What HTTP status pages do you create?
-
I was thinking about this since it's a project I want to take on at work. We have zero pages for any HTTP status other than 200, so I wanted to change that.
On my personal site, I have these:
- 401 - Unauthorized
- 403 - Forbidden
- 404 - Not Found
- 406 - Not Acceptable
- 500 - Internal Server Error
I don't think that 406 is ever hit, but it's there, so I don't really feel like taking it down.
Are there others that should be handled? Does it depend on what the site uses?
I tried researching what's best practice, but if there are any sites out there that give a decent explanation of what you should handle, they're buried in the eleventy billion pages explaining what HTTP status codes are.
-
we have
HTTP 200
HTTP 202
HTTP 204
HTTP 300
HTTP 301
HTTP 302
HTTP 303
HTTP 304
HTTP 400
HTTP 401
HTTP 403
HTTP 414 (which gets triggered far too often)
HTTP 418 (i'm 99.9% positive it's impossible to actually get, and 100% positive it's a joke)
HTTP 500
HTTP 505 (only if the HTTP version is specified as 0.5, so not likely to happen at all and i think it's funny enough to keep around (the file it's in is only included on the admin side anyway)there might me more, but that's what GREP turned up readily
-
Honestly, you can combine 401 and 403 into a single page, you need a 404, then you need a 500.
There's really only those three status pages worth developing. Make your 500 generic enough that you can redirect everything else to it.
-
401 means that you are not authenticated for an authentication restricted request (almost always HTTPBasic authentication) and that you should authenticate to proceed.
403 means that you are denied access and that authenticating (if you are not) will not grant you access.
if authenticating would grant you access you should probably be issuing a 302 with the appropriate return information (so the user returns to where they requested on authentication) in the case of a web app, or just 403 (or 401 as appropriate) in the case of an API
-
Off the top of my head, 503 (httpd is alive, but webapp isn't) and 504 (webapp is maybe alive, but is taking too long to respond) seem reasonable to handle.
HTTP 300
HTTP 301
HTTP 302
HTTP 303
HTTP 304
If I understand these correctly, you shouldn't need pages for these. The end user should never see 30x responses; the browser should simply redirect to the URL supplied.
-
yeah, technically theose aren't status pages, nor are the 2xx pages (although you could argue that the empty string for http204 is a status page...)
those would be the status codes our sites use, not static status pages. the only ones that are static are the two joke ones (418 and 505) and 500.
interestingly enough none of our websites will return a 404 status even though they have a 404 page. they are all 302 redirects to a 200 status 404 content page.
and i cannot convince design to change that!
-
401 means that you are not authenticated for an authentication restricted request (almost always HTTPBasic authentication) and that you should authenticate to proceed.
403 means that you are denied access and that authenticating (if you are not) will not grant you access.
if authenticating would grant you access you should probably be issuing a 302 with the appropriate return information (so the user returns to where they requested on authentication) in the case of a web app, or just 403 (or 401 as appropriate) in the case of an API
Yeah, on the personal site, we do have a restricted section, but anyone with a proper account can get there, so you get the 401.
-
401 pages aren't displayed by the browser unless the user cancels the login dialog or whose credentials fail too many times. Which is why I assume @blakeyrat said to combine them.
-
not everyone using what you code will be a browser.
the two status codes are distinct and should not be conflated because to computers the situations and responses to be taken to the error are different.
-
The page doesn't control what HTTP code it is, the header does.
-
i have met far too many web designers that do not know their ass from their elbows and wouldn't get that distinction.
yes the header is separate from the page, but i'm not trusting design to understand that.
thus i will always spec for both the 401 page design and the 403 page design.
-
401 means that you are not authenticated for an authentication restricted request (almost always HTTPBasic authentication) and that you should authenticate to proceed.
Right but practically-speaking, this never comes up because when a user performs an action that requires auth, you would redirect them to the auth page instead of serving up an error page.
That said, you might still need that error page for stuff like, say, REST API requests that aren't authed, since you don't really have an option of redirecting for those. At the same time, REST doesn't give a crap about custom page responses and only looks at the status code, so you still don't (for any practical purpose) need a 401.
So you write one page that covers the 403 case, and is worded in such a way that it also covers the 401 case just in case that ever comes up, which it won't, and you're gravy. Save yourself work.
-
What are the use cases for 202, 204, and 300? I'm trying to picture them, but can't come up with anything that I do in either environment.
Is the only difference between 301 and 303 that the target resource is the same, just in a different location for 301, and it's a different resource for 303?
