Why are Linux debug builds of my C++ app so big?
-
Build type: Release
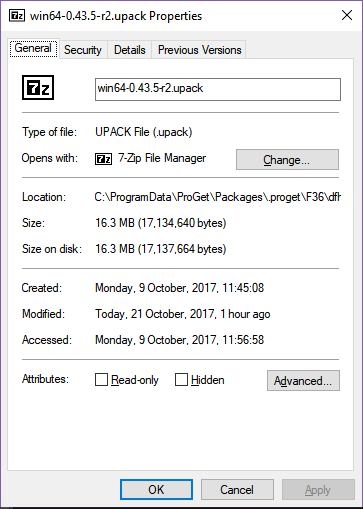
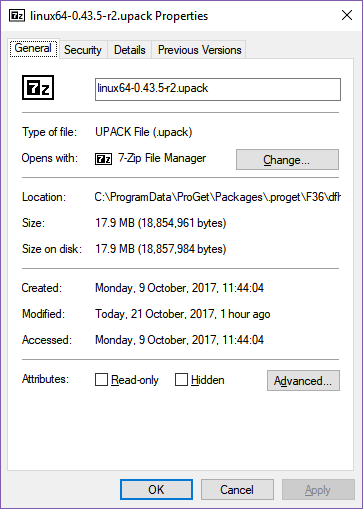
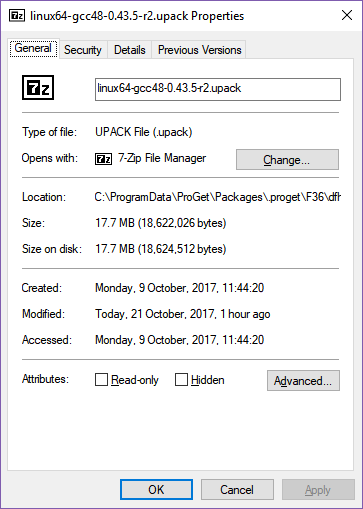
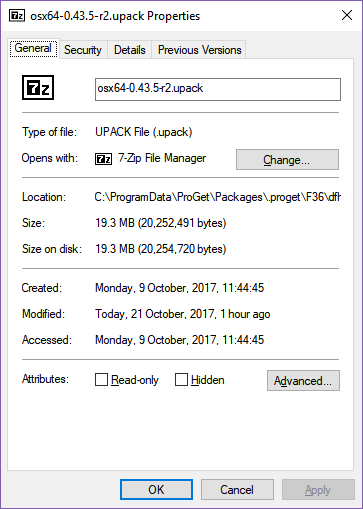
Build type: RelWithDebInfo
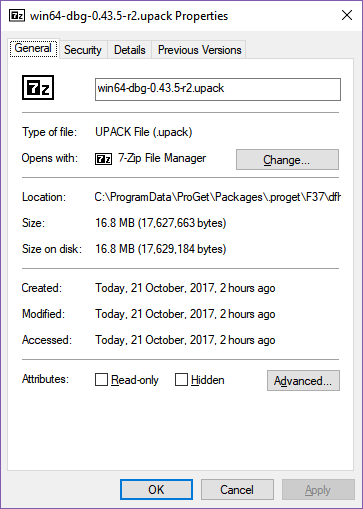
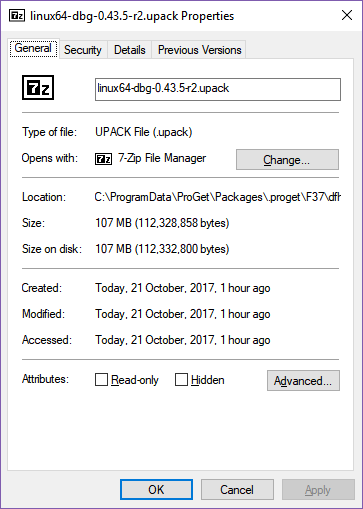
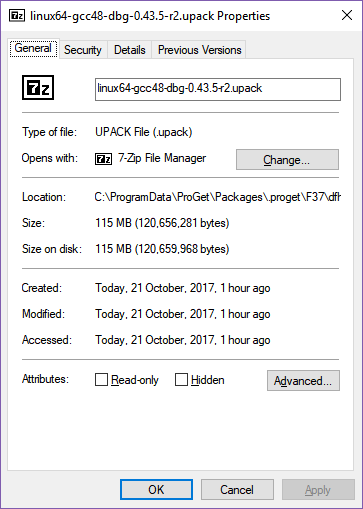
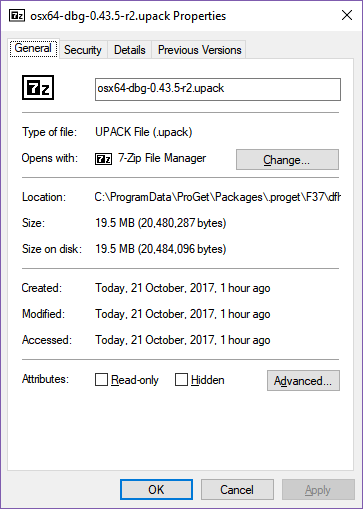
The Windows build gains half a megabyte, the Linux builds gain 90-100 megabytes, and the OS X build gains a quarter of a megabyte. What could be causing such a big increase in the Linux size but not the other two OSes?
