Unit Fighting
-
@boomzilla said in Unit Fighting:
The rest of us start fidgeting and checking our cell phone somewhere around the thirty minute mark.
Hence Pomadoro !
-
@thecpuwizard said in Unit Fighting:
@boomzilla said in Unit Fighting:
The rest of us start fidgeting and checking our cell phone somewhere around the thirty minute mark.
Hence Pomadoro !
What...lunchtime?
-
@boomzilla He means a particular method of break taking. I prefer to just slack off here.
-
@masonwheeler said in Unit Fighting:
@magus And yet, the highest-quality software I've ever worked on, that all but took over its whole industry and drove several competitors out of business, had zero automated tests. Why? Because we didn't need them; we just acted like professionals and put in the effort to make our software be of good quality.
Oh, man. If only I had learned much earlier in my career all I needed to do to remove technical risk was "act like a professional".
-
@heterodox It's never too late to start. :D
-
@boomzilla said in Unit Fighting:
@thecpuwizard said in Unit Fighting:
@boomzilla said in Unit Fighting:
The rest of us start fidgeting and checking our cell phone somewhere around the thirty minute mark.
Hence Pomadoro !
What...lunchtime?
No I think it's a breed of dog.
-
@ixvedeusi said in Unit Fighting:
Concerning the "(unit) tests become gospel" argument, my personal experience has been very much the contrary: my co-workers seem to quite happily just change the tests so that they match what their code does rather than think about it for a moment and discover the mistake in their code.
I've written unit-tests that just fail when the output of a function changes. I'd never verified whether the output was right in the first place, because that would have been work. It just "looked good" and that was enough. When such a test should fail, the default reaction would indeed be to "fix the test" by using the new output if it "looks good" and it was supposed to change. If the output was not supposed to change, and the test failed? Well I guess I'd just delete the test so it stops nagging.
-
@magus said in Unit Fighting:
@boomzilla He means a particular method of break taking. I prefer to just slack off here.
Me, too. The one where you eat.
-
@magus said in Unit Fighting:
We're in an industry where Fizzbuzz eliminates 80% of
peoplecandidates.The people who pass Fizzbuzz are not on the market often. That skews the results.
-
@hungrier said in Unit Fighting:
No I think it's a breed of dog.
Those are called Mutts that stupid people pay $1000s for.
-
@gleemonk said in Unit Fighting:
Well I guess I'd just delete the test so it stops nagging.
Sounds professional to me.
-
@heterodox I am an experienced professional.
-
I didn't read today's discussion yet, so forgive me if I'm repeating what others have already said.
@ixvedeusi said in Unit Fighting:
For example, I'd agree that "100% coverage" is a dangerous myth. The complexity of even the simplest modern software system is way too high to even get remotely close to testing all possible states, and insisting on "100% coverage" (by whatever flawed metric) will only produce a huge pile of essentially useless tests.
Not exactly useless. Having total (or near-total) coverage makes refactoring very easy. You don't care about subtle changes in how the program works internally that can potentially cause weird bugs down the line because you immediately see any and all changes in behavior. Sure, there'll still be some bugs. But they'll be of the interesting kind, not stupid shit you'd never do if you didn't overlook it.
@masonwheeler said in Unit Fighting:
Code can have bugs, and generally does, at a rather predictable rate of one serious bug per X lines of code.
Any such prediction is bullshit. In a sample of trillion lines of code (billion in Europe), sure, you might try to measure average bugs per line. But any smaller sample is bound to be heavily biased by competence of programmers involved, difficulty of the project, and sheer luck.
@masonwheeler said in Unit Fighting:
Many people acknowledge this point intellectually, but don't think about the ramifications, that tests can be buggy too. They treat tests as some sort of higher, purer, more noble form of code, that's worthy of being authoritative.
I don't. Tests are code. Since it's code, it can (and will) contain bugs. And bugs should be fixed.
@masonwheeler said in Unit Fighting:
Since the test code is a noble, pure, canonical spec
It's not. And whoever says that is full of shit.
@masonwheeler said in Unit Fighting:
its bugs become authoritative and get enforced rather than fixed.
No they don't. Bugs in tests get fixed like in every other code. Even if you were to treat tests as actual, literal specification - have you ever heard of a specification that doesn't change?
