That is for another iteration
-
We're eating lunch, and I'm talking to a colleague who's a senior developer for another system in the company. I ask him what he's working on.
Him: "We're currently replacing our database with NoSQL" [this is a large system in production with heavy loads]
Me: "Wow, that must be quite an undertaking."
Him: "Yes it is. We're using cloud. We only do inserts, never updates. That way we don't have to worry about cache propagation."
Me: "But won't your inserts also need to propagate?"
Him: "Yes, but that's no problem. You'll get an old version of the row."
Me: "Ok.. But wouldn't that be the same with an update?"
Him: "No, but you see, if you don't get a result, it means we never have had the row, ever. And it's all JSON, you can just call the URL and you get the JSON."
Me: "Uh.. ok! [fake smile] How are you planning to generate reports?"
Him: "We don't know yet."
Me: "Don't you have a lot of data? Sounds tricky."
Him: "Yes, it's very tricky. But you see, that problem is for another iteration. We have to concentrate on getting the system on NoSQL first."
-
And then it turns out by NoSQL he meant that the application has no SQL in it. Everything's done through storedprocs, so we just made InsertX and SelectX.
As for using JSON? The row's data is in a text field called JSON in the table. (The only other field is ID, a non-indexed VARCHAR of course.)
-
smacks forehead
-
I think last year I attended a session on some event where this kind of architecture was explained:
There should be one table containing the "base" information and another "changelog" kind of table. Upon creating of the record, you INSERT a record in the base table and every change to this record becomes an INSERT in the changelog table. There is no need to lock tables during inserts because the Reports or the Screens are not supposed to ever query these tables.
In the background however, you have "pre-calculation" jobs. They take this base data + changelog data and turn them into "Presentation" data, which is actually used for Reports and Screens
This kind of architecture allows the application to accept new data very fast but also to generate new reports quite quickly, if you don't mind the delay of updating the "presentation" data. The amount of stale data depend on the frequency of your background jobs.
I'm still a bit fuzzy about the concept but I think above scenario makes sense
-
Hmm bjolling, that sounds like an interesting concept. Do you have more information about this?
-
J uly
S eptember
O ctober
N ovember
"What happened to August?"
"We forgot to insert it and now we can't update it."
-
@keigezellig said:
Hmm bjolling, that sounds like an interesting concept.
Do you have more information about this?Please send me the codes.
PSMTCTFY
-
@bjolling said:
every change to this record becomes an INSERT in the changelog table.
Erm.. WHAT? You're building up a table of delta changes... is someone trying to replicate journalling INSIDE the database itself? @bjolling said:
In the background however, you have "pre-calculation" jobs. They take this base data + changelog data and turn them into "Presentation" data, which is actually used for Reports and Screens
This simply sounds like they're delaying the update; there's bound to be some race condition when stale data is being returned for a query that's hit the presentation data between the "pre-calculation jobs"
I feel this is probably appropriate only in specific situations.
-
@keigezellig said:
Hmm bjolling, that sounds like an interesting concept. Do you have more information about this?
Oracle allows you to put triggers on views. Easy.
-
@bjolling said:
There should be one table containing the "base" information and another "changelog" kind of table. Upon creating of the record, you INSERT a record in the base table and every change to this record becomes an INSERT in the changelog table. There is no need to lock tables during inserts because the Reports or the Screens are not supposed to ever query these tables.
In the background however, you have "pre-calculation" jobs. They take this base data + changelog data and turn them into "Presentation" data, which is actually used for Reports and Screens
This kind of architecture allows the application to accept new data very fast but also to generate new reports quite quickly, if you don't mind the delay of updating the "presentation" data. The amount of stale data depend on the frequency of your background jobs.
Assuming MS SQL Server here
I don't understand the problem that this is trying to solve. Is the concern here that an UPDATE heavy environment will result in tables being locked for reports? If so SQL Server allows you to set transaction isolation levels and use snapshot isolation to manage the way the DB engine handles locking and versions of data.Or am I missing the point....
-
@RTapeLoadingError said:
Sorry for dumping this on you guys and then forgetting about my post for several days.Assuming MS SQL Server here
I don't understand the problem that this is trying to solve.
A part of what I described is called the CQRS pattern. I suppose this would be a decent starting point:
bliki: CQRS
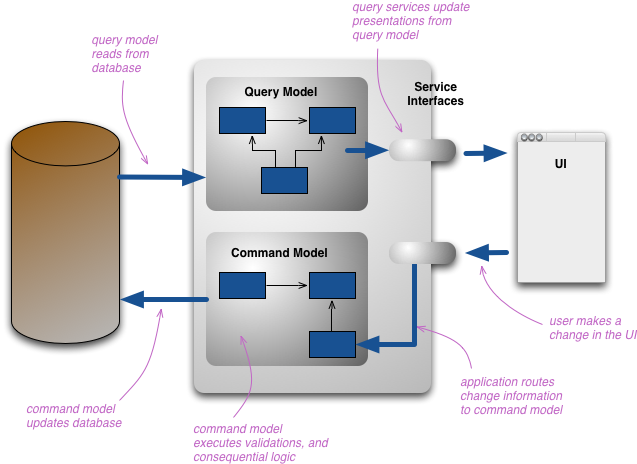
CQRS (Command Query Responsibility Segregation) is the notion that you can use a different model to update information than the model you use to read information
The reason I ignored the post is the same reason I'm not digging through my notes to find back the exact problem they were trying to solve: tomorrow morning I'm off skiing so I had a lot of task to finalize before the weekend and now it's time for bed because it's a long drive.