Azure bites
-
@Unperverted-Vixen said in Azure bites:
@Bulb said in Azure bites:
- As a bonus, the setting via API only accepts references to secrets, but apparently looks up certificates as well, because, under the impression from the portal that it wants a certificate I uploaded the certificate as that, and the app gateway found it.
Installing a certificate in Key Vault creates a hidden secret with the same name, with the contents of the private key. This allows you to grant an identity read access to the certificate but not the secret; they can then see the public portion (equivalent to the .cer file) but not the private portion (equivalent to the .pfx file).
Ah, thanks. I didn't really understand what's the point of the certificate type. It's … rather unintuitive the way it shows in the UI.
- But if you opt to use the option (that both the portal and the API also offer) to upload the certificate directly into the application gateway, the password is mandatory. So you have to encrypt the primary key. Which with openssl involves this magic incantation:
openssl pkcs12 -in cert.pfx -passin pass: | openssl pkcs12 -export -out cert-password.pfx -passout pass:1234. Because thepkcs12subcommand can't specify input and output formats separately, so it can only expand PKCS#12 to cert+key or compose cert+key to PKCS#12.
Or just install it on your local machine via MMC and export it again. (Although that has a tendency to fuck up the cert chain. App Gateway is fine with it but SSL Labs will whine.)
The certificate, having a key with it, shouldn't even be on the local machine, less so installed. Plus I already know how openssl behaves in general, so I know where to look if I want to do something specific. It's easier to just use it then then search how some other tool works.
-
@Bulb That second “suggestion” probably should have come with a
 . It’s definitely not the best way to do it, but since we didn’t have any experience with OpenSSL, it was our go-to for a while until someone in Corporate IT gave us the right incantations to use.
. It’s definitely not the best way to do it, but since we didn’t have any experience with OpenSSL, it was our go-to for a while until someone in Corporate IT gave us the right incantations to use.
-
@Unperverted-Vixen Yeah, it shouldn't need any incantations in the first place. And it … well, it does, but it's an
azincantation, not anopensslone.
-
Reading Microsoft's article series about Azure, I was a little astonished that they often mention that Azure may shut the instance where your Important Task
 is running.
is running.
E.g. in the article on the design patter "Leader Election":In a system that implements horizontal autoscaling, the leader could be terminated if the system scales back and shuts down some of the computing resources.

Really? Is there no possibility to veto the shutdown? In case of a Windows shutdown, a message usually gets sent to processes which could veto. So this Azure behavior looks more liking pulling the electric plug...
Who could of thought that that is a Good Idea ?
-
@BernieTheBernie said in Azure bites:
Is there no possibility to veto the shutdown?
How do you veto a hardware failure?
The whole premise of moving from special server hardware to clusters of commodity hardware is that even the most reliable beefy server can fail, so you have to make your software be able to resume after a failure, and when you do, you can just buy cheap hardware that fails more often, but you no longer care.
E.g. in the article on the design patter "Leader Election":
In a system that implements horizontal autoscaling, the leader could be terminated if the system scales back and shuts down some of the computing resources.
Well, the whole point of a leader election algorithm is to deal with nodes failing.
Now in this situation they are talking about a situation where you are saying one of the nodes can be shut down, presumably because the load has subsided and you don't need as many. Just the infrastructure will just pick one (at random or otherwise) and shuts it down.
They could have added an interface to let you select which one, but that would be extra work on their part, extra work on your part, and then it would still not handle the cases where the node fails because the hardware it was currently running on failed or when it fails because a bug causes it to crash. So they just keep it simple and tell you to deal with any node shutting down anytime, because you should be able to anyway and transforming any problem to that case just keeps things simpler.
I'm pretty sure it is a graceful shutdown in this case, where the application is signalled it is to be shut down, but as per usual Unix tradition, there is a hard limit.
In case of a Windows shutdown, a message usually gets sent to processes which could veto.
