TFS Upgrade!
-
When I took over my team, action item #1 was:
"Migrate from VS2008 to VS2010. Upgrade everything to .net 4.5.x"
Action item #2 was
"Upgrade to VS2013."Action item #3 was "Downgrade to VS2012 because VS2013 can't connect to our galactically ancient TFS server"
We are a Fortune 500 megacorporation and our TFS server is centrally provisioned and managed by Corporate IT. It is shared by every .net team in the entire company (there seem to be about ten of them - changeset numbers are up around 100k)
I duly complained and was told there are no plans to upgrade from TFS2008 to anything modern.
And then about two months ago I heard through the grapevine that a new TFS2013 system was going to be provisioned, but there wasn't going to be a migration - just a new database and teams would be added on a per-request basis.
And then LAST WEEK I was added to the email thread discussing the IMMINENT TFS2008->TFS2013 migration schedule with the words "By the way, I added Weng to this thread because I think his team uses this system too."
The migration plan is as follows:
- Tomorrow. Everybody make sure you check in or shelve EVERYTHING you want to migrate! Shutdown TFS2008 at noon.
- Friday/Sat/Sun. TFS2013 installed to completely new server, database is migrated (I assume this is because the underlying OS on the 2008 server is Win2k3 and they're bringing it up to a modern OS as well)
- Mon. TFS2013 goes live at noon. You can now use the new server by creating a new workspace and pulling down a fresh copy.
- Tues. Go forward/rollback determination.
So: 4 days without source control. Shared network drives have been suggested as an interim setup. Fortunately I don't think anyone is dumb enough to try it for their team.
However, everyone else seems to be planning on doing some idiotic variation of "Okay, everybody get latest on the whole repository and keep working! When the new server comes up, get latest on that and manually move your changes over!"My team's plan: Have some meetings to plan future changes, update our toolchain, install VS2013, go through the stack of potential candidates for our opening, and if all else fails I have an emergency copy of Settlers of Catan in my trunk.
If we have to do breakfix, sure, we'll fix it from our local copies and resync it manually on Monday, but if it can be deferred in any way we'll defer it. Because we aren't fucking stupid enough to try to work without source control.
Frankly, I'd have preferred they just create a new DB on 2013 - it would give us an opportunity to organize our repository sanely because whoever set it up originally was an imbecile who had no idea how software engineering worked.
-
Eh, nobody does work on Friday anyway. If you're not a WTF-y company, do a team movie trip or something.
-
Huh?
Can't you work on bigger projects / changes for 4 days without checking in anything?
I don't buy it.
-
Eh, nobody does work on Friday anyway. If you're not a WTF-y company, do a team movie trip or something.
The day Batman Begins came out, several people and I did just that. Our excuse was that something was going on that meant nobody was going to get work done. Might've been an integration day or something. ("Yes, we have 4 customers and each of them is on a different version of the product.")
-
We're WTF-y. My larger parent team was just instructed by the fucking CIO to go hire 10 more bodies. RIGHT NOW. And train them IMMEDIATELY for our peak season.
Which is already half over. It was too god damned late to properly train the ones that started in July - we have a twelve week spinup cycle.
Any hint of 'this sub-team is not doing anything for a few days' that reaches management (and believe me, it would) would result in my having to explain to the CIO that my team has a completely fucking different skillset from the one that's actually in demand during peak season (my team builds tooling for that team, so our peak has come and gone).
-
@created_just_to_disl said:
Huh?Can't you work on bigger projects / changes for 4 days without checking in anything?I don't buy it.
You could, but the workspace in which you make changes is going to be connected to the old TFS2008 server. So you can fuck around trying to rebind it to the TFS2013 server (which MS has actually told us not to bother trying because the chances of every developer in the company successfully not fucking it up is basically zero) or manually copypasta your changes from the TFS2008 workspace to a new TFS2013 workspace. Or dick around with uncontrolled source.In other words, the server that goes down on Thursday will not be the same one that comes up on Monday. You will never be able to check in work you do on Friday because that server will never come back up.
