The "Good news, everybody: we’re safe from Skynet!" Rant
-
@Arantor said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Arantor said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler someone should show you Gerrit sometime.

It’s a Git server where you can save draft commits, and revise the drafts until you have each commit be perfect whereupon the final perfect commit (or even a branch full of them) hits the actual repository.
Yo dawg I herd u liek versioned history so imma version control your version control.

-
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
-
@Mason_Wheeler my last job but 1 relied on it.
Consider the following: a product has a repo. It pushes out patches every two months.
You also have a repo tracking the same project but you have branches for each client where they have their special snowflake custom changes as commits (done in that perfect way so that each commit really does reflect a real atomic commit for a change)
Now it’s patch day. You have, say, v3.9.2 in your repo plus the custom changes, and you want to split it out such that you end up with 3.9.3 in your repo with your custom patches on the end.
Having spent the time making your patches very fucking tidy, this is generally a quick process to do. I would routinely spend more time waiting for the network I/O to do its thing than my actual effort.
-
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
Do you understand the meaning of "turtles all the way down"? The solution to the problem of the VCS server getting corrupted is to back up (or perhaps "replicate" would be a better term) the VCS server. Just the same as the solution to any other type of server getting corrupted.
This is a server issue, not a VCS issue.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
Do you understand the meaning of "turtles all the way down"? The solution to the problem of the VCS server getting corrupted is to back up (or perhaps "replicate" would be a better term) the VCS server. Just the same as the solution to any other type of server getting corrupted.
So your workstation is somehow different from a "server" in that it needs backup done as necessary part of a VCS but a server doesn't?
And no, "replicate" is not a replacement for or in any meaningful way equivalent to backup.
-
@LaoC said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
Do you understand the meaning of "turtles all the way down"? The solution to the problem of the VCS server getting corrupted is to back up (or perhaps "replicate" would be a better term) the VCS server. Just the same as the solution to any other type of server getting corrupted.
So your workstation is somehow different from a "server" in that it needs backup done as necessary part of a VCS but a server doesn't?
...huh?
And no, "replicate" is not a replacement for or in any meaningful way equivalent to backup.
Why not? Replication (in the database sense) achieves the same result: you have two intact copies of your data. I was suggesting that, for a system that's actively modified quite regularly like a VCS, replication might work better than running backups of the data store.
-
@Mason_Wheeler do you understand that for every committer to a Git repo, they all have the entire history at once and can reconstitute pretty much the entire server from what is locally checked out?
Any of them can become the VCS server at will in lieu of fixing “the master server”.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
Git is good at branching and merging because branching and merging is how you do everything in Git. It's Git's "magic hammer." Before Git, we didn't do branching and merging for every little thing, because we had better ways to do them, because we weren't using Git where everything requires branching and merging!
Unless you are using a shared filesystem with exclusive locks on files, you everything involves merging. In particular,
svn update(and corresponding operation in every other version control system) is a merge. With the working copy, which has all the features of a branch except nothing remembers its state.And this not remembering state is a problem. You are working on something, and do
svn update. It merges the changes in the repository with your local changes, using the 3-way merge alrgotithm, and … you get a conflict. And if you make a mistake resolving it, you are screwed and can start over, because there is no looking back.Distributed version control (not just git, also monotone, darcs, bzr, hg, fossil, brz, pijul) makes the local checkout a full-featured branch, with state. Now you can look at the previous state again and even go back and re-do the merge if needed.
But the real killer feature of distributed version control (not just git, also monotone, darcs, bzr, hg, fossil, brz, pijul) is that it made branches cheap. Not technically, but mentally. When branches are permanent part of the revision identifiers, like in subversion or tfs or clearcase, people want to give them good names. And we all know naming is hard, so the result is that people shy away from creating them. With git (but also monotone, darcs, bzr, hg, fossil, brz, pijul), throw-away names like
temportest,test2,triageetc. are OK (and can be changed after the fact), so nobody thinks twice to make a branch when there is a use. Plus they are aware that their checkout is a separate branch anyway. Which, as I said, it always kinda was, but it lacked features and the similarity was obfuscated.And easy branching allows one thing that corporate development teams do want: test before integration. With the older version control systems, everybody was committing to this increment's branch, breaking each other's work, and then there was a big test and integration phase, which was rather inflexible. And doing review at that point was rather late, if anybody bothered at all.