And the user will veto the veto. Or the system management whatever wanting to install updates will. And then the user will still blame you for writing crappy software that cannot handle reboots properly. There is also no way to veto a shutdown on Unix, only delay it, and Android also hard-kills apps, only notifying them when they are going off-screen.
Writing software so that it recovers from reboots and shutdowns well ends up making things easier, because then you can just deal with a lot of other problems by simply rebooting things.
So yeah, I consider that a honestly good idea.
-
@Bulb If you keep your state serialised (eg., in an SQLite DB) then you can resume trivially from a shutdown. Mobile apps have to work this way (they're not given any way to veto backgrounding or shutdown) but desktop apps ought to as well. They don't because of
 but that was always a poor habit to be in. It was obviously a bad thing 30 years ago though it was a lot more difficult to do continuous state checkpointing back then.
but that was always a poor habit to be in. It was obviously a bad thing 30 years ago though it was a lot more difficult to do continuous state checkpointing back then.
-
@Bulb said in Azure bites:
the infrastructure will just pick one (at random or otherwise) and shuts it down
Cmon, that's the point I was talking about. Not hardware failure.
-
@BernieTheBernie Amazon AWS does the same thing with "Spot" instances (where you don't pay to reserve CPU time). It's cheaper because you're only using processors that aren't being used otherwise, but:
Demand for Spot Instances can vary significantly from moment to moment, and the availability of Spot Instances can also vary significantly depending on how many unused EC2 instances are available. It is always possible that your Spot Instance might be interrupted. Therefore, you must ensure that your application is prepared for a Spot Instance interruption.
...
Data on instance store volumes is lost when the instance is stopped or terminated. Back up any important data on instance store volumes to a more persistent storage, such as Amazon S3, Amazon EBS, or Amazon DynamoDB.
-
@Watson said in Azure bites:
@BernieTheBernie Amazon AWS does the same thing with "Spot" instances (where you don't pay to reserve CPU time).
Amazon AWS does with “Spot” instances the same thing that Azure does with its “Spot” instances. This is something completely different. The talk was about scaling down. When you configure automatic scaling, well, then instances will get automatically shut down when the load decreases. You are explicitly asking for it to happen.
-
@BernieTheBernie said in Azure bites:
@Bulb said in Azure bites:
the infrastructure will just pick one (at random or otherwise) and shuts it down
Cmon, that's the point I was talking about. Not hardware failure.
And I addressed that point. If you wanted to pick, then you'd have to have additional logic to say which one should be picked, the infrastructure would have to have additional interface through which you'd tell it, and then if the instance shut down for a reason where you can't choose, you'd have to handle it anyway. So you have to handle any of the instances (it's horizontal scaling, so we are talking about instances that are equal except for the hostname and host id) shutting down and then don't have to bother with picking.
-
@dkf said in Azure bites:
@Bulb If you keep your state serialised (eg., in an SQLite DB) then you can resume trivially from a shutdown. Mobile apps have to work this way (they're not given any way to veto backgrounding or shutdown) but desktop apps ought to as well.
Yes. I know, and consider it a good thing Android did it that way.
@dkf said in Azure bites:
They don't because of
but that was always a poor habit to be in. It was obviously a bad thing 30 years ago though it was a lot more difficult to do continuous state checkpointing back then.And yet, ViM has had it 30 years ago just fine. It does it by keeping the important state in an mmapped file called “swap file” so kernel keeps writing it out behind the scenes.
-
Oh yes, totally different.
I imagine our Bright Future where everything is cloud managed. So, while I sit on the toilet and do a large dump, suddenly

 BEEP! This stall will shut down in 5 seconds!
BEEP! This stall will shut down in 5 seconds!
And now I have to jump up, pull up my pants and trousers, leave the stall, and move to the next free one. And hope I can continue and finish my business there, though a cliffhanger may have caused some extra dirt, and thus require extra postprocessing.
Our wunderful world.
Yes, I know the IoS thread is
 .
.