-
So...another argument for DVCS.
-
So...another argument for DVCS.
I'd say it's more an argument for updating your tools more than once a decade.
The path from version to version +1 is perfectly tested and compatible. The problem here is going from version to version +4 at one time.
The crappy company I just left did their 2010 -> 2013 upgrade last week, and it was flawless.
-
I'd say it's more an argument for updating your tools more than once a decade.
They'd still have the down time. Which was more an issue of moving to completely new servers than upgrading the TFS version.
-
I'd say it's more an argument for updating your tools more than once a decade.
Yeah. The problem is that they literally waited until compatability forced the issue. The entire time, we've all been MSDN licensed for the latest and greatest.The path from version to version +1 is perfectly tested and compatible. The problem here is going from version to version +4 at one time.
The real issue is that we use a single server for multiple teams. Some teams "needed" to remain behind on the old version (because they have heretofore steadfastly refuse to upgrade their fucking projects to modern versions of Visual Studio), so we all got held back because god forbid we run more than one server!
Of course, once the corporate overlords came forward and said "YOU ARE UPGRADING." they have now complied without incident. Fucking luddites.
If we'd been doing incremental upgrades, the whole thing would be a weekend upgrade at the worst, if not an overnighter, and then the OS upgrade could be managed separately by actually having gone through a version of TFS that would install on both versions of the OS and been able to upgrade the OS one farm node at a time. Instead we're in this fucked up spot where we have to do the whole farm all at once, TFS, SQL and OS.
-
Investors call this sort of thing "political risk."
-
DVCS implies disconnected operation. So when you make changes while the server is down those changes can be committed, merged, edited, whatever. When new server comes up, even if you need a new clone/copy/checkout, your changes can easily be used to generate patches or whatever to import to the new server. No downtime, no manual copying of changes file-by-file, no missing changes, no accidentally merged changes.
This would be easy with git.
-
DVCS implies disconnected operation.
Yeah but why?
I've had this debate with so many Git fans, when I say Git would be a lot better for corporate use if it had a "always online" mode, and they're always like, "well it can't have an always online mode because it's distributed source control" and I'm sitting here going, "what the holy fuck is the relationship between those two things!?" because goddamned that makes no sense.
This would be easy with git.
It's also easy with TFS, if your company isn't run by fuckwits.
-
DVCS would fix this particular issue, at the cost of introducing other challenges.
For instance, needing external packages for all the bonus stuff built into TFS - build server, work tracking, etc. and only being able to tie those to the central, canonical repository.
Of course, our TFS has heretofore been so fucking old that we have an external build server and work tracking software anyway, but I look forward to not needing to pay support fees and dick around with that shit anymore.
Since we seem to be upgrading TFS every 5 years or so, we lose a grand total of less than a day's work per year to source control dickfuckery (less approaching zero if we actually kept shit updated). If it costs me any more than 1 day per year configuring/maintaining/updating/etc. our external build system and work tracker and such (and it does, I think I'm at about 2 man-weeks this year so far) we're making out with TFS over DVCS. And that's before you consider the other 10 teams using the thing and the tooling they'd otherwise have to maintain.
-
I've had this debate with so many Git fans, when I say Git would be a lot better for corporate use if it had a "always online" mode
That would be awesome, because it would give another reason for a commit to fail and for you to be angry at something you don't understand.
It's also easy with TFS, if your company isn't run by fuckwits.
Can you commit stuff when you're not connected to the TFS server? This is an honest question, I've never used it. Whether the reason is because the server is off or because you're in the middle of nowhere?
-
Can you commit stuff when you're not connected to the TFS server?
You can in 2013. You can also hook Git up to it somehow, but I've never looked into the server side of that. (The client side is what makes Visual Studio the best Git client currently on Windows.)
