The Revival of Great SQL Ideas
-
 The Revival of Great SQL Ideas — Big News In Databases — Fall 2018
The Revival of Great SQL Ideas — Big News In Databases — Fall 2018

More NoSQL systems picking up SQL ideas, innovative cloud solutions, Just In Time (JIT) compilation
It appears that people are actually rediscovered that actually having a data structure actually makes sense.
-
Yeah, I think the main reason devs jumped on the NoSQL bandwagon is that most devs are utter shit at data modelling, which gets painfully obvious in an RDBMS and SQL system. But it seems most people just blamed the tools for their own ineptitude, as per usual.
-
@Carnage said in The Revival of Great SQL Ideas:
Yeah, I think the main reason devs jumnped on the NoSQL bandwagon is that most devs are utter shit at data modelling, which gets painfully obvious in an RDBMS and SQL system. But it seems most people just blamed the tools for their own ineptitude, as per usual.
I am far from an expert with Relational Databases. But I was shocked how many developers didn't know basic SQL, Foreign Keys and Data Types.
-
I always found SQL to be a bit cargo cultish. I know relational databases are based on specific mathematical principles, but that doesn't mean we always have to do everything the exact same way.
For example, in nearly every computer language in the world that supports data objects, you can declare something like
type Person{ int age; string name; list<string> favoriteColors; }But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why? because some guy said so 47 years ago?. It's not just the same data, it's fundamentally the same data type represented in different ways. What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
-
This post is deleted!
-
@anonymous234 said in The Revival of Great SQL Ideas:
I always found SQL to be a bit cargo cultist. I know relational databases are based on specific mathematical principles, but that doesn't mean we always have to do everything the exact same way.
For example, in nearly every computer language in the world that supports data objects, you can declare something like
type Person{ int age; string name; list<string> favoriteColors; }But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why? because some guy said so 47 years ago?. It's not just the same data, it's fundamentally the same data type represented in different ways. What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
Nothing, as long as they want to remain small and not do things like, perhaps, look at the favoriteColors of more than one person at a time, for instance to see who-all likes "blue".
Sometimes there is a right way to do a thing - said right way does not constitute a cargo cult until the understanding is lost.
2 + 2 = 4isn't a cargo cult.
-
CREATE TABLE Person { age integer, name text, favoriteColors text[] };If you're that insistent. You can even have
SELECT name,favoriteColors FROM Person WHERE 'chartreus' = ANY(favoriteColors)* but you may not find anyone.
-
@Watson said in The Revival of Great SQL Ideas:
CREATE TABLE Person { age integer, name text, favoriteColors text[] };If you're that insistent. You can even have
SELECT name,favoriteColors FROM Person WHERE 'chartreus' = ANY(favoriteColors)* but you may not find anyone.and if your DB has yon extension past ANSI.
-
@anonymous234 said in The Revival of Great SQL Ideas:
I always found SQL to be a bit cargo cultish. I know relational databases are based on specific mathematical principles, but that doesn't mean we always have to do everything the exact same way.
For example, in nearly every computer language in the world that supports data objects, you can declare something like
type Person{ int age; string name; list<string> favoriteColors; }But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why? because some guy said so 47 years ago?. It's not just the same data, it's fundamentally the same data type represented in different ways. What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
How else would you do it? Oh! Store it all in one object. Hmm...we could call it a document. This is going to be really snazzy.
-
@anonymous234 said in The Revival of Great SQL Ideas:
I always found SQL to be a bit cargo cultist. I know relational databases are based on specific mathematical principles, but that doesn't mean we always have to do everything the exact same way.
For example, in nearly every computer language in the world that supports data objects, you can declare something like
type Person{ int age; string name; list<string> favoriteColors; }But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why? because some guy said so 47 years ago?. It's not just the same data, it's fundamentally the same data type represented in different ways. What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
No it is so you don't have data duplication.
Consider this. Each on of these objects except for the last two directly map onto a table. The last two entities would be looked up on Lookup tables.
public class Person { public int Id { get;set; } public string Forenames {get;set;} public string Surnames { get; set; } public DateTime DateOfBirth {get;set;} public int TeamId { get;set; } public Team Team { get;set; } } public class Team { public int Id { get;set; } public string Name { get;set; } public int DepartmentId { get; set; } public Department { get; set; } } public class Department { public int Id { get; set; } public string Name { get;set; } } /* These two objects would be mapped by a Link table*/ public class TeamManager : Person { public int TeamId { get; set; } } public class DepartmentManager : Person { public int DepartmentId { get; set; } }- Each Person is part of a Team
- Each Team is part of a Department
- Each Team has a Manager
- Each Department has a Manager
There is no data duplication in data base, each relationship between entities is clearly defined.