Source code here if anyone wants to reproduce it for themselves.
-
@ben_lubar said in Why are Linux debug builds of my C++ app so big?:
What could be causing such a big increase in the Linux size but not the other two OSes?
Static linking of libraries would be my #1 suspicion. That can blow up the size of builds a lot.
-
@dkf said in Why are Linux debug builds of my C++ app so big?:
@ben_lubar said in Why are Linux debug builds of my C++ app so big?:
What could be causing such a big increase in the Linux size but not the other two OSes?
Static linking of libraries would be my #1 suspicion. That can blow up the size of builds a lot.
ben@australium:~/df/bigbuild$ readelf -S -W rel/package/hack/libdfhack.so There are 32 section headers, starting at offset 0xa569b0: Section Headers: [Nr] Name Type Address Off Size ES Flg Lk Inf Al [ 0] NULL 0000000000000000 000000 000000 00 0 0 0 [ 1] .note.gnu.build-id NOTE 0000000000000200 000200 000024 00 A 0 0 4 [ 2] .gnu.hash GNU_HASH 0000000000000228 000228 01ab08 00 A 3 0 8 [ 3] .dynsym DYNSYM 000000000001ad30 01ad30 05a660 18 A 4 3 8 [ 4] .dynstr STRTAB 0000000000075390 075390 0b8906 00 A 0 0 1 [ 5] .gnu.version VERSYM 000000000012dc96 12dc96 007888 02 A 3 0 2 [ 6] .gnu.version_r VERNEED 0000000000135520 135520 0001c0 00 A 4 7 8 [ 7] .rela.dyn RELA 00000000001356e0 1356e0 226b18 18 A 3 0 8 [ 8] .rela.plt RELA 000000000035c1f8 35c1f8 015c60 18 AI 3 25 8 [ 9] .init PROGBITS 0000000000371e58 371e58 00001a 00 AX 0 0 4 [10] .plt PROGBITS 0000000000371e80 371e80 00e850 10 AX 0 0 16 [11] .plt.got PROGBITS 00000000003806d0 3806d0 000358 00 AX 0 0 8 [12] .text PROGBITS 0000000000380a30 380a30 283ca9 00 AX 0 0 16 [13] .fini PROGBITS 00000000006046dc 6046dc 000009 00 AX 0 0 4 [14] .rodata PROGBITS 0000000000604700 604700 05cb60 00 A 0 0 32 [15] .eh_frame_hdr PROGBITS 0000000000661260 661260 0177b4 00 A 0 0 4 [16] .eh_frame PROGBITS 0000000000678a18 678a18 07ad64 00 A 0 0 8 [17] .gcc_except_table PROGBITS 00000000006f377c 6f377c 01140a 00 A 0 0 4 [18] .tbss NOBITS 0000000000904d10 704d10 000004 00 WAT 0 0 16 [19] .init_array INIT_ARRAY 0000000000904d10 704d10 000278 00 WA 0 0 8 [20] .fini_array FINI_ARRAY 0000000000904f88 704f88 000008 00 WA 0 0 8 [21] .jcr PROGBITS 0000000000904f90 704f90 000008 00 WA 0 0 8 [22] .data.rel.ro PROGBITS 0000000000904fa0 704fa0 0d5410 00 WA 0 0 32 [23] .dynamic DYNAMIC 00000000009da3b0 7da3b0 000260 10 WA 4 0 8 [24] .got PROGBITS 00000000009da610 7da610 0079e0 08 WA 0 0 8 [25] .got.plt PROGBITS 00000000009e2000 7e2000 007438 08 WA 0 0 8 [26] .data PROGBITS 00000000009e9440 7e9440 071f08 00 WA 0 0 32 [27] .bss NOBITS 0000000000a5b360 85b348 055188 00 WA 0 0 32 [28] .comment PROGBITS 0000000000000000 85b348 000023 01 MS 0 0 1 [29] .shstrtab STRTAB 0000000000000000 a56895 00011b 00 0 0 1 [30] .symtab SYMTAB 0000000000000000 85b370 099660 18 31 10755 8 [31] .strtab STRTAB 0000000000000000 8f49d0 161ec5 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), l (large) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)ben@australium:~/df/bigbuild$ readelf -S -W dbg/package/hack/libdfhack.so There are 39 section headers, starting at offset 0x325fdd0: Section Headers: [Nr] Name Type Address Off Size ES Flg Lk Inf Al [ 0] NULL 0000000000000000 000000 000000 00 0 0 0 [ 1] .note.gnu.build-id NOTE 0000000000000200 000200 000024 00 A 0 0 4 [ 2] .gnu.hash GNU_HASH 0000000000000228 000228 01abcc 00 A 3 0 8 [ 3] .dynsym DYNSYM 000000000001adf8 01adf8 05ab40 18 A 4 3 8 [ 4] .dynstr STRTAB 0000000000075938 075938 0ba53c 00 A 0 0 1 [ 5] .gnu.version VERSYM 000000000012fe74 12fe74 0078f0 02 A 3 0 2 [ 6] .gnu.version_r VERNEED 0000000000137768 137768 0001c0 00 A 4 7 8 [ 7] .rela.dyn RELA 0000000000137928 137928 226ed8 18 A 3 0 8 [ 8] .rela.plt RELA 000000000035e800 35e800 016128 18 AI 3 25 8 [ 9] .init PROGBITS 0000000000374928 374928 00001a 00 AX 0 0 4 [10] .plt PROGBITS 0000000000374950 374950 00eb80 10 AX 0 0 16 [11] .plt.got PROGBITS 00000000003834d0 3834d0 000358 00 AX 0 0 8 [12] .text PROGBITS 0000000000383830 383830 26d027 00 AX 0 0 16 [13] .fini PROGBITS 00000000005f0858 5f0858 000009 00 AX 0 0 4 [14] .rodata PROGBITS 00000000005f0880 5f0880 05f6b0 00 A 0 0 32 [15] .eh_frame_hdr PROGBITS 000000000064ff30 64ff30 017c04 00 A 0 0 4 [16] .eh_frame PROGBITS 0000000000667b38 667b38 07bb64 00 A 0 0 8 [17] .gcc_except_table PROGBITS 00000000006e369c 6e369c 0116e6 00 A 0 0 4 [18] .tbss NOBITS 00000000008f5bd8 6f5bd8 000004 00 WAT 0 0 4 [19] .init_array INIT_ARRAY 00000000008f5bd8 6f5bd8 000278 00 WA 0 0 8 [20] .fini_array FINI_ARRAY 00000000008f5e50 6f5e50 000008 00 WA 0 0 8 [21] .jcr PROGBITS 00000000008f5e58 6f5e58 000008 00 WA 0 0 8 [22] .data.rel.ro PROGBITS 00000000008f5e60 6f5e60 0d5410 00 WA 0 0 32 [23] .dynamic DYNAMIC 00000000009cb270 7cb270 000260 10 WA 4 0 8 [24] .got PROGBITS 00000000009cb4d0 7cb4d0 007b20 08 WA 0 0 8 [25] .got.plt PROGBITS 00000000009d3000 7d3000 0075d0 08 WA 0 0 8 [26] .data PROGBITS 00000000009da5e0 7da5e0 071e68 00 WA 0 0 32 [27] .bss NOBITS 0000000000a4c460 84c448 054f18 00 WA 0 0 32 [28] .comment PROGBITS 0000000000000000 84c448 000023 01 MS 0 0 1 [29] .debug_aranges PROGBITS 0000000000000000 84c46b 006e30 00 0 0 1 [30] .debug_info PROGBITS 0000000000000000 85329b 1d5e09c 00 0 0 1 [31] .debug_abbrev PROGBITS 0000000000000000 25b1337 0399c0 00 0 0 1 [32] .debug_line PROGBITS 0000000000000000 25eacf7 08957b 00 0 0 1 [33] .debug_str PROGBITS 0000000000000000 2674272 53a7a9 01 MS 0 0 1 [34] .debug_loc PROGBITS 0000000000000000 2baea1b 3a4a27 00 0 0 1 [35] .debug_ranges PROGBITS 0000000000000000 2f53442 108f90 00 0 0 1 [36] .shstrtab STRTAB 0000000000000000 325fc56 000174 00 0 0 1 [37] .symtab SYMTAB 0000000000000000 305c3d8 09ae90 18 38 10961 8 [38] .strtab STRTAB 0000000000000000 30f7268 1689ee 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), l (large) I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)The
.debug_infosection seems to be the largest at 30,793,884 bytes. The executable code (.text) seems to only be about 100kB larger.
