How do you get an impossible to fix (completely) bug? Just follow me...
-
For those TDWTFians that aren't already aware, I work for a railroad, dealing with various tools used to munge various bits and bobs of data into the screens that will be used by our train dispatchers (US term -- UK dwellers call 'em signalmen, but it's really the exact same job) when the overall system I'm dealing with goes to production.
One of the things that train dispatchers must do in the course of their job is issue what are called "bulletins" to train crews warning them of track conditions up ahead:
- Patches of damaged track, etc. that must be traversed at a reduced speed in order to cross them safely
- Workmen operating on or near the track (the train crew must radio the work gang and ask their foreman for permission to cross the work site)
- Any other condition that impacts safety (footing issues, faulty grade crossings, outsized loads whether on the rails or crossing the tracks via road, ...)
Railroad operating rules specify that when a a bulletin is put out, it is put out by specifying the name of the track it applies to, and the start and end mileposts of the section that's damaged or being worked on, rather like a 411 report that says that Highway 19 is one lane between mileposts 30 and 40 due to resurfacing work. Also, just like how a street or highway name can change at an intersection, the name of a track can change at a switch -- more precisely, at the point of switch of the switch, where the paths actually diverge.
Unfortunately, though, the system I work on was originally written to apply track names to track objects, which can only have one name. This is a problem because of what I just said above -- the track name can and will change at a switch; furthermore, you use a different name to refer to an OS track when the switch is reverse (usually the bent path), as opposed to the default name for that (on-station or OS) track, which corresponds to the normal (usually straight) path.
This led to a bug-fight (over a single issue, mind you -- that issue number has become immortalized among significant portions of the team as a result) that lasted over a year and costed untold amounts of money, where they insisted that issuing a bulletin up to the point of switch of a switch or even figuring out which parts of the track received which names was utterly impossible, while a couple of my coworkers worked out case after case in mind-numbing detail, taking the most insane track layouts they could find on the railroad and going through every single possible path through them to assign which parts received which track name, depending on which switches were in what position.
Eventually, my coworkers devised a rather nasty algorithm that handles most of the simple cases, assigning track names to various parts of the paths and tracks that make up the railroad's junctions automatically based on the names of the tracks surrounding the junction; complicated parts of the railroad are still hand-finessed into shape, though, as they are rare enough that it was considered not worthwhile to automate them.
Unfortunately, the importer that brings in the mileposts where switches are located at was not updated to match this change, despite years having passed since the original fix was implemented. Worse yet, the incoming data feed it imports from relies on these track names in order to match switch milepost records up to the corresponding tracks the switch is connected to, and the algorithm that handles putting names on these OS tracks requires the milepost locations of switches in order to function correctly, leading to a catch-22 that forced the milepost location of every dispatcher-controllable switch on the railroad (over eight thousand of 'em total) to be hand-entered into the system while we tried to work out how to fix the import routine.
Finally, a partial fix was determined -- the switch milepost would be imported if the switch only attaches to one OS track, or if the names on each side of the OS track were the same; if the OS track's neighboring tracks were unnamed or named differently, then hand-entry would be the only option. While this got us most of the way there, the underlying bug proved to be impossible to fix fully -- the hand-entry would have to at least partially remain for the forseeable future, and the data source for this information couldn't come up with any additional tidbits they could extract in order to match up switches and their OSes, not without hand-entering those tidbits for every switch on the railroad.
Have any of you ran into catch-22 bugs, those that seem to admit only an incomplete solution, or no solution at all?
-
If a bug is impossible to fix, I'd consider that a design flaw in the software itself. Or a bug in something outside of your control.
-
If a bug is impossible to fix, I'd consider that a design flaw in the software itself. Or a bug in something outside of your control.
Pretty much this. Every time I had something like that it was either a language limitation or a flaw in a system I was interfacing with.
Filed under: Wonder how long until this thread derails, #getit
-
I don't get it. Why is this impossible? It seems like you have a graph, and just need to label the edges.
-
I don't get it. Why is this impossible? It seems like you have a graph, and just need to label the edges.
The problem is that the correct label for one of these OS-tracks (they're really vertices of said graph, but we'll sweep that under the rug) depends, as far as I can tell, not only on the name of the edge to the left and the edge to the right, but on the relative ordering of the switches, as multiple switches can share an OS track, and that relative ordering influences whether the left or the right track's name gets assigned to the OS track when multiple switches are involved. However, the only way to figure out that ordering is by inspecting the mileposts on the switches, which is where the catch-22 for a fully general solution lies. Furthermore, the name coming in from the left can be different from the name coming in from the right...
