CSVs ought to be in ASCII
-
Sometimes, Microsoft just makes you wonder what they are thinking.
I happen to have some code that generates a CSV that contains, among other things, a list of student names (it'll also contain automatic marking info). Some of those student names contain diacritics (because that's how things go). No big deal, just make sure the CSV is written out as UTF-8 (the system encoding on Macs and Linux) and write it out like that. Job done.
Then double-click on the resulting file to open in Excel for Mac to get the mojibake experience!
 Because when opening a CSV you don't use the platform's default encoding! It doesn't even work when you put a BOM at the beginning of the file or choose an explicit import using UTF-8 (unless you like the diacritics converted to underscores). Huh.
Because when opening a CSV you don't use the platform's default encoding! It doesn't even work when you put a BOM at the beginning of the file or choose an explicit import using UTF-8 (unless you like the diacritics converted to underscores). Huh.What about if we export a file from Excel with these characters in? Surely that will work. Well, on output it generates the file using Mac Latin (:WTF:?! Nobody else has used that in the OSX era.) and when reading it back in, the same file it generated, it really assumes that it's CP1250, the Windows Western European encoding (a.k.a., not-quite-ISO8859-1). Well done, Microsoft, you've made some software that can't even round-trip with itself let alone with any sane tool, at least not without making a whole bunch of twiddly adjustments along the way.
What's better, the bug report on this has a truly pathetic corporate response:
Excel for Mac does not currently support UTF-8.
If this is a feature you’d like to see in future versions of Office for Mac, be sure to send your feedback by clicking “Help” > “Send Feedback…” in any Office application or by clicking on the link below:
The link is the standard feature request one. Total failure to understand what is going on here. Idiots.
-
Then double-click on the resulting file to open in Excel for Mac to get the mojibake experience!
Dunno about Excel for Mac, but I seem to remember you have to 'Data Source > Import' CSVs in Windows Excel otherwise it does something weird that's definitely not interpreting CSV (and it had encoding selection there).
-
it had encoding selection there
Tried that. It doesn't work; it merrily thought that the
éin the data wanted to be_after import.
The workaround I've found is to run the entire CSV file through
iconv -t cp1250and pray that none of our students have a name with characters in it that aren't in that set. I think we're lucky this year…
-
Workaround: Open in any text editor that supports Unicode, globally replace
,with tab, and copy-paste the entire thing into Excel.(CSV probably can't already contain embedded tabs or they won't come in correctly.)
-
Or use something like LibreOffice perhaps?
I know, it ain't excel, but it's capable of handling the import and to be honest it's replaced Office on my personal machine...
If you really like pain, try OpenXML SDK...
Or hope someone else's CSV parsing library has better luck...
To be honest, you could write something that would work by using the OpenXML SDK to work with the XML elements in the xlsx - but there's a bloody good argument that says that's MICROSOFT'S job...
-
Pathetic.
-
Workaround
There's a ton of workarounds (including “simply don't use Excel”, which is probably my #1 right now) but this isn't something that ought to require a workaround. It's not rocket science.
The worst part is the level of fail in the Import… route. At that point, the user is able to specify exactly what is going on and control everything exactly except that if they choose the correct character encoding, Excel screws the pooch and actively puts the wrong info in there. There's no excuse for getting that wrong. Putting an option in a dialog and then not making that option work is incredibly sloppy.
Excel on Windows is different. None of this rant is applicable there. Except who knows what sort of stupidity is lurking…
-
I had the same problem a while ago, and IIRC Mac Excel can successfully import UTF16LE tab-separated values. (At least, I think it was UTF-16LE, might have been the other UTF-16.)
You probably need the right BOM for that to work.
-
Excel for Mac does not currently support UTF-8
So it doesn't support the default system encoding. Nice
on output it generates the file using Mac Latin
when reading it back in, the same file it generated, it really assumes that it's CP1250
Disconsistency.Are you sure you're not using Excel from before 2000 ?
I mean, those open-source incompetent freaks have been supporting UTF-8 in GLIBC since version 2.2, which came out in 2000.And Microsoft is recommending every developers to move their application to Unicode
Don't tell me they are not following their own recommendations. They even provide guidelines to migrate
-
Don't tell me they are not following their own recommendations.
Microsoft: Not following our own recommendations since 1975
-
The bug report you linked specifically notes that converting to UTF-16 LE works (actually it's probably UCS-2-LE, which is what MS implemented everywhere else). Still ridiculous, but you don't need to convert to cp1250 and risk mojibake.
iconv -f utf-8 -t utf-16le studentfile.csvshould work just fine.
-
-
Or use something like LibreOffice perhaps?