With git (but also monotone, darcs, bzr, hg, fossil, brz, pijul), each feature gets a branch, it is developed there, reviewed there, tested there, and merged at the moment it is basically ready for deployment. Which means any fixes and critical features make it into production faster and that's a thing enterprises are really after.
Now why git is so much more popular than the other seven I keep mentioning? Well, performance. Git was the first that was carefully optimized to handle the moderately large Linux source, and could use it to demonstrate how well it's handling it. Conceptually they are otherwise similar. But the concept is still a big improvement over the centralized systems. Even for large corporations, though the original motivation is completely different.
-
@Arantor said in The "Good news, everybody: we’re safe from Skynet!" Rant:
I agree that GitHub is a large part of Git’s success, and I’d go as far as suggesting that this is partially because it has broadly-usable issues that integrate nicely with PRs, partially because it has a usable UI for browsing the repo including history.
It is. But it was Git that enabled the creation of GitHub. The whole concept of pull requests only started to make sense with distributed version control. It could have been done (and is done, it just isn't as popular) with hg and bzr too, but not with subversion or cvs.
At the time of subversion or cvs, you were sending patches. But those systems couldn't help with that process in any obvious way, because the submitter would need access to the server before even starting to work on the patch. Distributed version control changed that. Hallmark of a distributed system is that objects retain their identity when moved between nodes. That's the difference here. In subversion, revision 12345 only means a thing in context of the server, but in git the commit hash is a hash of the content and remains the same no matter where it is stored. So now suddenly the contributors could take full advantage of the version control system before needing to persuade the maintainer their work has any merit. Of course now the feature is most often used within teams that do have access to the same repository anyway. But it wouldn't have been invented before the distributed model.
And I should note, that applying a patch is the same three-way merge algorithm, just the patch does not carry the content of the two versions involved, so if the third version (the one to which it is to be applied) differs a lot, it becomes harder to resolve conflicts. So again there was always merging, just under different name and with less tooling to help when things went wrong.
-
@boomzilla said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Arantor said in The "Good news, everybody: we’re safe from Skynet!" Rant:
feature branching as a development model is basically impossible on SVN.
This hasn't been true for a while. It definitely used to be, but it's gotten much better about branches. It's probably still a bit behind on merging but nothing like it was.
- The main difference is mental. Because in subversion versions are on branches, the branch name matter more.
- I'm still not sure they ever properly fixed the merging of branches with common ancestor on third branch. Which is only a special case because versions are on branches; in git it's just a uniform directed graph.
-
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In subversion, revision 12345 only means a thing in context of the server, but in git the commit hash is a hash of the content and remains the same no matter where it is stored.
But now it's a hash. In SVN, you can immediately see that revision
12345comes before revision12357. This is obvious and intuitive. In Git, does revisionda30acd5872f25217a6a9092df896ed8976305a0come before or after revision48b951d15bad9f78c345dadfc2e1314788a500c1
-
@Mason_Wheeler potentially both, but never mind.
-
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@boomzilla said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Arantor said in The "Good news, everybody: we’re safe from Skynet!" Rant:
feature branching as a development model is basically impossible on SVN.
This hasn't been true for a while. It definitely used to be, but it's gotten much better about branches. It's probably still a bit behind on merging but nothing like it was.
- The main difference is mental. Because in subversion versions are on branches, the branch name matter more.
I guess. Haven't really thought about it in this context before.
- I'm still not sure they ever properly fixed the merging of branches with common ancestor on third branch. Which is only a special case because versions are on branches; in git it's just a uniform directed graph.
I don't think I've done this so much, other than cherry picking specific commits to back patch a branch of a previous sprint.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
For example, try this:
- Project exists on two computers.
- Project contains a file with 1,000 lines of code.
- On computer A, change line 20 in this file.
- Check in changes to the repo.
