SQL silly database
-
Hi All,
I'm trying to get reports out of an old access database over ODBC.
Because the application that uses the database is customisable, it is possible to add as many fields to the details for one person (record). This means I have the following tables:
CONTACT - this contains the company information (Name address etc)
REFS - this contains basic information on the people, with a foreign key to CONTACT.ID Basically only includes the keys and the person's name.
DATA - a massive table that contains the following headings: Field ID, Key 1, Key 2, Key 3, Data
Field ID references a different table for the Field name.
Key 1 is Company ID
Key 2 is REFS.ID
Key 3 seems to be unused
Data contains the actual data for that field for that personSo data contains all the information about the person.
How do I write a query that can output a table of all people with their details?
The example below is able to get just one field out at a time (postcode - I have previously looked up the field ID)
select Name,"Company name",Suffix,Data AS Postcode from REFS,CONTACT,DATA
where [REFS.Company ID] = [CONTACT.Company ID]
and REFS.Name Like 'x.%' and [REFS.Company ID] = [DATA.Key 1]
and [DATA.Field ID] = $Powersell(PostcodeField)
order by NameI'm not sure how many additional commands (UNION, JOIN etc.) are supported over ODBC to an Access 97 database, but hopefully there's an easy answer.
Make sense?
-
That general database design is called EAV: entity, attribute, value.
Depending on what your system needs to do, EAV can be perfectly fine or the absolute worst thing to use.
If you only ever care about querying a person at a time (person id 20), it's perfectly fine.
If you want to support querying many people (first name='mike'), it's probably going to end up being a nightmare for performance. EAV fields are not good candidates for the where clause.
Of course, the number of people and the number of attributes weighs into this. If the system will only hold a couple hundred people and each have 5 or 6 attributes, it'll probably perform just fine. Also, is searching a primary activity vs just something done on occasion? On that rare occasion, is slow performance ok?
-
If you do end up using this model, your query would look something like this. The query doesn't match your tables since I figured it'd be easier to show with a simplified schema.
Assume attribute 1000 is firstname and 2000 is lastname.
select c.id,fn.value as firstName, ln.value as lastName from contact as c inner join attrib as fn on fn.contactId=c.id and fn.id=1000 inner join attrib as ln on ln.contactId=c.id and ln.id=2000 where c.id= WANTED_ID
-
There are over 10000 people.
The database is on a network share, which will impact performance
I would like to generate a complete list of all people (filtered by certain things including data from the Data table).
Another problem is the database is in use constantly, so I can't cache it (or edit it), and strictly speaking it's not a report I want, it's a dashboard website to give a summary of all people (filtered), so every refresh of the page should be minimum time. The query above completes in about 6 seconds.
-
@ben_warre said in SQL silly database:
Access 97 database
If you wanted everything in one result set I might have suggested pivot, but I'm very certain that's not supported in Access 97...
If you're ok with multiple result sets this shouldn't be too onerous....
-
@ben_warre said in SQL silly database:
the database is in use constantly
An Access database on use constantly?
This sounds more like "help me recommend a big boys dbms to my boss". ...
A query like that should take nowhere near six seconds to process unless you have no indexing and are running it on spinning rust from a decade ago over a network share (which, considering your posts, seems likely).
-
I wouldn't know where to begin... A google suggests TRANSFORM, PIVOT, EXTRACT... Where's the idiots' guide?
-
@ben_warre said in SQL silly database:
. A google suggests
You're going to need to stick to results the date before 2003,that's for sure.
-
@tsaukpaetra It's a CRM system from the 90s. Still in use all day by 12 users at a time max.
-
@tsaukpaetra said in SQL silly database:
An Access database on use constantly?
Same database I never got around to replacing last year.
-
@ben_warre said in SQL silly database:
@tsaukpaetra It's a CRM system from the 90s. Still in use all day by 12 users at a time max.
I'm not saying it's impossible. I myself was a key component in translating a document custody application from Access 97 to SQL Server, so I understand the stubbornness of business.
In fact, the main reason the company transitioned off Access 97 is because auditors were dinging is super hard for using XP-era stuff.
-
@ben_warre Is this a one-time query to extract data, or a query being written for an application being actively used? The simple join across would be something like:
select * from contact c join refs r on r.contactId = c.contactId join data d on d.key2 = refs.key -- or whatever it's called in the refs tableFrom there, if you want a specific type of data, you'd add a
where FieldId = 'blah', etc.
-
@ben_warre said in SQL silly database:
The database is on a network share, which will impact performance
Uh, you're running an Access '97 database on a network drive with multiple simultaneous users in 2018?
This has suddenly turned into an archaeology problem.
Newer versions of Access have basically a 1-button conversion to change the app to a proper SQL Server-backed app (which still uses Access as the front-end so your users won't know the difference). Anything you do to this database other than to convert it to a proper SQL Server-backed app is the wrong thing to do. Seriously.