-
@ben_lubar Hmm, yes. OSX tends to put debug information into a separate
filedirectory, blah.dSYM. Maybe Windows does something similar? (I haven't had a build chain for that platform for a very long time.)The
.debug_str,.debug_locand.debug_rangessections look pretty chunky too.
-
@dkf Linux can use separate debug info as well, but that's a separate step. The compiler initially puts it all in one file.
One of the things linux includes in the debug info is a cross-reference between ranges of compiled instruction and the file names and line numbers they originate from - I expect that can be pretty large.
I think more recent versions store macro expansions as well - depending on your codebase, I can see that getting big as well depending on your codebase.
-
@dkf said in Why are Linux debug builds of my C++ app so big?:
Maybe Windows does something similar?
Yes, .pdb files.
-
Ok, it looks like two things are going wrong here:
- Linux debug symbols are not being split into separate files
- Windows and OS X packages do not include debug symbols
I'm going to split the debug symbols into a separate package for all 3 OSes and hopefully that'll fix both the problem of the build being huge and the problem of Mac and Windows builds being useless for debugging.
-
@ben_lubar said in Why are Linux debug builds of my C++ app so big?:
Ok, it looks like two things are going wrong here:
- Linux debug symbols are not being split into separate files
Oh, you can do that? Do you know how?
Does that mean you have a lib that is the same for debug/release and the debug symbols in another file (directory, whatever) next to it, or does the lib still have to be debug or release (not both at the same time)?
My understanding is that this is how Windows works, the DLL is either debug or release, but the debugging symbols are in a different file -- which IMO makes it somewhat useless, why would you go to the pain of making/distributing a debug DLL if not for the debug symbols?
-
@remi The way we've got it, there's only one production build, and debug symbols go in a separate RPM. If the SO is in
/usr/lib/libfrob.sothen the debug symbols are in/usr/lib/debug/usr/lib/libfrob.so.debug. Relevant tools load this automatically.I'm not sure how the debug symbols get extracted - rpm does this for us.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
Oh, you can do that? Do you know how?
IIRC, you split out the debug symbols from an object file after compilation. It's been a while; this (warning: SO) seems to summarize the process (first thee lines of code in the post).
@remi said in Why are Linux debug builds of my C++ app so big?:
Does that mean you have a lib that is the same for debug/release and the debug symbols in another file (directory, whatever) next to it, or does the lib still have to be debug or release (not both at the same time)?
It depends a bit what you mean with debug/release builds. Debug builds traditionally disable optimization and generate debug symbols, whereas a traditional release build enables optimization but doesn't generate debug information.
There's nothing preventing you from doing something in between, i.e. a build with optimization and with debug info (something like
gcc -O2 -g ...). From there you could split out the debug symbols into a separate file and ship the library and the symbols separately. (General caveats apply - debugging info may be less accurate for optimized builds etc etc.)But you generally can't use debug symbols from an unoptimized (or otherwise different) build for a optimized one, or vice-versa.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
My understanding is that this is how Windows works, the DLL is either debug or release, but the debugging symbols are in a different file -- which IMO makes it somewhat useless, why would you go to the pain of making/distributing a debug DLL if not for the debug symbols?
When you've fully tested your DLL, you can just ship the same file you just tested. Just omit the .pdb.
The Linux way is actually weirder, because it pretty much guarantees that it's impossible to ship the actual library you just finished testing-- you have to make a new build of it and ship a file with a different hash.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
why would you go to the pain of making/distributing a debug DLL if not for the debug symbols?
You're supposed to ship like yesterday, but the release build keeps on crashing because nobody ever tested that one (and now nobody has time to do so). So, you just ship the debug build without the symbols.
Filed under: Industry "best" practices.
-
@cvi @blakeyrat I think that what confused me is that we (usually) mean two things by "debug". One is having the symbols, and the other is, as @cvi said, different compilation options (usually no or less optimization than in release).
I would expect tests to be done initially with a debug version, i.e. no optimization and symbols included, so you can actually debug easily. Then as you move closer to release (or pass to the next team in the chain, whatever your procedure is), I expect you would switch to a release version, i.e. optimized. My assumption is that, at that stage, symbols are somewhat useless, unless you stumble onto a bug that only exists in the release version (not the debug one) -- which does happen but is certainly not the most frequent case! So that optimized version can also do without the symbols, because most of the time they'll be useless. And then of course when you ship, you don't ship symbols.
