Discussion of NodeBB Updates
-
-
-
@julianlam said in Discussion of NodeBB Updates:
The red boob conundrum is still being bounced around internally... We also don't call it a red boob, (...)
How It is called iinternally? Dick top-down?
-
@julianlam said in Discussion of NodeBB Updates:
Name suggestions welcome
Circle-avatar post-status minimized-window-subsystem interaction icon.
Note too that the icon isn't always a ➕, it sometimes turns into a 🔄 while submitting a post.
Filed under: NodeBB thing we don't know what it does
-
@ben_lubar said in NodeBB Updates:
I will be upgrading MongoDB from 3.4.2 to 3.6.2 at 02:00 UTC. [rainbows]
There should be very little downtime, probably significantly less than five minutes.
Whoops, I probably shouldn't have been helping my dad with his computer this close to when the script would activate.
-
@ben_lubar oh, is that what happened?

-
@anotherusername said in Discussion of NodeBB Updates:
@ben_lubar oh, is that what happened?
Yeah, sorry about that. We're on MongoDB 3.6.2 now, at least.
-
@ben_lubar said in Discussion of NodeBB Updates:
@anotherusername said in Discussion of NodeBB Updates:
@ben_lubar oh, is that what happened?
Yeah, sorry about that. We're on MongoDB 3.6.2 now, at least.
At least? So you don't even know what version we are on?

-
@polygeekery said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
@anotherusername said in Discussion of NodeBB Updates:
@ben_lubar oh, is that what happened?
Yeah, sorry about that. We're on MongoDB 3.6.2 now, at least.
At least? So you don't even know what version we are on?
My goal secretly wasn't to update, but to put the MongoDB server into replica set mode so I could take backups that were actually consistent. The update was just an extra thing we got as a bonus.
-
@ben_lubar said in Discussion of NodeBB Updates:
My goal secretly wasn't to update, but to put the MongoDB server into replica set mode so I could take backups that were actually consistent.
Or in other words, to enable backups.
-
@unperverted-vixen said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
My goal secretly wasn't to update, but to put the MongoDB server into replica set mode so I could take backups that were actually consistent.
Or in other words, to enable backups.
I was already taking backups; they'd just have the last few minutes of data in an inconsistent state (forum posts might be in the database but not the manually-maintained index, for example).
-
@ben_lubar said in Discussion of NodeBB Updates:
@unperverted-vixen said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
My goal secretly wasn't to update, but to put the MongoDB server into replica set mode so I could take backups that were actually consistent.
Or in other words, to enable backups.
I was already taking backups; they'd just have the last few minutes of data in an inconsistent state (forum posts might be in the database but not the manually-maintained index, for example).
2018-01-21T02:37:04.712+0000 MuxIn close 0.objects 2018-01-21T02:37:04.713+0000 Mux close namespace 0.objects 2018-01-21T02:37:04.713+0000 done dumping 0.objects (32796326 documents) 2018-01-21T02:37:04.713+0000 ending dump routine with id=3, no more work to do 2018-01-21T02:37:04.713+0000 dump phase III: the oplog 2018-01-21T02:37:04.714+0000 checking if oplog entry 6513325635325132802 still exists 2018-01-21T02:37:04.714+0000 oldest oplog entry has timestamp 6513321155674243073 2018-01-21T02:37:04.714+0000 oplog entry 6513325635325132802 still exists 2018-01-21T02:37:04.714+0000 writing captured oplog to 2018-01-21T02:37:04.714+0000 MuxIn open .oplog 2018-01-21T02:37:04.719+0000 Mux open namespace .oplog 2018-01-21T02:37:04.723+0000 counted 1190 documents in .oplog 2018-01-21T02:37:04.742+0000 MuxIn close .oplog 2018-01-21T02:37:04.743+0000 Mux close namespace .oplog 2018-01-21T02:37:04.743+0000 dumped 1190 oplog entries 2018-01-21T02:37:04.743+0000 checking again if oplog entry 6513325635325132802 still exists 2018-01-21T02:37:04.743+0000 oldest oplog entry has timestamp 6513321155674243073 2018-01-21T02:37:04.743+0000 oplog entry 6513325635325132802 still exists 2018-01-21T02:37:04.743+0000 finishing dump 2018-01-21T02:37:04.743+0000 Mux finish 2018-01-21T02:37:04.743+0000 mux completed successfully1190 documents in oplog. That's 1190 changes that may or may not have been included in the backup previously.
