Azure bites
-
@BernieTheBernie They seem to be obsessed with the BaaS buzzword termitology. Why the fuck should I care whether I'm using a CaaS or SaaS, what I actually care about is what specific service it is.
… and I suppose they are not even using it consistently with the actual system, because a resource of type “SaaS” represents a subscription to a 3rd-party service ordered through the marketplace.
-
Yesterday one of our deployment builds broke.
It was looking up a storage account by this query:
az resource list --resource-type Microsoft.Storage/storageAccounts | jq -r '.[] | select(.tags.environment == "%environment.suffix%") | .name'``%environment.suffix%` gets replaced by the name of one of the many test environments we have. For most resources that suffix is simply part of the resource name, making everything simpler, but storage account names are too limited, so we have to resort to abbreviated names and looking them up by tag.
Well, this time the resource was not being found, though it clearly existed and could be seen in portal.
 1: Apparently the
1: Apparently the az resource listhas a limit on how many items it will return—that does not seem to be mentioned anywhere in the help—and we have too many now.So I checked the help and it also allows filtering by the tag directly. But if you think
az resource list --resource-type Microsoft.Storage/storageAccounts --tag environment=%environment.suffix%is going to work, you are naîve. It will say those two parameters can't be used together. So I tried doing the filtering the other way:az resource list --tag environment="%environment.suffix%" | jq -r '.[] | select(.type == "Microsoft.Storage/storageAccounts") | .name'And still got an error:
ERROR: you cannot use '--tag' with '--resource-group'(If the default value for resource group is set, please use 'az configure --defaults group=""' command to clear it first)
Oh, our old friend default parameters.
2: You can set the default resource group, but then it gets implicitly passed to all commands and any command that shouldn't have it will error out instead of simply ignoring the default.I had to resort to this:
az graph query -q 'where type == "microsoft.storage/storageaccounts" and tags.environment == "%environment.suffix%" | project name' | jq -r '.data[0].name'but that also required prepending it with
az extension add --upgrade -n resource-graphbecause some commands are not installed as part of the command-line tool, but have to be added separately. Because
 I guess.
I guess.It's good that you can do such query, but it would be better if the list command worked and you didn't have to jump through this unobvious hoop.
Side
: I accidentally fixed just that one build and not the others using the same logic, because when you edit a build step that is defined by a template, TeamCity overrides it for the specific build without any warning, just the gray note “(Inherited from Some Project / Deployment / Bflm / Psvz template)” gains an “, overridden” appendix. Very conspicuous indeed.
-
And at nearly the same time I got another problem report, for the other project. A logic app was failing. It's a trivial logic app. It just acts as a webhook for some API and pushes the message into a queue.
I am creating the “api connection” object with terraform (resource "azurerm_api_connection"). It takes a secret key as a parameter, which terraform usefully obtains from the storage account and it can be easily substituted. So far so good.
1: However the terraform provider does not handle the fact that the key, being a secret, is not returned back from the API, and wants to overwrite it each time. The documentation even says:ⓘ Note:
The Azure API doesn't return sensitive parameters in the API response which can lead to a diff, as such you may need to use Terraform's ignore_changes functionality on this field as shown in the Example Usage above.
So I ignored the changes. But that means it won't be updated even if the key does change. And it appeared to have changed. So I had to find the other workaround: You can create a resource "terraform_data" that just remembers a value, so you can trigger change with a lifecycle.replace_triggered_by meta-property. Of course I promptly hit the bigger
2: After recreating the connection, the logic app couldn't even find it with an error like:"Error from token exchange: The connection (logic-apis-northeurope/azurequeues/<random number>) is not found. Please create new connection and change your application to use the new connection."
Wait, wat, the connection has some ID that does not contain that random number anywhere and the identifier in that form is never given to the logic app. If it was, terraform would have updated it properly.
Hm, but what do I do to make the Thing™ re-read the properties and fish out the new number when the parameter is the resource manager ID of the connection that did not change.
Unfortunately I don't know how to trigger writing the API even though nothing has changed, and obviously the JSON blob passed in is documented (right? well, maybe somewhere in the mess of a documentation), so I wasn't sure whether I could add something that would be preserved without actually changing anything. So I resorted to re-creating the step that uses the connection.