I am frequently told not to use LibreOffice because it isn't compatible with MS Office. My usual response is, "Sure, but it's not like MS Office is compatible with MS Office either."
-
For 99% of documents, you won't notice a difference between Office and LibreOffice anyway
-
(including “simply don't use Excel”
I'd suggest using a REAL database, however: http://stackoverflow.com/a/6840439
-
For 99% of documents, you won't notice a difference between Office and LibreOffice anyway
eeeh... it's closer to 70%. there are some pretty substantial differences to how libreoffice handles things like block indentation and certain kinds of colouration such that documents created by the fingerpaint department are highly likely to have rendering differences between M$ office and LibreOffice.
of course anyone that's not in the fingerpaint department will almost certainly be creating documents that are much more basic and will convert more or less flawlessly..... until the finger paint department gets their mitts on them.
-
Isn't the thing we're talking about here Excel, where it's more like 40%? Not that it should matter for csv, of course.
-
I'd suggest using a REAL database
Why are you assuming that it's being used as a database? It's basically just a short report in a format that is both computer- and human-readable. No computation or embedded scripts, just a description of the state of things at a particular moment (extracted from a fairly annoying web service, but that's another story).
If I was to invoke doing it with a database with the particular group of people I'm doing it for, it'd probably have to be with Oracle.
 Or something awful with RDF and a graph database…
Or something awful with RDF and a graph database…
The general point that MS can't into UTF-8 is fair though. The stupid bit is it isn't even complicated to write a correct converter so they can hold things internally in anything they want. I wouldn't criticise them for doing that. But claiming to do it and getting it utterly wrong in a product that's been out and receiving patches for a few years…

-
I am frequently told not to use LibreOffice because it isn't compatible with MS Office.
"Please hold the handrail as your emerge from the timepod. Now, I know some people from before 2007 remember a time when MS Office couldn't open StarOffice documents..."
-
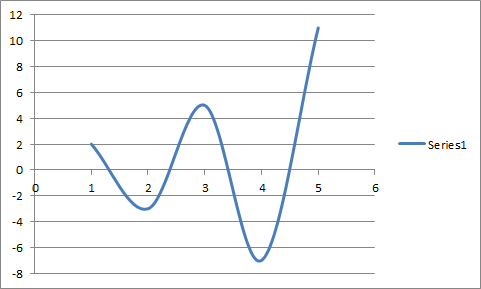
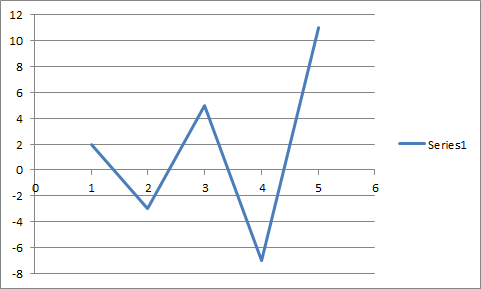
Last time I tried to use OpenOffice/LibreOffice/whateverthefuckit'scalled, in the very first Excel workbook I tried to open with it, all of the non-smoothed lines on my scatter graphs had been replaced with smoothed lines.
I uninstalled it and haven't looked back.
-
Last time I tried to use OpenOffice/LibreOffice/whateverthefuckit'scalled, in the very first Excel workbook I tried to open with it, all of the non-smoothed lines on my scatter graphs had been replaced with smoothed lines.
Oi! This isn't the FWP thread…
-
Wait. Isn't anti-aliasing the lines better? Why the hell would you want the jaggy version?
-
It has nothing to do with anti-aliasing.
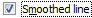 =>
=> 
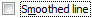 =>
=> 
-
Oh. Yeah that is actually changing the data, and deserving of your WRATH!
-
Oh, I don't think of that as being smoothed. It's more a line-segments vs spline thing to me. And getting that wrong is weird. Like someone read the spec and decided to randomly invert a boolean for chuckles.
-
Oh, I don't think of that as being smoothed. It's more a line-segments vs spline thing to me.
Yes, but it's what Excel calls it. I wouldn't expect the average Excel user to know what "splines" are, anyway.
getting that wrong is weird. Like someone read the spec and decided to randomly invert a boolean for chuckles
I didn't try importing one that was supposed to be smoothed, so the impression I got was that it just ignored the setting and its default was smoothed.
-
I'm of the tendency that calls a
spadespline a spline.
-
Ima steal that image...
-
Yes, but it's what Excel calls it. I wouldn't expect the average Excel user to know what "splines" are, anyway.
Hey, I played SimCity!
-
But were they reticulated?
-
...in the very first Excel workbook I tried...
