Embedded madness
-
Some code I'm refactoring is embedded C and while most of it is OK some is a little...not good (formatting as per the original):
void Convert_Int_Into_Char(unsigned int temporary_int) { unsigned char highbyte,lowbyte = 0; highbyte = 0; lowbyte = 0; Int_Into_Char_Loop: if (temporary_int >= 256) { highbyte ++; temporary_int -= 256; goto Int_Into_Char_Loop; } lowbyte = temporary_int; globalstring[0] = highbyte; globalstring[1] = lowbyte; }
I was going to do some pointer-magic #defines for high/low byte access but I just went with something simple and sane:typedef union { struct { uint8_t HighByte; uint8_t LowByte; }; uint16_t Word; } WORD_t;
Bonus WTF:if (Variable2ShouldBeNegative < 0) { SomeVariable = Variable2; SomeVariable -= Variable2; SomeVariable -= Variable2; }
Filed under: Why is everything a global variable, gah!
-
Why is everything a global variable, gah!
You're doing embedded code. Sorry, no abstract singleton factories for you.
And the slicing union can bite you hard in the general case, though here you can probably assume the endianness, variable widths, etc.
To me, the code doesn't seem so bad - it obviously looks like somebody was thinking in assembly while writing it, but that's the charm.
-
To me, the code doesn't seem so bad - it obviously looks like somebody was thinking in assembly while writing it, but that's the charm.
Not so bad? He's looping to split high and low bytes. That's ghastly. And the negation thingy... Where did that guy learn algebra?
-
Not knowing 'C', is it common to create an unsigned char, and assign it an integer value?
-
Sure, but lots of the functions don't have any local variables they use globals that are used in exactly one place, that function. The compiler still seems to manage to optimise but I think it's sloppy.
Yeah, width and endian-ness are guaranteed for this platform.
Not the biggest WTFs I know, but I've been fighting this hydra for a while and wanted to vent.
-
"Sane" is the wrong word to describe your struct-union mangling. What's wrong with this?
highbyte = temporary_int / 256; lowbyte = temporary_int % 256;Or if you don't trust the compiler's optimiser, what's wrong with this?
highbyte = temporary_int >> 8; lowbyte = temporary_int & 0xFF;
-
And the negation thingy... Where did that guy learn algebra?
I'm willing to give it the benefit of the doubt and say it's some weird optimization. The slicing... hm, that is weird, though.
Sure, but lots of the functions don't have any local variables they use globals that are used in exactly one place, that function.
How's your stack space? It might be an issue.
-
Sure, but lots of the functions don't have <i>any</i> local variables they use globals that are used in exactly one place, that function. The compiler still seems to manage to optimise but I think it's sloppy.
That sounds like there's limited stack space and they're trying to conserve it by allocating variables on the heap.
-
That sounds like there's limited stack space and they're trying to conserve it by allocating variables on the heap.
Or the CPU is something like a 68HC11 which doesn't have stack-relative addressing, and my experience of the compilers available for it was(*) that they generated horrible, horrible code when you used stack-based local variables.(*) In 1990-1993.
-
And the negation thingy... Where did that guy learn algebra?
Long ago, embedded CPUs didn't support multiplication, at least not without using a library. The most common way to negate, of course, is to multiply by -1, but subtracting yourself twice also works, and isn't multiplication.
For that matter, on old CPUs, multiplication took a lot more cycles than addition; it's possible that the repeated-subtraction version is just faster.
-
Long ago, embedded CPUs didn't support multiplication, at least not without using a library. The most common way to negate, of course, is to multiply by -1, but subtracting yourself twice also works, and isn't multiplication.
For that matter, on old CPUs, multiplication took a lot more cycles than addition; it's possible that the repeated-subtraction version is just faster.
Yes, butx = -y;doesn't actually require multiplication. The most common way to negate is to subtract from zero, and all the small embedded CPUs I ever used offer a dedicated instruction for doing just that without having to specify the zero.
-
"Sane" is the wrong word to describe your struct-union mangling. What's wrong with this?
highbyte = temporary_int / 256;
lowbyte = temporary_int % 256;Or if you don't trust the compiler's optimiser, what's wrong with this?
highbyte = temporary_int >> 8;
lowbyte = temporary_int & 0xFF;I don't want to be the WTF here, I thought that was a valid use for unions. What is the issue with doing that, just the dependencies on width and endianness?