Except (I'm not sure this is a
, because the needing to poke it is a ) I can't re-create the middle step without also re-creating all the steps that follow. Fortunately they are terraformed, so it just means a chain of lifecycle.replace_triggered_by attributes. Ugly as fuck, but it seems to work.Also I looked what caused the change, there is some limited capability to do that with the graph query mentioned above, but it does not seem to say who or what triggered it.
-
@Bulb said in Azure bites:
They seem to be obsessed with the BaaS buzzword termitology.
Not sure if you mixed up Termites and Ants here

 , but
, but
those XaaS things just describe the basic concepts of services provided by the cloudz, and someone dealing with the cloudz schould understand those concepts.
They do create just silly questions around these words.("Your company decided that PaaS must be used ..." - another such bullshit part of a question, and then an IaaS solution is provided and you have to say NO!, though the actual requirement would be well fulfilled.)
-
@BernieTheBernie PaaS == $$$$$aaS
-
@dkf Is it? Is a Docker container or Web App moar expensive than a virtual machine where you install your crap?
On the other hand, also databases are PaaS. Among the exam questions, there is one asking if you can save money by shutting down an Azure SQL Server instance when you do not need it... Answer: No. You pay full for it, even when it does temporarily not run.
Well, it is an example of pay-as-you-go, isn't it?

-
@BernieTheBernie said in Azure bites:
those XaaS things just describe the basic concepts of services provided by the cloudz, and someone dealing with the cloudz schould understand those concepts.
I don't agree. I think the distinction is, at this level, completely inconsequential. Knowing that both database server and event hub are platform while a vnet is infrastructure does not really tell me anything useful. I still need to know benefits of renting a database server compared to setting it up myself, and I need to know that for the event hub and the reasons for renting or setting up each may be different (they are in our current project).
("Your company decided that PaaS must be used ..." - another such bullshit part of a question, and then an IaaS solution is provided and you have to say NO!, though the actual requirement would be well fulfilled.)
This just shows that the terms can be actually harmful. Because I can totally imagine some
 to get sold on PaaS and insist on using it even when it's a bad fit. It should be balanced by useful use of them. I can't think of any.
to get sold on PaaS and insist on using it even when it's a bad fit. It should be balanced by useful use of them. I can't think of any.
-
@Bulb said in Azure bites:
Because I can totally imagine some to get sold on PaaS and insist on using it
In such a case, you can upload your VMs to Azure, setup some Azure functions ("serverless"), and tell
that all is PaaS - he won't know the differences, and you used the correct buzz word.

-
@BernieTheBernie Sure. Still didn't make the buzzwords useful though.
… I suppose they exist so the
snake oilAzure salesmen can sound more profound.
-
@Bulb said in Azure bites:
@BernieTheBernie Sure. Still didn't make the buzzwords useful though.
In reality there isn't a clear line separating them. Infrastructure is just a lower level Platform, and Software can grow to look mightily Platform-like...
-
@dkf Indeed. Which is another reason having test question about them is dumb.
-
This monday, course AZ-204 developing solutions in azure started. What the fun did I have when I started the first "lab" today (i.e. there you can do some training work on real Azure, and get instructions).
Create an "Azure Logic App". That's a "serverless" thingy which reacts on triggers. First trigger: a blob storage trigger. I entered the text into the search box, and the desired item did not show up. But a newer version. OK, let me try that. On the next screen, several fields have to be filled, and they are provided in the instructions section. Well, for the previous version, not for the "V2" version...
Next trigger: SQL Server Item Added. Typed the text into the search box, and also here the desired item did not show up. Tried a different one, could fill the fields on the next screen, but then the creation of the item failed: could not connect to database.
Great experience.And a very valuable lesson: better do not base important things on Azure Logic Apps, as Microsoft just removes your triggers and adds new triggers which will soon be replaced either.
Lesson learned!
-
Though the first "lab" mentioned above failed successfully, further labs worked. Somehow, at least.
In one of them, I had to connect to a virtual machine. It runs Windows 10, not a very recent version of it. So first thing you have to do according to the instructions is open Internet Explorer (no, Edge is not there...), accept the standard settings, then allow downloads from anywhere.
Why?
Because in the next step you navigate to the Chrome download page, and install Chrome, and set Chrome as your standard browser.

-
@BernieTheBernie said in Azure bites:
Create an "Azure Logic App". That's a "serverless" thingy which reacts on triggers.