-
You can in 2013
See, I didn't even know that. Because you can't connect TFS2008 to VS2013, so I never got to really look at the VS2013 featureset. See? ADVANTAGES to upgrading things more frequently than 'when forced'.
-
You can in 2013.
Some googling and I find that this is using a local environment vs a server environment. Have you used this feature? Did you find it more confusing / annoying than having to push changes in, e.g., git?
-
Nope, never used it. Was in an always-online office.
Did you find it more confusing / annoying than having to push changes in, e.g., git?
I imagine it's just as confusing as doing the same thing in Visual Studio's Git client: way more than it should be, but way less than trying to use the open source shit to do the same.
-
I imagine it's just as confusing as doing the same thing in Visual Studio's Git client: way more than it should be, but way less than trying to use the open source shit to do the same.
Fair enough. Again, I haven't really used git, but my early impressions are that it makes things more difficult than it needs to.
-
Yeah but why?
The "D" in "DVCS" stands for "Distributed". That means no central server and implies no server is necessary at all. I haven't used all DVCSs so there may be some oddballs that need a server but I am not aware of them.
Git would be a lot better for corporate use if it had a "always online" mode
What does "always online" mean to you in the context of a DVCS such as git?
-
The easiest implementation would be something like, when the user creates a commit, the Git client queries to see if the server is online/accessible, if so it just does a "sync" operation right away.
As-is, people working for a corporation could potentially do weeks of work without syncing, and then they're hit by a bus and that work goes bubye. That sucks.
-
I haven't really used git, but my early impressions are that it makes things more difficult than it needs to.
For beginners that don't know what they're doing, it can seem easy to get into difficult situations. I'm the go-to guy in my team for git. I'm no git master but I can usually fix the "broken" repositories here, and they're usually caused by users not wanting to learn. Usually it's a merge that fails with conflicts, they pretend there weren't any and steam on ahead, then wonder where everything went wrong. It was much much worse when we were using SVN which does merge-then-commit and ad-hoc merges. At least with git your committed changes are still there, untouched.
But I think git is complex because the problem it's trying to solve is complex and it doesn't try to hide that. Branching and merging is very complex and DVCS is all about branching and merging.
-
...and they're usually caused by users not wanting to learn.
I tend to agree with that. I have a lot of experience with svn and hg, but git feels different. Though when I researched the problems I was having, they made sense and I could avoid them (again, this was some fairly superficial testing).
But I think git is complex because the problem it's trying to solve is complex and it doesn't try to hide that.
I don't disagree with this, but git's bigger problem to me is that some of the implementation details cause situations that aren't intuitive until you know what they are. I think a lot of those details make sense for the use case that git was designed for, but it isn't really my use case.
-
The easiest implementation would be something like, when the user creates a commit, the Git client queries to see if the server is online/accessible, if so it just does a "sync" operation right away.
You want the "pull; push" part of "commit; pull; push" to be automatic when the "commit" part is executed. That's totally reasonable. What's not reasonable is how to implement that. It's something like this:
git config --global alias.whateveryouwantthecommandtobe '!git commit && git pull && git push'
That's terrible UX. It's horrible to set up. It's inflexible. It doesn't handle errors at all.
I don't know how well that works on Windows, or how a GUI client might implement it. I haven't found a GUI client I like for anything other than viewing the log of commits and branches.
Also, now you're really doing three things instead of one. What to do when one fails? The pull might fail because of conflicts, and the push might fail because the server doesn't like your commit message or maybe you have static code analysis running or whatever. And you will probably want to add "-a" to commit so you don't need to stage changes first, and maybe you want "--rebase" on pull to keep your history linear and I'm assuming matching branch names and so on. None of that matters to you because I haven't gotten over the first barrier which is a useful GUI client.
As-is, people working for a corporation could potentially do weeks of work without syncing, and then they're hit by a bus and that work goes bubye. That sucks.
