Deep Learning
-
I try to learn something new every now and then, and decided to look at "Deep Learning". I took a book with the title "Praxiseinstieg Deep Learning" from the library, and started to read it. WTF!
In the introductory chapter "What is deep learning" a "single layer perceptron" learns the Boolean AND. The author defines the input data:

There are 4 cases for the input data, so the outer array has 4 items. Every item is a tuple of an array consisting of the two input values and third value, and the expected result. The author tells us that that 3rd value is called "bias" but does not at all tell us what it is useful for. Great!Then he defines the "heaviside" function:
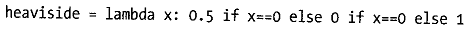
Ok, Python does things the odd way round. Return 0.5, then check if it was supposed to do so, ...
But: two checks for "x==0"? I think the second condition should be x<0.
-
Let's continue with the next challenge. The single layer perceptron can't do a Boolean XOR. We need more layers.
Again, the author defines the inputs, but now he does things differently:

Now he has an array containg 4 arrays of 3 items each, and another array with 4 items for the expected results.
But somehow, I fail to get them aligned with an XOR.
0 XOR 1 makes 1, doesn't it? But the second element in the result list 0,
1 XOR 1 makes 0, doesn't it? But the last element in the result list 1,In my opinion, the author just invented to Boolean IGNORE:
A IGNORE B = A.

Next, the author tells us he won't use the heaviside function here, but the sigmoid function. He does not tell us why,
But when he defines its derivative, things become clearer: the heaviside function is not derivable. And backpropagation requires a derivable function.Then the author defines the weights:

He informs us that random((3,1)) will return a vector of 3 rows and 1 column, different to random(3) used in previous example. But why does he initialize it with values between -1 and +1, while in the previous example he initialized it with values from 0 to 1? No idea. WTF.Deep learning is required by the reader!
-
Also worth mentioning: on p21, I found "eine moderne NIVIDA-Volta-Grafikkarte".
I'll continue reading that book, looking forward to stumbling upon a NIVEA graphic card.
-
Enters the convolutional layer.

It took me some time to understand that figure. Fortunately, I know some image manipulation techniques. There you have a "structural element" or "kernel" in shape of a matrix, and apply it to the input image which is typically shown as a two dimensional array,
The small colored numbers are part of the input data (the 5x5 matrix). While the black numbers are part of the 3x3 kernel inside the area enclosed by the colored dotted line, but outside that area they are part of the input data...
What a great figure!
-
@BernieTheBernie said in Deep Learning:
I think the second condition should be x<0.
Yes. Otherwise it's just an upside-down Dirac delta.
-
@BernieTheBernie said in Deep Learning:
I took a book with the title "Praxiseinstieg Deep Learning"
I found your problem. The book appears to be written in moon language.
-
@HardwareGeek said in Deep Learning:
@BernieTheBernie said in Deep Learning:
I took a book with the title "Praxiseinstieg Deep Learning"
I found your problem. The book appears to be written in moon language.
Goggle Mistranslate's detection algorithm, when applied to "Praxiseinstieg", hints that the Lunarians speak German.
-
@Steve_The_Cynic I mean, Duh!

-
A few chapters and many pages later...
On pp.82-3, the author creates a 3dimensional array with 2/5/3 elements each, and a square root operator. He shows the array on p82: it contains float numbers between 0 and 1.
On p83 he shows the result of applying the square root operator onto that array. All its values are still >0, but some of them are >1.

Ehm? How did that come? The square root of a number between 0 and 1 is also a number between 0 and 1. Or did he calculate square roots on the innermost arrays, viewing them as vectors? I am not so sure if a square root on a vector is defined.
Or on the inner 5x3 matrices? No, that does not work. The square root of a matrix is defined only if the matrix is symmetric.
So, what did he do?My brain is now convoluted by confusional neural networks...
-
Eventually, we arrive at a network for recognition of hand-written numbers (MNIST data) with Caffe2:

In the steps not shown here, the input data are downloaded and reformatted. Nothing special there.Then he sets up the network. He just shows the steps, but does nowhere tell us why he selected this specific step with the specific parameters instead of a different type of step or different parameters. We just go along this way!
What is dim_in and why is it 1? What is dim_out and why 20?
From image manipulation, I know what a kernel is, and I assume it has a square shape (as was shown in a post before). But what are its values? Or are they part of the following optimization process?
What is function FC?
Why do the numbers for both dim_in and dim_out grow? And why is at the FC step the former greater than the latter, while in the steps before, it was the other way round?
Then follows an activation function Relu, and another FC, and finally a normalization of the weights by Softmax.WHY?
WHY not something different?
NO ANSWER.At least, I could set up the environment on my machine, and play with it. Perhaps I can then find out more.
That's the gist of Deep Learning, isn't it?
-
A minor crap can be found on p143, The author needs to extract the filename without extension from a path.
That great scripting language called Python does not have a Path.GetFileNameWithoutExtension like the .Net world. So the poor guy has to re-invent the wheel.
And so he does:

Yeah, it works.
In his specific case:

Better not store the images in /usr/Bernie/Wtf/styles/starry-night.jpg...My curiosity is not yet satisfied: how will the author deal with Dates?
Perhaps some gems are still waiting in that book.
-
@BernieTheBernie said in Deep Learning:
That great scripting language called Python does not have a Path.GetFileNameWithoutExtension like the .Net world.
And it's definitely not something you might do with
os.path.splitext!
-
@dkf said in Deep Learning:
And it's definitely not something you might do with os.path.splitext!
Since I am not at all a Python programmer, I had to look up the documentation at https://docs.python.org/2/library/os.path.html
Applying that function on /usr/Bernie/Wtf/styles/starry-night.jpg returns:
root: /usr/Bernie/Wtf/styles/starry-night
ext: .jpgObviously different from starry-night, the return value of the author's function.
-
@BernieTheBernie
If you're using Python 3 (which I hope you and the author of the book are doing), you may want to take a look at pathlib.
-
@BernieTheBernie said in Deep Learning:
What is dim_in and why is it 1? What is dim_out and why 20?
From image manipulation, I know what a kernel is, and I assume it has a square shape (as was shown in a post before). But what are its values? Or are they part of the following optimization process?
What is function FC?
Why do the numbers for both dim_in and dim_out grow? And why is at the FC step the former greater than the latter, while in the steps before, it was the other way round?
Then follows an activation function Relu, and another FC, and finally a normalization of the weights by Softmax.WHY?
WHY not something different?
NO ANSWER.That's the thing that bugs me most with neural network (and other similar methods), there are a bunch of parameters that have almost no relation to the problem being treated, and some values Just Work while some other don't. They're black boxes not only in terms of not understanding what's happening inside (which is partly a good thing as they can model complex relationships), but also in terms of how you can tune them -- a black box with black buttons, to poorly extend the image.
Compare with simpler "machine learning" methods (e.g. good'ol PCA or clustering) or other analysis techniques, where most parameters have some degree of physical meaning, so you can get an understanding of what will happen if you tweak them this way or that. Not necessarily predict exactly what will happen, but at least get a feeling of how results will change.
-
@remi said in Deep Learning:
understanding what's happening inside
They're doing hypercurve fitting in high-dimensional space with non-trivial mappings between what we understand as inputs and outputs, and what the algorithm understands as inputs and outputs. Sometimes, though not usually, there's a temporal dimension to the hyperspace embedding.
The problem is you can understand what it is doing on one level, but converting the understanding on that level to anything else is stupidly difficult.
-
@BernieTheBernie said in Deep Learning:
WHY?
WHY not something different?
NO ANSWER.Generally books are unable to answer direct questions.

-
@dfdub said in Deep Learning:
@BernieTheBernie
If you're using Python 3 (which I hope you and the author of the book are doing)Me? Nope, I don't use Python (currently - and hopefully won't use it). I am quite reluctant to learn more of that scripting language than what is necessary to understand most scripts.
And the author... Uhm, let's look at p.54 (my translation):
All examples were tested with Python 2.7, and are expected to run also with Python 3, maybe requiring minor adjustments.
I stumbled upon the WTFery of Python 2 vs 3 some time ago. I wanted to create a map for a Garmin unit based on OpenStreetMap data, with DEM (digital elevation model), and elevation contour lines. I had some DEM files, and needed to create contour line files usable for the map creation pipeline. Well, I found a Python script, downloaded it, and went to install Python. On the Python download site, I found 2 versions: 2 and 3. After short research, I found out that Python 3 was first released almost 10 years ago. So why should I use Python 2? I installed Python 3. It suggested C:\python3x (dont remember the exact number, perhaps 36) as its installation folder. WTF? The OS on my computer is NOT Windows 95 where you place all your crap directly into C:! (and your temporary files in C:\Windows, but that's a different story). Corrected the path to C:\Program Files\Python3x. It installed, but failed to run. Don't know if that was due to the uppercase P in Python3x, to the very long path name, or to the space between Program and Files, or something else.
OK, removed that installation and tried again with C:\python3x. Now it started, but failed to run the script. The error messages showed that the script was written in Python 2. Tried a converter. Failed. Removed Python 3, installed Python 2. The script did not produce the expected output anyway...
The I removed Python from my machine completely.I learned that most Linux distros replaced PERL with Python.
Thinking of Python as a more fashionable kind of PERL looks quite adequate!
-
Figure 6-15 shows a visualization of the data in a pool layer of the CNN