Worse, Logic App is the
 codeless thing. Where one connects boxes instead of writing code. Looks simple, becomes unmaintainable somewhere around 5 boxes.
codeless thing. Where one connects boxes instead of writing code. Looks simple, becomes unmaintainable somewhere around 5 boxes.We use them for some purposes. Mainly because they have connectors to Office365 bits, making good adapter for things like sending e-mail or extracting data that someone fills in an Excel template and uploads to Sharepoint. But it's usually just an adapter so we don't have to find and integrate libraries for doing it directly from the code of the main app. They are not suitable for actual logic.
@BernieTheBernie said in Azure bites:
And a very valuable lesson: better do not base important things on Azure Logic Apps, as Microsoft just removes your triggers and adds new triggers which will soon be replaced either.
That's a general problem of all the higher-level services: the APIs get replaced, deprecated and removed and you can't keep running an older version and just have to upgrade your code.
In this case, though, I bet the older versions are still there, and you could still construct them over the resource manager API, just the portal only offers the latest version, because beaver.
My latest adventure with logic apps is this:
In this app we have a small logic app that just takes a message via a webhook and drops it into a storage queue. Because the service calling the webhook doesn't have good retry policy (or has too scarily worded documentation; didn't look myself), so we want to pick the request even if our app is down.
Well, but the app stopped working. At the moment I was fixing it, it wasn't working because something—or someone—triggered regeneration of the API key for the destination storage account and the logic app was getting a 403 error.
In the portal I could go in and fill in the connection again. Things started working.
But the app is terraformed. Because we need to keep the dev, test and prod environments in sync, and because the portal is crap anyway.
So I told terraform to rebuild the “connection”, the object that holds the queue name and the API key for it. And the logic app stopped working again, saying it can't find the connection! Because for some reason it internally links to some magic ID of the connection that is not the resource ID it gets as a parameter.
Fixing it in portal was easy-ish again, but how the F do I tell terraform to fix it next time I'll need to do it? The parameters didn't change, so terraform won't try to set them again, and I can't force re-configuring of resources in it, just re-creating them.
So I told it to re-create the queue message step (fortunately each step is a separate resource). But I can't re-create just the middle step, because the request to remove it will fail. I had to trigger re-creation of that step, and all the (only one, fortunately) step after it.
The whole thing is also ugly, because terraform only knows about the overall shape of the logic app resource, but the steps are given as JSON fragments you basically have to design in the portal, then extract from the API.
-
@BernieTheBernie said in Azure bites:
In one of them, I had to connect to a virtual machine. It runs Windows 10, not a very recent version of it. So first thing you have to do according to the instructions is open Internet Explorer (no, Edge is not there...), accept the standard settings, then allow downloads from anywhere.
Yeah, Microsoft is a small startup company, they don't have the personpower to update their lectures as often.
Why?
Because in the next step you navigate to the Chrome download page, and install Chrome, and set Chrome as your standard browser.As if running browser on a server was ever a good idea. Sane people have an install script they run on the VM to install the service the VM is supposed to provide and then only log in if they need to diagnose it.
Which reminds me, if you run a powershell script in a VM as a custom startup script, and want to download resources using
Invoke-WebRequestin it (which you need to use even for blob storage, because only file storage can be mounted and most other things use blob storage), you have to use-UseBasicParsingparameter, because otherwise the commandlet fails since something in Internet Explorer wasn't initialized yet.What makes it
 to debug is that when you first log in, the initial question you get will get it initialized and your script works just fine. And finding the logs from the run during first boot is also quite —as usual, several different places with different parts of the information exist.
to debug is that when you first log in, the initial question you get will get it initialized and your script works just fine. And finding the logs from the run during first boot is also quite —as usual, several different places with different parts of the information exist.
-
@Bulb said in Azure bites:
something in Internet Explorer wasn't initialized yet
Deferred initialization. A famous Microsoft pattern.
When you learn about Functional Programming, you learn thatenumerablesare either empty or have values - and are nevernull. With Microsoft, it is different: they are null or have values, but are not empty. Think of theInvocationListofEventHandlers.
I was badly struck with that when I used aDictionary<TKey, TValue>in a multithreaded context. Yes, I know, it is not thread safe. But so what? Missing an item or getting an item fücked up, was not at all critical. Only the exception I sometimes received at startup was...
Turned out that the dictionary contains 2 arrays,TKey[]andT[Value], and both arenullwhen the constructor has finished. When you add an item, TKey[] gets checked for null, and if it is null, it gets created, and then also TValue gets created without having ever been checked for null.