-
@ben_lubar said in Discussion of NodeBB Updates:
I was already taking backups; they'd just have the last few minutes of data in an inconsistent state (forum posts might be in the database but not the manually-maintained index, for example).
I figured that you were taking backups already (or you wouldn't know they were inconsistent!). I was snarking about how an inconsistent database backup is arguably just as bad as having no backup at all.
Maybe in NodeBB's case it's not the end of the world, if all you have to do after restoring a backup is rebuild all of the indexes. But in general I would say relying on inconsistent backups isn't good practice.
-
@unperverted-vixen said in Discussion of NodeBB Updates:
an inconsistent database backup is arguably just as bad as having no backup at all
If the potential for inconsistency is known and limited ("the last few minutes") then it's definitely better to have them than not at all.
-
@polygeekery said in Discussion of NodeBB Updates:
@julianlam red boob, with nipple tape
-
@anotherusername said in Discussion of NodeBB Updates:
@unperverted-vixen said in Discussion of NodeBB Updates:
an inconsistent database backup is arguably just as bad as having no backup at all
If the potential for inconsistency is known and limited ("the last few minutes") then it's definitely better to have them than not at all.
If you know that it's always the last few minutes, then it's not inconsistent. Known and inconsistent are (sort of) opposites.

-
@anotherusername said in Discussion of NodeBB Updates:
@unperverted-vixen said in Discussion of NodeBB Updates:
an inconsistent database backup is arguably just as bad as having no backup at all
If the potential for inconsistency is known and limited ("the last few minutes") then it's definitely better to have them than not at all.
In MongoDB backups created using
mongodumpwithout--oplog, it is undefined which version of a document that gets added, changed, or deleted between the start and end of the backup process will appear in the backup. With--oplog, that's still true, but the changes that happened since the start of the backup are recorded at the end of the backup andmongorestorecan apply those changes if you specify--oplogReplay.Here's the catch:
--oplogonly works if the server is in a replica set.--oplogand--oplogReplayonly work if you're backing up or restoring an entire server, but that's less of an issue because you can restore to a temporary server and then copy a database or collection from there if you don't want to restore the whole thing.You can make a single server into the master of a 1-server replica set pretty easily, which makes me question why MongoDB even has a standalone mode. Why have your database server default to a "lose data randomly" option, even if you're going to add that option?
As a side note, sometimes it is useful to make a database be less safe. A great example is when you're doing an offline operation that you can restart from a backup faster than you can repair a database and resume whatever operation you were doing. You would turn the safety features back on before going back online, though. *cough*
-
@unperverted-vixen said in Discussion of NodeBB Updates:
if all you have to do after restoring a backup is rebuild all of the indexes
No, that's not really something NodeBB is set up to do. These aren't database indexes, they're Redis sorted sets.
I'm currently trying to get NodeBB on PostgreSQL:
 PostgreSQL database driver by BenLubar · Pull Request #5861 · NodeBB/NodeBB
PostgreSQL database driver by BenLubar · Pull Request #5861 · NodeBB/NodeBB
because the world needs more confusing SQL schemas
The next step after that is to deprecate Redis and make NodeBB use actual tables and rows and columns and keys and indexes and data types and falls over, starts foaming at mouth
-
@ben_lubar That's okay, I started doing the same thing once you said "Redis". ;)
-
@julianlam said in Discussion of NodeBB Updates:
The red boob conundrum is still being bounced around internally

-
@julianlam said in Discussion of NodeBB Updates:
The red boob conundrum is still being bounced around internally...
Can't you at least change the symbol to "" ? It's the closest thing to "minimize" in my head.
-
@julianlam said in Discussion of NodeBB Updates:
Filed under: Name suggestions welcome
Suggestion: replace your designer with someone who has a sense of humor.
(Disclaimer: Don't actually do this, they will sue your pants off.)
-
@anonymous234 said in Discussion of NodeBB Updates:
Can't you at least change the symbol to "" ? It's the closest thing to "minimize" in my head.
I'm pretty sure it's already been brought up, but would make sense for minimize and it could switch to once it's actually a restore button.
-
@anonymous234 said in Discussion of NodeBB Updates:
@julianlam said in Discussion of NodeBB Updates:
The red boob conundrum is still being bounced around internally...
Can't you at least change the symbol to "" ? It's the closest thing to "minimize" in my head.
That's a good one, I like it.
Certainly better than the minimize icon in font awesome, which looks like a fat hairy dash.