- On computer B, change line 700 in this file.
- Save changes locally. Do not check in.
- Pull changes made by computer A from the repo.
SVN: Works just fine. No problem. (And why should there be?)
Until you make changes close to each other, reformat the code on one side or do anything that actually does cause a conflict.
Git: Freaks out and declares that it's not going to even attempt to pull those changes until you either get rid of those local changes or commit them, because there might somehow mystically be a (dun dun DUNNNN!) merge conflict! (How?
It's cautious. It does not want to run the three-way merge algorithm on contents that is not saved in the repository. It can afford it, saving it is ultra-cheap.
And if there was, what difference would having your local changes checked in make anyway?!? It would still be a merge conflict, so the entire thing is pure nonsense!)
A huge one. Subversion just slaps those conflict markers in your file. And slaps them there without the base. That's already totally fucked up. And now it also forgot what the base was, so you can't even look it up with a proper three-way merge tool like kdiff3.
In git, you just do the local commit. That's basically a free action. You can do it whenever. Don't think twice about it. You can always undo it, redo it, do whatever. But now
- You have the full content of the three stages, base, local and remote, so you can run a proper three-way merge tool on them.
- If you screw up, you can retry the operation any number of times.
- Say the conflict is because the other side has reformatted the code. So you reformat the code the same way and merge again and it works fine this time. And if not, you merge the part before the reformat, do the reformatting, then merge the rest. In git you can, because you have that local commit to go back to and try another way. While subversion already fucked up your checkout and that's it.
Yeah, "doing merging well" is easy if you dump all the complexity on the end user and refuse to play the merge game on anything other than easy mode!
Doing merging well … the thing is more that it does it properly, while subversion doesn't. Or didn't for a long time. Because it had trouble finding the correct most recent common ancestor. Because the model with using directories for branches, and the complication of branching on arbitrary subtrees, makes that a hard problem. The distributed model forces having a simple directed graph of revisions at the top level only, and that simply avoids a whole lot of complexity. Complexity that almost nobody actually needs, but the centralized version control systems always had.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
If two entirely different portions of a file get changed, and the changes are integrated, there is no possibility of a merge conflict. None. Zero. Does not and can not exist. It is possible that this could introduce logical problems in the code at the language level, such as if your local changes renamed or deleted a field that the remote code relies upon, but 1) that's not a merge conflict and it's not an issue that it's possible for the VCS to comprehend, and 2) the same logical problem would be introduced regardless, even if your local changes were checked in, so what benefit comes from checking them in to avoid the nonexistent merge conflict?
… but it is a case where it totally is useful to have the state before the merge recorded. You have a working code, you do a merge, and you have a non-working code. At which point you might want to go look which changes you brought with that merge that might have caused that logical conflict. And then the local commit git made you make can come in handy, because you can go look at the history in a history viewer.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using.
- I disagree. Versioned and backed up have separate purposes and both are useful in their own rights without the other. It is useful to integrate them in one system, but you don't always need them together.
- You seem to be dead set on wanting the same terms to mean the same thing in all version control systems. They don't. Documentation of every version control system means subtly or less subtly different things when it talks about commits, revisions, branches etc.
- Local commits are not backed up. But note that at the points where you can't push them in git, you can't commit in subversion either, so git isn't any worse, it just isn't as much better as your understanding of the term ‘commit’ would suggest.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In subversion, revision 12345 only means a thing in context of the server, but in git the commit hash is a hash of the content and remains the same no matter where it is stored.
But now it's a hash. In SVN, you can immediately see that revision
12345comes before revision12357. This is obvious and intuitive. In Git, does revisionda30acd5872f25217a6a9092df896ed8976305a0come before or after revision48b951d15bad9f78c345dadfc2e1314788a500c1Yeah, that's the cost of Network Relativity. Things that happen at different places (computers) do not have a well defined order (I'm calling it Network Relativity, because it works pretty similarly to General Relativity, the theory that explains why things in the physical world and not strictly synchronized either).
You can ask git whether the one version precedes the other, and you have the timestamps in them. Distributed systems can't do better. It's the price for not having to be on the network and waiting for the synchronization all the time.