Now imagine that TKey[] has just been created, but not yet TValue[] when the second call toAddhappens...
That was
-
@BernieTheBernie Simultaneous read is probably safe, but simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
-
@PleegWat said in Azure bites:
simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
I think he learned that.
-
@PleegWat said in Azure bites:
@BernieTheBernie Simultaneous read is probably safe, but simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
It's a bit better in C# and Java than in C++. C# and Java always do some operations atomically to remain memory-safe even in presence of data races, so you can get weird exceptions, but not completely random data. In contrast C++ doesn't care and random data is precisely what you'll usually get.
-
@Bulb said in Azure bites:
It's a bit better in C# and Java than in C++. C# and Java always do some operations atomically to remain memory-safe even in presence of data races, so you can get weird exceptions, but not completely random data. In contrast C++ doesn't care and random data is precisely what you'll usually get.
In particular, both C# and Java try very hard to never give you a reference to anything that isn't a proper referenceable object. C++ is more... relaxed about such concerns for the most part. You won't get a half-n-half very often as alignment and memory models usually save you, but pinning down that it can't happen is difficult.
-
@dkf There's always plain old uninitialized memory in C++. And I'm pretty sure inconsistent multiply-linked lists can pop up in C#/Java as well.
-
@PleegWat I don't think you ever get a reference off into never-never land.
-
@dkf said in Azure bites:
You won't get a half-n-half very often as alignment and memory models usually save you, but pinning down that it can't happen is difficult.
On x86 and x86-64 the memory model saves you from getting half-n-half. On other architectures it may not.
@PleegWat I don't think you ever get a reference off into never-never land.
Even if you are on a platform where you can't get the values mixed up, in C++ you can get pointer to released memory if one thread thinks it removed the element and deletes it while the other thinks the element is still current and writes the pointer somewhere else.
You can't get that in C# or Java, because as long as there is something that looks like a pointer to that chunk, it won't be released.
Colleague recently triggered similar race condition in C#. He was occasionally getting null when taking elements out of a collection (without properly locking it) though the collection never contained any nulls.
-
@Bulb said in Azure bites:
@dkf said in Azure bites:
You won't get a half-n-half very often as alignment and memory models usually save you, but pinning down that it can't happen is difficult.
On x86 and x86-64 the memory model saves you from getting half-n-half. On other architectures it may not.
Only really true if you don't split the reference itself across cache lines. (64-bit values usually have only 32-bit alignment constraints.) If you satisfy the alignment constraints, then ARM will give you an all-or-nothing op as well (though when other CPU cores notice it is complex, so this isn't enough for a synchronisation primitive). If you need to really care, use the atomic ops; the implementations of those handle the gnarly bits.
-
@Bulb said in Azure bites:
@PleegWat said in Azure bites:
@BernieTheBernie Simultaneous read is probably safe, but simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
It's a bit better in C# and Java than in C++. C# and Java always do some operations atomically to remain memory-safe even in presence of data races, so you can get weird exceptions, but not completely random data. In contrast C++ doesn't care and random data is precisely what you'll usually get.
I would be careful with these statements.
In Java, using HashMap from different threads without any synchronization/locking can result in an infinite loop.
(This is no longer true in recent JREs, but the older ones are still used, so be careful).
-
@Kamil-Podlesak said in Azure bites:
In Java, using HashMap from different threads without any synchronization/locking can result in an infinite loop.
Something which explicitly says it is not thread safe turns out not to be thread safe?

-
@Kamil-Podlesak said in Azure bites:
@Bulb said in Azure bites:
@PleegWat said in Azure bites:
@BernieTheBernie Simultaneous read is probably safe, but simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
It's a bit better in C# and Java than in C++. C# and Java always do some operations atomically to remain memory-safe even in presence of data races, so you can get weird exceptions, but not completely random data. In contrast C++ doesn't care and random data is precisely what you'll usually get.
I would be careful with these statements.
In Java, using HashMap from different threads without any synchronization/locking can result in an infinite loop.
Infinite loop isn't memory-unsafe.
-
@Bulb said in Azure bites:
Infinite loop isn't memory-unsafe.
 but fuck up in this way and you'll still end up in trouble when the root cause analysis is done.
but fuck up in this way and you'll still end up in trouble when the root cause analysis is done.