Well, there's your problem right there. You should never have used Excel to create a graph for something important enough that the distinction between smoothed and not was critical.
-
Of course they should be in ASCII, ASCII has control codes to designate end of field, end of record and end of file.
Oh, you meant the content? Fück yóù wîth ã spīky pūrplė dįldø.
-
Workaround
My usual workaround is to open the CSV in LibreOffice and then "Save As" xlsx so that Excel will behave. Though these days I don't usually bother with Excel anyway.
-
Of course they should be in ASCII, ASCII has control codes to designate end of field, end of record and end of file.
That nobody uses. Which is a real shame. Too often people don't quote their CSV data and someone adds a comma to a field.
-
Too often people don't quote their CSV data and someone adds a comma to a field.
Tab-separated value (TSV) files are a thing. They mostly work fine. Provided you're not trying to do the import that I was doing that lead to the start of this thread…
-
That nobody uses. Which is a real shame. Too often people don't quote their CSV data and someone adds a comma to a field.
Or a quote. Or both. My favorite was the name field that contained something like:
Bush,George W "GW"Guess how that parsed when it was in a string of other fields:
20,199994145,Bush,George W "GW",788 East Barge St,Alamoma,VI,10241,4074074071Talk about breakage...
-
What's really sad is that there is an RFC that makes it really easy to do CSV right. Of course its just a RFC (and I'm pretty sure 95% of 'enterprise' developers have never even heard the term).
-
Then double-click on the resulting file to open in Excel for Mac to get the mojibake experience!
Right now, out there on Monster or CareerBuilder, there is some HR 'expert' writing an ad asking for "10+ years of Mojibake experience", I'll bet.
-
run the entire CSV file through iconv -t cp1250 and pray
I have iconv -t cp1250'ed your CSV file, pray I do not iconv any further.
Yes, but it's what Excel calls it. I wouldn't expect the average Excel user to know what "splines" are, anyway.
According to the Jargon File, at Xerox PARC circa 1975-1980, 'what is a spline?' was the canonical example of the question you should have asked but were too embarassed to admit you didn't know the answer to.Apparently, Microsoft never asked it.
As for using an actual database instead, that would go against the grain for people who think Excel is a database. And a recipe manager, a graphics program, an accounting system, hell, pretty much anything except a spreadsheet (which, back in the days when they were written with chalk on blackboards, were a way to project the results of changes in things like prices, quantities of reagents, and things like that - you used them to keep track of multiple variables, then to make the projection you changed one variable and then recalculated all the other ones which depended on it). Dan Bricklin had no idea what he was setting in motion when he ported Visicalc to the Apple ][, and we live with the results of it to this day.
Worse, computerizing spreadsheets was one of the last significant advances that the software world really made. That was back in 1977. The only important one since then was the Lempel-Ziv series of compression algorithms, which came a whole six months later. Everything since then has just been a lot of rehashing, re-imagining, reinventing, and renaming the same old bullshit that we knew before most of the current generation of developers were born. Oh, things have been refined pretty well, yes, at least some things have been anyway, but nothing really new has come out in decades.
-
Tab-separated value (TSV) files are a thing. They mostly work fine.
My biggest problem with CSV is that it's more of a loosely defined collection of patterns than a single file format. It's non-standard enough that some people mean "character separated values" when they say CSV and others mean "comma separated values". TSV is a subset of CSV in the first definition and is a completely different format in the second. All variants have the issue of using a separator that could potentially be embedded in the data and all need the character encoding and file conventions (quotes or not, header row, etc...) to be communicated by some other mechanism.
XML may be much derided, but this is exactly the scenario it was designed for. At least it is specified well enough that you are guaranteed to get out whatever data you put in it.
-
According to the Jargon File, at Xerox PARC circa 1975-1980, 'what is a spline?' was the canonical example of the question you should have asked but were too embarrassed to admit you didn't know the answer to.
What are the 5
 if none of them were to fix that...
if none of them were to fix that...Excel is a database. And a recipe manager, a graphics program, an accounting system, hell, pretty much anything except a spreadsheet
Hey! Never underestimate people's ability to use something for many different purposes, including its intended one.
Dan Bricklin had no idea what he was setting in motion when he ported Visicalc to the Apple ][
I actually find that a little hard to believe, because computer geniuses tend to think outside the box and figure out novel ways to use the tools in their toolbox. Surely you'd expect that if you build a new tool, once it has a few million users they'll come up with a few million uses that even you would never have anticipated.
Worse, computerizing spreadsheets was one of the last significant advances that the software world really made. That was back in 1977.
Not a big fan of the Ribbon, the Cloud, Aero, or Metro, I take it.