-
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
The whole concept of pull requests only started to make sense
I still don't get the naming of that. You don't have to request to do a pull. A pull request is more like a merge request. You don't get pull conflicts from a pull request, you get merge conflicts.
Pull
Push
Pull request (merge)I'm sure there's a historical/technical reason for calling it a pull request, but it's non-obvious superficially.
-
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In git, you just do the local commit. That's basically a free action.
No, it's not. It's all of the work of creating a commit, minus the actual meaningful part, which is the simplest part of the whole process.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In the sense that either your code is ready to be committed to the repo or it isn't. In my entire career I've never seen a valid in-between state.
But, but, but... then how am I going to backup the code changes I've made that aren't ready for the repo yet?

-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In Git, does revision da30acd5872f25217a6a9092df896ed8976305a0 come before or after revision 48b951d15bad9f78c345dadfc2e1314788a500c1
Since it's distributed, they might have been done in parallel.
And if you merge the corresponding histories.. well, then that depends on which way you did the merge. And it might not even matter.
-
@Zecc Exactly! Hash version numbers convey no meaningful information.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
Hash version numbers convey no meaningful information.
So what? If you want to see the relationship between them, ask the software. If it knows about them both, it can give you metadata about them (like the author, timestamp, possibly the digital signature), generate a difference description between them, show the commits that may lie between them along various paths (e.g., from a common ancestor), etc.
You must not think of these things as numbers but rather as IDs.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
a commit, minus the actual meaningful part,
I have to disagree with you there. Being able to commit without pushing to the main repo is my favourite part of git. I like being able to commit often without "polluting" shared history. Other people don't need to see how the sausage is made.
In practice, I would push a lot more often to the central repro, but in a private branch, if I was worried my machine will die. But, more often than not it's really not worth it, because I keep amending the latest local commit until I consider it's ready for pushing. Or I squash the latest commits in a branch because they are not interesting on their own.
But the kicker is that I'm free to do as I please based on my own judgement at any point in time, and that's why it's cool.
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Zecc Exactly! Hash version numbers convey no meaningful information.
It's distributed version control.
Either you have to ask for a monotonic ID from a central repo every time you want to make a local change, or you'll get the same ID being used by completely different versions created by two people in parallel.
And if you do the former, you may get version 17586 as a child of version 1234 in a branch forking from an old revision. So it's not like monotonic numbers are very informative either.
Use the author and timestamp metadata. That's what they are there for.
Oh, and at least with hashes we're sure we're talking about the actual same version no matter what.
-
@Zecc said in The "Good news, everybody: we’re safe from Skynet!" Rant:
It's distributed version control.
-
@Mason_Wheeler That song raises so many questions.
- Why would you use straw to fix a bucket?
- If straw is the only thing you have to block the hole in a bucket, wouldn't you prefer it to be long?
- Why use an ax, of all things, to cut straw? Specially if it's dull. Is your farm really that badly equipped?
- Is it really a problem for a stone to be too dry to sharpen an ax? I admit I have no experience grinding axes.
- If you want to wet the stone, can't you just dip it in the water instead of getting the water with the bucket?
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In git, you just do the local commit. That's basically a free action.
No, it's not. It's all of the work of creating a commit, minus the actual meaningful part, which is the simplest part of the whole process.
Once again you're shooting your foot with an absurd focus on some semantic nonsense.
It can be perfectly meaningful for me to do local incremental changes and have that history while I'm working. The inability of your brain to admit this does not affect the usefulness of any of it in the rest of the universe.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Zecc Exactly! Hash version numbers convey no meaningful information.
Maybe we need to back up. What does "meaningful" mean to you?
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Zecc Exactly! Hash version numbers convey no meaningful information.
Not sure why a random linearization of a parallel process would give you anything meaningful either. I guess it's nice to see number go up, though.
If you have multiple people working on multiple things, any linearized timeline is pretty much one possible arbitrary choice. Representing it as a graph is way more useful.
-
@cvi said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Zecc Exactly! Hash version numbers convey no meaningful information.