-
@Bulb said in Azure bites:
@Kamil-Podlesak said in Azure bites:
@Bulb said in Azure bites:
@PleegWat said in Azure bites:
@BernieTheBernie Simultaneous read is probably safe, but simultaneous write on a non-thread-safe structure can result in way worse than a single missing or corrupt value.
It's a bit better in C# and Java than in C++. C# and Java always do some operations atomically to remain memory-safe even in presence of data races, so you can get weird exceptions, but not completely random data. In contrast C++ doesn't care and random data is precisely what you'll usually get.
I would be careful with these statements.
In Java, using HashMap from different threads without any synchronization/locking can result in an infinite loop.
Infinite loop isn't memory-unsafe.
And I never claimed otherwise.
-
@PleegWat, no, you did not.
But @Kamil-Podlesak said:
I would be careful with these statements
where the statement from me just above was
C# and Java always do some operations atomically to remain memory-safe even in presence of data races
-
@Bulb said in Azure bites:
@PleegWat, no, you did not.
But @Kamil-Podlesak said:
I would be careful with these statements
where the statement from me just above was
C# and Java always do some operations atomically to remain memory-safe even in presence of data races
 Ok, I suppose the content of the memory is remains fine, but from the perspective of the whole application/process, being stuck in an infinite loop is pretty bad. So, unless the C++ makes the memory to explode in a cloud of radioactive asbestos, I am going to rate both "unsafe".
Ok, I suppose the content of the memory is remains fine, but from the perspective of the whole application/process, being stuck in an infinite loop is pretty bad. So, unless the C++ makes the memory to explode in a cloud of radioactive asbestos, I am going to rate both "unsafe".
-
@Kamil-Podlesak I thought you in particular know that the term memory-safe has fairly precise definition now and also why.
@Kamil-Podlesak said in Azure bites:
So, unless the C++ makes the memory to explode in a cloud of radioactive asbestos
It probably won't make it explode, but it might end up executing pretty random stuff, possibly under control of an adversary. Just locking up in an endless loop won't do that.
Also the endless loop still occurs in the operation, so it's still relatively easy to debug. Memory safety violations often make the application crash some time later in completely unrelated function in a place where the crash is inconsistent with what is written in the code. It's much, much, harder to debug.
-
@Bulb said in Azure bites:
Memory safety violations often make the application crash some time later in completely unrelated function in a place where the crash is inconsistent with what is written in the code. It's much, much, harder to debug.
Some are easier to debug than others. Use-after-free is actually relatively straight-forward, whereas array-bounds-overrun can be trickier (or at least a lot more intrusive, in part because some uses of memory are damn tricky in the first place). I tend to think that array bounds ought to be automatically checked (with the compiler able to remove the check when it can prove that things are well-behaved) but that's quite tricky to do in general. I've even written code for which that checking would be difficult; memory allocators don't just magically exist without someone writing them...
Stacks are, curiously, harder to validate than heaps.
-
@Kamil-Podlesak said in Azure bites:
@Bulb said in Azure bites:
@PleegWat, no, you did not.
But @Kamil-Podlesak said:
I would be careful with these statements
where the statement from me just above was
C# and Java always do some operations atomically to remain memory-safe even in presence of data races
Ok, I suppose the content of the memory is remains fine, but from the perspective of the whole application/process, being stuck in an infinite loop is pretty bad. So, unless the C++ makes the memory to explode in a cloud of radioactive asbestos, I am going to rate both "unsafe".It's still a denial of service, but if you're treating actual garbage data as a valid pointer then while you commonly get a segfault, you may also get information leaks or even arbitrary code execution.
-
$ terraform plan ╷ │ Error: expected frequency to be one of ["PT1M" "PT5M" "PT15M" "PT30M" "PT1H"], got P1D │ │ with azurerm_monitor_metric_alert.sqljob-failed, │ on monitoring.tf line 194, in resource "azurerm_monitor_metric_alert" "sqljob-failed": │ 194: frequency = "P1D" │ ╵ ╷ │ Error: expected window_size to be one of ["PT1M" "PT5M" "PT15M" "PT30M" "PT1H" "PT6H" "PT12H" "P1D"], got P4D │ │ with azurerm_monitor_metric_alert.sqljob-failed, │ on monitoring.tf line 199, in resource "azurerm_monitor_metric_alert" "sqljob-failed": │ 199: window_size = "P4D" │ ╵So we have this SQL Elastic Job agent in our project that takes care of running some daily clean-up routine to drop old data. So
- It only runs once a day, checking whether it failed more than once a day is pointless.