-
@BernieTheBernie said in Azure bites:
This stall will shut down in 5 seconds!
Why would it do that? It's in use!
And it kinda works the same in the cloud. You can have services that won't just shut down randomly unless the system underneath them has failed, which can of course still happen.
Automatically scaled instances are not that thing though. It's not like they can have much of an important state anyway, because the HTTP protocol is stateless, so if you have an auto-scaled set of services, the client might suddenly come to a different instance with the next request.
-
Oh what a
 ery is this thread!
ery is this thread!
So when a container instance is the leader, it is incative? The "leader" task may hardly need any ressources (depending on the concrete task), but it is active. And Azure decides to shut that active instance down.But this example shows a totally different issue of theory and practice of
CloudoTopia: in theory, all instances of a container are equal. They are created equal, and they stay equal for all over their lifetime. Never does anyone of them become more equaller (the Animals Farm thread is ).
but with "leader election", exactly thatBad Thing happens: one of the instances becomes more equal.
-
And there are many more reasons for why Azure may shut down an instance. Not only hardware failure, or scaling in. They may decide that the hardware the current instance is running on is hardly used and can be shutdown (saves energy, i.e. money). So spin up a new instance elsewhere, and shut this one down. And what ever else.
What I do complain about is the selection of an
active non-idle instancewhen instead anidle instancecould be selected for shutdown (oh yay, that does obviously not work inc ase of hardware failure, yes!).
-
@BernieTheBernie said in Azure bites:
But this example shows a totally different issue of theory and practice of
CloudoTopia: in theory, all instances of a container are equal. They are created equal, and they stay equal for all over their lifetime. Never does anyone of them become more equaller (the Animals Farm thread is ).
but with "leader election", exactly thatBad Thing happens: one of the instances becomes more equal.With the leader election, the processes REMAIN EXACTLY EQUAL except one gets some number that means when it confirms a transaction, it can be shown that all of them did. When it goes away, some other process' number will become the special one, and the leader election algorithm is to find out which one it is.
Leader election is basically a technical detail of some distributed algorithms. They are still distributed algorithms, meaning they are explicitly designed to tolerate nodes shutting down randomly.
Microsoft poorly explaining what they are talking about … yeah, Microsoft documentation is as crap as it's always been. But there is no wrong behavior here. Just poor documentation.
-
So I just spent two days trying to find out how to configure Prometheus for Azure Kubernetes.
- There is a new configuration option that is “recommended”. Instead of “log analytics workspace”, where the logs go, this needs a “azure monitor workspace”, also known as “monitor account”.
- Turning it on creates a poorly documented “data collection rule” and some even more poorly documented example (turned off by default) “prometheus rules”.
- So I turned it on, imported the created objects in the IasC and went to look how I view the metrics.
- I couldn't quickly find the metrics. And everything kept pointing to Grafana (I didn't enable that) as TheWay™ to view them. Stuff it up your ass please, I don't want a mix of two tools for monitoring.
- But the documentation also, in a later section, mentions sending prometheus metrics into the “log analytics workspace” alongside the logs. I already know how to work with that one, so I decided to give it a shot.
- So went through that guide and … the only option that I wanted in other then default position was collecting custom metrics exposed by my own workloads.
- And sure enough, the other instance (the production one—I have one instance for integration and two (soon to become) production in two different regions) does write in the table with the metrics, so

- (edit) I should note that this simpler solution does not actually involve prometheus per se—it works like prometheus, but scraping is done by the log collector (which is fluentbit under the hood) and the metrics are written into the logs database. Which might not be as well tuned to the purpose, but at least we don't have extra tools.
Yeah, I spent two days studying the “fancy” configuration just to find there is a “less fancy” one that almost works by default and with throwing of one switch completely works.
-
@Bulb said in Azure bites:
I don't want a mix of two tools for monitoring
 With the great advancements of microservices and cloud technology, you can use the technology most appropriate for the task you have to do, and of course, you can use a different tachnology for the next task.
