Git hates UTF-16
-
"Use git", they said. "It'll be fine", they said.
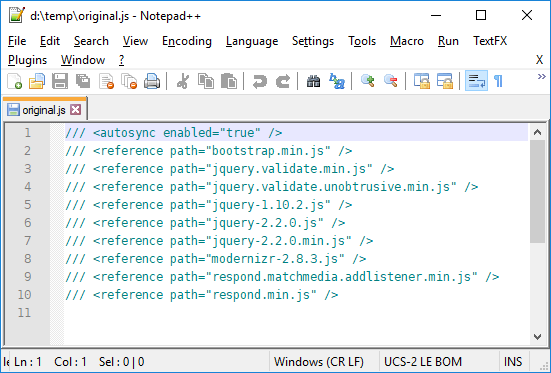
One checkout later, on a different machine:
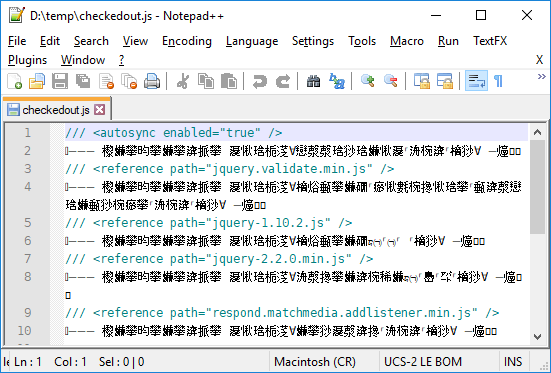
(ノಠ益ಠ)ノ 彡 ┻━┻
-
@JBert It that's what it takes to stop people from using the world's shittiest encoding, so be it!
-
@Deadfast What do you mean, "shittiest encoding"? PHP tried to use it!
-
@kazitor So does Windows in fact.
-
@Deadfast said in Git hates UTF-16:
@JBert It that's what it takes to stop people from using the world's shittiest encoding, so be it!
There's no reason that file has to be encoded in UTF-16, so some tool (maybe Visual Studio!) must have done it. The above problem only got noticed after a whole bunch of history was imported from TFVC, which means the import either needs to be done over again or the file needs to be discarded.
Likely it's going to be the latter, seeing how it seems to be nothing but comments.
-
As for how this problem came to be:
See the original bytes versus the later files' bytes:
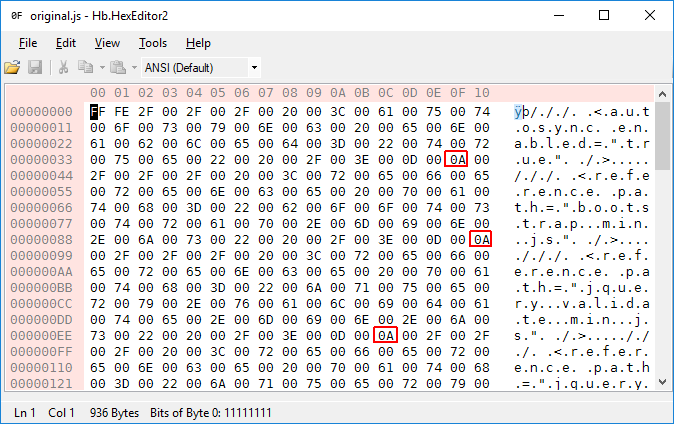
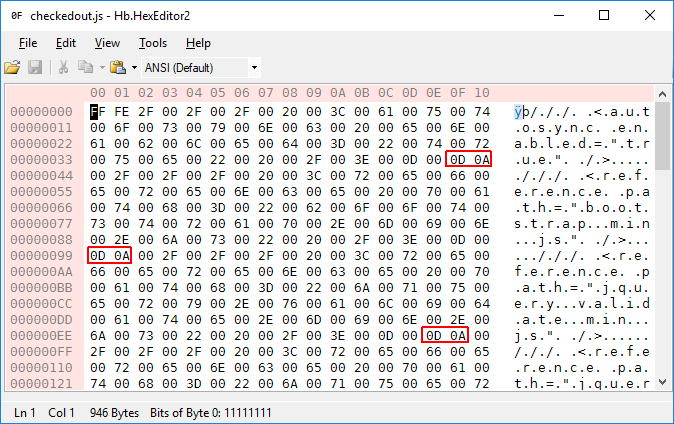
Git converts Windows newlines (0x0D 0x0A) into Linux endlines (0x0A) when you commit on Windows, and it does the reverse operation when you check out a file on Windows.