- Things randomly failing is a fact of The Cloud. And any software, really. And nobody cares if it fails once, because it will just drop the data next time around. But we better get notified if it keeps failing all the time.
So of course I wanted to set up an alert that would check whether it failed three time in four days. But no, I can't have a longer window than 1 day.
-
Can you really have two
topics with the same name in an Azure Service Bus? This test question seems to imply that:
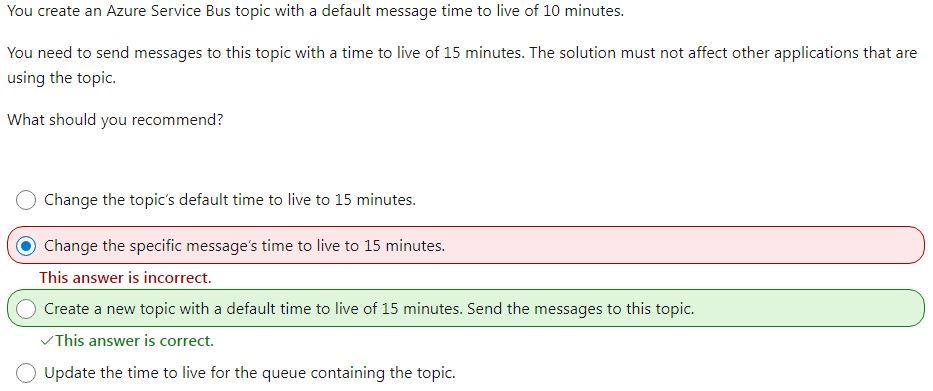
But the instructions say that I have to send messages to "this topic" where TTL was set to 10 minutes...
-
-
@BernieTheBernie said in Azure bites:
Azure Service Bus
… on this project, colleagues concludes that it ain't no good and we are using RabbitMQ we deploy into kubernetes ourselves.
-
@Applied-Mediocrity Are you sure that little sucker can hold upto 80 GB of data? And what's its time to live?
-
@BernieTheBernie said in Azure bites:
Are you sure that little sucker can hold upto 80 GB of data?
Easily. See also: AWS Snowmobile.
And what's its time to live?
Aah, well, your messages will have expired before it even arrives, thus releasing you from the burden to actually send anything

-
I just finished the "lab" with the title "provision an azure cognitive search service". My feedback at the end was:
Azure Search has again been renamed: Azure AI Search. And of course, many things look different. Somehow I could figure several things out, but queries always failed.
Important lesson learned: with such unreliability, I will not use it in production.
-
@BernieTheBernie It will probably be renamed to Bing Chat Search or Azure Copilot Search or some shit like that in a few weeks.
-
@dkf has the Azure business been infected by the MSDN brain measles where things get renamed weekly?
-
As of today, switching tenants in Azure portal seems to only work on second, maybe sometimes third, attempt!
… when you have multiple Entra tenants, you have to switch between them by clicking the
 icon in the upper right and selecting the tenant you want to use. As of today you select, the screen flashes wildly a dozen or two times as it redirects through login.microsoft.com trying to get hold of the token for the selected domain, and comes back to the initial tenant. Only if you try again will it flash a half dozen more times and end up in the state it was supposed to.
icon in the upper right and selecting the tenant you want to use. As of today you select, the screen flashes wildly a dozen or two times as it redirects through login.microsoft.com trying to get hold of the token for the selected domain, and comes back to the initial tenant. Only if you try again will it flash a half dozen more times and end up in the state it was supposed to.Long live
 –
– mentality.
mentality.
-
@Arantor said in Azure bites:
@dkf has the Azure business been infected by the MSDN brain measles where things get renamed weekly?
All of Microsoft is has had that for a long time, so why should Azure be any exception.
-
@Bulb they don’t rename everything regularly. Though even their core franchises are heading that way - Office becoming part of Office 365 then Microsoft 365. I’m waiting for them to announce Office Live, to merge those brands together.
-
@Arantor There is no regularity to the renaming, but they are renaming things all over the place.
-
@Bulb I assume it must be the Redmondian equivalent of the Google mentality. In Google you have to ship something to get a promotion, in MS I guess you have to rebrand and relaunch something for the same.
-
@Arantor Microsoft has a very big marketing department, probably way bigger than Google, and this is their way of leaving a trace on things.
-