And absolutely nothing is wrong with shifting and masking. I just wanted to make it the simplest and most readable I could. My first thought was to do:
highbyte = (* ((unsigned char*)&temporary_int))
lowbyte = (* ((unsigned char*)&temporary_int +1))But I didn't think it was clear enough.
Edit: code-snippit was little-endian as pointed out by Steve_The_Cynic. Changed for clarity.
-
That sounds like there's limited stack space and they're trying to conserve it by allocating variables on the heap.
For most purposes, a static variable (either in a function or in the C file) will have the same effect as a global variable, except it will not result in silent conflicts with another variable with the same name.
-
I thought that was a valid use for unions.
I had an otherwise brilliant book on C++ that advocated this approach. Then, a few years later, it occured to me that things are... not so simple. Especially in C++.
Also, embedded programming is just one big here be dragons.
-
I don't want to be the WTF here, I thought that was a valid use for unions. What is the issue with doing that, just the dependencies on width and endianness?
And absolutely nothing is wrong with shifting and masking. I just wanted to make it the simplest and most readable I could. My first thought was to do:
lowbyte = (* ((unsigned char*)&temporary_int))
highbyte = (* ((unsigned char*)&temporary_int +1))But I didn't think it was clear enough.
I agree, it wasn't clear enough. It's also (as written, which might be an oversight or memory failure) the opposite endianness than the struct-union implies. My opinion is that the shift-and-mask version more clearly expresses what you want to do, but I might be biased... ;)Programming for tight-space embedded environments is something I haven't had to do since the beginning of 1995, and there are those who would say that one should point the finger at late 1993 instead, but some of the lessons are unforgettable...
-
Not knowing 'C', is it common to create an unsigned char, and assign it an integer value?
An unsigned char is an integer.
-
What. The. Fuck.
Really?
Huh. So it is. Thanks google. (I learned something today! ... C# has come a long way since C)
-
That sounds like there's limited stack space and they're trying to conserve it by allocating variables on the heap.
Heap? What? No. Globally-global globals, file-scope globals, and function-scope statics are not on the heap. The heap is where malloc() and friends play.And small-box embedded systems (here we are talking about a machine with 16-bit ints, something I haven't used in nearly 20 years) don't usually have enough RAM to accommodate a heap.
-
Heap is possible but not enabled here. The stack usage is not an issue.
On this platform the width of these types is:
8 bits: signed/unsigned char
8 bits: uint8_t16 bits: signed/unsigned int
16 bits: uint16_t
-
Long ago, embedded CPUs didn't support multiplication...
Ok, but nowadays they do, and even if there was no way to write x = -y; he could still have written x = 0; x -= y; or x = 0 - y;
That saves an instruction or two, and that's quite a lot on old processors.
-
It's also (as written, which might be an oversight or memory failure) the opposite endianness than the struct-union implies
That was a copy pasta from code for another platform. I didn't think to change it when posting but you're right it makes things confusing when discussing a big-endian platform. Apologies.
-
Filed under: Why is everything a global variable, gah!
So embedded programming is little like javascript
-
Hey! We have closures, dude! Closures!
-
javascript
It also doesn't support hardcoded strings except in the special case of string literals.Microsoft said:
JavaScript does not support block scope (in which a set of braces {. . .} defines a new scope), except in the special case of block-scoped variables.
-
It doesn't support thing except when it supports thing. Awesome.
-
Yes, but
x = -y;doesn't actually require multiplication. The most common way to negate is to subtract from zero, and all the small embedded CPUs I ever used offer a dedicated instruction for doing just that without having to specify the zero.I'll take your word for it--I never actually worked with an embedded system; I'm just going by what I remember reading in college.
-
Heap? What? No. Globally-global globals, file-scope globals, and function-scope statics are not on the heap. The heap is where malloc() and friends play.
And small-box embedded systems (here we are talking about a machine with 16-bit ints, something I haven't used in nearly 20 years) don't usually have enough RAM to accommodate a heap.
Ugh. Yeah, I know that, but I haven't messed much with assembly in 20 years and I couldn't remember the exact thing. .bss or .data or whatever. My point was just about the space coming conceptually from a different bag of memory.
-
Yes, but x = -y; doesn't actually require multiplication. The most common way to negate is to subtract from zero, and all the small embedded CPUs I ever used offer a dedicated instruction for doing just that without having to specify the zero.
-x = ~x + 1
-
-x = ~x + 1More like:
NEG A NEG X NEG U ; MC6809 NEG D ; MC6809but what do I know...
