts and characters, symbols and the like.
There’s also 37 new Very-Important-to-UnicodeⓇ’s-Purpose emoji characters, of course.
Bringing wonders such as the melting face, face with diagonal mouth (distinct from
 , of course), but of utmost importance is U+1FAA9 MIRROR BALL!
, of course), but of utmost importance is U+1FAA9 MIRROR BALL!No need for custom

 s no longer, soon the DISCO HORSE will bless the very essence of modern text encoding itself! Uh, yay.
s no longer, soon the DISCO HORSE will bless the very essence of modern text encoding itself! Uh, yay.Somewhat distressing is the addition of U+1F9CC TROLL which provides a disgustingly non-oblique way to signify that subtle concept of a “troll”.
There’s also coral and lotus but still no fern you’ve had almost 400 million years to get your act together but I digress. Quite a number of utterly useless things but much to remi’s (I think? Vague recollection of you seeking the following) delight there is finally a heavy equals sign to complement all the other heavy mathematical operators.
So get excited for 🪩🐎! Maybe there’s a zero-width-joined sequence in the near future… maybe not.
-
@kazitor said in Unicode 14 finalised; Disco Horse now recognised:
So get excited for 🪩🐎! Maybe there’s a zero-width-joined sequence in the near future… maybe not.
I'd be seriously worried about what some idiot would choose to draw that combined form as…
-
@kazitor said in Unicode 14 finalised; Disco Horse now recognised:
Quite a number of utterly useless things but much to remi’s (I think? Vague recollection of you seeking the following) delight there is finally a heavy equals sign to complement all the other heavy mathematical operators.
Nice. I do have a vague recollection of having ranted about some missing operators, so yeah, that probably was that.
Though me being an upstanding WTD
 citizen (
citizen ( ) (narrator: the
) (narrator: the  wins every time), I usually prefer to type for one of our emojis rather than searching for a unicodepoint and how to input it.
wins every time), I usually prefer to type for one of our emojis rather than searching for a unicodepoint and how to input it.Maybe there’s a zero-width-joined sequence in the near future… maybe not.
I'm not familiar enough with unicode (and don't want to be!), but is there some sort of specification of which sequences can be zero-width joined, and what the result should look like? Or can any font designer randomly decide that joining U+12345 with U+54321 will result in a "yo mama" joke?
-
@remi the correct-enough answer is that Unicode specifies some combinations of joins and especially up in the emoji range client apps have some precedence for doing whatever the fuck they feel like. So score 1 for OSes doing odd things.
But then you have font ligatures. These specify at the font level how “these adjacent glyphs” can become “this other glyph”. The common example is how in a bunch of fonts,
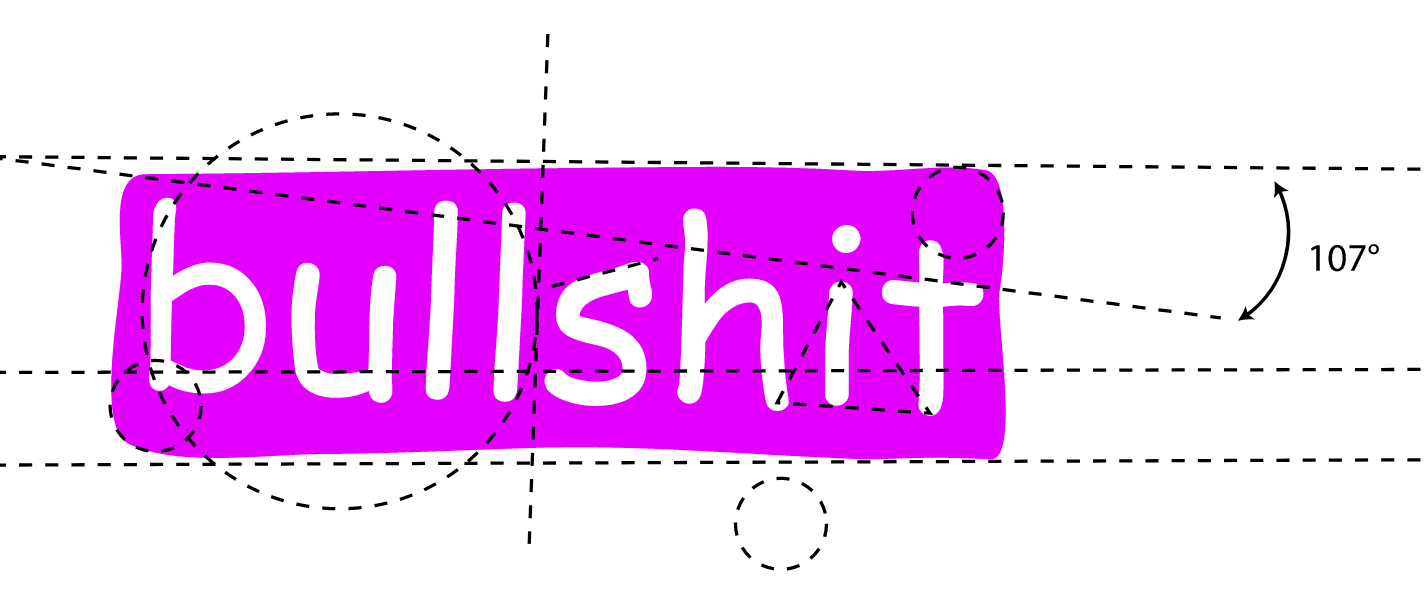
fimay well have a nicely drawn fi (though not this font) glyph where the bridge of the f joins the top of the i.My favourite example use of this is https://www.sansbullshitsans.com/ - each of the letters is normal but if you join the following 5 letters together: a, g, i, l, and e, you get a new dedicated glyph rendered instead.