@masonwheeler said in Unit Fighting:
Since bugs occur at a predictable rate per lines of code, your comprehensive test bed is virtually certain to contain more bugs than your codebase, simply by virtue of being larger than it.
And that's exactly why this X bugs per line is bullshit. Complexity of test code is incredibly smaller than the code it tests - and simpler code means less bugs. Also, 90% of tests is copy-paste of previous tests with slight variations - and if the original test has no bugs, neither do the copies.
@masonwheeler said in Unit Fighting:
This has been demonstrated experimentally by testing the tests: when bugs are randomly seeded in both the codebase and the test bed, users will consistently uncritically "fix" the codebase to match the tests, even when it's the tests that are in error.
It only shows that those "users" have no idea what they're doing, and they desperately need a cluebat. A competent programmer who has a good idea of what the program is supposed to do, is never going to fall for that.
OK, now to read those 30 posts...
-
@masonwheeler said in Unit Fighting:
@boomzilla You really think your team would do better at a random-bug-seeding audit?
Just think about your codebase. You've probably got a bunch of code somewhere in there that's 10+ years old, written (along with its tests) by someone who's no longer with the company, that no one is really a subject matter expert on anymore. It's there, it basically works, and no one likes to have to touch it. (I know you do, because there's been code like that everywhere, at every place I've worked in my career.)
If a test fails in an area like that, what's a developer going to do? The tests are the only authoritative source they have! The way it always works out shouldn't surprise anyone, really.
This is a straw man. Tests can serve as a spec but they aren’t a substitute for one, nor are they a reason not to create one.
Generally, you should have:
- Business that requests a change.
- Documentation trail where the feature is negotiated.
- Entry in your task management system.
- Tests.
Existence of any of these isn’t a reason not to have the other. And certainly tests aren’t a substitute.
But, if 2 and 3 are missing, it’s better to have tests. If 1 is missing and a test fails, it’s an indicator of what might have gone wrong. If you don’t have tests, you have nothing. And you’re utterly screwed.
-
@kt_ said in Unit Fighting:
Existence of any of these isn’t a reason not to have the other. And certainly tests aren’t a substitute.
I don't think you comprehend the enormity of the situation. Mason has witnessed people who can't look into all that other stuff and just add kludges until the tests pass!
-
@jaloopa said in Unit Fighting:
@magus said in Unit Fighting:
most people have no idea what they're doing
evenespecially in this industryOr has my maintenance of terrible legacy software made me overly cynical?
It has. Construction workers, administration workers and teachers are all much worse. And I'm sure there's more professions like that.
-
I've found the value of unit testing also depends on the type of code. If your object being tested is more or less an "object router", unit tests probably aren't too useful. If you have a bunch of mocking going on to test a few if-statements, those tests probably aren't worth it and are probably a mess because of all the mocks. Especially if there's a lot of mock data. You could argue that maybe that object isn't all that valuable and should lead to a refactor, but you'd really need per-app context to say that for sure.
I also don't like TDD for brand new development. I do like it for bug fixes and "more of the same" features. For instance, a validator that should now enforce "last name is at most 50 chars". I find that for truly new development, there tends to be too much churn in the "real code" that if you follow the mandates of TDD would require a lot of bouncing around with code edits.
-
@masonwheeler said in Unit Fighting:
@ixvedeusi You're completely missing the most important part of the article's line of reasoning. It goes like this:
- Code can have bugs, and generally does, at a rather predictable rate of one serious bug per X lines of code.
- Tests are made of code.
- Many people acknowledge this point intellectually, but don't think about the ramifications, that tests can be buggy too. They treat tests as some sort of higher, purer, more noble form of code, that's worthy of being authoritative.
- In order to thoroughly test a codebase, you need more test code than code code, often orders of magnitude more. (See above, where @Gąska claims it's possible to get a "reasonable" 95% code coverage with "only" about 2X as much test code as codebase.)
- Since bugs occur at a predictable rate per lines of code, your comprehensive test bed is virtually certain to contain more bugs than your codebase, simply by virtue of being larger than it.
- Since the test code is a noble, pure, canonical spec, its bugs become authoritative and get enforced rather than fixed.
- This has been demonstrated experimentally by testing the tests: when bugs are randomly seeded in both the codebase and the test bed, users will consistently uncritically "fix" the codebase to match the tests, even when it's the tests that are in error.