-
Why not just name them by fiat? Assign each one an id, send out maps/legends to interested parties?
-
Why not just name them by fiat? Assign each one an id, send out maps/legends to interested parties?
We'd have to send the maps/legends out to, well...a giant pile of folks in the field, and also rework several other systems that use this information.
Sending out general orders and timetable changes is a pain in the arse compared to even this!
-
that issue number has become immortalized among significant portions of the team as a result
-
It looks like a fundamental design flaw to me, as well.
Being no expert on the subject, it seems to me that the flaw was to not only apply the notification to the track, but then to use the track object to provide the notification to the train. My shallow take is that, it was fine to bind the notices to track segments. But there should be an itinerary object for a train, that references, in order, every track that the train will move along, in order, with relative mileage. That should be the object that is queried for notices, and the itinerary in turn queries the referenced tracks.
It wouldn't matter how complex the switching is in that case, because the itinerary controls delivery of notices.
-
The problem is that the correct label for one of these OS-tracks
is legacy, evolved rather than sanely designed, and beyond your control. Your importer is trying to do automated gender assignment based on first name.
Keep an eye on your sales droids. You will want plenty of warning before they close a deal with Russian or Australian railway operators and you have to start dealing with tracks that may or may not cross a time zone boundary depending on switch settings

-
Solution: name the track from the most South-East location of it, with coordinates in deci-micro-decimal degree. (that's 10^-7 degree precision, that should be enough)
As long as you stay on Earth, no more naming problem of any tracks.
For the really devious, you want to add the altitude (in meter or yard, that should be enough as most railways have at least a clearance of 2 meters above the track). (I love Switzerland). Make provision for negative number as well
I chose South-East, but any of the three other corner is suitable too, just stick to the same convention all the time.
Track id: 10+10+5 digits, with two separators, 27 characters
-
encoding/json: support unmarhaling "1.111111e+06" into int64
Bug report: gopherbot has a severe case of @accalia[1]
[1] - People (and software) suffering from @accalia can still lead normal, mostly uninterrupted lives. However, community understanding is required to avoid additional suffering of the afflicted.
-
Solution: name the track from the most South-East location of it, with coordinates in deci-micro-decimal degree
Fails for tracks that share a bounding box, which they can do provided that a "track" is still a thing whose exact identity depends on current switch settings and/or train directions.
The only sane way to deal with this is to model the network as a network where each track segment is encoded as a directed edge from a starting vertex to an ending vertex, and vertices are either physical switch points or places where a physical pair of steel rails crosses some kind of administrative boundary.
Once you have that, the exact convention you use to name your track segments internally doesn't matter much, and you can generate legacy track names from it at will. If you don't have that, and all you have instead is legacy track names, you're screwed.
-
Ok, I cannot use the corner of any bounding box, but I can use the exact location of the middle of the track : whatever the curve, it is inside the bounding box and yet not crossed by any other track. Notice, it is not just between the start and end point, it is exactly on the track. (it does not have to be at the same rolling distance from both ends, but it must be on the track)
It also separate the tracks that split left/right to join back later. I stick to 27 characters.
-
You will want plenty of warning before they close a deal with Russian or Australian railway operators and you have to start dealing with tracks that may or may not cross a time zone boundary depending on switch settings
Thankfully, we don't have to worry about that case at all as we don't plan to sell it to anyone else -- the system has too many of our business rules coded in, anyway, as safeworking/operating rules differ quite drastically from place to place (the US still has NORAC vs. GCOR going on, even).
The only sane way to deal with this is to model the network as a network where each track segment is encoded as a directed edge from a starting vertex to an ending vertex, and vertices are either physical switch points or places where a physical pair of steel rails crosses some kind of administrative boundary.
I'd love to implement the underlying data representation this way -- it's crossed my mind many times. Unfortunately, that'd be a massively destabilizing systemwide change, so it's at the
 stage at this point.
stage at this point.
Once you have that, the exact convention you use to name your track segments internally doesn't matter much, and you can generate legacy track names from it at will. If you don't have that, and all you have instead is legacy track names, you're screwed.
Luckily, we have internal unique identifiers to help us out inside the system itself -- but that doesn't help us much when ingesting data from external sources which only know the legacy track names.
-
Being no expert on the subject, it seems to me that the flaw was to not only apply the notification to the track, but then to use the track object to provide the notification to the train. My shallow take is that, it was fine to bind the notices to track segments. But there should be an itinerary object for a train, that references, in order, every track that the train will move along, in order, with relative mileage. That should be the object that is queried for notices, and the itinerary in turn queries the referenced tracks.