Not sure why a random linearization of a parallel process would give you anything meaningful either. I guess it's nice to see number go up, though.
If you have multiple people working on multiple things, any linearized timeline is pretty much one possible arbitrary choice. Representing it as a graph is way more useful.
The timeline isn't a history of "working on;" it's a history of commits. That's not the least bit arbitrary; that's the official Single Source of Truth. And it's exponentially easier to understand when it doesn't require a degree in graph theory to make sense of!
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
it doesn't require a degree in graph theory to make sense of!
I don't understand the tool != It's a bad tool
-
@TimeBandit said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
it doesn't require a degree in graph theory to make sense of!
I don't understand the tool != It's a bad tool
"Tool A is easy to understand. Tool B is difficult to understand. They both do fundamentally the same thing." = Tool A is a better tool.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
Tool B is difficult to understand.
For you

-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@LaoC said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
Do you understand the meaning of "turtles all the way down"? The solution to the problem of the VCS server getting corrupted is to back up (or perhaps "replicate" would be a better term) the VCS server. Just the same as the solution to any other type of server getting corrupted.
So your workstation is somehow different from a "server" in that it needs backup done as necessary part of a VCS but a server doesn't?
...huh?
"You have nothing" without a remote copy seems to be true for the workstation but not for the repo server. If the server is destroyed/stolen, what do you do? Would be nice to have a copy of the repo with the entire history somewhere else, say geographically distributed in each checkout, right?
And no, "replicate" is not a replacement for or in any meaningful way equivalent to backup.
Why not? Replication (in the database sense) achieves the same result: you have two intact copies of your data. I was suggesting that, for a system that's actively modified quite regularly like a VCS, replication might work better than running backups of the data store.
If a drunk admin types
rm -Rf . *ordrop database vcs;, you're fucked with replication just like without it. A backup is different.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@TimeBandit said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
it doesn't require a degree in graph theory to make sense of!
I don't understand the tool != It's a bad tool
"Tool A is easy to understand. Tool B is difficult to understand. They both do fundamentally the same thing." = Tool A is a better tool.
Ah so this is why you ride a skateboard everywhere instead of driving a car.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Bulb said in The "Good news, everybody: we’re safe from Skynet!" Rant:
In git, you just do the local commit. That's basically a free action.
No, it's not. It's all of the work of creating a commit, minus the actual meaningful part, which is the simplest part of the whole process.
You're probably thinking of creating a commit as hard work because you're used to only creating commits that everybody can see, that should be meaningful and self-contained and have a good description and whatnot. Nobody cares about that for local git commits.
-
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
unless everyone is all working on a primary branch in some sort of monorepo

-
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Carnage said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@dkf said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler But it's not a backup, because a backup necessarily involves separate storage. The history part is the important bit of any VCS; you don't just have the current configuration, but you have all the other ones in the past as well.
I disagree. All three components of the definition of version control I gave above (versioned, integrated, backed up) are crucial. Take away any one of the three and you don't have a VCS worth using. (Theoretically you could get away with dropping integration if you're a solo dev working on a project alone, but then you'd have a toy VCS in much the same way as SQLite is a toy pretending to be a real database.)
So,s ay you have SVN, when SVN gets unrestorably corrupted, how do you restore that SVN to a workings state using itself? Backup is separate from VCS. Distributed VCSes get a sorta, kinda, backup feature by means of mildly modified copies existing everywhere, but they are not a replacement for backups.
Yeah, yeah, it's turtles all the way down. You deal with VCS server corruption the same way you deal with any other sort of server corruption. This is a server issue, not a VCS issue.
Are you willfully missing the point or didn't you understand it?
Yes.
-
@jinpa said in The "Good news, everybody: we’re safe from Skynet!" Rant:
I'm sure there's a historical/technical reason for calling it a pull request, but it's non-obvious superficially.
I've always understood it to mean that you're requesting the other repo's maintainer to pull from your repo (logically, if not literally).
-
@LaoC said in The "Good news, everybody: we’re safe from Skynet!" Rant:
Nobody cares about that for local git commits.