Therefore, a test bed large enough to be useful literally does more harm than good. It's not the simple tautology of "bad tests are bad" that some people are trying to reduce it to; it's pointing out that bad tests are inevitable, and will inevitably cause harm.
You're missing a huge part of how unit tests can help discover bugs:
If a unit test is flawed in that you are passing an incorrect expected value or whatever other flaw in logic, that will likely be caught when you are writing the implementation of the code and notice the contradiction. In other words, in order for bugs to be introduced in this manner, you would have to coincidentally make the same exact mistake on the code itself and its corresponding unit test at the same time. Otherwise, if one is correct and the other isn't it will fail.
Such coincidences would be likely an indication that the software engineer has a misunderstanding of the requirements and/or design of the product their coding, which is something that would have been a problem with or without unit tests.
And, yes, obviously you could be in the same mental state where you fuck both up at once because you're tired/distracted/whatever but, again, those things still are present when you're coding without unit tests. There's no way the addition of unit tests do more harm than good if you're forced to make both ends meet.
-
@kt_ said in Unit Fighting:
ests can serve as a spec but they aren’t a substitute for one, nor are they a reason not to create one.
Have you (Seriously) looked at "Specification by Example"?
-
@boomzilla I think that guy has had more than one "Emperor's New Clothes" moment:
Trying to discover the risks of Adderall is a kind of ridiculous journey. It’s ridiculous because there are two equal and opposite agendas at work. The first agenda tries to scare college kids away from abusing Adderall as a study drug by emphasizing that it’s terrifying and will definitely kill you. The second agenda tries to encourage parents to get their kids treated for ADHD by insisting Adderall is completely safe and anyone saying otherwise is an irresponsible fearmonger. The difference between these two situations is supposed to be whether you have a doctor’s prescription.
-
@mikehurley said in Unit Fighting:
I've found the value of unit testing also depends on the type of code. If your object being tested is more or less an "object router", unit tests probably aren't too useful. If you have a bunch of mocking going on to test a few if-statements, those tests probably aren't worth it and are probably a mess because of all the mocks. Especially if there's a lot of mock data. You could argue that maybe that object isn't all that valuable and should lead to a refactor, but you'd really need per-app context to say that for sure.
That sounds like a system with a really lousy dependency chain. It also sounds like you might notice it because you tried writing tests.
-
@magus said in Unit Fighting:
@mikehurley said in Unit Fighting:
I've found the value of unit testing also depends on the type of code. If your object being tested is more or less an "object router", unit tests probably aren't too useful. If you have a bunch of mocking going on to test a few if-statements, those tests probably aren't worth it and are probably a mess because of all the mocks. Especially if there's a lot of mock data. You could argue that maybe that object isn't all that valuable and should lead to a refactor, but you'd really need per-app context to say that for sure.That sounds like a system with a really lousy dependency chain. It also sounds like you might notice it because you tried writing tests.
As Magnus alluded to, the tests very well may be worth it simply because of highlighting a poor dependency chain that needs to be refactored.
For those doing advanced testing, dependency chain measurements are a very interesting type of low-level (automated) test...
-
@ixvedeusi said in Unit Fighting:
For example, I'd agree that "100% coverage" is a dangerous myth. The complexity of even the simplest modern software system is way too high to even get remotely close to testing all possible states, and insisting on "100% coverage" (by whatever flawed metric) will only produce a huge pile of essentially useless tests.
I'd have replied to this sooner, but I didn't see it until after it was jeffed out of the other topic, which I was pretty much ignoring because it wasn't relevant to me.
I'd like to offer a different perspective. This is what I've done on the hardware side (where "hardware" really means "software model of future hardware") for 20+ years. Not all of this may be applicable to more general software development, but a lot of it could be, if the software world chose to put as much emphasis on quality as the hardware world does.
It's arguably much more important to get high test coverage (and no test failures) in my world than in yours, because it's so much harder to update buggy hardware than buggy software. Once the hardware is in the field, the only options are a very expensive and PR-damaging recall (FDIV, anyone?) or trying to work around the bug in software, which may involve performance hits (why does this sound so familiar?). So great effort is put into making the hardware as not-buggy as possible before it's released.