-
@sweaty_gammon @sweaty_gammon said in The Revival of Great SQL Ideas:
It appears that people are actually rediscovered that actually have a data structure actually makes sense.
I've thought about this. Sometimes you want to specify structures and constraints for your data. Sometimes you don't. Constraints can have obvious advantages both in terms of safety and in terms of efficiency, but they are not always worth the design time. Sometimes you just want to dump a load of objects of varying types there but still be able to work with them as efficiently as possible.
The whole SQL vs NoSQL is a false dichotomy. Any degree of structuredness is valid, and I don't see why you need entirely different softwares to handle each.
I call this the "principle of best effort": ideally, the developer should be able to give the computer system any amount of information about the data it's going to handle, and have the computer system perform as best as possible with it.
As a corollary: any system that does the same thing as another one with less human effort (input) should have some drawback. Otherwise the other system was requiring unnecessary information.
It also works with static vs dynamically typed languages btw. It's why all statically typed languages let you have declare variables as object or even dynamic, because sometimes you just don't know (or care).
-
I don't see it as a dichotomy either. However normally people use NoSQL database because they didn't do any real analysis on what data they were storing or as to why. I've worked with some guys that are straight outta Uni and the reason why they prefer NoSQL is because it makes things "easy", they don't really know how to structure the data etc or they don't understand SQL.
I have found that you rarely don't want constraints for some kind when it comes to some data.
The problem with dynamic languages and their lack of real types past the most basic has been discussed to death. Yeah sure it is quicker when you are hacking something up quick or pretty simple. But it becomes a real PITA as the system gets larger and this includes the frontend. Even typescript doesn't really deal with this well.
-
@Gribnit
Or a version of ANSI SQL that dates from this century.
-
@anonymous234 said in The Revival of Great SQL Ideas:
What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
Sanity.
-
@anonymous234 Some SQL dialects have array types, so you can in fact write it that way. There's nothing inherently wrong with doing so, it's just not standardised or well-supported.
-
@anonymous234 said in The Revival of Great SQL Ideas:
But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why?
To prevent data duplication and other types of errors. It might be very convenient to query a single color and find out what Persons have it as a favorite. And without proper normalization, that might be near-impossible.
I used to work for a GIS company, and GIS data is typically stored in a relational database. It was sometimes quite funny when data was put together by clients who knew nothing about normalization. I remember seeing a manhole layer and one of the fields was "Location". Normally this is a foreign key into another table, but on this one, it was just a normal attribute on the manhole table. And it had dozens, if not hundreds, of variations for each possible value, using different nouns, capitalization, superfluous whitespace, and typographical errors! Then someone built a pie chart using the values of that field, and put it in a presentation on the importance of data normalization. You couldn't make anything out because it had a thousand slices when in actuality there were maybe ten possible options.
If you wanted to know what manholes were in the "middle of the street", you'd have to search for all of the following (and more):
- "middle of the street"
- "middle of street"
- "middle of road"
- "In the middle of the street"
- "middle of street"
- "center of street"
- "center of road"
- "street"
And so on...
-
@anonymous234 said in The Revival of Great SQL Ideas:
I always found SQL to be a bit cargo cultish. I know relational databases are based on specific mathematical principles, but that doesn't mean we always have to do everything the exact same way.
People optimize their code for specific database engine. Database engines get optimized for the code that's most frequently written. After enough time, the only good way is the exact same way as everyone else.
-
@anonymous234 said in The Revival of Great SQL Ideas:
The whole SQL vs NoSQL is a false dichotomy. Any degree of structuredness is valid, and I don't see why you need entirely different softwares to handle each.
But only after enough structuring you end up with data forms that have some very specific mathematical properties which you can then use to write very fast algorithms that perform certain common operations on datasets. SQL vs. NoSQL might be false dichotomy, but the "relational algebra-friendly structures" vs. "just any random structures" dichotomy is real.
-
@mott555 said in The Revival of Great SQL Ideas:
To prevent data duplication and other types of errors. It might be very convenient to query a single color and find out what Persons have it as a favorite. And without proper normalization, that might be near-impossible.