You're working with a system that should have been thrown in the garbage 15 years ago. Is it even backed-up? I'm guessing: no.
I mean I can't emphasize this enough. Any professional ethics you have demand that you walk up to your boss and say "no features can be built on this until it's properly maintained. Here, we can do it with an Azure account and $50 bucks. Seriously. $50 to fix all of this. It'd be insanely stupid not to."
-
You should be able to do something like this:
SELECT Name, "Company name", Suffix, Postcodes.Data AS Postcode FROM REFS, CONTACT, DATA Postcodes WHERE [REFS.Company ID] = [CONTACT.Company ID] AND REFS.Name Like 'x.%' AND [REFS.Company ID] = [Postcodes.Key 1] AND [Postcodes.Field ID] = $Powersell(PostcodeField) ORDER BY NameThat should, if I'm not mistaken, be the same as your example query, but -- here's the key -- it aliases
DATAasPostcodes. So you'll notice that everywhere but in theFROMclause, that table is calledPostcodes, and for all we care, it's all it contains.To add another attribute from
DATAto the query, you'd just- add another appropriately-named alias to
DATA - add a line to the
WHEREclause to select the attribute that you want - add it to the
SELECTclause to include it in the results
edit: is
$Powersellsupposed to be spelled like that? I just copied and pasted what you wrote.
- add another appropriately-named alias to
-
@anotherusername said in SQL silly database:
edit: is $Powersell supposed to be spelled like that? I just copied and pasted what you wrote.
PowerSell is probably the name of their CRM software from the Age Of Sail.
-
@blakeyrat said in SQL silly database:
@anotherusername said in SQL silly database:
edit: is $Powersell supposed to be spelled like that? I just copied and pasted what you wrote.
PowerSell is probably the name of their CRM software from the Age Of Sail.
Exactly that.
It is due to be replaced, probably with MS Dynamics within 2 years.
We just need more of an overview of the things we've shoehorned into it (hint: not every 'person' in the database is a person...)
-
@ben_warre said in SQL silly database:
It is due to be replaced, probably with MS Dynamics within 2 years.
That doesn't change your responsibility to put this app on solid footing for the next two years. Two years is a very long time.
You also didn't answer my question: are there backups? Have the backups been restored in the last month? Do they work? This is a HUGE bundle of risk your company's operating on, and I'm sure your management doesn't even recognize that they're basically rolling the dice on bankruptcy every time someone opens up that database connection.
-
@blakeyrat said in SQL silly database:
@ben_warre said in SQL silly database:
It is due to be replaced, probably with MS Dynamics within 2 years.
That doesn't change your responsibility to put this app on solid footing for the next two years. Two years is a very long time.
You also didn't answer my question: are there backups? Have the backups been restored in the last month? Do they work? This is a HUGE bundle of risk your company's operating on, and I'm sure your management doesn't even recognize that they're basically rolling the dice on bankruptcy every time someone opens up that database connection.
Multiple backups. And the network share is also backed up.
-
@ben_warre Ok well do what you do, you know my opinion on the matter.
I'll put $50 on "2 years from this day, the move to MS Dynamics hasn't yet happened" though. These guys haven't fixed their shit since 2003, what makes you think it'll happen now? Hah.
-
@blakeyrat said in SQL silly database:
@ben_warre Ok well do what you do, you know my opinion on the matter.
I'll put $50 on "2 years from this day, the move to MS Dynamics hasn't yet happened" though. These guys haven't fixed their shit since 2003, what makes you think it'll happen now? Hah.
We are finally updat
eding our production DBs from SQL Server 2008 to SQL Server 2014. For applications that have EOLed for almost 3 years because there were to be replaced by Microsoft Dynamics CRM. I'm can say with certainty that our application was/is more complicated than your Access 97 application.So I agree with blakey.
EDIT: Grammar
-
I agree. But it is what it is.
-
@karla said in SQL silly database:
We are finally updated
You don't get a vote in these things ... too close to governement!

-
So, if @blakeyrat is done hijacking the topic, and we could get back to the SQL thing...
Does the code that I posted work?
-
@anotherusername said in SQL silly database:
So, if @blakeyrat is done hijacking the topic, and we could get back to the SQL thing...
Does the code that I posted work?
I will test at work tomorrow (uk time)
-
@anotherusername said in SQL silly database:
So, if @blakeyrat is done hijacking the topic, and we could get back to the SQL thing...
Does the code that I posted work?