The effort starts with detailed product specification(s). From these, you create verification plans. Let's say the chip you're working on includes a USB 3 interface, a PCIe interface, and other stuff. You go through the USB 3 spec line-by-line; for every behavior that is specified, you have an item in the verification plan for that behavior. Since USB 3 is backward compatible with earlier versions of USB, you do the same thing for the earlier USB specs, too. If your chip can receive or deliver power over USB, you go through the relevant USB Power Delivery specs. Same for PCIe. Same for every other interface and functional unit in the chip, including (one hopes) internal and proprietary units and interfaces.
You also consider what happens when behavior not covered by the spec happens. What happens when you get an invalid packet on the USB interface? If you get protocol violations on USB and PCIe at the same time? A hot-plug event occurs at the same time as your frobnicator fruubnicotes? Maybe you don't really care what happens, as long as the system doesn't brick itself, but you bleep sure check that you can recover from it.
Now you have a plan for how to test the system, with thousands (perhaps hundreds of thousands) of line item in the plan. Since your product will be EOL before you even finish writing hundreds of thousands of tests, you use a "constrained-random" testing methodology — random, because (in theory) if you let it run long enough, it will hit every possible state in the design, even ones you didn't think were possible/interesting, and constrained, so the randomization spends more effort hitting interesting states/transitions and less effort on states that are invalid or insignificant variations on similar states.
So, you're blindly firing a shotgun at thousands of items in the plan, hoping to hit all of them (as well as ones you didn't think of, which is big benefit if randomized testing). How do you know if you've hit them? Coverage. The language we use for testing our software models of hardware has coverage features built into the language itself, but it doesn't take a lot of effort to roll your own; at one place I worked years ago, before this feature existed in the language (rather, before the language itself existed), we used assertions that wrote non-error messages into the log file, then parsed the log looking for these messages. However one does it, the idea is that one writes a coverpoint for each line item in the verification plan, which writes something into a log file or database indicating that condition has occurred.
Some tool — maybe built into your toolset; maybe a Python or whatever script you write — then examines this log, possibly across multiple runs of your test suite, and determines which items are not covered. You can focus your efforts on aiming your shotgun toward those specific items or, if necessary, making a rifle for a specific item that is hard to hit randomly.
Does this guarantee that every possible bug can be detected? No. But if enough effort is put into doing the verification plan well, the vast majority of them can. And if the coverage is high enough, and the tests are good enough, one can have reasonable confidence that you've caught anything serious.
Are the tests good enough? Ah, that's the rub. The hard part of randomized testing is that the test setup needs to figure out, for any given input, what is the correct output? If the checker makes the same wrong assumptions as the DUT, then you are indeed codifying the bug in the test. Most chip companies attempt to minimize this by having separate teams for design and verification. Design and verification can collaborate to decide what to test and, to some extent, how to test it. But if there are any questions or ambiguities in the spec, the verification team should ask the system architects, "What should happen in this condition?" rather than asking the design team, "What does happen in this condition?"
Is the product bug free? Probably not. Are the tests useless? No. Even if some obscure bug slips through, hundreds of more fundamental bugs have been found and fixed. And each time you fix a bug, you have a suite of tests to check that you didn't break something else in the process (which does happen a lot).
Possibly interesting side note: "Regression" has somehow come to mean something quite different in chip logic verification than it does anywhere else. "Regression test" got shortened to "regression," then broadened to "regression test suite," thence to "test suite — including both regression and new feature tests," then to "the act of running a test suite." Thus usage such as "Add your test to the regression," "Run a mini-regression before you check in," "Did the regression pass?" and "That test has been passing in the regression for weeks, but it failed in last night's foo regression," are perfectly routine and everyone involved understands exactly what is meant, whereas if you were to use "regression" in its standard meaning, everyone would experience a moment of confusion until they remembered the standard definition.
-
@masonwheeler said in Unit Fighting:
Since the test code is a noble, pure, canonical spec, its bugs become authoritative and get enforced rather than fixed.
Not in my world. I've spent more time in the last however-many years debugging test failures caused by test bugs than bugs in the code being tested. I don't have any real statistics, but I'd guess it's probably somewhere between 1.5:1 and 2:1 test bugs vs. code bugs.
-
@masonwheeler said in Unit Fighting:
You've probably got a bunch of code somewhere in there that's 10+ years old, written (along with its tests) by someone who's no longer with the company, that no one is really a subject matter expert on anymore. It's there, it basically works, and no one likes to have to touch it.