No offense meant to any fat hairy dashes.
-
-
@pie_flavor said in Discussion of NodeBB Updates:
@luhmann If the gerbil abuse thing is a meme, then I'm
 ing, but my complaint has always been that it's slower than Discourse.
ing, but my complaint has always been that it's slower than Discourse.Reference to Ember's logo. Discourse uses Ember.
-
2018-01-21T09:20:52.158+0000 0.objects 6.66GB 2018-01-21T09:20:53.054+0000 demux namespaceHeader: {0 objects true -1333268303289254875} 2018-01-21T09:20:53.055+0000 demux checksum for namespace 0.objects is correct (-1333268303289254875), 7148359429 bytes 2018-01-21T09:20:53.055+0000 demux namespaceHeader: { oplog false 0} 2018-01-21T09:20:53.055+0000 demux Open 2018-01-21T09:20:53.088+0000 ending restore routine with id=3, no more work to do 2018-01-21T09:20:53.088+0000 ending restore routine with id=0, no more work to do 2018-01-21T09:20:53.327+0000 0.objects 6.66GB 2018-01-21T09:20:53.327+0000 restoring indexes for collection 0.objects from metadata 2018-01-21T10:10:55.901+0000 finished restoring 0.objects (32796326 documents) 2018-01-21T10:10:55.902+0000 ending restore routine with id=1, no more work to do 2018-01-21T10:29:58.589+0000 finished restoring 0.searchpost (1285812 documents) 2018-01-21T10:29:58.589+0000 ending restore routine with id=2, no more work to do 2018-01-21T10:29:58.633+0000 replaying oplog 2018-01-21T10:30:01.172+0000 oplog 28.1KB 2018-01-21T10:30:03.308+0000 oplog 74.5KB panic: send on closed channel goroutine 32 [running]: panic(0x802e80, 0xc42d03fa10) /opt/go/src/runtime/panic.go:500 +0x1a1 github.com/mongodb/mongo-tools/common/archive.(*RegularCollectionReceiver).Write(0xc4200f6000, 0xc420178010, 0x29b, 0x1000000, 0xc420100748, 0x1, 0x0) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/common/archive/demultiplexer.go:334 +0x67 github.com/mongodb/mongo-tools/common/archive.(*Demultiplexer).BodyBSON(0xc42417a000, 0xc420178010, 0x29b, 0x1000000, 0x0, 0x0) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/common/archive/demultiplexer.go:214 +0x1d2 github.com/mongodb/mongo-tools/common/archive.(*Parser).ReadBlock(0xc420178000, 0xf181c0, 0xc42417a000, 0x0, 0x0) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/common/archive/parser.go:147 +0x166 github.com/mongodb/mongo-tools/common/archive.(*Parser).ReadAllBlocks(0xc420178000, 0xf181c0, 0xc42417a000, 0x0, 0x0) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/common/archive/parser.go:111 +0x57 github.com/mongodb/mongo-tools/common/archive.(*Demultiplexer).Run(0xc42417a000, 0x7fdb6bc2a4b0, 0x7fc080) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/common/archive/demultiplexer.go:67 +0xd9 github.com/mongodb/mongo-tools/mongorestore.(*MongoRestore).Restore.func1(0xc4200d39b0, 0xc4200e4380, 0xc4200e61e0) /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/mongorestore/mongorestore.go:409 +0x36 created by github.com/mongodb/mongo-tools/mongorestore.(*MongoRestore).Restore /data/mci/9f64f943125fbb3748765d4ec9ec29ae/src/src/mongo/gotools/.gopath/src/github.com/mongodb/mongo-tools/mongorestore/mongorestore.go:411 +0xc79
-
For anyone who doesn't know Go, that error message always means the programmer did something wrong.
Closing a channel signals the receivers that nothing else will ever come through it. You do not need to close a channel for it to be garbage collected. Channels should never be closed if any thread is going to send things through them in the future.
-
@pie_flavor
How can you state that? You where not around when we where on Discourse. It. Was. Slow.
-
@ben_lubar said in Discussion of NodeBB Updates:
For anyone who doesn't know Go, that error message always means the programmer did something wrong.
Closing a channel signals the receivers that nothing else will ever come through it. You do not need to close a channel for it to be garbage collected. Channels should never be closed if any thread is going to send things through them in the future.
-
@ben_lubar said in Discussion of NodeBB Updates:
the programmer did something wrong.
Using mongodb? Developing mongodb?