With the great advancements of microservices and cloud technology, you can use the technology most appropriate for the task you have to do, and of course, you can use a different tachnology for the next task.
Wow!
-
@BernieTheBernie I don't mind using different technologies for different tasks. I like using different technologies. But this is only one task, so I don't want to use two technologies for it.
-
@Bulb You need to use three or more technologies for one task?
-
@dkf I try not to, but in this case Microsoft is “recommending” it. The case is monitoring, and they are telling me to use one tool, the one they have had for quite a while now, for logs, but they started recommending a separate tool for metrics. But the log analytics can work with metrics just fine, so the separate tool is mostly superfluous.
-
@Bulb said in Azure bites:
the separate tool is mostly superfluous.
Not to their telemetry gathering.
-
Currently, I get some training in Azure technologies. It's
 . Because I can collect some real world Azure experience.
. Because I can collect some real world Azure experience.
E.g. create 2 virtual machines in the Azure portal. What does the web tool remember in the 2nd machine from the first machine?
Exactly: the user password. And only that. Not the user name - you have to type it again. And of course, you have to type the password again in the field for repeating the password.
But the password field proper was filled properly.
-
@BernieTheBernie last time I received some training in Azure technologies, I was fired a week later without notice.
-
Create a virtual network, and add 2 vms to it, and have them ping each other. Simple, isn't it?
So I started with creating the Virtual Network, and followed all instructions. Next, Virtual Machine 1. can't I select the virtual network just created and deployed in the network section of the machine? It cannot be found. What did I do wrong?
After the launch break, I decided to create a second virtual network. And then the first virtual machine, and voilà, there it was: I could only select the new virtual network now. Odd. And the same with the second virtual machine.
Later on, during the cleanup step, when I had to delete the resource group, I saw a hint: the first virtual network was on "East US", while everything else was on "East US 2".
That does make a difference, I guess.

-
@Gustav Won't happen to me.
-
@BernieTheBernie said in Azure bites:
I saw a hint: the first virtual network was on "East US", while everything else was on "East US 2"
The resource group has a default location for resources. But 9.3 times out of 10 the portal will give you some arbitrary value (IIRC East US, because it was the first or something) instead of the resource group default.
-
@BernieTheBernie said in Azure bites:
in the Azure portal
That's
 , actually. The portal is, for a lot of reasons, crap. Except you need it to substitute the missing documentation (the helicopter joke¹ is still true as ever).
, actually. The portal is, for a lot of reasons, crap. Except you need it to substitute the missing documentation (the helicopter joke¹ is still true as ever).To get reasonably clean set-up, you need to use the azure cli, the powershell commandlet, azure resource manager templates, terraform or pulumi. That will protect you from having inconsistent locations because the portal failed to fill in the correct default or because you clicked on the wrong item, give you a way to actually configure the resources consistently, provide place to write some documentation², and there is a couple of things that the portal does not even do, like linking certificates so they get updated when your rotate them (if you do it in portal, it looks all the same, but the certificate is copied rather than linked, so it won't get updated).
However, sometimes you will have no clue how to set the parameters in the template, because the documentation either does not describe them well enough, or the description is buried somewhere in the middle of a wall of text you've seen a dozen times already, so you'll have to set up the resource in the portal, then look up the ‘deployment’, copy it over to the template/terraform/pulumi script and rebuild it from there.
¹ Helicopter joke³: a guy is flying in a helicopter and suddenly a fog starts to fall and he's no longer sure where he is. He carefully flies forward when a high-rise office building appears out of the fog and there's someone sitting by an open window. So he flies as close as he can and shouts out: ‘hey, good man, where am I?’. ‘In a helicopter,’ responds the desk worker. The pilot turns the craft around and soon finds the airport. ‘How did you make it?’ fellow pilots ask him after landing. ‘Well, from the answer that was entirely correct, but utterly useless I figured it would be the Microsoft office…’
² There is no field for documentation on most resources (except role assignments), but most resources do have tags, so I suggest putting in some for who created the thing, when and why so you have something to go on when you wonder why the hell did you create this thing half a year from now.