So while I can understand building a debug (non-optimized) version without the symbols (to save space when distributing to testers/other a version with some checks in the code itself), I don't really see a use case for a release version with symbols. In the end, I feel that having the symbols separately is less useful than I thought initially.
-
@remi If you ever run into segmentation faults in production, you certainly want symbols to be around so you can debug the core dumps though.
I generally haven't found optimisation to be that big a hurdle to debugging, but that may just be gcc's optimiser not being all that aggressive, combined with me not using the debugger often.
-
@remi You go to TEST with a Release build AND the corresponding .pdb files so you get more information in your exception logging. Then you go to PROD with the same Release build, omitting the .pdb files
-
@remi I don't think the debug information in release builds is quite as useless as you seem make them out to be. It's more like certain variables have been optimized away (so you can't easily see their values), and single instructions don't necessarily map to a specific statement/LOC any more. On a (non-inlined) function level, you're still good, typically -- meaning that a stack trace will still be able to show you each function's name and source location (instead of just a pile of addresses).
The other major use case is profiling. If you profile with something like
perf, it'll resolve the recorded addresses against the symbol information. But profiling a non-optimized build rarely makes a lot of sense.
-
@pleegwat said in Why are Linux debug builds of my C++ app so big?:
If you ever run into segmentation faults in production, you certainly want symbols to be around so you can debug the core dumps though.
Good point. I was actually thinking about something like a desktop application that is sold and deployed to users potentially anywhere in the world, so it's unlikely that you'll ever get usable coredumps (trying to get a user to send you one is, in my experience, not straightforward to say the least...). But for server apps where you can easily access the running version of the program, yeah, that makes sense.
@cvi said in Why are Linux debug builds of my C++ app so big?:
The other major use case is profiling.
Also a good point, yes. I forgot about that.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
Good point. I was actually thinking about something like a desktop application that is sold and deployed to users potentially anywhere in the world, so it's unlikely that you'll ever get usable coredumps (trying to get a user to send you one is, in my experience, not straightforward to say the least...).
You mean like Windows? Microsoft makes symbols for their release builds publicly available and demonstrates the solved answer to this problem: Get the system to send you the dump rather than the user, or at least get it to package it up in a .zip file with a neat little bow instead of trying to talk the user through it.
-
@heterodox Maybe MS has the patience and resources to make it work, but I know that at my level, I can't. It's sometimes hard enough to get a client to send us something as basic as a snapshot (dumb users), or to find a way through layers of firewalls to exchange one tiny text file (paranoid companies), so a potentially large and full of information coredump? Forget about it...
-
@bjolling said in Why are Linux debug builds of my C++ app so big?:
@remi Then you go to PROD with the same Release build, omitting the .pdb files
Why omit the PDB files? Is saving disk space really worth throwing away that potential information source for when something does go wrong?
-
@remi FWIW, there are tools to print out (or log) stack traces and similar at runtime (I've used backward with some success). Getting somebody to send you a human-readable log file might be easier than a core dump, as you mention. However, for the full printouts, it also relies on debug symbols.
It should be possible to change e.g. backward so you can resolve symbols later, and there might (of course) be other options that do this for you already.
-
@remi A better idea is to just never use C++ which is a shitty language and code in something where the debug builds have all the same optimizations, and also where optimizations don't break shit.
-
@blakeyrat It might be better, but it won't happen. I might as well wish for magic pixie dust to sprinkle on my code to make all bugs go away.
-
@cvi said in Why are Linux debug builds of my C++ app so big?:
I don't think the debug information in release builds is quite as useless as you seem make them out to be. It's more like certain variables have been optimized away (so you can't easily see their values), and single instructions don't necessarily map to a specific statement/LOC any more. On a (non-inlined) function level, you're still good, typically -- meaning that a stack trace will still be able to show you each function's name and source location (instead of just a pile of addresses).
Inlining tends to be not a problem, as the debug info just says “hey, these instructions came from an inlined function”. The real problem (apart from the fact that variables and statements may simply be optimised out entirely) is that code paths may be merged, so a particular instruction may have multiple discontiguous associated source line numbers. That sort of thing is more prevalent at the higher optimisation levels, and it tends to be confusing as heck to ordinary programmers.
-
@dkf Yeah. This is especially interesting when one tries to set a breakpoint on a certain line in the source, but code from said line is spread all over the place.
-
@heterodox That's easily solved. Make your applicatoin detect a segfault and handle it. You don't have to have your users do more than click on a button to send the core dump. Even that click is not strictly necessary - but it is poite to ask seeing as how it might contain sensitive information.