Simply put, no, it doesn't work - it gives me duplicates
% set reqcols {Name,"Company name",Suffix,Postcodes.Data AS Postcode, Machines.Data AS Machines}
%set query " select $reqcols from REFS,CONTACT,DATA Postcodes,DATA Machines "
%append query " where [REFS.Company ID] = [CONTACT.Company ID] and REFS.Name Like 'x.201%' "
%append query " and [REFS.Company ID] = [Postcodes.Key 1] and [Postcodes.Field ID] = $Powersell(PostcodeField)"
%append query " and [REFS.Company ID] = [Machines.Key 1] and [Machines.Field ID] = $Powersell(MachineField)"
%append query " "
%append query " order by Name"I guess the cross of the two data tables is doing it. I get each person repeated I think by the number of people in the company.
-
Sorted, I think. The problem is the Companys can have fields and people can have fields. Both are stored in the Data table.
This works I think.
% set reqcols {Name,"Company name",Suffix,Postcodes.Data AS Postcode, Machines.Data AS Machines}
%set query " select $reqcols from REFS,CONTACT,DATA Postcodes,DATA Machines "
%append query " where [REFS.Company ID] = [CONTACT.Company ID] and REFS.Name Like 'x.201%' "
%append query " and [REFS.Company ID] = [Postcodes.Key 1] and [Postcodes.Field ID] = $Powersell(PostcodeField)"
%append query " and [REFS.Company ID] = [Machines.Key 1] and [REFS.Reference ID] = [Machines.Key 2] and [Machines.Field ID] = $Powersell(MachineField)"
%append query " "
%append query " order by Name"
-
@tsaukpaetra said in SQL silly database:
A query like that should take nowhere near six seconds to process unless you have no indexing and are running it on spinning rust from a decade ago over a network share (which, considering your posts, seems likely).
The above query runs in under 3 seconds, so I guess the 6 second load is more to do with delays in outputting the data and chrome displaying the table.
Let's just hope that adding many more field queries doesn't slow it down too much more.
Would I get any speed up if I did my Like 'x.' somehow before crossing all the tables together? How would I do that?
-
Oh for $Deity's sake!
So, if a field is not filled in, the data isn't added to the DATA table.
So I am missing loads of complete rows, because I want a <null> instead of ignoring the person.
FULL OUTER JOIN??
-
@ben_warre said in SQL silly database:
Would I get any speed up if I did my Like 'x.' somehow before crossing all the tables together? How would I do that?
Any of the
ANDterms can be arranged --A AND B AND Cis no different fromB AND C AND A, orC AND A AND B, or...So, you could try simply rearranging them. That said, I don't think it should matter.
You could also try replacing the
WHEREsections that join tables with actualLEFT JOINs -- e.g. instead ofwhere ... and [REFS.Company ID] = [Postcodes.Key 1] and [Postcodes.Field ID] = $Powersell(PostcodeField)you'd do
left join DATA Postcodes on [REFS.Company ID] = [Postcodes.Key 1] and [Postcodes.Field ID] = $Powersell(PostcodeField)Edit:
LEFT JOINshould fix your issue with no data. That's probably what you should use. It's possible to emulate it in aWHEREclause (iirc... it might depend on the specific database), but it's probably better just to useLEFT JOIN, if you're able.
-
@mikehurley said in SQL silly database:
If you want to support querying many people (first name='mike'), it's probably going to end up being a nightmare for performance. EAV fields are not good candidates for the where clause.
Experience from supporting RDF databases (which are the most EAV things you can imagine) suggests that extracting critical attributes into their own columns can be a gigantic win. If you're selecting or ordering by it, you want it extracted. You might use a trigger to keep the extracted columns correct. They are derived data, after all…
All of which means bupkis if you're using Access 97. (On a network share? Good grief!)
-
@dkf said in SQL silly database:
@mikehurley said in SQL silly database:
If you want to support querying many people (first name='mike'), it's probably going to end up being a nightmare for performance. EAV fields are not good candidates for the where clause.
Experience from supporting RDF databases (which are the most EAV things you can imagine) suggests that extracting critical attributes into their own columns can be a gigantic win. If you're selecting or ordering by it, you want it extracted. You might use a trigger to keep the extracted columns correct. They are derived data, after all…
All of which means bupkis if you're using Access 97. (On a network share? Good grief!)
I don't see the point of having the data in two places. Things that are that important should just live in their own columns. If consumers are hitting a webservice to get the info, the service can create magic attributes to put in the bucket which helps with api stability. Webservices don't need to just parrot back db records.
-
@mikehurley said in SQL silly database:
Things that are that important should just live in their own columns.