³ I heard this joke some 25 years ago now. To this day it still accurately describes most Microsoft documentation (except the WinAPI one, that's actually decent).
-
@Bulb funny, that's the opposite of AWS, where doing things via the API or Cloudformation templates is a massive pain due to a bunch of things that don't play nice, but doing it via the console works... As long as you only have one set of things to set up. Any more and you're in for pain.
-
@Benjamin-Hall Unless you are a team of cowboys who tests in production, you always have multiple sets of things to set up – at which point you need to be using templates so you can update the production set the way you already tested on the integration set quickly and reliably.
-
@Benjamin-Hall I have no experience with AWS, but in Azure fortunately (and my understanding is that it wasn't from the start) the portal calls the API under the hood, and you can inspect what it did, so you can prototype in portal — sometimes things are quite complex over the API, but the portal already has templates for them — and then extract the templates and apply them to production with api, terraform or pulumi. And switch between the three to work around quirks as each has its share.
Overall it took me some time to learn to wield it, but terraform is really helpful in the long run, because you have somewhere written down what infrastructure you are actually supposed to have. And I might have gone with pulumi instead if I knew about it earlier. Though … I learned one has to resist the temptation to abstract things much with terraform, because they will end up not exactly uniform anyway, so maybe pulumi won't help that much.
-
@Bulb said in Azure bites:
To get reasonably clean set-up, you need to use the azure cli, the powershell commandlet,
Yes, I learned how (not) to use the azure powershell, too:
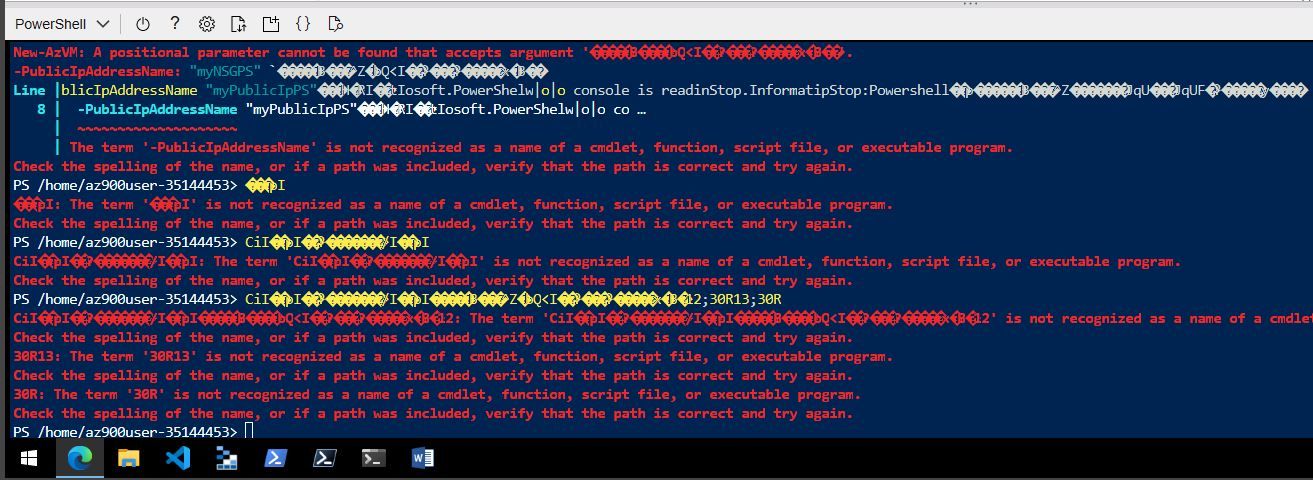
That looks ... interesting ...? ..., doesn't it?