People problem. I know, it's easy to blame the users, but this time it genuinely is a problem with that staff member being irresponsible. Why are they not syncing? How does anybody else know how or what they're doing? Why is there no peer review or continuous integration going on? Early testing? What if their network happens to be down every time they commit, so the push never happens? It's no different to them working away alone in their basement and then their house burns down destroying everything.
-
What to do when one fails?
A: blakeyrant at how good software isn't easy, but dammit someone should figure out how to defy logic.
-
git config --global alias.whateveryouwantthecommandtobe '!git commit && git pull && git push'
Right and obviously that's because my idea is bad and not because Git's interface is boiled shit on toast.
People problem.
Yet somehow magically this "people problem" doesn't exist for the vast majority of source control products. Hm! I guess if you start using Git, you become a different person, that is the only explanation.
-
Right and obviously that's because my idea is bad and not because Git's interface is boiled shit on toast.
Your idea isn't bad. I already said it's reasonable. Why doesn't anybody ever read what I type? Read the post you're replying to, arsehole!
Yet somehow magically this "people problem" doesn't exist for the vast majority of source control products.
Yes. It's totally impossible to work for weeks at a time without committing or syncing in other products.
-
Right and obviously that's because my idea is bad and not because Git's interface is boiled shit on toast.
You're getting bogged down in gittisms and ignoring the conceptual problem. What do you do if you can't talk to the server when you want to commit? In a centralized system, we know that the commit doesn't happen. Do you go ahead and commit and just sync up later? How do you warn your idiot users about this and prevent the situation you're trying to prevent?
-
As-is, people working for a corporation could potentially do weeks of work without syncing, and then they're hit by a bus and that work goes bubye. That sucks.
You can do weeks' worth of work without committing to a centralized system too, so I don't really see your point.Or really hopefully you couldn't, because someone would notice that you said "bug 32576 is fixed" and they're still seeing 32576. Same as if you don't push with git.
-
The "D" in "DVCS" stands for "Distributed".
Then use Team Foundation Online where the server is azured away for you.
-
Another flamewar from uninformed developers who can't be bothered to learn something new.
Commits to a central server are one of the most stupid ideas in software development. And it's not the most stupid idea, because central/remote branches are the stupidest idea.
Why is GitHub such a hit? Because it uses git. Yes, git can be a fucking PITA if you don't wrap your head around it, but it's the same with every fucking tool you use. It doesn't adapt to you, you have to adapt to it.
The main problem people have with DVCS is that with CVCS (CVS, TFS, SVN) there's a person responsible for the repository that makes all the decisions and are able to fix the sort of fuckups that morons make. With DVCS, fuckups are yours and you have to fix them by yourself or you won't be allowed to push your crap so others can consume it.
-
Git
I recommend sourcetree. It has a nice GUI which tells me stuff about my git repos without my having to type things to the interwebs 'n' such. So far it hasn't destroyed any of the 3 computers I've used it on or gotten me lost in the Pacific Ocean, so it gets my thumbs up.
-
Commits to a central server are one of the most stupid ideas in software development. And it's not the most stupid idea, because central/remote branches are the stupidest idea.
The problem with git was never the basic model of commits that can be shared and uniquely addressed by content hash. That model is great (unless you're really wedded to having a small sequential decimal number to represent a particular commit). The problem is with all the stuff on top of it. Git tries really hard to make the underlying model do something other than what it naturally does, and that's where most of the trouble starts.It also has problems with naming of things (i.e., the labelling you add to commits and branches to make them easier to find) in a shared context, but that might be related to “tries really hard to make the underlying model do something other than what it naturally does”.
Why is GitHub such a hit? Because it uses git.
It also hides virtually all the git craziness.
-
That model is great (unless you're really wedded to having a small sequential decimal number to represent a particular commit).