Gratuitous Rosie:
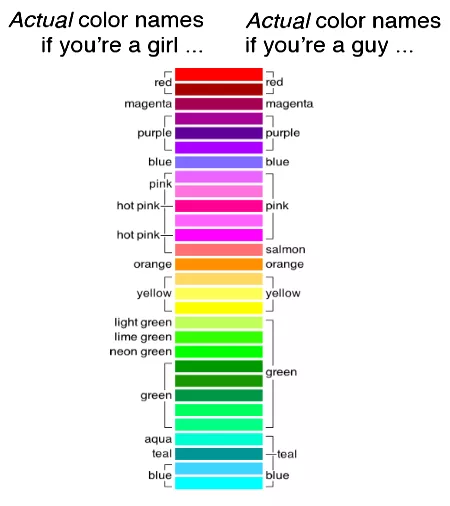
-
@PJH said in The Revival of Great SQL Ideas:
I recalled that as having far fewer names on the male side.
-
@PleegWat said in The Revival of Great SQL Ideas:
I recalled that as having far fewer names on the male side.
You're probably thinking of the one that prompted the survey to which that was the result:
https://blog.xkcd.com/2010/05/03/color-survey-results/
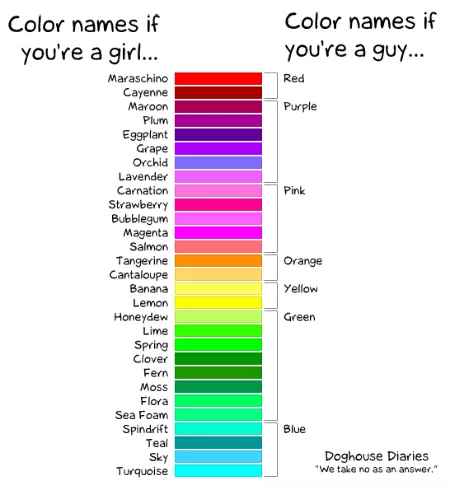
-
@PJH Probably
-
@anonymous234 said in The Revival of Great SQL Ideas:
The whole SQL vs NoSQL is a false dichotomy. Any degree of structuredness is valid, and I don't see why you need entirely different softwares to handle each.
I call this the "principle of best effort": ideally, the developer should be able to give the computer system any amount of information about the data it's going to handle, and have the computer system perform as best as possible with it.
SQL databases have (B|C)LOB and JSON and XML columns. Pick your serialization method and have at it.
-
@boomzilla said in The Revival of Great SQL Ideas:
SQL databases have (B|C)LOB and JSON and XML columns. Pick your serialization method and have at it.
Postgres even has JSONB which allows you to query and edit this data inside the db engine, and even index individual fields inside. It's a lot better than some internally unparsable blob*, but I still avoid it whenever possible.
Bulk updates are always a pain with this sort of data, and in my experience you can't avoid bulk updates, and in most projects bulk-updating, user-facing features will be requested, like "change names of all matching favorite colors from 'magenta' to 'purple'" etc.*People put serialized PHP arrays in a text field in the database. And that's what the most popular framework uses by default to store user's permission groups. Now imagine changing the permission policy for a million users, good luck with that.
-
I know oracle has nested tables and XML. I have not so far been put into a situation where I had to use either.
I did once try to select a nested table column from client-side, just to see if it worked, and gave up when I got errors saying I was opening too many cursors.
-
@PleegWat said in The Revival of Great SQL Ideas:
I got errors saying I was opening too many cursors.
That doesn't surprise me. Perhaps your use case wasn't included in the integration tests.
-
@anonymous234 said in The Revival of Great SQL Ideas:
But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why?
Because at that point, colors are already likely their own entities which have fields other than their name, and...
...back then, the war between hierarchical data models and relational data models had already been fought and won. Hierarchical data models make it relatively difficult to, for example, count how many people like blue, or determine which colors are the least favored, which are effortless queries in a relational model.
-
@Groaner said in The Revival of Great SQL Ideas:
Hierarchical data models make it relatively difficult to, for example, count how many people like blue, or determine which colors are the least favored, which are effortless queries in a relational model.
Ponders a few seconds I'm pretty sure I could do this somewhat easily with a pivot and a few aggregations. Maybe the difficulty is in the CPU power needed to do it?
-
@Tsaukpaetra said in The Revival of Great SQL Ideas:
@Groaner said in The Revival of Great SQL Ideas:
Hierarchical data models make it relatively difficult to, for example, count how many people like blue, or determine which colors are the least favored, which are effortless queries in a relational model.