However, this "smart" feature fails to detect UTF-16, even though the file in this case is full of null bytes (0x00) and despite the byte order indicator (0xFF 0xFE) at the start of the file. Then when the file gets checked out it turns every single 0x0A byte into a 0x0D 0x0A pair, thus shifting every line by one byte. Since UTF-16 uses (multiples of) two bytes for each character, all even lines are garbage while odd lines will match the usual two-byte offsets again and display fine.
-
@levicki But the problem isn't newline conversion; it's UTF-16-unaware newline conversion.
-
@levicki said in Git hates UTF-16:
@JBert That's what you get for not specifying "commit as is, checkout as is". Solved with
core.autocrlf = false."Solved" you say.
Turning the conversion off is fine until the Windows sheeple and Mac weenies start duking it out on what endlines are best (or even stupidly combine both in the same file!) and $deity knows that the CI server is not going to like any of it. (Meanwhile our single hardcore Linux developer will sigh and tweak his Vim dotfiles. Again. And then waste some more time juggling branches in his dotfiles repo on github.)
Like @kazitor said, if only Git would leave UTF-16 alone or simply worked right like it does for all other text files. Obviously "correct" has a different meaning in Git land.
-
@JBert said in Git hates UTF-16:
@levicki said in Git hates UTF-16:
@JBert That's what you get for not specifying "commit as is, checkout as is". Solved with
core.autocrlf = false."Solved" you say.
Turning the conversion off is fine until the Windows sheeple and Mac weenies start duking it out on what endlines are best (or even stupidly combine both in the same file!) and $deity knows that the CI server is not going to like any of it. (Meanwhile our single hardcore Linux developer will sigh and tweak his Vim dotfiles. Again. And then waste some more time juggling branches in his dotfiles repo on github.)
Like @kazitor said, if only Git would leave UTF-16 alone or simply worked right like it does for all other text files. Obviously "correct" has a different meaning in Git land.
I suppose using UTF-8 like a sane person is out of the question.
-
@Gribnit sometimes, yes. For reasons beyond the developer's control.
-
@Gąska said in Git hates UTF-16:
@Gribnit sometimes, yes. For reasons beyond the developer's control.
Listen, if you're going to say there are whole countries that use UTF-16 I am going to say that people can move.
-
@JBert said in Git hates UTF-16:
Turning the conversion off is fine until the Windows sheeple and Mac weenies start duking it out on what endlines are best
Oh christ. We're only on Windows and we've been duking that out for the 6 years I've been here. I'm going to blame the people who work in cygwin on Windows.
-
@Gribnit said in Git hates UTF-16:
@Gąska said in Git hates UTF-16:
@Gribnit sometimes, yes. For reasons beyond the developer's control.
Listen, if you're going to say there are whole countries that use UTF-16 I am going to say that people can move.
No. I meant legacy programs.
-
@Gąska said in Git hates UTF-16:
@Gribnit said in Git hates UTF-16:
@Gąska said in Git hates UTF-16:
@Gribnit sometimes, yes. For reasons beyond the developer's control.
Listen, if you're going to say there are whole countries that use UTF-16 I am going to say that people can move.
No. I meant legacy programs.
That's kinda weak, the legacy component could have a loader or pre-processor written for it. Hard for me to see how a legacy program would require the whole codebase to be in UTF-16.