-
@hungrier said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
the programmer did something wrong.
Using mongodb? Developing mongodb?
The latter.
I'm running mongorestore built with the Go race detector.
It might, uh, take a while...
-
@ben_lubar said in Discussion of NodeBB Updates:
@hungrier said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
the programmer did something wrong.
Using mongodb? Developing mongodb?
The latter.
I'm running mongorestore built with the Go race detector.
It might, uh, take a while...
2018-01-21T14:45:15.053-0600 0.objects 150MB ⋮ 2018-01-21T14:52:36.053-0600 0.objects 200MBOk, if my math is right, that's 113.38 kBps, so there's probably more than 16 hours in this run. See you tomorrow for the results!
-
@ben_lubar are you backing up to your PC in Milwaukee?
-
@polygeekery said in Discussion of NodeBB Updates:
@ben_lubar are you backing up to your PC in Milwaukee?
No, the backup is already on that PC, and the MongoDB server is on the same machine. I'm just running the restore with Go's race detector enabled, which makes programs significantly slower and use more memory but also reports where they are broken.
-
@ben_lubar said in Discussion of NodeBB Updates:
@hungrier said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
the programmer did something wrong.
Using mongodb? Developing mongodb?
The latter.
I'm running mongorestore built with the Go race detector.
It might, uh, take a while...
Instead of waiting for that, I just found the reason and stopped the slow thing:
-
@tsaukpaetra that's not what i get when i GIS for "fat hairy dash"
something tells me that my search history has polluted google's mind.
-
@darkmatter said in Discussion of NodeBB Updates:
@tsaukpaetra that's not what i get when i GIS for "fat hairy dash"
something tells me that my search history has polluted google's mind.To be fair, those weren't the only keywords in the search bar. :face_with_stuck-out_tongue_closed_eyes:
Filed under: I may have omitted the "hairy"
-
Ok, the restore process is getting close to the oplog part. Here's the index build time for the
objectscollection:2018-01-22T06:05:27.408+0000 I INDEX [conn2] build index done. scanned 32796326 total records. 5957 secs 2018-01-22T06:05:32.295+0000 I COMMAND [conn2] command 0.$cmd command: createIndexes { createIndexes: "objects", indexes: [ { name: "expireAt_1", ns: "0.objects", expireAfterSeconds: 0, background: true, key: { expireAt: 1 } }, { sparse: true, ns: "0.objects", background: true, unique: true, name: "_key_1_value_-1", key: { _key: 1, value: -1 } }, { name: "_key_1_score_-1", ns: "0.objects", background: true, key: { _key: 1, score: -1 } } ], $db: "0" } numYields:281539 reslen:238 locks:{ Global: { acquireCount: { r: 281543, w: 281543 } }, Database: { acquireCount: { w: 281543, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 2318689 } }, Collection: { acquireCount: { w: 281540 } }, oplog: { acquireCount: { w: 3 } } } protocol:op_query 5963180msThere's another index build currently at 1165400/1285812, which I believe is the post search index. In an ideal world, that would be a regular index on a regular table in a regular database, but we can't always get what we want.
-
@ben_lubar said in Discussion of NodeBB Updates:
@unperverted-vixen said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
My goal secretly wasn't to update, but to put the MongoDB server into replica set mode so I could take backups that were actually consistent.
Or in other words, to enable backups.
I was already taking backups; they'd just have the last few minutes of data in an inconsistent state (forum posts might be in the database but not the manually-maintained index, for example).
Something about this post horrifies me, but I'm not quite sure what it is
-
@ben_lubar said in Discussion of NodeBB Updates:
but we can't always get what we want.
Did you get what you needed?
-
@sloosecannon said in Discussion of NodeBB Updates:
Something about this post horrifies me, but I'm not quite sure what it is
My guess is "manually-maintained index" is triggering SSDS trauma.