I've not seen a lot of that in my world, because hardware designs are generally obsolete long before that. However, I can think of one situation like this. Back when I was designing graphics chips that had to be hardware compatible (in legacy modes) with VGA chips, which had to be hardware compatible with EGA, CGA, MDA, ... which had incomplete (public) specifications and all sorts of weird timing gotchas and stuff.
Most of the problem, of course, was that we didn't have comprehensive test suites. The only way we had to really be sure we were compatible was to make the chip and throw all kinds of games and other software at it and if it looked the same as a genuine IBM VGA and didn't crash (at least any more often than the real thing), then it worked. Once it worked, you never, ever touched that part of the logic again, ever, for any reason.
If we did have a comprehensive test suite, changing that code wouldn't have been nearly as scary. Of course, it still wouldn't have been changed without very good reason, because it was really fragile, and because it probably would have taken a month just to run the bloody test suite with the computers of that era.
-
@boomzilla said in Unit Fighting:
I'm actually looking at a failing test right now and trying to figure out if the problem is with the test or the code.
That what I spend probably 70 or 80% of my time doing. If it's a problem with the test or test infrastructure, I fix it (or give it to the guy who wrote that test or that part of the test infrastructure). If it's a bug in the code that's part of the chip itself, I file a bug report with enough information, including log files, waveforms*, instructions to reproduce, etc., that I can say something like "At 800ns, data should be cf instead of df, and signal3 should be 0 instead of 1." Obviously, it takes a fair bit of debugging to get to that point.
*
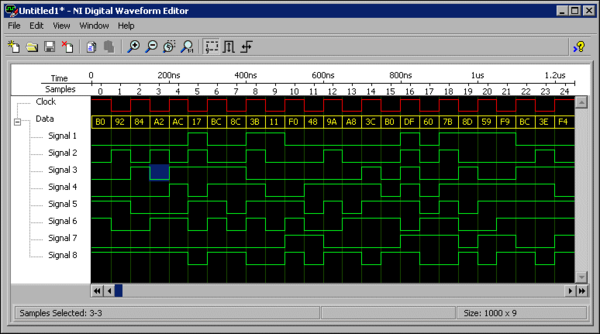
-
@thecpuwizard said in Unit Fighting:
More and more companies are adopting this approach and minimizing (Sometimes eliminating) system level testing.
I worked for a company that wanted to do that for the blocks that went into their chips, too. Define a standardized interface between each of the blocks in the chip. Test very thoroughly that each of the blocks implements its interface correctly. Connect the blocks together, and it Just Works™.
There were a few problems. One, a lot of the blocks had direct, sideband connections that weren't part of that well defined interface.
Second, there were interactions that weren't necessarily covered in the interface spec, like block A produces data every n clock cycles, so B has to consume it at the same rate. No problem, that's well within the interface's data transfer rate. Except blocks C, D, E, F, ... might also be using the interface at the same time.
Third, and perhaps most importantly, this transferred the bulk of the verification effort to verifying the individual blocks. However, the schedule for verifying the blocks was not adjusted to match the more stringent requirements.
-
@hardwaregeek said in Unit Fighting:
Possibly interesting side note: "Regression" has somehow come to mean something quite different in chip logic verification than it does anywhere else. "Regression test" got shortened to "regression," then broadened to "regression test suite," thence to "test suite — including both regression and new feature tests," then to "the act of running a test suite." Thus usage such as "Add your test to the regression," "Run a mini-regression before you check in," "Did the regression pass?" and "That test has been passing in the regression for weeks, but it failed in last night's foo regression," are perfectly routine and everyone involved understands exactly what is meant, whereas if you were to use "regression" in its standard meaning, everyone would experience a moment of confusion until they remembered the standard definition.
Similar thing happened in software world with Continuous Integration. I don't know if it's universal (it certainly was within my international megacorporation), but instead of the intended meaning of "philosophy of running automated tests all the time, especially before and after committing code", we used it to refer either to the test suite, the server running the test suite, or the team maintaining those servers. "It didn't pass CI." "CI's been acting strange since morning." "I've finally got a reply from CI."
-
@the_quiet_one said in Unit Fighting:
In other words, in order for bugs to be introduced in this manner, you would have to coincidentally make the same exact mistake on the code itself and its corresponding unit test at the same time.