-
@dkf said in Why are Linux debug builds of my C++ app so big?:
@cvi said in Why are Linux debug builds of my C++ app so big?:
I don't think the debug information in release builds is quite as useless as you seem make them out to be. It's more like certain variables have been optimized away (so you can't easily see their values), and single instructions don't necessarily map to a specific statement/LOC any more. On a (non-inlined) function level, you're still good, typically -- meaning that a stack trace will still be able to show you each function's name and source location (instead of just a pile of addresses).
Inlining tends to be not a problem, as the debug info just says “hey, these instructions came from an inlined function”.
Inlining is mainly a problem if you call the same inlined function multiple times from one parent; since the code location points to the inlined function doesn't have its own stack frame, you don't get the line number in the parent function in the stack trace (at least not in my gcc/gdb combo) so you don't know which invocation is causing the error. Getting at the local variables of the calling function in a core dump can also be tricky.
-
@martijntje said in Why are Linux debug builds of my C++ app so big?:
@heterodox That's easily solved. Make your applicatoin detect a segfault and handle it. You don't have to have your users do more than click on a button to send the core dump. Even that click is not strictly necessary - but it is poite to ask seeing as how it might contain sensitive information.
Think you meant to direct that to @remi; I didn't assert it was particularly difficult.
-
@pleegwat said in Why are Linux debug builds of my C++ app so big?:
Inlining is mainly a problem if you call the same inlined function multiple times from one parent; since the code location points to the inlined function doesn't have its own stack frame, you don't get the line number in the parent function in the stack trace (at least not in my gcc/gdb combo) so you don't know which invocation is causing the error. Getting at the local variables of the calling function in a core dump can also be tricky.
That sounds like a gcc problem; the actual debug metadata format supports that sort of thing unambiguously.
-
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
guarantees that it's impossible
Windows builds have debug information separate by default but it can be included in the executable.
Linux builds have debug information included in the executable by default but it can be separated.
Mac OS X builds have debug information sitting somewhere on the filesystem and it'll get lost if you don't rundsymutilon the executable to make a folder with some bullshit in it.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
One is having the symbols, and the other is, as @cvi said, different compilation options (usually no or less optimization than in release).
Due to some technical constraints, there is no "Debug" build of DFHack, only Release and RelWithDebInfo. As far as I can tell, it has something to do with Windows using a different ABI for some thing that DFHack needs to modify at runtime.
-
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
When you've fully tested your DLL, you can just ship the same file you just tested. Just omit the .pdb.
The Linux way is actually weirder, because it pretty much guarantees that it's impossible to ship the actual library you just finished testing-- you have to make a new build of it and ship a file with a different hash.No, Linux is the same. The only difference is that after you run the compiler, you must run strip to split the
.soor binary to the actual code and debug symbol parts. Then you proceed like on Windows.The Windows process also has the disadvantage that all the compilers, while writing different
.objfiles, are all writing the debug information into one.pdb, which slows things down. It is also managed by a separate process that sometimes causes problems on build servers. It also prevents things likedistcc.
-
@bulb said in Why are Linux debug builds of my C++ app so big?:
The only difference is that after you run the compiler, you must run strip to split the
.soor binary to the actual code and debug symbol parts.No. Debug symbols don't need to be inside the same binary as the executable code.Edit: Ugh, misread your post. The link is still relevant, though.
-
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
When you've fully tested your DLL, you can just ship the same file you just tested. Just omit the .pdb.
The Linux way is actually weirder, because it pretty much guarantees that it's impossible to ship the actual library you just finished testing-- you have to make a new build of it and ship a file with a different hash.Actually, Linux is even better. On Windows, the system libraries have separate debug and release versions. And you can't mix them in a single executable. So you can build a release DLL with debug symbols, or you can build a debug DLL and you often have to build both depending on how the other DLLs the user needs to link it with are compiled.
On the other hand, on Linux, most distributions ship standard libraries in exactly the way you described for Windows. So there you only ever need the one optimized-with-detached-debug-symbols build.
-
@remi said in Why are Linux debug builds of my C++ app so big?:
@heterodox Maybe MS has the patience and resources to make it work, but I know that at my level, I can't. It's sometimes hard enough to get a client to send us something as basic as a snapshot (dumb users), or to find a way through layers of firewalls to exchange one tiny text file (paranoid companies), so a potentially large and full of information coredump? Forget about it...
Linux distributions have tools that take care of those things too and KDE has its own.
@cvi said in Why are Linux debug builds of my C++ app so big?:
It should be possible to change e.g. backward so you can resolve symbols later, and there might (of course) be other options that do this for you already.