-
@ben_lubar said in Discussion of NodeBB Updates:
Ok, the restore process is getting close to the oplog part. Here's the index build time for the
objectscollection:2018-01-22T06:05:27.408+0000 I INDEX [conn2] build index done. scanned 32796326 total records. 5957 secs 2018-01-22T06:05:32.295+0000 I COMMAND [conn2] command 0.$cmd command: createIndexes { createIndexes: "objects", indexes: [ { name: "expireAt_1", ns: "0.objects", expireAfterSeconds: 0, background: true, key: { expireAt: 1 } }, { sparse: true, ns: "0.objects", background: true, unique: true, name: "_key_1_value_-1", key: { _key: 1, value: -1 } }, { name: "_key_1_score_-1", ns: "0.objects", background: true, key: { _key: 1, score: -1 } } ], $db: "0" } numYields:281539 reslen:238 locks:{ Global: { acquireCount: { r: 281543, w: 281543 } }, Database: { acquireCount: { w: 281543, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 2318689 } }, Collection: { acquireCount: { w: 281540 } }, oplog: { acquireCount: { w: 3 } } } protocol:op_query 5963180msThere's another index build currently at 1165400/1285812, which I believe is the post search index. In an ideal world, that would be a regular index on a regular table in a regular database, but we can't always get what we want.
Ok, it failed again on the oplog part, and there's no error message in the mongod log, which tells me that the backup is broken.
I took another backup overnight and will now restore it, so hopefully that will work better.
If not, it's not the end of the world, since the oplog only matters for the last few minutes of data changes.
-
@ben_lubar said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
Ok, the restore process is getting close to the oplog part. Here's the index build time for the
objectscollection:2018-01-22T06:05:27.408+0000 I INDEX [conn2] build index done. scanned 32796326 total records. 5957 secs 2018-01-22T06:05:32.295+0000 I COMMAND [conn2] command 0.$cmd command: createIndexes { createIndexes: "objects", indexes: [ { name: "expireAt_1", ns: "0.objects", expireAfterSeconds: 0, background: true, key: { expireAt: 1 } }, { sparse: true, ns: "0.objects", background: true, unique: true, name: "_key_1_value_-1", key: { _key: 1, value: -1 } }, { name: "_key_1_score_-1", ns: "0.objects", background: true, key: { _key: 1, score: -1 } } ], $db: "0" } numYields:281539 reslen:238 locks:{ Global: { acquireCount: { r: 281543, w: 281543 } }, Database: { acquireCount: { w: 281543, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 2318689 } }, Collection: { acquireCount: { w: 281540 } }, oplog: { acquireCount: { w: 3 } } } protocol:op_query 5963180msThere's another index build currently at 1165400/1285812, which I believe is the post search index. In an ideal world, that would be a regular index on a regular table in a regular database, but we can't always get what we want.
Ok, it failed again on the oplog part, and there's no error message in the mongod log, which tells me that the backup is broken.
I took another backup overnight and will now restore it, so hopefully that will work better.
If not, it's not the end of the world, since the oplog only matters for the last few minutes of data changes.
If this were important production data, first of all it wouldn't be in MongoDB, but more importantly, I could take a consistent backup by stopping NodeBB, stopping MongoDB, and copying MongoDB's data directory.
-
@ben_lubar said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
Ok, the restore process is getting close to the oplog part. Here's the index build time for the
objectscollection:2018-01-22T06:05:27.408+0000 I INDEX [conn2] build index done. scanned 32796326 total records. 5957 secs 2018-01-22T06:05:32.295+0000 I COMMAND [conn2] command 0.$cmd command: createIndexes { createIndexes: "objects", indexes: [ { name: "expireAt_1", ns: "0.objects", expireAfterSeconds: 0, background: true, key: { expireAt: 1 } }, { sparse: true, ns: "0.objects", background: true, unique: true, name: "_key_1_value_-1", key: { _key: 1, value: -1 } }, { name: "_key_1_score_-1", ns: "0.objects", background: true, key: { _key: 1, score: -1 } } ], $db: "0" } numYields:281539 reslen:238 locks:{ Global: { acquireCount: { r: 281543, w: 281543 } }, Database: { acquireCount: { w: 281543, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 2318689 } }, Collection: { acquireCount: { w: 281540 } }, oplog: { acquireCount: { w: 3 } } } protocol:op_query 5963180msThere's another index build currently at 1165400/1285812, which I believe is the post search index. In an ideal world, that would be a regular index on a regular table in a regular database, but we can't always get what we want.
Ok, it failed again on the oplog part, and there's no error message in the mongod log, which tells me that the backup is broken.
I took another backup overnight and will now restore it, so hopefully that will work better.
If not, it's not the end of the world, since the oplog only matters for the last few minutes of data changes.
If this were important production data, first of all it wouldn't be in MongoDB, but more importantly, I could take a consistent backup by stopping NodeBB, stopping MongoDB, and copying MongoDB's data directory.
Why stop NodeBB? Shouldn't the application be able to recover database connections?