Such coincidences would be likely an indication that the software engineer has a misunderstanding of the requirements and/or design of the product their coding,
This is why, in the hardware world, most companies have separate teams writing tests, to reduce the likelihood of making the same wrong assumptions.
-
@gąska said in Unit Fighting:
95% is very realistic
It's pretty reasonable to get to that sort of level. Going higher than that requires stuff like injecting mocks into private variables, and that sort of mocking has a nasty tendency to make the code far more brittle as you end up testing the internal structure of the implementation. It's better to outright design for testability, but that's irritatingly uncommon and quite annoying to add after the fact.
@gąska said in Unit Fighting:
Having total (or near-total) coverage makes refactoring very easy.
Alas, not always. I've got a code module that I maintain at work with coverage at about 99.98%, and doing any changes to it is horrible because the tests encode exactly all the algorithms that the original author used: it does crazy things like checking the ordering of calls to the comparator function in the sorting that it is using internally for some of its collections of things (because why would you trust the authors of Python to get a sorting algorithm right?). That's the level of stupid in testing that you're better off without, and it just makes doing anything with the code difficult.
Unit tests should check result conditions against something you could at least predict in advance, given the spec. Otherwise they're just experiments, not tests. Like that, if you see an unexpected failure you can answer “which is wrong,
the chicken or the eggthe code or the test?” without having to resort to guesswork. (This sort of thing makes good testing of GUI toolkits hard, precisely because there's so much in those that is determined by the environment, and environments churn a lot.)And unit tests aren't a substitute for integration tests. No matter how well you unit test that your round peg and square hole work fine on their own, hammering one into the other is still Doing It Wrong™.
-
@hardwaregeek said in Unit Fighting:
@thecpuwizard said in Unit Fighting:
More and more companies are adopting this approach and minimizing (Sometimes eliminating) system level testing.
I worked for a company that wanted to do that for the blocks that went into their chips, too. .....
I never said it was easy <grin>. My background is also hardware (long ago, in a defense industry far away) including chip design, so I completely get what you are talking about.
But even back then there were systems that simply could not be tested before production [think SpaceLab], so being able to test sub-systems with a high degree of confidence was critical.
Some of the work today in "pure software" (e.g. business apps) that reduced (or even eliminates) the need for full system testing can be traced back to these origins.
-
@gleemonk said in Unit Fighting:
@magus said in Unit Fighting:
We're in an industry where Fizzbuzz eliminates 80% of
peoplecandidates.The people who pass Fizzbuzz are not on the market often. That skews the results.
Relevant:
 News
News

Everyone thinks they’re hiring the top 1%. Martin Fowler: “We are still working hard to hire only the very top fraction of software developers (the target is around the top 0.5 to …
-
@pjh
Good news for the 199! @cartman82's boss is on another hiring spree!
-
@dkf said in Unit Fighting:
It's better to outright design for testability, but that's irritatingly uncommon
"DFT" is very much a thing in the hardware world, but it means something quite different — design for (manufacturing) testability — being able to detect manufacturing defects. What you're talking about, we'd call DFV — design for verifiability — and it is irritatingly uncommon.
-
@thecpuwizard said in Unit Fighting:
@hardwaregeek said in Unit Fighting:
@thecpuwizard said in Unit Fighting:
More and more companies are adopting this approach and minimizing (Sometimes eliminating) system level testing.
I worked for a company that wanted to do that for the blocks that went into their chips, too. .....
I never said it was easy <grin>. My background is also hardware (long ago, in a defense industry far away) including chip design, so I completely get what you are talking about.
But even back then there were systems that simply could not be tested before production [think SpaceLab], so being able to test sub-systems with a high degree of confidence was critical.
Some of the work today in "pure software" (e.g. business apps) that reduced (or even eliminates) the need for full system testing can be traced back to these origins.
Of course, the company I worked for wasn't doing anything like that; they were just trying to be Better! Faster!! Cheaper!!! (Pick any two (at most, if you're lucky (but not the first one))) Not that that is necessarily a bad thing, but they did not implement it well.
-
@hardwaregeek said in Unit Fighting:
"DFT" is very much a thing in the hardware world, but it means something quite different
I first read that as "DTF" and that is very different indeed.
-
@hungrier Indeed. I was unfamiliar with the meaning of that, but Urban Dictionary has enlightened me. Or something.