-
Since Azure is a High Performance, High Availability platform, embrace
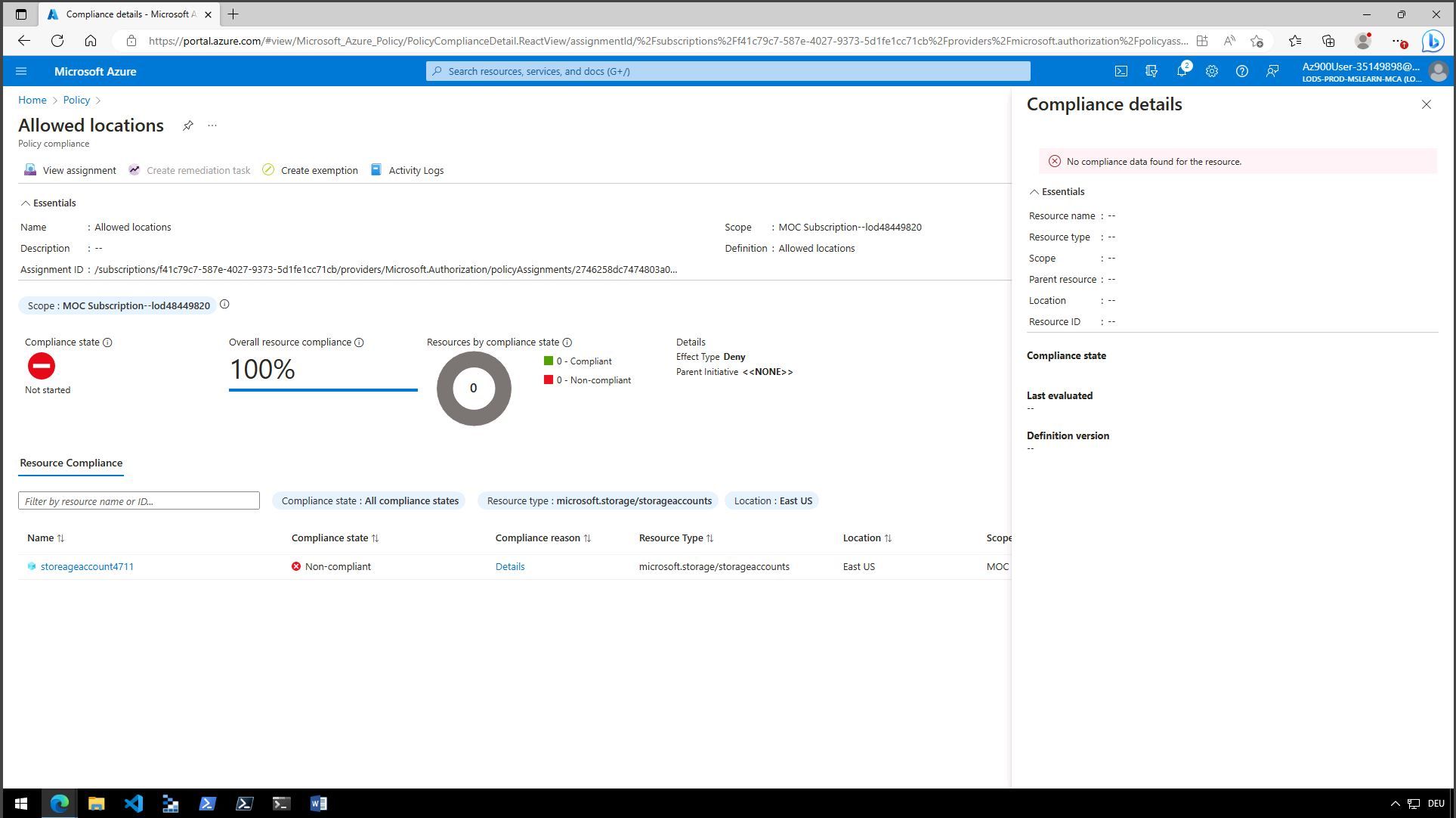
eventualfücked-up consistency.