This. The "foreign key, name, value" table is the sort of
 that you find when there's an idiot DBA who believes that new columns must never be created under any circumstances whatsoever, so the programmer has to find a way to fake it in the application layer. Or someone who just heard about normalizing data and went "NORMALIZE ALL THE THINGS" while completely missing the point that properly normalized data has kinds of data stored in separate tables, not dumped in one big table with a "data type" column to tell you what the data stored in that row actually is. (The table name should tell you that.)
that you find when there's an idiot DBA who believes that new columns must never be created under any circumstances whatsoever, so the programmer has to find a way to fake it in the application layer. Or someone who just heard about normalizing data and went "NORMALIZE ALL THE THINGS" while completely missing the point that properly normalized data has kinds of data stored in separate tables, not dumped in one big table with a "data type" column to tell you what the data stored in that row actually is. (The table name should tell you that.)But, I'm hijacking the thread again. We all knew already that the database schema is idiotic, and it doesn't sound like he can change it.
-
Joins don't seem to work... I will keep trying. I'm hesitant to query multiple times but it maybe the only way.
-
@mikehurley said in SQL silly database:
I don't see the point of having the data in two places.
It's sometimes more work to stop it from being in multiple places. The extracted columns are derived data in this case, and there are (hopefully rare) queries that need the complexity that the extraction avoids. You could normalise everything and no longer have the problem of data getting out of synch… but that increases the amount of work you have to do in other cases. So you trade-off, keep the original data (warts and all) and just derive some common columns to allow you to make key production queries fast.
Remember: not all databases fit nicely with a defined relational world.
-
@dkf said in SQL silly database:
All of which means bupkis if you're using Access 97. (On a network share? Good grief!)
Ah, that brings back memories...
Pardon me, I need to go book some time with my therapist now.
-
@ben_warre said in SQL silly database:
Joins don't seem to work... I will keep trying. I'm hesitant to query multiple times but it maybe the only way.
tum tee tum te tum...
If I query 'People' from the last two years, without accessing DATA in any way, it takes 0.2 seconds.
As expected, if I then go through each one and pull out all the data from DATA for each person, it takes 7 minutes.
-
@dkf said in SQL silly database:
Remember: not all databases fit nicely with a defined relational world.
That just means that the relationships haven't been well-defined yet for that data.

-
@ben_warre said in SQL silly database:
Joins don't seem to work... I will keep trying. I'm hesitant to query multiple times but it maybe the only way.
Including empty data in the results can be done in 2 ways that I can think of:
In the ON clause for LEFT or FULL JOINs:
-- if company or person can be null, just change -- all the join types to FULL instead of INNER or LEFT SELECT c.name, p.name, d1.data, d2.data, d3.data FROM Company c INNER JOIN Person p ON p.company_id = c.id LEFT JOIN UserData d1 ON d1.company_id = c.id AND d1.person_id = p.id AND d1.type = 'Data Type 1' LEFT JOIN UserData d2 ON d2.company_id = c.id AND d2.person_id = p.id AND d2.type = 'Data Type 2' LEFT JOIN UserData d3 ON d3.company_id = c.id AND d3.person_id = p.id AND d3.type = 'Data Type 3'In the WHERE clause with comma joins:
SELECT c.name, p.name, d1.data, d2.data, d3.data FROM Company c, Person p, Data d1, Data d2, Data d3 WHERE p.company_id = c.id AND ((d1.company_id = c.id AND d1.person_id = p.id AND d1.type = 'Data Type 1') OR d1.type IS NULL) AND ((d2.company_id = c.id AND d2.person_id = p.id AND d2.type = 'Data Type 2') OR d1.type IS NULL) AND ((d3.company_id = c.id AND d3.person_id = p.id AND d3.type = 'Data Type 3') OR d1.type IS NULL)I know some DBMS's (and many connection providers) don't like to support outer joins (left, right, full), so all that are left are inner and cartesian (comma/cross) joins.
-
Update: A full query to get basic company info now takes about a minute. I then cache that in a local database, along with the time. Then a mini update (from the last time stored) takes about 10 seconds.
Displaying the data works nice and smoothly. Aside from the 1000 div issue, but that's not really an issue.
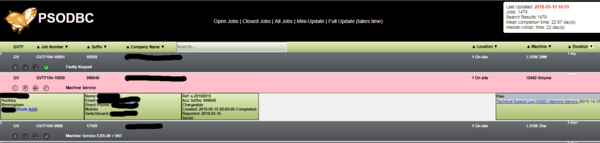
-
@blakeyrat said in SQL silly database:
@ben_warre Ok well do what you do, you know my opinion on the matter.
I'll put $50 on "2 years from this day, the move to MS Dynamics hasn't yet happened" though. These guys haven't fixed their shit since 2003, what makes you think it'll happen now? Hah.
Blakey would be satisfied to know that the move hasn't happened yet...
-
@djls45 said in SQL silly database:
@dkf said in SQL silly database:
Remember: not all databases fit nicely with a defined relational world.
That just means that the relationships haven't been well-defined yet for that data.
Or that the data is naturally recursive. Recursion and relational databases are a poor fit. (There are other DB types that work better.)
Or the data is naturally unstructured or semi-structured. Because the real world is messier than a DB…