That's another reason I like hg. It uses the hash, but each repo locally has the sequential number. Obviously, it's useless communicating with other people, but damn useful for doing stuff with your repo.
-
Yet somehow magically this "people problem" doesn't exist for the vast majority of source control products
My company has been burned by people working in their centrally-hosted developer instance VMs and not committing because they've had a VM server die and take weeks of work with it once. Those people who prefer to finish a feature before committing get scolded.
-
It also hides virtually all the git craziness.
Amen to that. You're totally right on this.
-
My company has been burned by people working in their centrally-hosted developer instance VMs and not committing because they've had a VM server die and take weeks of work with it once. Those people who prefer to finish a feature before committing get scolded.
Is this with TFS? One of the great annoyances with TFS IMHO is that it almost encourages you to finish your feature before committing, because making a branch to hold your intermediate, buggy work is so heavyweight - you have to create a new on-disk copy of the entire repo that you're working in. And anybody else who wants to work on it or test it has to download that entire new copy from the server.
-
-
The best thing about SVN is
svn-git.
-
Is this with TFS? One of the great annoyances with TFS IMHO is that it almost encourages you to finish your feature before committing, because making a branch to hold your intermediate, buggy work is so heavyweight - you have to create a new on-disk copy of the entire repo that you're working in. And anybody else who wants to work on it or test it has to download that entire new copy from the server.
TFS (even the old versions) has online shelvesets, that's what you're supposed to be using. Just keep shelving your work until you're finished, and since they're online, anybody else with permissions can check out your shelvesets after you get creamed by the bus.
You can branch, but like you said that's a pain.
-
TFS (even the old versions) has online shelvesets, that's what you're supposed to be using.
I remember shelves being one of the "don't use, ever" things, but don't remember why. Something to do with merging the changes back, I guess (can you shelve stuff that doesn't quite work, start on a different feature, then merge the shelf back in after you're done? I think that was it).
-
I guess (can you shelve stuff that doesn't quite work, start on a different feature, then merge the shelf back in after you're done? I think that was it).
No harder than in, say, Subversion. Which means it's not 100% foolproof, but it'll work the vast majority of the time.
It certainly doesn't work any worse than branches, so I don't know why you'd prefer branches to shelving, when branches in TFS are a huge PITA.
-
With Visual Studio Premium/Ultimate, there's a little area in the corner called "My Work". You can drag work items there and have it automatically track time spent and link changesets, shelvesets, and test results to that work item. When you have to context switch, dragging a work item back out automatically shelves your work -- tied to that work item -- and takes you back to the last changeset. When you're done there, dragging the work item back in unshelves and merges for you.
The biggest problem I have with shelvesets is that, by default, they go away as soon as you use them, and they don't retain history. The second-biggest problem I have with shelvesets is that most people don't know they exist, and those that do know they're stored server-side and available to any other developer to fuck with.
-
Except shelfsets are almost as bad in their own way. They aren't ridiculously heavyweight like branches, but they have no sequence or history, just arbitrary names. You could create a series of shelfsets which each all have all of your changes up to that point, with name suffixes or something to identify them. But then half the point of version control is to have granular and ordered changes that can be described and rolled back individually. You could try and create more incremental shelfsets with a small part of the changes each, but TFS makes this difficult, and there's still no ordering to them. Either way, if you want to break it into multiple changesets, you'll have to do most of the work manually at check-in time.
Then there's the way that somebody decided that it would be a good idea to only allow you to find shelfsets by full user name, which must be typed in exactly the way that your name is entered in TFS. There's nothing that would actually make sense, like a list of all of the registered TFS users or the users you've recently searched for, and any typos in the name means your search returns nothing except a statement that the name you entered is not a valid identity. Hope you don't have anybody on your team with a long or hard to spell name.