Or even a commit you push to a private branch on another repo ("main" or otherwise), if you're so concerned about your disk dying.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
The timeline isn't a history of "working on;" it's a history of commits. That's not the least bit arbitrary; that's the official Single Source of Truth. And it's exponentially easier to understand when it doesn't require a degree in graph theory to make sense of!
Says someone that has clearly never seen a non-trivial rebase.
Scenario:
Commit A is made for a new feature.
Commit B is made, unrelated to A.
Commit C is a typofix for A.Now rebase this to reorder the commits as A, C, B, then squash C into A to leave the new A commit with its fix, otheriwse the complete untypoed atomic commit for that feature.
This happens in real world, production environments. Groups that curate their PRs tidily will insist on this sort of thing before merging.
The fact that you don't do it this way is not proof positive that the rest of us don't do it this way, nor that the tool is bad because it explicitly allows workflows like this (for which a linear measure is explicitly not going to fly)
-
@HardwareGeek said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@jinpa said in The "Good news, everybody: we’re safe from Skynet!" Rant:
I'm sure there's a historical/technical reason for calling it a pull request, but it's non-obvious superficially.
I've always understood it to mean that you're requesting the other repo's maintainer to pull from your repo (logically, if not literally).
GitLab calls them merge requests, which is probably more meaningful.
-
@Arantor Stuff like that is exactly why I don't do it that way. There's something disturbingly Orwellian about rewriting the history of your repo.
-
@Mason_Wheeler You would probably be happier with Fossil. That doesn't let you rewrite history, but it lets you amend things (the amendments are really a metadata-only commit, but you can ignore that). It also has a workflow more optimised for small teams; commits are usually shared unless you tell it not to for that branch. (Also, it doesn't need to synch immediately, in case you're working offline. I've found that useful when flying long-haul over the ocean.)
One of the best things about it is that it comes with a web-based history viewer and ticket management system. And it is much better about displaying things like cherry-picks helpfully than UIs for git typically are.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Arantor Stuff like that is exactly why I don't do it that way. There's something disturbingly Orwellian about rewriting the history of your repo.
Maybe. But in practice it's a lot more disturbing trying to get a quick understanding of history and being bogged down by a spaghetti of irrelevant details rather than seeing actually meaningful commits. Kind of like the difference between data and information.
-
@Zecc That's what
blameis for.
-
@boomzilla said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@TimeBandit said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
it doesn't require a degree in graph theory to make sense of!
I don't understand the tool != It's a bad tool
"Tool A is easy to understand. Tool B is difficult to understand. They both do fundamentally the same thing." = Tool A is a better tool.
Ah so this is why you ride a skateboard everywhere instead of driving a car.
To be fair, if I could ride a skateboard without breaking my arse I probably would try.
-
@Mason_Wheeler said in The "Good news, everybody: we’re safe from Skynet!" Rant:
@Zecc That's what
blameis for.Our logs used to look like the one of the left, and nowadays they look like the one on the right. I
blamethe people who don't know how to rebase.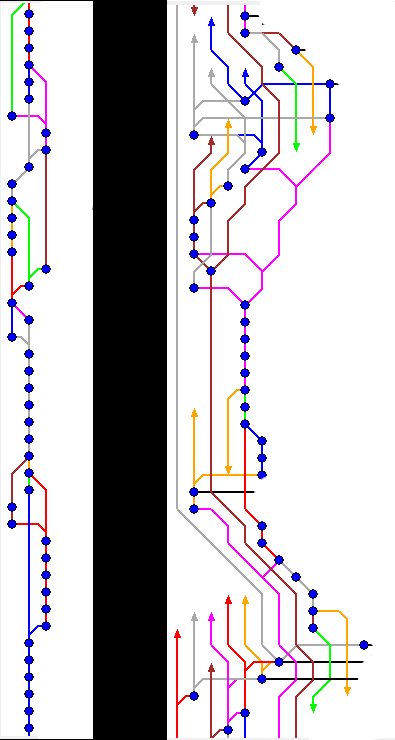
-
@Zecc And I blame people who chose to use a tool that treats branches and merges as a magic hammer.