-
@tsaukpaetra said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
@ben_lubar said in Discussion of NodeBB Updates:
Ok, the restore process is getting close to the oplog part. Here's the index build time for the
objectscollection:2018-01-22T06:05:27.408+0000 I INDEX [conn2] build index done. scanned 32796326 total records. 5957 secs 2018-01-22T06:05:32.295+0000 I COMMAND [conn2] command 0.$cmd command: createIndexes { createIndexes: "objects", indexes: [ { name: "expireAt_1", ns: "0.objects", expireAfterSeconds: 0, background: true, key: { expireAt: 1 } }, { sparse: true, ns: "0.objects", background: true, unique: true, name: "_key_1_value_-1", key: { _key: 1, value: -1 } }, { name: "_key_1_score_-1", ns: "0.objects", background: true, key: { _key: 1, score: -1 } } ], $db: "0" } numYields:281539 reslen:238 locks:{ Global: { acquireCount: { r: 281543, w: 281543 } }, Database: { acquireCount: { w: 281543, W: 2 }, acquireWaitCount: { W: 2 }, timeAcquiringMicros: { W: 2318689 } }, Collection: { acquireCount: { w: 281540 } }, oplog: { acquireCount: { w: 3 } } } protocol:op_query 5963180msThere's another index build currently at 1165400/1285812, which I believe is the post search index. In an ideal world, that would be a regular index on a regular table in a regular database, but we can't always get what we want.
Ok, it failed again on the oplog part, and there's no error message in the mongod log, which tells me that the backup is broken.
I took another backup overnight and will now restore it, so hopefully that will work better.
If not, it's not the end of the world, since the oplog only matters for the last few minutes of data changes.
If this were important production data, first of all it wouldn't be in MongoDB, but more importantly, I could take a consistent backup by stopping NodeBB, stopping MongoDB, and copying MongoDB's data directory.
Why stop NodeBB? Shouldn't the application be able to recover database connections?
Stop NodeBB before stopping MongoDB so that MongoDB isn't in the middle of a request. You'd need some sort of graceful shutdown where NodeBB finishes up any pending requests but doesn't accept new ones, but you could get an even better result if you used a database that supported transactions.
-
I decided to try running MongoDB on my Windows machine's SSD.
2018-01-22T13:15:41.014-0600 finished restoring 0.objects (32809525 documents) 2018-01-22T13:15:41.014-0600 ending restore routine with id=3, no more work to do 2018-01-22T13:15:41.015-0600 replaying oplog 2018-01-22T13:15:41.202-0600 demux namespaceHeader: { oplog true -3128193628598373497} 2018-01-22T13:15:41.202-0600 applied 169 ops 2018-01-22T13:15:41.203-0600 demux checksum for namespace .oplog is correct (-3128193628598373497), 30335 bytes 2018-01-22T13:15:41.221-0600 demux End 2018-01-22T13:15:41.221-0600 demux finishing (err:<nil>) 2018-01-22T13:15:41.222-0600 doneThe oplog section took 0.188 seconds. For the record, I started the command at
2018-01-22T12:53:05.023-0600.
-
@ben_lubar said in Discussion of NodeBB Updates:
manually-maintained index
JFC, Ben, we post a lot how do you manage to find the time to write those?
-
@ben_lubar said in Discussion of NodeBB Updates:
if you used a database that supported transactions.
wat
-
Let's play "find the bottleneck".
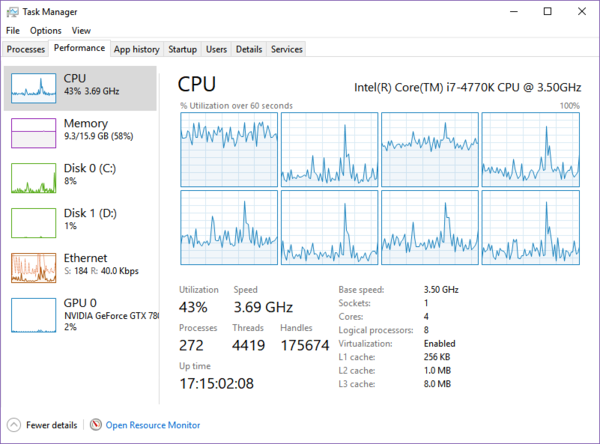
MongoDB, this script, and PostgreSQL are all running on the same SSD (
D:). None of them have any OS-imposed limits on CPU, network, disk, or RAM usage.Why is the script not running faster?

 Loading...
Loading...
{kind=link}