The problem is that the itinerary (schedule in our world, actually) isn't predetermined to that level of detail, partly because a dispatcher might have to rearrange everything at the last minute because something happened™ on the railroad and now the plan he or she's been working off of for the past several hours of his or her shift has been (sometimes literally) blown to bits.
-
It also separate the tracks that split left/right to join back later. I stick to 27 characters.
Have you ever been to Chicago? Or Houston? Or L.A.? Or Kansas City?
-
Have you ever been to Chicago? Or Houston? Or L.A.? Or Kansas City?
Enlight me, as I do not get it about Chicago. Any photo ? What are you thinking about ?
From previous specifications, a track has no switch, it's a edge between two points. So if a track A meet a switch, the left track is B and the right track is C. When B & C are back together at the next switch, we continue in track D. now, replace A,B,C,D with the coordinates of the middle of relevant track, and you always have unique internal key for a database.
-
Enlight me, as I do not get it about Chicago. Any photo ? What are you thinking about ?
Chicago is one of the main places where the major US railroads (yes, basically all of them) join together and swap railcars around -- it's an absolute spaghetti bowl of railroad tracks.
I'd embed a map, but things like Google Maps have a penchant for getting railroad tracks wrong...
-
How bad could it b--
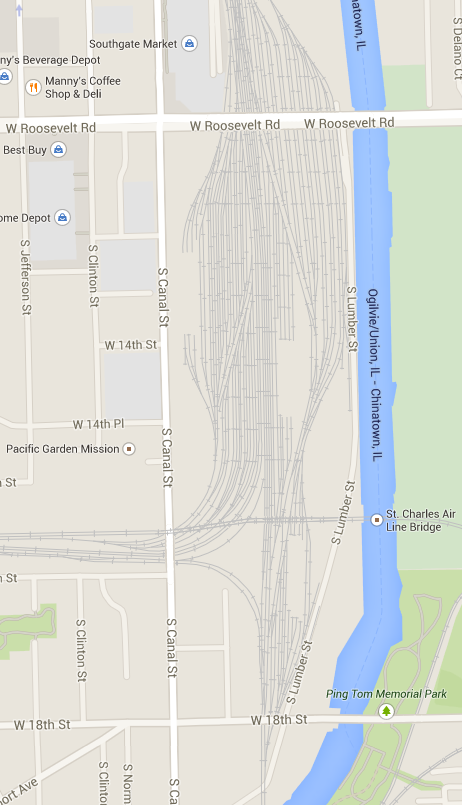
-
Have any of you ran into catch-22 bugs, those that seem to admit only an incomplete solution, or no solution at all?
I've got one that is bugging the heck out of me (no pun intended).
I am responsible for an algorithm that lays out UI controls inside of containers, and one of the design imperatives is that the users who design the layouts should not have to specify sizes for the controls or the containers. Each control has some inherent knowledge of "preferred" size, and each container has some inherent knowledge of what to do with those preferred sizes. So in general, a container can figure out its size from the sizes of its children.
(I've simplified that, because children and containers can specify size, they just aren't required to. But that's not terribly relevant to this particular problem)
For the most part, this works fine. Where the catch-22 comes in is with Text Labels. Specifically, Text Labels for which Word Wrap is enabled.
- A word-wrapped Text Label whose width is not specified wraps based on the width of its container
- Recall that a container whose width is not specified gets its width based on the widths of its children
- Text Labels aren't used to label individual controls - each control has a built-in label
- In many cases, Text Labels are short "labelly" labels (e.g. header for a section of controls)
- In many other cases, though, Text Labels are used for longer descriptive text
Those first two points are the real killer here - when we have a word-wrapped Text Label without a width inside a container without a width, where should we wrap the Text Label/what should be the width used? We can't set an arbitrary point, because of the last two points - if we go too large, we might end up too wide in the first case, and if we go too small, we might end up too narrow in the second case.
We've chosen an arbitrary point, but it's not a great solution.
Even worse, when you word-wrap a Text Label, its height changes. So you might end up having to change the height of the container. This causes a recalculation of the container, and then a re-layout, which, if the container is constrained in some other way (perhaps ITS container is constrained, or something like that), or because of some intermediate weirdness along the way, can cause scrollbars to appear (I'm working in Flex, which is its own WTF). That affects the available width and height of the Text Label, which causes another recalculation of the wrapping point of the text, which causes another recalculation, which blah blah blah.
In short, we sometimes get what we call "Dancing Text Label", where scrollbars appear and disappear. So far, there appears to be no complete solution.