Oh, how beautiful! Can you tell me what those shades of grey mean? Can you do it in color and 3d also? That could be even more beautiful!At least, the code for the function vis_square is shown on that page.
But no word on how to interpret that image, of course.
(@dfdub Take a look at the top roght corener of the figure: "Python 2")
-
@BernieTheBernie said in Deep Learning:
Take a look at the top roght corener of the figure: "Python 2"
Of course. Because while you're writing a crappy book, why not use an outdated language version which will be unsupported by the time people read it, just to show how little you care about details?
I initially parsed your typo as "coroner" and that's what we really need for Python 2.
-
@BernieTheBernie said in Deep Learning:
He just shows the steps, but does nowhere tell us why he selected this specific step with the specific parameters instead of a different type of step or different parameters.
Spoiler alert: Almost none of the deep learning things do. At best, somebody tried a few different sets of parameters. But the default answer to "why this layout/shape/count/activation function/whatever" seems to be a shrug and a "because that ended up working", or perhaps a "those other guys did it that way".
-
@cvi Sounds like pure cargo cult/magical thinking/overfitting. Fiddle till it "works", and then claim you've discovered something.
-
This post is deleted!
-
@error_bot !xkcd Machine Learning
-
-
@dfdub said in Deep Learning:
I initially parsed your typo as "coroner" and that's what we really need for Python 2.
Calm down, dear. It's already doomed and on death row. Execution is scheduled for the end of this year.
-
@cvi said in Deep Learning:
Almost none of the deep learning things do.
There's a suspicion that it's not really all that important in the first place, since the learning algorithms themselves converge strongly enough to start out with. (There's a similar argument with spiking NNs, but there at least the argument “it looks like what has been measured in biology” can be used; the suspicion is that there's a wide class of non-linear models that will work, especially so if you allow both adaptation of weights and synaptogenesis.)
-
@cvi said in Deep Learning:
@BernieTheBernie said in Deep Learning:
He just shows the steps, but does nowhere tell us why he selected this specific step with the specific parameters instead of a different type of step or different parameters.
Spoiler alert: Almost none of the deep learning things do. At best, somebody tried a few different sets of parameters. But the default answer to "why this layout/shape/count/activation function/whatever" seems to be a shrug and a "because that ended up working", or perhaps a "those other guys did it that way".
Back when I had a lecture about NNs a decade ago, I learned that you should use a sigmoid activation function because it has all the right properties. Recently I got told that everybody is using ReLU now. No idea why. I'm told that it not only is faster to compute because it's simpler, but even that aside it produces better results.
Now, in this case I think there are actual explanations for why it works better (I just haven't read them), but for other things pretty much all of it seems to be cargo culting the methods of the last guy, who achieved the best-yet results only by putting in the most power.
-
@dkf said in Deep Learning:
There's a suspicion that it's not really all that important in the first place, since the learning algorithms themselves converge strongly enough to start out with.
I find it a bit problematic. On one hand, if you want to set up a network for a new problem, it's very hard to get a good starting point. Most advice so far seems to be try something arbitrary, if it doesn't work, make it bigger, otherwise make it smaller until it stops working. On the other hand, how do I know that somebodies published network isn't vastly overprovisioned? Training (and even evaluating) is costly enough as is.
(There are of course exceptions, where the relevant people have very good knowledge and done a very in-depth analysis/exploration, but those seem to be the exception rather than the rule.)
-
@topspin said in Deep Learning:
Recently I got told that everybody is using ReLU now. No idea why. I'm told that it not only is faster to compute because it's simpler, but even that aside it produces better results.
That used to be my impression too. However, a lot of networks seem to be using non-linear activation functions (sigmoid etc) in at least one layer. I've also read/been told that relu actually perform worse than the traditional activation functions, but that they are so much cheaper to evaluate that you get a better results in the end anyway, simply because you can train more/faster.
-
@dkf said in Deep Learning:
@cvi said in Deep Learning:
Almost none of the deep learning things do.
There's a suspicion that it's not really all that important in the first place, since the learning algorithms themselves converge strongly enough to start out with. (There's a similar argument with spiking NNs, but there at least the argument “it looks like what has been measured in biology” can be used; the suspicion is that there's a wide class of non-linear models that will work, especially so if you allow both adaptation of weights and synaptogenesis.)
Why not use deep learning to determine the most applicable deep learning algorithm?
-
@cvi That at least makes sense. If theory (ignoring how much that matches reality) tells you that sigmoids have better training properties but they are costly to compute, the extremely cheap approximation of a ReLU is more efficient.
What I didn't understand is how everything else being equal (same amount of training) it could achieve better results. I heard that claim, it seemed counter-intuitive, but with these DL things who really knows anything for sure.
-
@topspin The other thing I've heard, is that relu apparently don't suffer (or at least suffer less) from the whole vanishing gradients thing (this goes a bit counter to what I said previously, so, eh, who knows?).
I don't know how true that is, and how much of the vanishing gradients were "fixed" by better/more advanced training schemes (i.e., instead of just plain standard backpropagation). After all, with traditional relus the gradient is zero on one side (leaky relus seem to fix that, but I don't see them used as exhaustively.)
-
-
@cvi said in Deep Learning:
I find it a bit problematic.
99% of all machine learning is crap. Might as well call it praying to the machine god for all the knowledge that most people are using with it. There are a few people who actually know what they're doing, most of whom are looking very hard at how to train networks using much smaller input datasets, but any learning algorithm that needs millions of examples to learn something even partially is definitely bunk, and might as well be randomly applying a transform until you get something that produces the right result purely by chance. (Random isn't wrong as such, but there's a big difference between stochastic processing and banging two rocks together hoping that the solution will just pop up.)
-
@pie_flavor said in Deep Learning:
Why not use deep learning to determine the most applicable deep learning algorithm?
That'd be great… but you need to train millions of examples optimally to make the input dataset for that…
-
@dkf said in Deep Learning:
but any learning algorithm that needs millions of examples to learn something even partially is definitely bunk
That'd be great… but you need to train millions of examples optimally to make the input dataset for that…
Let's just start banging those two rocks together then.
-
@dkf The reason for big sample sizes is high dimensionality and sparseness.
The learner has to learn two things: how to categorize into scenarios, and then the specific rules/logic for each. (It could make sense to use a clustering algorithm and feed into multiple NN's...)
It's tractable (now, not when I did machine learning in 2006...), but you end up with big necessary samples sizes.
-
@Captain said in Deep Learning:
The reason for big sample sizes is high dimensionality and sparseness.
Doesn't stop the algorithms from also being rather shit. I've seen results (that I'm not sure about whether they're published yet) where it turns out that temporality is rather more important than was previously thought, allowing learning to proceed much more rapidly. Seriously, doing both temporal and spatial correlation seems to make the learning convergence (at least for relatively simple problems such as MNIST) enormously faster.
-
@dkf said in Deep Learning:
might as well be randomly applying a transform until you get something that produces the right result purely by chance.
I wrote a genetic algorithm using bytecode instructions as the genome and the result was almost exactly this.
-
@error said in Deep Learning:
I wrote a genetic algorithm using bytecode instructions as the genome and the result was almost exactly this.
Oh, it definitely is like that for simple genetic algorithms (and at least they're totally honest about producing results by chance). The more complex ones have software genes that control recursive code generation. The code they spit out is… genuinely alien; people don't write their programs to have a fractal structure.
One of our students is doing this sort of thing to generate spiking neural networks capable of learning. He's using an enormous amount of compute power, and is probably the closest anyone in the world is to making skynet (when it isn't crashing due to random radiation-induced hardware failures). He'll go far. Or our code will just up and crash on him and prevent the apocalypse by accident!