I believe the Debian or Ubuntu tools can pull in the
-dbgpackages themselves (with user confirmation).@unperverted-vixen said in Why are Linux debug builds of my C++ app so big?:
@bjolling said in Why are Linux debug builds of my C++ app so big?:
@remi Then you go to PROD with the same Release build, omitting the .pdb files
Why omit the PDB files? Is saving disk space really worth throwing away that potential information source for when something does go wrong?
The trouble with Windows is that they don't normally provide core-dumps (though I believe they can be persuaded to). With core dump, you can pull in the debug symbols ex-post and analyse it at your leisure.
-
@ben_lubar said in Why are Linux debug builds of my C++ app so big?:
@remi said in Why are Linux debug builds of my C++ app so big?:
One is having the symbols, and the other is, as @cvi said, different compilation options (usually no or less optimization than in release).
Due to some technical constraints, there is no "Debug" build of DFHack, only Release and RelWithDebInfo. As far as I can tell, it has something to do with Windows using a different ABI for some thing that DFHack needs to modify at runtime.
Yes, in Windows there are separate Debug and Release runtimes that are incompatible and can't be mixed within a process.
You don't really need Release either. Just build everything RelWithDebInfo, separate the symbols and provide them as separate download corresponding to each package. That way you—or users—don't have to reinstall the binaries when you need to do some bug triage and you can analyse already captured coredumps. Debian has been doing it for most packages for quite a few years and it works pretty well.
-
@bulb said in Why are Linux debug builds of my C++ app so big?:
@remi said in Why are Linux debug builds of my C++ app so big?:
@heterodox Maybe MS has the patience and resources to make it work, but I know that at my level, I can't. It's sometimes hard enough to get a client to send us something as basic as a snapshot (dumb users), or to find a way through layers of firewalls to exchange one tiny text file (paranoid companies), so a potentially large and full of information coredump? Forget about it...
Linux distributions have tools that take care of those things too and KDE has its own.
(and that's more or less the point made by @martijntje as well)
It's not really a question of having a one-click-sends-the-coredump.
Core dumps with the software I work with will typically be at least a few 100's MB, more likely several GB (and can be up to 100's GB in some cases). Also, most users are in large companies who have stupid IT policies. Their computers might not be connected to the net (yes, that exists... and not only in the defence industry), or they might need to pass several layers of firewall to get to the outside. Their policy may also prevent them from sending any data if not through some approved channels. It might also prevent them from installing any program that communicates with any remote server. Some clients are also prevented by law to send any data outside of their country.
So, while we could have some automated system, it's unlikely it would really help much, and it would probably create more problems than it solves, either to sell/install the software (having to configure network access, or to convince the clients that this violation of their policies is actually good for them) or when using it (such as clogging the network while trying to send 10 coredumps at the same time because the user in a remote location saw the application crash and restarted it 10 times, only to make it crash each time).
-
@bulb said in Why are Linux debug builds of my C++ app so big?:
I believe the Debian or Ubuntu tools can pull in the -dbg packages themselves (with user confirmation).
Depending on the situation, it's probably more useful if your users don't have to pull in -dbg packages or similar, and you can instead resolve the names at a later stage yourself based on a relatively lightweight stack trace. (That's assuming you can't get your hands on full core dumps.)
Sure, there's less information in the stack trace, but it's more email-friendly than a full core dump, and it's somewhat human readable so it might be easier to convince people that they're not leaking all sorts of confidential information all over the place. And it gives you a bit of information on where to start looking for problems, rather than just wild guesses and conjecture.
-
@cvi The problem is that you need the debug symbols with the core dump to generate detailed backtrace.
Android does generate backtrace without much details and can fill in some later with the debug symbols (Android build tools separate the debug symbols automatically and never put them in the
.apk), but it can never fill in as much.So these tools download the debug package (because the package manager that can do that is already in place, and most users have faster download than upload these days), generate a detailed backtrace and attach that to the bug report.
-
@bulb said in Why are Linux debug builds of my C++ app so big?:
The problem is that you need the debug symbols with the core dump to generate detailed backtrace.
No core dumps are involved. Backward (the library I mentioned above) is a library that generates a stack trace by walking the stack at runtime. One special case is that you do this from a SIGSEGV/BUS (but you could do it elsewhere too).
The default behaviour of the library is to then immediately pretty-print the stack trace by looking up debug information at runtime, and matching the addresses from the stack trace to function/symbol names and if possible even against the sources (so it'll actually print the source line + a bit of context). This is the way I use it currently.
