Another Javascript surprise: undefined vs undefined
-
@nexekho said:
But how can you have a sparse array with a length of three but nothing in it?
That is literally the definition of a sparse array. That's what the "sparse" part means: not all slots contain a value. And "0 slots contain a value" certainly qualifies as "not all slots contain a value" for any array size > 0.
My beef with that is that it is not the only way to implement sparse arrays, and this one has some "unintuitive" consequences. "length" is not an arbitrary property: var a = []; a[0] = 1; changes the length of the array, just as if a was a dynamic array, and so do push() and pop(). And there isn't even a function to populate an array. It probably all comes from a post-hoc rationalization of an initial implementation there Array was just an Object, and push and pop changed the length property, and they were so happy with it that they kept it.
-
...are you saying it wasn't?
Depends on whether you can afford to not think about performance or not. On desktops, you can, which leads to better abstractions, cheaper maintenance and higher quality (if done right). On mobiles, you can't, so we must do things like it was 1993 again.Performance is important only if you're on the edge of being too slow to be usable at all. Quality is important always.
-
Performance is important only if you're on the edge of being too slow to be usable at all.
No; if you're too slow to meet your minimum responsiveness targets, you're too slow. However, most people shouldn't worry too much about performance and should instead think about using the right algorithm in the first place and making sure that their code doesn't make Baby Jesus cry.
There's one big exception to this. Infrastructure code (such as the .NET runtime) does need to be optimised pretty heavily since it ends up getting used all over the place. Most people don't write that sort of code (how many million computers run your code all the time?) but for people who do, working on chiselling even tiny savings can be very worthwhile.
-
The really fun part is if you've changed the object's toString function.
You can also assign to
undefined- hilarity will ensue.
-
No; if you're too slow to meet your minimum responsiveness targets, you're too slow.
And what have I just said?
-
-
There's one big exception to this. Infrastructure code (such as the .NET runtime) does need to be optimised pretty heavily since it ends up getting used all over the place.
It's not exception - it's still the same rule of "if it doesn't take more than X, you're good". The only difference is that on websites, X is several seconds, and in .NET core, X approaches zero.
-
It's not exception - it's still the same rule of "if it doesn't take more than X, you're good". The only difference is that on websites, X is several seconds, and in .NET core, X approaches zero.
It's the same, yet it isn't. For almost all code, keeping it all very clean is a better use of time. Infrastructure code is different because it is deployed so much more widely; knocking a microsecond off a rare case there can still save a lot of time in aggregate, and that can lead to it actually being genuinely justifiable to write code that is a little bit less clear in order to eke out a little bit more speed. That's usually a Bad Idea, and with good reason (because most programmers are too eager to jump into microoptimisation instead of thinking about getting their algorithms and deployment platform right).
-
My beef with that is that it is not the only way to implement sparse arrays, and this one has some "unintuitive" consequences. "length" is not an arbitrary property: var a = []; a[0] = 1; changes the length of the array, just as if a was a dynamic array, and so do push() and pop(). And there isn't even a function to populate an array. It probably all comes from a post-hoc rationalization of an initial implementation there Array was just an Object, and push and pop changed the length property, and they were so happy with it that they kept it.
So in other words, JS is one big mess from beginning to end.
What else is new?
-
It's the same, yet it isn't.
I hate when someone says that. After that, you can say whatever you want, and by the law of excluded middle, no one can say you're wrong.
-
-
After that, you can say whatever you want, and by the law of excluded middle, no one can say you're wrong.
Doesn't seem to stop people telling me that I'm wrong.

-
You're not wrong. You're not even wrong.
-
Also worth mentioning is that "array" keys/indices are actually strings, and anything that can be cast to a string (i.e., anything) can be used as an array index.
Yes. A web developer friend of mine had this to say when I asked about the performance implications of this:
Browsers make the case where you only index
Arrayobjects with integer indices fast. (By treating Arrays as arrays, obviously.) If you ever index anArraywith a non-integer index, then that optimization can no longer work, so never do that. Yes, Javascript is dumb and sucks.
-
this one has some "unintuitive" consequences. "length" is not an arbitrary property: var a = []; a[0] = 1; changes the length of the array, just as if a was a dynamic array, and so do push() and pop().
How is that not intuitive? It is a dynamic array, at least exhibited as one despite being a hash map under the hood. A sparse array may not have values at all positions, but if it has a defined length then it certainly can't (or at least shouldn't) have values at indices that don't exist. If you're permitted to write a value at an array index that didn't exist, then the array size has to change dynamically to allow for it, and the
lengthattribute should naturally change to indicate that.(Well, it can have arbitrary keys... anything that's not an integer in the range 0-4294967294 is a valid key but not a valid array index, so the
lengthattribute will not be changed; those keys can exist but simply be ignored for the purposes of considering it an array. Although there is a big performance hit, as @bugmenot already pointed out.)there isn't even a function to populate an array
Overlooked, but coming in ES6 as
Array.prototype.fill(currently supported in Firefox, Chrome, and Safari): https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/fill
You can also assign to
undefined- hilarity will ensue.Not anymore... it's not writable.
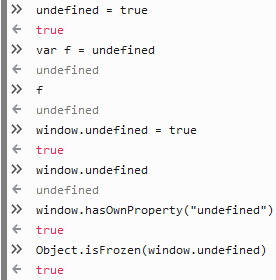
Note that the attempts to change
undefineddidn't work, but failed silently. In strict mode, attempting to write toundefinedwill throw an error instead of failing silently:
-
this one has some "unintuitive" consequences. "length" is not an arbitrary property: var a = []; a[0] = 1; changes the length of the array, just as if a was a dynamic array, and so do push() and pop().
How is that not intuitive?
Because it is not the length of the array, only the index of the highest element plus 1.
if it has a defined length then it certainly can't (or at least shouldn't) have values at indices that don't exist.
It does: they are undefined, except in map(). So while it is called an Array, and seems to behave like an array, in reality it isn't. I might have hoped for too much consistency.
And about the memory efficiency of sparse arrays: Chrome allocates 1024 slots when you create an empty array and assign to some arbitrary numeric index under 1024.
-
So while it is called an Array
It's called an array, but it's really an associative array. Plus some implementation magic to try to make it go faster.
-
it is not the length of the array, only the index of the highest element plus 1.
Length of sparse array != number of elements which are stored in it.
> if it has a defined length then it certainly can't (or at least shouldn't) have values at indices that don't exist.
It does: they are undefined, except in map(). So while it is called an Array, and seems to behave like an array, in reality it isn't. I might have hoped for too much consistency.
By "indices that don't exist", I meant array indices which are >= length. I was not referring to whether or not an element exists at any given index, only that the index was within the array's range, based on its
lengthproperty.Pretty much all of the builtin iteration functions that come with
Array.prototypewill skip empty slots in a sparse array, but that's a whole separate issue.
-
Not sure if JS or PHP is the bigger
 on its array/hash map mutation weirdness.
on its array/hash map mutation weirdness.