And, to make matters worse, our users are insisting that the defaults be:
- No specified Width for Text Labels
- No specified Width for Containers
- Word Wrap set to true for Text Labels
That is, the exact scenario that can lead to this.
sigh.
-
That's just Union Station's yard and the Canal Street interlocker -- it gets worse from there.
-
Yeah, once I knew what sort of thing to look for I zoomed out and saw a few others:
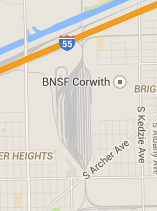
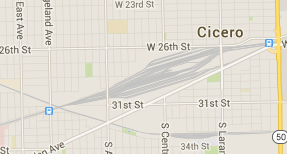
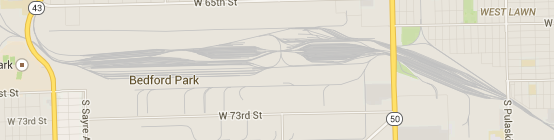
-
Well you found Corwith, Cicero, and Bedford Park (none of which are ours) -- but all you're looking at are the yards. You need to see the big picture to get an idea of how bad it is:
-
-
-
Everything!
Well yes, but I was thinking about how to switch things around. With containers, you can do it by crane. (The equipment is standard and the weights are sane.) With bulk cargo, you might well just uncouple one engine and stick another on; the whole load is probably going to the same destination. It's just with “other” that things get awkward.
-
Well yes, but I was thinking about how to switch things around. With containers, you can do it by crane. (The equipment is standard and the weights are sane.) With bulk cargo, you might well just uncouple one engine and stick another on; the whole load is probably going to the same destination. It's just with “other” that things get awkward.
You simply grab a pile of cars from your yard that need to go over to that other yard over there, couple them up into a cut, lace the air and test it, stick some locos on, and have a yard crew trundle it over to the other yard as a transfer job and drop the cut of cars off for the other yard to sort out.
So, how you envision it works for "bulk cargo" is really how it works for just about everything -- the whole entire railcar gets interchanged between railroads.
-
-
So I know how interchange works, but the exact details have always been a puzzler. Who is responsible for maintaining all that crap? What's the incentive to go build more if it's just going to disappear into a tiny short line half a continent away and stay there for 30 years? Why the hell is 3/4 of the rolling stock I've ever seen owned by CN?
-
What is the round trip time to Tom Memorial Park, and why would I want to ping it?
-
- You'd have to ping it to find out.
- See 1.
HTH
-
The problem is that the itinerary (schedule in our world, actually) isn't predetermined to that level of detail, partly because a dispatcher might have to rearrange everything at the last minute because something happened™ on the railroad and now the plan he or she's been working off of for the past several hours of his or her shift has been (sometimes literally) blown to bits.
Oh, I see. The system isn't used for planning; nothing-in-nothing-out. Yeah, that makes it hard for the system to keep an itinerary.
-
The system isn't used for planning; nothing-in-nothing-out. Yeah, that makes it hard for the system to keep an itinerary.
No, it's that you can't always predict the future ;) You can have an entire territory running like clockwork and BAM the coal train that was almost dead on the law gets an UDE while traversing a crossover, blocking both main tracks and bringing half the territory to a screeching halt while the crew raises you on the radio saying that they'll be dead on the law in fifteen minutes -- they're walking the train, but they'll need a patch crew to come over with the car repairman to relieve them.
-
Who is responsible for maintaining all that crap?
In general, the car owner is financially responsible for car maintenance -- either they contract with a shop for routine maintenance, or they get billed by the RR in case urgent repairs are needed.
What's the incentive to go build more if it's just going to disappear into a tiny short line half a continent away and stay there for 30 years?
New requirements are being imposed on railcars (tank cars to be precise), cars do wear out after a while, and derailments happen. Also, most railcars AIUI don't stay parked for nearly that long at any one time -- they get unloaded and either reloaded with something else or sent back empty as soon as they're ready for the next customer to use.Why the hell is 3/4 of the rolling stock I've ever seen owned by CN?
CN bought out several major-ish US railroads (Grand Trunk Western, Wisconsin Central, Illinois Central, and the Elgin, Joliet, and Eastern)
-
Oh look, that redirects to github so I still can't read it : (
-
you can't always predict the future
“Predictions are difficult, especially about the future.”
So, how you envision it works for "bulk cargo" is really how it works for just about everything -- the whole entire railcar gets interchanged between railroads.
OK, I can see how that works. It might not be the easiest way for containers (since I've seen multi-container cars in use) but for anything that fills out a whole car it's going to be simplest that way. And everything smaller than that is probably either already in a container or being handled by someone else who's aggregated it into a full car load (or doesn't care about the waste too much).