Looking at the source code of backward, it seems like it should be possible to omit the pretty-printing step, and essentially just record the addresses from walking the stack (plus maybe some information to deal with relocatable stuff) in a log; this doesn't need any debug symbols or so. Then, later (on a different machine etc), you match up the addresses against names/source locations using the debug information that you have (hopefully for that exact build).
I've not done the second part, so I can't guarantee that it's possible (if not, I'm interested in why). It's on my list of stuff to try out (and has been there for a while).
Android does generate backtrace without much details and can fill in some later with the debug symbols (Android build tools separate the debug symbols automatically and never put them in the .apk), but it can never fill in as much
Hmm. OK. Sounds like what I want to do.
It's been a while since I looked at Android stack traces. What's missing?
-
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
The Linux way is actually weirder, because it pretty much guarantees that it's impossible to ship the actual library you just finished testing-- you have to make a new build of it and ship a file with a different hash.
Your ability to be wrong is truly breathtaking.
-
@bulb said in Why are Linux debug builds of my C++ app so big?:
The Windows process also has the disadvantage that all the compilers, while writing different .obj files, are all writing the debug information into one .pdb, which slows things down. It is also managed by a separate process that sometimes causes problems on build servers. It also prevents things like distcc.
Again I must note that this is only the case when using shitty languages that suck.
-
@gwowen said in Why are Linux debug builds of my C++ app so big?:
Your ability to be wrong is truly breathtaking.
Isn't it.
-
@cvi said in Why are Linux debug builds of my C++ app so big?:
@bulb said in Why are Linux debug builds of my C++ app so big?:
I believe the Debian or Ubuntu tools can pull in the -dbg packages themselves (with user confirmation).
Depending on the situation, it's probably more useful if your users don't have to pull in -dbg packages or similar, and you can instead resolve the names at a later stage yourself based on a relatively lightweight stack trace. (That's assuming you can't get your hands on full core dumps.)
Sure, there's less information in the stack trace, but it's more email-friendly than a full core dump, and it's somewhat human readable so it might be easier to convince people that they're not leaking all sorts of confidential information all over the place. And it gives you a bit of information on where to start looking for problems, rather than just wild guesses and conjecture.
I've had to do this. The product includes a helper script that prints a detailed back trace for all threads as well as the link map. If need be, I can use this to manually resolve symbols.
I don't particularly want to download 50gb core dumps over our 10mbit office line.
-
@pleegwat said in Why are Linux debug builds of my C++ app so big?:
as well as the link map
How do you get hold of this?
I did some quick googling, and it seems that you could call
dlinfo()withRTLD_DI_LINKMAP. You'd need a handle to each shared object (I'm not quite sure how to get this). Alternatively, the returned structure seems to include a linked list, so perhaps it's sufficient to call this once on the main program (i.e.,dlopen(NULL)) and then just walk the list? The other option seems to be withdl_iterate_phdr()...I'll have to quickly try this tomorrow, I guess.
-
@cvi It's a script. It calls gdb on the core dump. Getting that installed hasn't generally been a problem.
I can give you the exact gdb instruction needed tomorrow.
-
@pleegwat said in Why are Linux debug builds of my C++ app so big?:
I can give you the exact gdb instruction needed tomorrow.
That would be cool. :-)
I'll probably end up looking at doing it directly from within the binary automagically at some point (being able to programmatically capture a stack trace at will has been useful). But having something to compare against would certainly be helpful.
-
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
@bulb said in Why are Linux debug builds of my C++ app so big?:
The Windows process also has the disadvantage that all the compilers, while writing different .obj files, are all writing the debug information into one .pdb, which slows things down. It is also managed by a separate process that sometimes causes problems on build servers. It also prevents things like distcc.
Again I must note that this is only the case when using shitty languages that suck.
What, in your opinion, is an example of a non-shitty systems language that doesn't suck?
-
@pie_flavor said in Why are Linux debug builds of my C++ app so big?:
@blakeyrat said in Why are Linux debug builds of my C++ app so big?:
@bulb said in Why are Linux debug builds of my C++ app so big?:
The Windows process also has the disadvantage that all the compilers, while writing different .obj files, are all writing the debug information into one .pdb, which slows things down. It is also managed by a separate process that sometimes causes problems on build servers. It also prevents things like distcc.
Again I must note that this is only the case when using shitty languages that suck.
What, in your opinion, is an example of a non-shitty systems language that doesn't suck?
Trick question. All languages suck.
-
@pie_flavor said in Why are Linux debug builds of my C++ app so big?:
What, in your opinion, is an example of a non-shitty systems language that doesn't suck?
I don't know that there are any.