-
-
When I read
DFT, I think Density Functional Theory.
-
@hardwaregeek said in Unit Fighting:
"DFT" is very much a thing in the hardware world
@benjamin-hall said in Unit Fighting:
When I read DFT, I think Density Functional Theory.
Myself, I spent a moment wondering wtf the Discrete Fourier Transform had to do with testing...
-
@ixvedeusi I always used that as the Fast Fourier Transform, so that wasn't a problem.
-
@the_quiet_one said in Unit Fighting:
There's no way the addition of unit tests do more harm than good if you're forced to make both ends meet.
Folks, remember the song:

If you need a test case, stop!
and code right away!
Commit and push
and be on your way!
-
@greybeard If I had an alt I would have given you two likes. As a father to a two year old, I know exactly how this song goes.
-
@pjh said in Unit Fighting:
@gleemonk said in Unit Fighting:
@magus said in Unit Fighting:
We're in an industry where Fizzbuzz eliminates 80% of
peoplecandidates.The people who pass Fizzbuzz are not on the market often. That skews the results.
Relevant:
News
Everyone thinks they’re hiring the top 1%. Martin Fowler: “We are still working hard to hire only the very top fraction of software developers (the target is around the top 0.5 to …
Great article. It's funny because I've been both kinds of candidates - in USA, I applied for every job I could find on Indeed, Monster, Dice and Craigslist that half-matched my profile - over a year it was about 150-200 applications, and only got 1 interview and 0 offers. On the other hand, after Christmas I've started looking for job in Poland. Sent one application total, and got two offers - one from them, and one from random recruiter on Linkedin. And I only applied because it's the only Rust company in the whole country - I could easily find a job through my existing contacts.
-
@gąska My experience with Dice has been interesting; it took 6 months before anyone even started trying to call me.
At that point, they started calling and emailing all the time - mostly recruiters. It was just interesting that I never really submitted my resume anywhere directly, except Microsoft, who ignored me completely.
-
@the_quiet_one References to scatological songs are apparently my new thing.
-
So, about mocking.
The problem with mocking is, you need to hardcode values and thus internal stare of the class under test. If I set up this property, it means it’ll be used, right?
Setting up mocks using a mocking library makes tests fragile. If implementation details change, the test will start to fail, because your mock isn’t set up correctly.
My experience tells me to mock only the absolutely necessary dependencies, while using actual objects wherever I can.
I’m interested in your opinions.
-
@kt_ said in Unit Fighting:
So, about mocking.
The problem with mocking is, you need to hardcode values and thus internal stare of the class under test. If I set up this property, it means it’ll be used, right?
Setting up mocks using a mocking library makes tests fragile. If implementation details change, the test will start to fail, because your mock isn’t set up correctly.
My experience tells me to mock only the absolutely necessary dependencies, while using actual objects wherever I can.
I’m interested in your opinions.
I see mocking as most useful for testing error conditions that would otherwise be difficult to simulate. Make a fake
FileStreamthat says the disk is full after the first write, or aTcpConnectionthat takes 20 seconds to send a packet, for example.
-
@ben_lubar said in Unit Fighting:
@kt_ said in Unit Fighting:
So, about mocking.
The problem with mocking is, you need to hardcode values and thus internal stare of the class under test. If I set up this property, it means it’ll be used, right?
Setting up mocks using a mocking library makes tests fragile. If implementation details change, the test will start to fail, because your mock isn’t set up correctly.
My experience tells me to mock only the absolutely necessary dependencies, while using actual objects wherever I can.
I’m interested in your opinions.
I see mocking as most useful for testing error conditions that would otherwise be difficult to simulate. Make a fake
FileStreamthat says the disk is full after the first write, or aTcpConnectionthat takes 20 seconds to send a packet, for example.That’s exactly what I mean. But quite often, you don’t need to have control over the dependency in order to test.
-
@ben_lubar said in Unit Fighting:
I see mocking as most useful for testing error conditions that would otherwise be difficult to simulate. Make a fake
FileStreamthat says the disk is full after the first write, or aTcpConnectionthat takes 20 seconds to send a packet, for example.Yes, except then you've got to make your code in such a way that it is reasonably practical to plug that mock in without doing a horrendous amount of other work too. It's not too bad if you have in mind doing this from the beginning… but otherwise it's pretty awful.