-
@Gribnit who said anything about whole codebase?
-
@Gąska said in Git hates UTF-16:
@Gribnit who said anything about whole codebase?
So then, any part of committed codebase. Legacy thing takes UTF-16, you commit UTF-8 and convert to UTF-16 for legacy run. I squarely blame you for this situation.
-
@Gribnit so now the commits are in UTF-8. And the legacy code expects UTF-16. Who does that conversion, if I don't have anything in my codebase for it?
-
@Gąska said in Git hates UTF-16:
@Gribnit so now the commits are in UTF-8. And the legacy code expects UTF-16. Who does that conversion, if I don't have anything in my codebase for it?
Get off your butt and write some code yo.
-
@Gąska said in Git hates UTF-16:
@Gribnit who said anything about whole codebase?
That would be our i18n
.rcfiles. Of course, the automated i18n tool creates them with unix EOLs and no BOM marker. Thankfully, VS handles them correctly. Any other editor - not so much.
-
@Gribnit said in Git hates UTF-16:
@Gąska said in Git hates UTF-16:
@Gribnit so now the commits are in UTF-8. And the legacy code expects UTF-16. Who does that conversion, if I don't have anything in my codebase for it?
Get off your butt and write some code yo.
But wouldn't that put UTF-16 handling code inside my codebase? I thought it's bad to have that?
-
@Gribnit said in Git hates UTF-16:
@Gąska said in Git hates UTF-16:
@Gribnit so now the commits are in UTF-8. And the legacy code expects UTF-16. Who does that conversion, if I don't have anything in my codebase for it?
Get off your butt and write some code yo.

Yeah. I really want my build to be:
- Check files out of git
- run tool
- build
- undo changes and/or run tool to convert into git-commitable
I see absolutely nothing that could go wrong in the process!
-
@Gąska I don't know why you think it would be bad to have code that handles the legacy format in your legacy-involving project.
-
@Gribnit because
@Gribnit said in Git hates UTF-16:
Hard for me to see how a legacy program would require the whole codebase to be in UTF-16.
@Gribnit said in Git hates UTF-16:
So then, any part of committed codebase.
-
@Gąska So, code that handles a format, it is not an artifact in that format. Those are different things yo.
-
@Gribnit yeah, I've noticed that we're talking about different things. I'm still trying to figure out what you are talking about, though.
-
@Gąska saying you could reduce the UTF-16ness of the artifacts to right before and right after the legacy component runs, with a wrapper around the legacy stuff.
-
@Gribnit okay, that covers artifacts. But what about inputs to legacy components that are at the front of pipeline? Say, configuration files that the component only accepts as UTF-16 file?
-
@Gribnit said in Git hates UTF-16:
Get off your butt and write some code yo.
Go fix Git.


Um actually, let me google. Ok, here's a thing:
Git recognizes files encoded in ASCII or one of its supersets (e.g. UTF-8, ISO-8859-1, …) as text files. Files encoded in certain other encodings (e.g. UTF-16) are interpreted as binary and consequently built-in Git text processing tools (e.g. git diff) as well as most Git web front ends do not visualize the contents of these files by default.
In these cases you can tell Git the encoding of a file in the working directory with the working-tree-encoding attribute. If a file with this attribute is added to Git, then Git reencodes the content from the specified encoding to UTF-8. Finally, Git stores the UTF-8 encoded content in its internal data structure (called "the index"). On checkout the content is reencoded back to the specified encoding.
-
@Zecc get out of here with your viable solution
-
@Gribnit said in Git hates UTF-16:
@Zecc get out of here with your viable solution
Don't worry, it's got lots of pitfalls.
-
@dcon said in Git hates UTF-16:
@JBert said in Git hates UTF-16:
Turning the conversion off is fine until the Windows sheeple and Mac weenies start duking it out on what endlines are best
Oh christ. We're only on Windows and we've been duking that out for the 6 years I've been here. I'm going to blame the people who work in cygwin on Windows.