-
Yep, these parts also have both an 8-bit wide 'NEG' and a 16-bit wide 'NEGW' instruction. The ref doc summary states they toggle the 7th or 15th bits on the target file register (sign bits here).
-
Hey! We have closures, dude! Closures!
You have them in embedded programming too. They're the box that you glue the board into after it's built.
-
Yep, these parts also have both an 8-bit wide 'NEG' and a 16-bit wide 'NEGW' instruction. The ref doc summary states they toggle the 7th or 15th bits on the target file register (sign bits here).
WTF? Sign-and-magnitude? WTF CPU is that?For those who aren't up-to-speed on binary representations of signed numbers:
1's complement inverts all bits of a positive number to get its negative equivalent. It's simple to explain, but also causes there to be a negative zero as well as a positive zero, and is expensive to implement in hardware because of the need for "end around carry". It is rare, especially in new architectures.
2's complement is easy to implement in hardware because you can use very simple cascading add and subtract circuits without any need for anything like end around carry. -X is calculated as ~X+1, or more simply as 0-X. It has only one zero, and an extra most-negative value.
Sign-and-magnitude reserves one bit for the sign, and the only difference between X and -X is the value of this bit. This is arguably the simplest representation for us to understand as humans, because it is just like our way of writing down numbers. A hardware implementation, however, is horrible because of all the combinations of adding and subtracting positive and negative numbers, each of which needs to be routed to the correct order and operation, with the correct output value of the sign bit. For integer operations, sign-and-magnitude is tremendously rare, but most floating point systems, especially IEEE754, use it for the mantissa, but, curiously, not for the exponent.
So if the only difference between positive and negative on your machine is the sign bit, you've got something a little out of the ordinary.
-
No, you're right I was reading the wrong part. The 7th and 15th bit logic is for the 'Negative' CPU flag. The actual operation for NEGW is:
X ← 0000 - X
So that is two's compliment just like you said.
I swear I have used a uC or DSP back in the dark days that was genuinely sign-magnitude.
-
This reminds me how glad I am that I can use C now and I don't have to do things like memory bank management by hand any more or keeping track of how long my jumps are because of page boundaries.
Although you could do some fun things in assembly like linear vertical counters for input debouncing. And jump tables by directly adjusting the program counter. I had a coworker that would change execution by adjusting the return address stack directly.
-
I had a coworker that would change execution by adjusting the return address stack directly.
For those who haven't seen it. Yet. And if you haven't, where have you been?
-
The most common way to negate is to subtract from zero, and all the small embedded CPUs I ever used offer a dedicated instruction for doing just that without having to specify the zero.
I think these days you typically just hack around this via the filesystem.
-
I'm amazed the Jargon File is still around. I was completely disappointment when I had to use a PDP-11 and it did not have a 'more magic' switch (it did need a hairdryer on the main power supply on cold days though).
-
You have them in embedded programming too. They're the box that you glue the board into after it's built.
No, that's a special construct called the n-closure.
-
This reminds me how glad I am that I can use C now and I don't have to do things like memory bank management by hand any more or keeping track of how long my jumps are because of page boundaries.
If you have to program in that kind of environment, with essentially the atoms of computing instructions.... isn't the very first thing you do writing a (small) library that abstracts all of that away for you?
-
And then the second thing is you optimize for size to get rid of the bloat of YAGNI-ness of the library.
-
For those who haven't seen it.
What the hell is up with that ee cummings formatting? I remember reading this as a proper piece of text-- but maybe that was a different legend?
-
I remember reading this as a proper piece of text-- but maybe that was a different legend?
Most of the renditions I've seen (including the one in my OP) have the following postscript:
[1992 postscript --- the author writes: "The original submission to the net was not in free verse, nor any approximation to it --- it was straight prose style, in non-justified paragraphs. In bouncing around the net it apparently got modified into the `free verse' form now popular. In other words, it got hacked on the net. That seems appropriate, somehow."]
The link in this post stops there, the JF copy has further updates in 1999, 2001 and 2002.
-
There were some macros so that you could easily switch banks to the correct one for the register you wanted, to save and restore registers in interrupts and things like that. If you went too far you just ran out of program memory.
The first parts I used had just 1k of program memory and 68 bytes of data memory, it got tight quick!
-
It's also possible that back then, just like this time, I added a css rule
p br { display:none; }but have forgotten about it
-
http://www.catb.org/jargon/html/story-of-mel.html
For those who haven't seen it. Yet. And if you haven't, where have you been?