Really, though, Google has done a significant amount of innovating. Their Maps and Gmail web-based clients were downright revolutionary when they first appeared, and immediately became de facto standards which competitor's products have only hoped, and even still have mostly failed, to meet. The old services, like MapQuest and Hotmail, with their slow, clunky interfaces, were blown right out of the water and it became Google's pond to play in.
I would also consider social networking to be innovative software... it's connected people together on a global scale to a point that no prior technology even remotely approached. Oh, sure, you could transfer text and send files to someone if you were both on the same bulletin board or in the same chat room, or if you knew their online handle in one of the instant messaging clients, but nothing like this - virtually every person has the ability to be instantly connected to hundreds or thousands of other people.
-
I would also consider social networking to be innovative software
That's not innovative, it was inevitable. Social networking took off this century because of the ubiquitousness of always-on networking, not because that's when someone thought of it.
-
Ehhhh. Okay, I'm willing to concede that the social networking boom was mostly innovation in hardware and infrastructure that had to improve to the point where social networking could gain critical mass and take off.
-
Not a big fan of the Ribbon, the Cloud, Aero, or Metro, I take it.
All of those fall into the areas of 'refinement'. Yes, they were improvements in how they used the existing ideas, but they were not themselves particularly innovative.
As for Google... well, maybe MapReduce counts. I'll give you that one.
-
Their Maps and Gmail web-based clients were downright revolutionary when they first appeared
So was their web search. It actually found what you wanted and put it as the first or second link returned (usually)! Before that, you either had AltaVista (which didn't meaningfully sort results) or you had Yahoo! (which only worked if what you were looking for was something a person at the company had thought of looking for). Both sucked.
There were a few key algorithms that sat behind the service, but the core of it which relies on both bibliometric analysis and mapreduce hasn't changed hugely.
-
XML may be much derided, but this is exactly the scenario it was designed for. At least it is specified well enough that you are guaranteed to get out whatever data you put in it.
Except for when you think you're getting xml but you really get something better described as...
a loosely defined collection of patterns than a single file format.
-
you won't notice a difference between Office and LibreOffice anyway
Yes, you will. LibreOffice didn't grow a ribbon.
Why are you assuming that it's being used as a database?
You didn't click the link, did you? Because the link just says:
Q: How to write UTF-8 characters using bulk insert in SQL Server?
A: You can't. … The database does not support UTF-8.
XML may be much derided, but this is exactly the scenario it was designed for.
XML? It isn't even a format.
And do you know about any simple xml-based format for tabular data? Because I don't (neither OpenDocument nor OOXML qualify as simple).
-
And do you know about any simple xml-based format for tabular data? Because I don't (neither OpenDocument nor OOXML qualify as simple).
You can put anything in XML. You're asking if I know an XML schema for tabular data, but that's a totally different issue. There's nothing wrong with this:
<data> <row col1="val1" col2="val2"> <row col1="other val1" col2="other val2"> </data>At least there are well-define rules about what to do with carriage returns, embedded quotes, and characters in the data that are not natively representable in the character set of the file.
-
You can put anything in XML.
That's the problem. If you can put anything there, how do I know what you did put there?
You're asking if I know an XML schema for tabular data, but that's a totally different issue.
That's not a different issue. That is precisely this issue.
There's nothing wrong with this…
Yes, there is. As far as I can tell, it is not a standard. So how do I know that you encoded each row as
data/rowand in that you encoded columns as@col1and@col2. You might have encoded the columns with elements, you might have called themvalue-1andvalue-2, you might have useentryorentityor …. But all that information is needed to read the file.At least there are well-define rules about what to do with carriage returns
Actually no, there ain't. You might be expected to strip leading and trailing whitespace or you might not and you don't know without the schema.
embedded quotes
Yes, that is an advantage. A bit small for such a complicated and verbose format.
and characters in the data that are not natively representable in the character set of the file.
Not really. XML is expected to always be Unicode, which would eliminate the character set issue, except many (and Microsoft in particular) don't respect that.
And entities must be defined in the schema, which would have to exist in the first place.
-
That's the problem. If you can put anything there, how do I know what you did put there?
This discussion is about CSV. Are you suggesting that any of the perceived deficiencies you pointed out aren't things that CSV also doesn't handle?
XML works just fine without schemas, just like CSVs are perfectly acceptable even though they have no capability to restrict or define the structure of data contained within them.
Not really. XML is expected to always be Unicode
... you have no idea what you are talking about. What do you think the encoding attribute of the XML declaration is for?And entities must be defined in the schema, which would have to exist in the first place.
Nope. I've used XML hundreds of times in my professional life and schemas were only involved in a small percentage of the those cases.