Ponders a few seconds I'm pretty sure I could do this somewhat easily with a pivot and a few aggregations. Maybe the difficulty is in the CPU power needed to do it?
Oh, it's certainly possible, it's just that you're forced into traversing and scanning each person and then their sets of colors within. If persons and colors are each in their own tables, it's significantly easier to project and/or cut that data as you see fit.
Consider this common pattern/antipattern (depending on who you ask):
Having many separate tables, each containing a different dimension reduces filtering logic to the small dimension tables rather than scanning the massive fact table.
-
@Groaner said in The Revival of Great SQL Ideas:
Having many separate tables, each containing a different dimension reduces filtering logic to the small dimension tables rather than scanning the massive fact table.
Oh, I thought you were talking about using separated tables in the prior post. I seem to have been confused.
-
@anonymous234 said in The Revival of Great SQL Ideas:
But in SQL, as we all know, you have to put the favoriteColors list in its own table and link it back to Person. Why? because some guy said so 47 years ago?. It's not just the same data, it's fundamentally the same data type represented in different ways. What exactly does not allowing me to write it that way offer to the developer or maintainer of a small website?
That guy was pretty smart 47 years ago. Your Person structure as such allows me to specify "elephant", "virgin blood", "fuck you", or "$^@&#$&#^" as my favorite colors.
-
@Cabbage said in The Revival of Great SQL Ideas:
@anonymous234 Some SQL dialects have array types, so you can in fact write it that way. There's nothing inherently wrong with doing so, it's just not standardised or well-supported.
You know, the ANSI SQL past SQL92 is actually a thing, give it try it some time.
-
@sebastian-galczynski said in The Revival of Great SQL Ideas:
*People put serialized PHP arrays in a text field in the database. And that's what the most popular framework uses by default to store user's permission groups. Now imagine changing the permission policy for a million users, good luck with that.
Yay for all the race conditions!
-
@wft said in The Revival of Great SQL Ideas:
Yay for all the race conditions!
It's the lack of utility that is the problem. Storing a serialized type in the DB means that you can't really query against the contents of that type. By comparison, in a JSON-typed column the database does some picking apart of the structure for you behind the scenes (as well as keeping the original JSON document as a value). Similar approaches are used when you've got an unstructured text column that you can do full-text searches against; the DB is doing “clever stuff” behind the curtain.
Race conditions shouldn't be a thing, so long as transactions are used correctly. OK, so a lot of programmers don't know how to do that…
-
@dkf I mean race conditions like these: you read in the whole record, change a subfield, save the whole record. If someone else beats you to it and changes another, otherwise non-conflicting subfield, you undo their changes.
Why? Because you need to specifically program against possible conflicts in every place they may potentially happen, and the number of programmers actually giving a shit about this is dangerously low.
-
@wft if you split read and write into separate transactions, then yes, you have that problem. But why would you ever split read and write into separate transactions?
-
@Gąska said in The Revival of Great SQL Ideas:
@wft if you split read and write into separate transactions, then yes, you have that problem. But why would you ever split read and write into separate transactions?
When the read and write are separate REST calls?
Or any other API where the data leaves your transaction controlled layer.
-
@Carnage then your second transaction should verify if nothing has changed before commit. Yeah, I guess it does technically qualify as having to write special code to prevent that behavior. But you have to do it anyway, regardless of whether the column is XML blob or just a simple integer.
-
@Gąska I fail to see how keeping read and write in the same transaction really helps, except maybe for creating a deadlock which means that someone’s changes are going to be rolled back anyway. There would be no conflict, had the engine been aware of the underlying structure.
-
@dkf said in The Revival of Great SQL Ideas:
Race conditions shouldn't be a thing, so long as transactions are used correctly. OK, so a lot of programmers don't know how to do that…
Given that the answer to only tech question (outside of "what technologies have you used before") on my last job interview was "use a transaction?", I can confirm that it's apparently black magic only the worthy can wield

-
@wft said in The Revival of Great SQL Ideas:
@Gąska I fail to see how keeping read and write in the same transaction really helps
Atomicity anyone?
except maybe for creating a deadlock which means that someone’s changes are going to be rolled back anyway.
Only if you do the locking wrong. AFAIK all major RDBMS do the locking right by default.
There would be no conflict, had the engine been aware of the underlying structure.