-
Oh look, that redirects to github so I still can't read it : (
it's a discussion of a "bug" in go that's the result of marshalling an integer to JSON then unmarhsalling it back and expecting the number to be an integer. JSON explicitly defines all numbers to be Float64.
Not a bug.
-
Not a bug.
But JSON is capable of representing integers losslessly as float literals, up to 9,007,199,254,740,992. Why disallow roundtripping integers less than that?
-
if i was defining the document type i would say the same thing, but i didn't. the document stnadard for JSON says all numbers are Float64.
to deserialize differently would be to violate the document standard.
-
if i was defining the document type i would say the same thing, but i didn't. the document stnadard for JSON says all numbers are Float64.
Do you think that1111111isn't representable in a float 64?The point is that the Go JSON module apparently allows you to deserialize some numbers that are representable in an int directly to that int type --
json.Unmarshal([]byte("1"), &i))will set anvar i int64to 1 -- but not all. The deserialize-right-to-int is quite reasonable provided it is to give an error for things that can't be represented as an int, and it does. Not allowing you to deserialize to an int, and making you do the cast yourself, would also be pretty reasonable.But to have a two numbers that are both representable as both float64 and int64, and for one of them to round-trip as @ben_lubar is doing it but not the other -- I agree that's a
 .
.Edit: I can even kind of see the logic behind allowing
1111111to deserialize to an int but not1.111111e+06, even though I think it's sort of a dumb argument. But in that case, serializing an int should produce1111111and not1.111111e+06. Nominally being able to roundtrip JSON-representable integers, but not actually being able to roundtrip most JSON-representable integers, gets us back to in the library.the document stnadard for JSON says all numbers are Float64. ...
And actually, I was curious about something else... so I looked up what the standard had to say about what numbers are valid. And that statement is just flat out wrong:
to deserialize differently would be to violate the document standard.
@ECMA-404 Standard; The JSON Data Interchange Format said:JSON is agnostic about numbers. In any programming language, there can be a variety of number types of various capacities and complements, fixed or floating, binary or decimal. That can make interchange between different programming languages difficult. JSON instead offers only the representation of numbers that humans use: a sequence of digits. All programming languages know how to make sense of digit sequences even if they disagree on internal representations. That is enough to allow interchange.
-
Basically, Go encodes the number 1111111 as
1.111111e+06in json, but refuses to decode that as an integer type, even though1.111111e+06has an exact integer representation.The reason? Something about integers not being in the JSON spec. Apparently that makes you handle them differently from floats.
-
Been there.... it is.... insane.
-
-
Actually, looking at it when coming into the city in a plane is the best view I recall. You can't really get a good grasp of how big it is from ground level.
I did live in downtown Chicago for nearly 5 years, quite a while back.
-
There's a few of the yards that you can get an impression of the size from the freeway due to the road being elevated in the right way. It's a long time since I've driven in central Chicago (not gonna make that mistake again!) so I forget which exactly, and I CBB to look it up.
-
where should we wrap the Text Label/what should be the width used?
About 50em makes for comfortable reading of descriptive text. So if you have a Text Label whose width is not set explicitly, not constrained by that of its container, and not inferrable via alignment with other controls above or below, then 50em in whatever font its text is in would be a reasonable default.
when you word-wrap a Text Label, its height changes. So you might end up having to change the height of the container. This causes a recalculation of the container, and then a re-layout, which, if the container is constrained in some other way ... can cause scrollbars to appear... That affects the available width and height of the Text Label, which causes another recalculation of the wrapping point of the text, which causes another recalculation, which blah blah blah.
If that were my problem, I'd be doing all my layouts not against the container itself, but against an invisible box that would still fit in the container even if the container were to grow both X and Y scrollbars.
To prevent my users from noticing that this is what I was doing, I would centre the layout box within the active area of the container; without scrollbars, the only visible effect would be to give the interior controls half a scrollbar's worth of extra margin all round.
If anybody does complain, point out that this is merely default behavior and, as with any default, they're perfectly free to specify whatever they like if the default doesn't suit.
-
refuses to decode that as an integer type, even though 1.111111e+06 has an exact integer representation
Inferring float from a numeric literal that includes a decimal point is the norm for every compiler I've ever seen; why should a JSON parser work any different?
-
Go encodes the number 1111111 as 1.111111e+06 in json
That's not a choice I would have made.
-
It's JSON, so numeric literals are floats by definition. I'm saying integers should be any number with an exact integer representation.
Not to mention that this compiles: http://play.golang.org/p/3A7WCfqWpU
{kind=link}