-
I have the same issue @Yamikuronue has in SVN... I get scolded if I break the build (the build server does this automagically). Doesn't help that branches are heavyweight in SVN (you literally create them with
svn copy).In Git (and Mercurial I think), branches are lightweight and extremely easy to use. Not surprisingly, when working in these, I work on new stuff in a branch. To prevent complications later on, I periodically merge master into my branch.
Every time I make a commit in Git using TortoiseGit, the dialog saying the commit was successful has a really large "Push" button to remind me to push it to central::
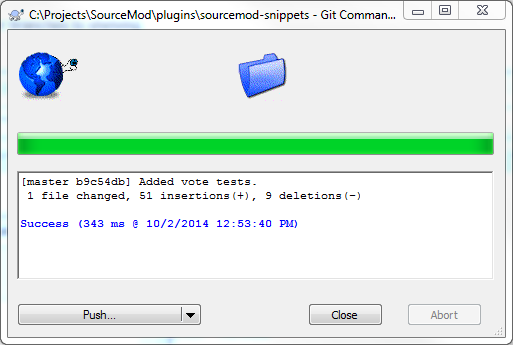
Now, this particular arrangement is one that TortoiseHg (for Mercurial) does better, as it has functionality that you can use to see what commits haven't been pushed back to the upstream (or central) repository and see if there are any that the local repository doesn't have.
-
Doesn't help that branches are heavyweight in SVN (you literally create them with svn copy).
I never really got the "svn copymeans branches are bad" argument. The server isn't copying the data; it stores just a marker. It's not going to create repository size. In SVN 1.4 and before, the syntax for creating a branch was obnoxious, but that's largely cleared up since the introduction of the ^ shortcut.My personal opinion is that the reason svn branches are more obnoxious to use is (1) merging (which has nothing to do with
svn cp), which has also been at least somewhat alleviated (I don't know how much) by the merginfo tracking, and (2) they go into a global namespace, so if you want to create a branch for something you're working on you have to worry about name conflicts with others or policies about what branches you can have or just general pollution of having to look through potentially a lot more stuff to find what you're looking for.Now, this particular arrangement is one that TortoiseHg (for Mercurial) does better, as it has functionality that you can use to see what commits haven't been pushed back to the upstream (or central) repository and see if there are any that the local repository doesn't have.
TortoiseGit does too... I'm not exactly sure where all it will tell you this, but at least from the log viewer.
-
So...another argument for DVCS.
Or at least for "intelligent" enough centralized VCS clients. For example, in Subversion, when you have stuff to commit and your server is gone for some reason, and some other SVN server at a different URL contains a different repository with different history (because of somebody running some dump filters on it), but there is still a place in the repo that looks similar enough for your changes to apply, TortoiseSVN will detect this situation (repository UUID mismatch) when you try to "relocate" to the new server and guide you to create a patch out of your uncommitted stuff (which is by design possible while offline because the local .svn folder contains pristine versions of all retrieved files), perform a fresh checkout, and apply that patch.
Used (had to) it once (also because of some communication problems), and it worked a lot better than I had expected. I had already made a patch before trying because I did not trust it, but all my uncommitted changes were still there, ready to commit

But probably the new TFS client would also be able to handle that (never used TFS myself, only heard people cursing about it). But we are quite happy with SVN now - and its possibility to set up read-only slave servers in different offices (connected by a relatively slow VPN only) so that checkout, update and blame operations are blazingly fast and only commits (or the occasional lock/unlock) will have to write-through to the master which will then in turn inform all the slaves of the change. How well is a scenario like this supported in a TFS environment?
-
Or at least for "intelligent" enough centralized VCS clients.
Managing patch files for a single commit you want to do isn't too bad... but once you have two changes you want to make (where both have a file in common) while you don't have repo access, it suddenly becomes a PITA. Or if you have copies/renames. The CLI Subversion client provides zero tools for helping in this situation, and while I don't know for sure I doubt Tortoise helps either.
Your repo migration example is easy to handle in contrast.
-
Only in TheDailyWTF you would found someone defending TFS.