There was a similar story that was mostly probably fabricated by our college professor. I wish I could find it, and I will post it as soon as I do.
-
No, you're right I was reading the wrong part. The 7th and 15th bit logic is for the 'Negative' CPU flag. The actual operation for NEGW is:
X ← 0000 - X
So that is two's compliment just like you said.
No, that's how it would be expressed if the CPU was one's complement, because a NEG instruction calculates 0-X (the negation of X). A "complement" instruction (equivalent of the C ~ operator) would be described as something like X <- NOT X, where "NOT" means bit inversion. If you look at the value when you negate something, you'll see immediately - if we start with 0000 0001 binary and 8-bit negate it, on a one's complement machine you'll get 1111 1110 and on a two's complement machine you'll get 1111 1111. Sign-and-magnitude(*) architectures would of course give 1000 0001.It's highly unlikely that the CPU is 1's-c. The only machine I've ever used with 1's-c integers was a CDC Cyber back in the mid-to-late 80s. And don't forget the IBM System/360 floating point format, which is neither binary nor decimal. (Seriously. The exponent is a power of 16, and the mantissa is consequently a hex fraction.)
(*) It's entertaining and not entirely inappropriate that this abbreviates neatly to S&M...
-
Oh for god's sake (not at you). I didn't notice the lack of '+1'.
That's was a direct cut-n-paste from the instruction-set reference. So the manual is wrong which wouldn't be the first time.
It states elsewhere that that instruction is "Logical 2's Complement".I don't think I've ever used a one's-compliment processor. I think some of the ADI DSPs could process data (natively) in a variety of modes but they were deeply weird beasties.
-
Well, I tested it:
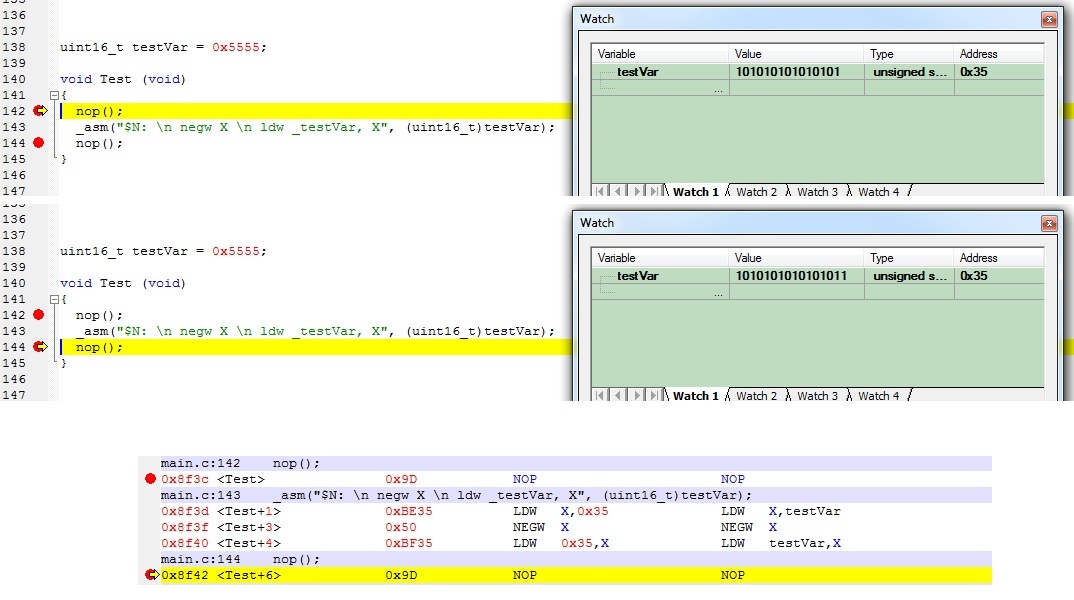
It's really helpful that the watch window suppresses the leading zero on the 'before' load of 0x5555, that made me do a double-take on the results!

Edit: The global and the argument to _asm( are because of the variable binding limitations and the auto-load-to-working-register behaviors respectively.
-
This is not a WTF! Working on an embedded system means that there might be no file system, no stack, or even no nothing. So you are effectively free to reimplement as much as you wish in any crazy way you like as long as you can blame it on something. A tip is to choose relatively worthless hardware or to refuse to pay for a decent compiler. This way you can get away with any WTF of your liking!
-
Yay for memes