3 workplaces in the last 5 years and I've being involved in the same arguement in all three.

Git should not be modifing the files in any way.

-
@DogsB said in Git hates UTF-16:
Git should not be modifing the files in any way.
But that would make it useless for version control...

I approve of this solution!
-
@Gąska said in Git hates UTF-16:
@DogsB said in Git hates UTF-16:
Git should not be modifing the files in any way.
But that would make it useless for version control...
I approve of this solution!
You'll have git write your code for you?

-
@dcon said in Git hates UTF-16:
BOM marker.
BOM markers are always enforced by the Department of Redundancy Department.
-
@pie_flavor And if you need to pay any fines to the DRD Department, they prefer that you head over to the ATM machine.
-
@lolwhat Make sure that you remember your PIN number!
-
@Deadfast said in Git hates UTF-16:
@lolwhat Make sure that you remember your PIN number!
Post it here just to be safe!
-
@levicki said in Git hates UTF-16:
Source control should not modify files.
That depends on what you interpret the file as being. For some file types, the correct interpretation is as a sequence of bytes. For others (e.g., program sources) the most relevant interpretation is as a sequence of characters. The right thing to do in those two cases is different.
Though anything using UTF-16 on disk is still retarded by design.
-
@levicki said in Git hates UTF-16:
Yes, solved. Source control should not modify files.
Take this example, you check in a CA.pem in repository (the one which your code is supposed to trust and which you use through OpenSSL). Git converts LF to CRLF in CA.pem file and suddenly your file is not compliant anymore and won't work.
Hence, core.autocrlf = false¹.Git has something called the
.gitattributesfile where you specify what types of file might look like text but need to be processed in a different way. That solves the issue with pem files for everyone ever touching the repo (whether or not they remembered to setcore.autocrlf).EDIT: Wait, at the end of your own post you refer to the
.gitattributesfile. Why even give this strawman then? /END EDIT@levicki said in Git hates UTF-16:
You forgot Linux zealots.
You forgot to read the rest of my humorous post, we've got one zealot.
@levicki said in Git hates UTF-16:
CR and LF used together in that order are the only proper endlines. Anyone who thinks otherwise should be flogged into submission with a shielded SCSI cable.
CR by itself is only supposed to reposition writing head (cursor) to the beginning of the current line.
LF by itself is only supposed to advance to the next line without moving the writing head.
Using either by itself is retarded. If people cannot compromise and accept both in order as it was designed, then they should stop arguing and settle on a new character which will be accepted by all 3 groups.You're serious, aren't you? How teletype printers worked has nothing to do with the "proper" way for endlines because those things have gone the way of the dodo. Computers don't necessarily have to stick to the representation those things used because neither CR or LF characters by themselves are treated a real control code nowadays.
The "CR by itself" and "LF by itself" have the advantage of wasting 1 byte less so there's definitely something to be said for them. At the end of the day though each variant of endline is now so frequently used that it's impossible to switch them all, so just pick a variant and don't mix them up within a file.
The reason to keep them forcefully consistent inside a repo is so that cross-platform development won't suddenly encounter a set of files where some have one variant, other files have the other variant. This means that a given tool one a single platform either accepts all files in the repo or accepts none, so that errors can be detected just by opening any random file.
@levicki said in Git hates UTF-16:
It can leave them alone if you set core.autocrlf = false as you should have, or if you mark them as binary files in your .gitattributes (*.foo -text).
If you read my initial post you would see it happens to be a single
JSONJS which got encoded in UTF-16. I don't want to mark allJSONJS files as binary, nor do I want them to lose the "normalization on commit" which currently happens.EDIT 2: I typed JSON when I meant JavaScript files.
-
@JBert said in Git hates UTF-16:
Computers don't necessarily have to stick to the representation those things used because neither CR or LF characters by themselves are treated a real control code nowadays.