414 gets triggered for me, most likely.......I should add that one, although the two GET forms that I have will be converted to POST soon. Anything else is merely malformed.
505, yeah, don't think that I'd add that.
-
So you write one page that covers the 403 case, and is worded in such a way that it also covers the 401 case just in case that ever comes up, which it won't, and you're gravy. Save yourself work.
Depends on the envrionment. The personal site uses htaccess for authentication, so 401 is very common.
-
not everyone using what you code will be a browser.
the two status codes are distinct and should not be conflated because to computers the situations and responses to be taken to the error are different.
this is what i get for trying to be clear?
not everyone is using a web browser to connect to the site. there are APIs there too
What are the use cases for 202, 204, and 300? I'm trying to picture them, but can't come up with anything that I do in either environment.
Is the only difference between 301 and 303 that the target resource is the same, just in a different location for 301, and it's a different resource for 303?
414 gets triggered for me, most likely.......I should add that one, although the two GET forms that I have will be converted to POST soon. Anything else is merely malformed.
505, yeah, don't think that I'd add that.
202 is just for the API side. if you are not writing a REST API then ignore it
204 is for saying "Yeah the content you wanted? well i found where it lives but there isn't anything stored there" it's again for the REST api, so you can ignore it for a website.
300 is for the REST API again, it's for fuzzy matching on the request and returned when there wasn't a good enough match to determine what object was wanted.
301 vs 303 is for SEO: 301 says "the page has moved over there and won't be back here ever" where 303 says "this page has gone away on vacation but will be back later, in the mean time use that page over there"
-
they are all 302 redirects to a 200 status 404 content page.
Argh! I hate this. Sometimes the URL has some obvious error (e.g., ".hmtl") that I could easily fix, but the URL isn't there any more, because it's now the address of your stupid 404 content page.
-
The personal site uses htaccess for authentication, so 401 is very common.
Are we talking man-on-the-street visitors who need a nice pretty branded error page, or techy-McTechs-a-lot who'd be fine with a page that just reads: "401 - Authorization Required"?
I'm just saying don't do work you don't got to do.
-
Argh! I hate this. Sometimes the URL has some obvious error (e.g., ".hmtl") that I could easily fix, but the URL isn't there any more, because it's now the address of your stupid 404 content page.
i tried to get that fixed. had a shouting match with design over it. in the end their boss had more political power and so they won, even though my boss and boss+1 was pulling for me.
-
202
301
300
204
Why would you write pages for any of those, though? The REST user doesn't give a crap about having a webpage, he'd rather have the status code and maybe a bit of JSON that says, "{"error": "fart too long"} to debug with.
... to remind you of the actual topic, we're talking about creating pages for codes. It's not just, "what's the laundry-list of possible HTTP codes you can return!??!?!?!?"
-
Are we talking man-on-the-street visitors who need a nice pretty branded error page, or techy-McTechs-a-lot who'd be fine with a page that just reads: "401 - Authorization Required"?
I'm just saying don't do work you don't got to do.
Yeah, that 401 page is pretty simplistic:
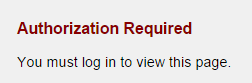
-
And that's 100% perfectly fine, as long as you're not exposing it to every Tom, Dick, and Harry who comes by.
There's no point in creating friendly, branded error pages unless that error page is going to be seen by a lot of the general public.
-
The end user should never see 30x responses; the browser should simply redirect to the URL supplied.
yeah, technically theose aren't status pages, nor are the 2xx pages (although you could argue that the empty string for http204 is a status page...)
do you even read the threads you reply to?
-
Calm down, you guys.
I'm fully ignoring the REST HTTP codes, since they won't be used in either environment.
But thank you for explaining your setup, @accalia.
-
no problem, glad to help.
-
do you even read the threads you reply to?
He's only vaguely aware of what he put in his replies.
-
Argh! I hate this. Sometimes the URL has some obvious error (e.g., ".hmtl") that I could easily fix, but the URL isn't there any more, because it's now the address of your stupid 404 content page.
On the personal site (the one that actually has a 404 page), the URL is preserved. It shows /404.html, which has a link to the site map on it, but doesn't redirect to it, which is pretty nice.
-
do you even read the threads you reply to?
At first I thought you were replying to me, and was about to criticize you for criticizing me for not having read a post that was after mine, but then I noticed you were actually replying to Blakey. Carry on.
And Discurse didn't notify me for that quotation. Discoursistency, yeah!