A resource (storageaccount4711) was created, and afterwards, a policy was created for allowed locations, which excluded the location used for the resource.
Eventually, Azure finds out that the resource does not comply with the policy, but when you query details, it fails to tell you what you did wrong. And of course, there is a 100% compliance rate, though a non-compliant resource is listed...
-
@BernieTheBernie said in Azure bites:
I learned how (not) to use the azure powershell
I sort of included it for completeness. Every time I tried to use powershell I ran into it being a sack of quirks.
-
@BernieTheBernie Microsoft has fully embraced the
 –
– mentality with Azure.
mentality with Azure.
-
Next step: prepare for the AZ-900 examination.



My training provider sent me a large pdf document with exam questions and answers. Some parts translated to german, most not. A real funny hodgepodge. Sometimes, things were translated which Microsoft does not translate on their web page, like names of support plans...In some cases, the answers did not look correct to me. And eventually, I looked things up in the internetz.
E.g. for a question discussed on
my answer was Yes-Yes-No as suggested there, but in my training document it was Yes-No-Yes.
Then there are examples where you can find different ideas in the internetz. E.g. for
first part...
The
thing is that you often have to extremely legalesely interprete the question and find a weird answer which is  . But unfortunately, there is no really authoritative source (like a law or a contract) where to read up the definitions, e.g. for differentiating between IaaS, PaaS, SaaS (but several examples only) ...
. But unfortunately, there is no really authoritative source (like a law or a contract) where to read up the definitions, e.g. for differentiating between IaaS, PaaS, SaaS (but several examples only) ...Important: always look out for words limiting the answer like
only("you can use only method Y for purpose X") - the answer then is "NO" when you could also use method Z to achieve X...And more wrong answers. With composite SLAs, you won't take the minimum of a service, but you have to multiply all the SLAs.
Sometimes you have to memorize rather meaningless numbers. How many 9s for a VM SLA? And when you have 2 VMs in 2 availability zones?
So eventually they sent me an access code to cert2brain web site, where I can check my knowledge in English.
That looks much better to me. But not completely, of course.
E.g. there was a question about a support plan with phone support. And their solution was a plan I had never heard of - because it does no more exist.
Some of the questions involve 3 parts which can each be answered with Yes or No. How many combinations? They offer 6 only, but upto now the correct combination was always listed...
Azure documentation is great and useful.
Except when it isn't.
-
@BernieTheBernie said in Azure bites:
prepare for the AZ-900 examination
All that for what is a fancy marketing material to make sure you'll use their most expensive option to build your solution on.
@BernieTheBernie said in Azure bites:
Azure documentation is great and useful.
Azure documentation is … well it for sure is, but usually it tells you the same thing that was already obvious twelve times and good luck noticing that one important sentence that actually tells you the important caveat.
-
@BernieTheBernie said in Azure bites:
But unfortunately, there is no really authoritative source (like a law or a contract) where to read up the definitions, e.g. for differentiating between IaaS, PaaS, SaaS (but several examples only) ...
IaaS: VM runners, virtual disks. Commody stuff these days. Thin profit margins for big hosting companies.
SaaS: Run programs over the Internet!!! For money...
PaaS: Middleware crud that sits on IaaS and below SaaS. Aimed at getting massive lock-in on what ought to be commoditised.
-
@dkf Storage is IaaS.
Azure Files - simply put: a file share on Azure (instead of on a machine in your local network) - is ... what?
IaaS because it's storage?
PaaS because you do not need to care for the OS?
SaaS because also the file sharing software is managed by Azure?
...
-
@BernieTheBernie If you can't RDP or SSH into the resource, it's not IaaS.
(Under a
 ic reading that would exclude VM disks/NICs too, but I need to get back to work so I can't come up with a better definition right this second.)
ic reading that would exclude VM disks/NICs too, but I need to get back to work so I can't come up with a better definition right this second.)If it doesn't run in your browser, it's not SaaS.