It strongly depends on what exactly is the transaction. And with read-read-write on XML field, you prevent exactly the problem you're complaining about, without any extra locks (over what you need to perform the write anyway).
-
@wft said in The Revival of Great SQL Ideas:
That guy was pretty smart 47 years ago. Your Person structure as such allows me to specify "elephant", "virgin blood", "fuck you", or "$^@&#$&#^" as my favorite colors.
"Virgin blood" is a nice color though.
-
Presented in reverse chronological order...
@Gąska said in The Revival of Great SQL Ideas:
But why would you ever split read and write into separate transactions?
@wft said in The Revival of Great SQL Ideas:
the number of programmers actually giving a shit about this is dangerously low.
@Gąska said in The Revival of Great SQL Ideas:
your second transaction should verify if nothing has changed before commit
@wft said in The Revival of Great SQL Ideas:
the number of programmers actually giving a shit about this is dangerously low.
-
@Zecc said in The Revival of Great SQL Ideas:
"Virgin blood" is a nice color though.
@wft said in The Revival of Great SQL Ideas:
the number of programmers actually giving a shit about this is dangerously low.
-
@Gąska you used that word, “atomicity”, without elaborating on it, which makes it semantically equivalent to “magic”, and about just as free of content in this context.
Again. A database holds a serialized representation of composite data. The database knows it’s an opaque blob of bytes. I read it in, and Bob reads it. I modify field A, Bob modifies field B. Then we both serialize what we have back, write it, and commit.
How does atomicity enable us to avoid undoing work of one another?
This is in context of “there are folks who store PHP serializations in TEXT columns”.
-
@wft said in The Revival of Great SQL Ideas:
@Gąska you used that word, “atomicity”, without elaborating on it, which makes it semantically equivalent to “magic”, and about just as free of content in this context.
Because I assumed everyone here knows what atomicity is. It's Databases 101 material. Don't expect me to explain what
printlnortoStringfunctions do either.Again. A database holds a serialized representation of composite data. The database knows it’s an opaque blob of bytes. I read it in, and Bob reads it. I modify field A, Bob modifies field B. Then we both serialize what we have back, write it, and commit.
How does atomicity enable us to avoid undoing work of one another?
You start a transaction. You get exclusive lock for that field/table. Bob starts a transaction. He has to wait for your lock. You read the blob. You modify field A. You serialize it back, write, commit, and end your transaction. Bob gets the lock. Bob reads the blob, modifies field B, serializes it back, writes, commits and ends his transaction. Voila.
-
@Carnage said in The Revival of Great SQL Ideas:
@Gąska said in The Revival of Great SQL Ideas:
@wft if you split read and write into separate transactions, then yes, you have that problem. But why would you ever split read and write into separate transactions?
When the read and write are separate REST calls?
Or any other API where the data leaves your transaction controlled layer.Then you need to push some "version" identifier to the REST API consumer and require that they pass it back when they update something. The HTTP ETag can be used for that.
-
@wft said in The Revival of Great SQL Ideas:
@Gąska I fail to see how keeping read and write in the same transaction really helps, except maybe for creating a deadlock which means that someone’s changes are going to be rolled back anyway. There would be no conflict, had the engine been aware of the underlying structure.
That's exactly how optimistic concurrency control works. Also, had the underlying structure be split you still might want a rollback of the second modification; who says it is still correct when another subfield got modified?
-
@Gąska said in The Revival of Great SQL Ideas:
You start a transaction. You get exclusive lock for that field/table. Bob starts a transaction. He has to wait for your lock. You read the blob. You modify field A. You serialize it back, write, commit, and end your transaction. Bob gets the lock. Bob reads the blob, modifies field B, serializes it back, writes, commits and ends his transaction. Voila.
I know what web scale is. What scale does this translate into?
-
@boomzilla said in The Revival of Great SQL Ideas:
@Gąska said in The Revival of Great SQL Ideas:
You start a transaction. You get exclusive lock for that field/table. Bob starts a transaction. He has to wait for your lock. You read the blob. You modify field A. You serialize it back, write, commit, and end your transaction. Bob gets the lock. Bob reads the blob, modifies field B, serializes it back, writes, commits and ends his transaction. Voila.
I know what web scale is. What scale does this translate into?
"Major pain in the ass" scale, especially when your application forgets to give up the lock due to an unexpected crash.
 Star schema - Wikipedia
Star schema - Wikipedia