-
@Arantor said in Unicode 14 finalised; Disco Horse now recognised:
My favourite example use of this is https://www.sansbullshitsans.com/
Seriously (?) though, this means that not only Unicode is full of random shit (and keeps adding to it), but everyone can do whatever the fuck they want to add even more random shit to it. It's a wonder we still manage to actually communicate when you can't have the slightest idea how what you're typing is going to be seen, let alone interpreted, by the other side...
-
@remi said in Unicode 14 finalised; Disco Horse now recognised:
It's a wonder we still manage to actually communicate when you can't have the slightest idea how what you're typing is going to be seen, let alone interpreted, by the other side...
You've seen evidence of communication?
-
@boomzilla well in our case we're all in your mind anyway, so I guess we don't need unicode to communicate.
Other than that... maybe we can do a bit better than "G, D, A, lower octave A, and E?"
Filed under: references that are either obscure or indicate
 , I guess?
, I guess?
-
@Arantor this is amazing. How can I install this on every computer on the planet?
Filed under: something something sudo?
-
@remi said in Unicode 14 finalised; Disco Horse now recognised:
@Arantor said in Unicode 14 finalised; Disco Horse now recognised:
My favourite example use of this is https://www.sansbullshitsans.com/
Seriously (?) though, this means that not only Unicode is full of random shit (and keeps adding to it), but everyone can do whatever the fuck they want to add even more random shit to it. It's a wonder we still manage to actually communicate when you can't have the slightest idea how what you're typing is going to be seen, let alone interpreted, by the other side...
What they do is based on OpenType though, not Unicode as such. Unicode has a few precomposed ligatures and defines a fixed set of characters that can be combined, most popularly the emoji skin tone, gender and whatnot modifiers, but you can't just make up your own.
-
@LaoC yup, so there’s combining shit at the character set level and the font can optionally do things on top of (or potentially differently to) that.
It’s absolutely mental how complex this stuff is because the concept of “what is a character” is now very ambiguous whether you’re talking about a character, a grapheme, and/or a glyph.
-
@Arantor said in Unicode 14 finalised; Disco Horse now recognised:
It’s absolutely mental how complex this stuff is because the concept of “what is a character” is now very ambiguous whether you’re talking about a character, a grapheme, and/or a glyph.
It all depends on what that byte sequence self-identifies as.
-
@dkf kinda. What’s to stop a stream of UTF-8 being confused with ISO-8859-1?
And then on the other hand if you have a stream of UTF-32 vs UTF-8 that still only gets you “these bytes indicate these code points” which may or may not be interpreted by systems higher up the stack as characters or not.
There are systems that notionally recognise UTF-8 but do it wrong to the point of pretending that combining characters don’t exist and either ignore them, or in some cases treat them as a glyph it doesn’t know how to render.
My favourite are the things that play “count the characters” and watch the confusion in users when you feed such things two emoji with a combination character and the count goes down by a number that might be 1, 2, 3, 8 or 12 depending on what method of counting is involved and situationally any or all of these might be wrong!
It’s good fun this combination character stuff. Personally I think it makes a pretty compelling case for most things to ignore length where possible, or be very very clear about what you’re accepting in what context. And I’ll admit I’m just an enthusiastic amateur at it, I’m sure I get it wrong too, but I try to get it less wrong.
-
@Arantor said in Unicode 14 finalised; Disco Horse now recognised:
It’s good fun this combination character stuff.
Well yes, until you're trying to build a GUI component that lets you do editing of this stuff, because that's when suddenly you care about all the meanings at once.
-
@Arantor said in Unicode 14 finalised; Disco Horse now recognised:
My favourite are the things that play “count the characters” and watch the confusion in users when you feed such things two emoji with a combination character and the count goes down by a number that might be 1, 2, 3, 8 or 12 depending on what method of counting is involved and situationally any or all of these might be wrong!
This has come far enough that you're better off treating it like crypto stuff: Unless you have at least a PhD thesis on this exact topic on your CV, leave it alone and use something that exists.
- if you use Perl, read everything Tom Christiansen has ever written and use that
- elsif you use something that has ICU, use it
- else you poor bugger
-
@LaoC I work with PHP where ICU is an optional extra that is too exotic for most of the people using the language.
And I can’t always talk people out of their stupid requirements like “the page must have no more than 235 characters of description otherwise it won’t fit” (because fixing this in CSS is impossibru, as any fule kno)
And I’d quite happily leave it at simple characters but the client wants to put emoji in because they like how it looks and then it all gets horribly confused for everyone.
Or better I’d not limit it in the first place because I’m capable of fixing it like a grownup!
-
@dkf web browser plus stupid requirements. It’s unbeatable.
-
@LaoC said in Unicode 14 finalised; Disco Horse now recognised:
- if you use Perl
- else you poor bugger
Logic error detected.