 Allow me to direct you towards an unholy number of shell programs that do just that.
Allow me to direct you towards an unholy number of shell programs that do just that.
-
@pie_flavor said in Git hates UTF-16:
@JBert said in Git hates UTF-16:
Computers don't necessarily have to stick to the representation those things used because neither CR or LF characters by themselves are treated a real control code nowadays.
Allow me to direct you towards an unholy number of shell programs that do just that.Oops, I completely forgot about (v)TTY and VT100. Still, that's the "view" of a shell program, which doesn't mean that a file on disk necessarily needs to comply with whatever gets displayed (also see database 3NF and how views present that data in different ways).
-
@levicki said in Git hates UTF-16:
Sequence of characters is also a sequence of bytes (with fixed or variable number of bytes per character).
But a sequence of characters can be represented in bytes in multiple ways without “changing” them.
-
If you really want to get creative you could separate lines in UTF-8 encoded files with 0xE2 0x80 0xA8 (Unicode codepoint U+2028) for extra effect.

Filed under: Storage is cheap
-
@levicki said in Git hates UTF-16:
They are not supposed to be human readable.
Oh, hello there Mr. Crockford. Nice to meet you.
-
@levicki said in Git hates UTF-16:
@JBert said in Git hates UTF-16:
If you read my initial post you would see it happens to be a single JSON which got encoded in UTF-16. I don't want to mark all JSON files as binary, nor do I want them to lose the "normalization on commit" which currently happens.
So the is your JSON, not Git. Nobody puts CR LF in JSON. They are not supposed to be human readable.
Oops, I wrote JSON when I meant JavaScript.
Though I would still classify JSON and XML as "human readable", or rather "human readable but you don't want to" in full. Having newlines in those files can sometimes be useful.
-
@levicki said in Git hates UTF-16:
Or you could just use Notepad++ with JSONViewer plugin which shows them as a tree without the need for CR LF.
My browser does that by default…
-
-
@JBert said in Git hates UTF-16:
If you really want to get creative you could separate lines in UTF-8 encoded files with 0xE2 0x80 0xA8 (Unicode codepoint U+2028) for extra effect.
Filed under: Storage is cheap
Filed under: more recognition to those wonderful characters that are valid in JSON but not always valid in JavaScript
-
@levicki said in Git hates UTF-16:
[settings] option-1 = "Foo" option-2 = "Bar" option-3 = "Baz"FTFY
-
@levicki said in Git hates UTF-16:
I guess nobody briefed you on this thing called XML (and HTML)?
<MyAwesomeProgramConfiguration> <MyAwesomeProgramConfigurationSettings> <MyAwesomeProgramOption1>Foo</MyAwesomeProgramOption1> <MyAwesomeProgramOption2>Bar</MyAwesomeProgramOption2> <MyAwesomeProgramOption3>Baz</MyAwesomeProgramOption3> </MyAwesomeProgramConfigurationSettings> </MyAwesomeProgramConfiguration>You haven't seen enough XML.
<MyAwesomeProgramConfiguration> <MyAwesomeProgramConfigurationSettings> <MyAwesomeProgramOption> <MyAwesomeProgramOptionNumber>1</MyAwesomeProgramOptionNumber> <MyAwesomeProgramOptionValue>Foo</MyAwesomeProgramOptionValue> </MyAwesomeProgramOption> <MyAwesomeProgramOption> <MyAwesomeProgramOptionNumber>2</MyAwesomeProgramOptionNumber> <MyAwesomeProgramOptionValue>Bar</MyAwesomeProgramOptionValue> </MyAwesomeProgramOption> <MyAwesomeProgramOption> <MyAwesomeProgramOptionNumber>3</MyAwesomeProgramOptionNumber> <MyAwesomeProgramOptionValue>Baz</MyAwesomeProgramOptionValue> </MyAwesomeProgramOption> </MyAwesomeProgramConfigurationSettings> </MyAwesomeProgramConfiguration>