Therefore, storage accounts are PaaS.
-
@Unperverted-Vixen IaaS is simple virtualised hardware; for storage, it means you can mount it on your VM. SaaS is apps-running-in-the-browser tier stuff; many many examples of it as it is often the most user-facing form. PaaS is everything in between; abstractions of servers behind load balancers and so on, all designed to be something that someone puts a SaaS offering on top of. PaaS is selling shovels to miners in a gold rush, except with much much more vendor lock-in.
-
Some questions come with variations, and of course, the variations are highly consistent.
Version 1:
An administrator wants to manage virtual machines. He has 3 computers from where to perform that task:
I. Windows 10
II. MacOS
III. Linux
Which tools can he use in each case?
A. Azure CLI and Azur Portal
B. Azure Portal and Azure Powershell
C. Azure Powershell, Aure Portal, and Azure CLIIn this case, the correct answer is always C for any type of computer, as there are ports of Azure CLI and Azure Powershell available for Mac and Linux.
Version 2:
An administrator wants to manage virtual machines with a Powershell script. He has 3 computers from where to perform that task:
A. Windows 10
B. MacOS Mojito with Powershell 42.7 (rookie number - CRS)
C. Linux with Azure CLI
Which machines can he use?In this case, the correct answer is A and B only.
The is excluded. Because Azure CLI is not Powershell . And the question does not tell us anything about Powershell on that machine. And additionally installing that is out of question here.
is excluded. Because Azure CLI is not Powershell . And the question does not tell us anything about Powershell on that machine. And additionally installing that is out of question here.Yeah, that is easy, isn't it?
Or is variation 2 just the older version of the question, from an era when Powershell on Linux was not yet available? And the outdated question still in the training catalogue (see above regarding Premier support)?
But IIRC it became available in 2016...
-
 matters.
matters.
You can start your journey into Azure services with a free account. It comes with a spending limit, and one that money has been used up, that's it - your VMs just won't start, you have read-access only to your data, etc.But the free account ends somewhen. And now you can use "pay-as-you-go".
What about your spending safety there?
You can create a "budget alert". When your spending is over the alert limit, an alert is sent to you.
But does it actually limit your spending?
No. Of course not.
It is upto you to react quickly and stop all things you think you can stop to limit your costs.
Azure won't do anything automatically for you.
If you have bad luck, you may burn all your resources and beyond within shortest time...
Why does Azure not prevent that?
Well, why should they?
You do provide for them!
for them!
-
@BernieTheBernie they learned it from AWS.
-
@Arantor At least Azure lets you enumerate all the resources in the subscription so you can see what’s costing you money. AWS won’t do that.
-
@Arantor No experience at all with AWS, or the Google Cloudz...
-
@BernieTheBernie you’re not really missing much. Everything I’ve seen of Azure smells to me like MS trying to do a Redmond-flavoured budget knock-off of AWS. But bless those guys at that tiny startup, they’re trying so hard.
-
@Arantor At the infrastructure level, the only weird things about Azure are that they block ping (ICMP ECHO) and time out idle connections after a while.
-
@dkf that and if you give blob storage the wrong credentials it often presents as a DNS failure rather than a wrong credentials error. Except that a real DNS failure (tenant not existing) behaves ever so slightly different. Meaning that the “security” benefit is superficial at best.
-
Actually not an
Azure Bitesproper, but an AZ-900 exam question:You are tasked with deploying Azure virtual machines for your company.
You need to make use of the appropriate cloud deployment solution.
Solution: You should make use of Software as a Service (SaaS).
Does this meet the goal?
Your answer: Yes No
Yes NoWhat a fucking stupid question!
Nowhere during the process of deploying a virtual machine, I'll be asked if I want to use IaaS / PaaS / SaaS / serverless / FotM / FotD or whatever thingy. I just deploy my vm. That's it.
And also the version where it says IaaS in the Solution part is actually wrong: though I make use of IaaS, nowhere in the fucking process I need to select that.