-
It shows /404.html ..., but doesn't redirect to it
That's called Doing It Right™.
-
@chubertdev said:
It shows /404.html, [snip], but doesn't redirect to it,
That's called Doing It Right™.
QFT
-
-
ITYM "doing it right."
Yeah, my bad. Of course, Doing It Right™ is doing it wrong, and Doing It Wrong™ is doing it right.
-
interestingly enough none of our websites will return a 404 status even though they have a 404 page. they are all 302 redirects to a 200 status 404 content page.
and i cannot convince design to change that!
The main site at my last job was similar, except they had us redirect 404s to the home page. It was interesting when iframes 404'ed.
-
It was interesting when iframes 404'ed.
Bonus points if said iframes were on the main page. I wonder if browsers do detect this kind of redirect loop...
Filed under: too lazy to check
-
wonder if browsers do detect this kind of redirect loop...
IIRC no, but is moot point because they will only allow so many nested levels of iframes (50 i think....)
-
Well, you could add iframe-escape logic to the homepage...
-
I'm currently building stuff that does HTTP 200, 206, 301, 302, 304, 400, 403, 404, 500.
The oddity here of course is 206, but then again I'm throttling large files through fucking PHP like the madman I am.
-
I generally go with 401, 403, 404, 50x as my defaults and add others if I need more granular handling.
-
Guys, try this link:
https://www.google.com/generate_204
That's right, you can't click it.
Try copying and pasting it into your address bar.
Nope, can't do that either.
BECAUSE THERE'S NO CONTENT TO GO TO.
It's not a blank page. It's a page that exists but has no (not even a zero-length) content.
-
-
Does it actually go somewhere for you? It should be producing a 204 response which tells your browser to not switch pages.
-
I middle-click it, I get a blank page in a new tab. So does left-clicking, actually, which may be due to my profile settings.
Open a new tab in Chrome, paste into address bar, hit enter, nothing happens (I still see my frequent tiles).
Try opening a new IE, pasting into address bar, hit enter, I get "navigation to the webpage was canceled."
-
It's a scientific fact that it is impossible to middle or right click on links.
-
That's right, you can't click it
I most certainly can click it. In fact, I clicked it multiple times. Clicking it does nothing useful, but I can click it.
-
I create the one for "500 : Fuck off with prejudice, you cunt" and redirect everything else to that.
<small
Filed under : Including 200
-
That's right, you can't click it.
Ok Ben. I know you're the young one of the group, so I'm going to make this explanation as simple as possible:
Nothing you can do in HTML can prevent me from clicking on a link. Despite your confident assertion, I was indeed able to move my mouse cursor over the blue text and click it with no barriers at all.
Now what you might have meant to say was, "clicking this link opens a blank tab", which appears to be an accurate statement. If you had typed that, I would have slightly more respect for you than I do now.
P.S. I also could paste it into my title bar.
P.P.S. Someone's about to call me a hypocritical pedantic dickweed and say, "well it's obviously what he meant, to which I will reply: 1) it wasn't obvious to me at first, I had to do a double-take, and 2) fuck you.
-
I was briefly confused, as I could do both of the things I was told that I couldn't.
Wasn't sure if it was a bug with Discourse or with @ben_lubar.
-
Someone's about to call me a hypocritical pedantic dickweed and say, "well it's obviously what he meant, to which I will reply: 1) it wasn't obvious to me at first,
Naw, we all understand you are unable to understand that kind of context and implication.
-
I middle clicked like I do with all links on this forum and got a blank tab and went "so?"
It was only after reading a few more posts that I realized I was meant to left-click it. LEft-clicking it does nothing at all.Which is really amazing! Given that This link behaves totally differently-- oh wait, no, it doesn't. I click on it and nothing happens.
I am now totally underwhelmed.
I then make a conscious effort to put aside my experimentation and read the rest of your post again. I am mildly interested in what you're saying, but I was totally put off by the way you explained it.
-
I also remember one time I created an easter egg that returned
HTTP/1.2 666 Evil Insideas the status header.
-
The REST user doesn't give a crap about having a webpage, he'd rather have the status code and maybe a bit of JSON that says, "{"error": "fart too long"} to debug with.
Strictly, that ought to be done by content type negotiation. If the user's client prefers HTML, give 'em the pretty page; that's what they asked for. If they really want XML, angle-bracket them to death. (REST is trickier than it looks, which is why most sites that claim to do it are really just a fucking mess with some godawful JS wrapped around the front end of it.)