-
Isn't it obvious? You're supposed to use deep learning to learn deep learning.
-
@_P_

(btw, GIS "that's deep meme", even with safesearch on, gave me some not-so-unexpected-on-hindsight results, but not quite was I was expecting initially either)
-
@BernieTheBernie sound like a really crappy book; this website should give a better introduction
-
Overall, I found the book rather crappy. But I should mention that I found some "fun" chapters in it too:
A chapter on transferring the style of an artistic painting onto a photo, and a chapter on a "dreaming" network, both with long code listings so that one can try that.
Likely useless, but in case my network will have odd hallucinations, I might remember these chapters.
-
@BernieTheBernie said in Deep Learning:
in case my network will have odd hallucinations
I'm still waiting on a proper classifier to lie along to help me determine if mind has ever experienced this.
-
@pie_flavor I don't remember the exact context, but another student in a discussion class of mine said, in all seriousness, that deep neural networks should be trained by other deep neural networks. We ended class.
-
@HannibalRex Well, GANs kind of do that, don't they. (If you squint a lot)
-
@topspin Perhaps so, I'm far from familiar enough to say one way or another, but this was nowhere near that context. I remember this comment came from so far out in left field and was so forceful it just ended the entire discussion.
-
@HannibalRex said in Deep Learning:
Perhaps so, I'm far from familiar enough to say one way or another
Oh, it was just a throw-away remark. My knowledge is entirely superficial.
 Heaviside step function - Wikipedia
Heaviside step function - Wikipedia

 1838: Machine Learning - explain xkcd
1838: Machine Learning - explain xkcd
