Belgium!
-
We need proper censoring of words like Belgium and Belgian!
-
We need proper censoring of words like Belgium and Belgian!
Shut your fucking mouth with those fucking swears, you cuntnuzzler. There's children reading these goddamn assforums.
-
I agree!
Also, @Lorne-Kates:
http://www.amazon.com/Depraved-Insulting-English-Peter-Novobatzky/dp/0156011492
-
There's a plugin for that (nodebb-plugin-beep), but it doesn't work like what we had on Discourse. It would replace "belgium" with "b*****m" instead of "■■■■■■■". And it only replaces text in posts, not in topic titles or post previews.
-
@NedFodder What about URLs?
-
@PleegWat It breaks URLs to other sites, but URLs to topics on the forum should still work.
-
@NedFodder said in Belgium!:
And it only replaces text in posts, not in topic titles or post previews.
Yeah, that's the only hook that's readily available. It's probably just doing a search and replace on posts after they are fetched from DB but before they are served to the client. Topic titles might also be modifiable in the same way (would have to check the docs), but I think there's nothing that could make it work in the preview right now, some additions to the core would likely be needed.
-
It's probably just doing a search and replace on posts after they are fetched from DB but before they are served to the client.
Yes, that's exactly what it does.
I've been playing around with this (don't ask me why). Here's the hooks I'm using to filter:
filter:parse.post: for post content (this is what nodebb-plugin-beep uses)filter:parse.raw: for the composer preview windowfilter:parse.signature: for signatures (why not)filter:topic.getandfilter:topics.get: for topic titles and post teasers on category pages,/unread,/recent, etc.
You can use the last two hooks to also censor tags, but that breaks the link to the tag. There's no way to censor the tags on
/tags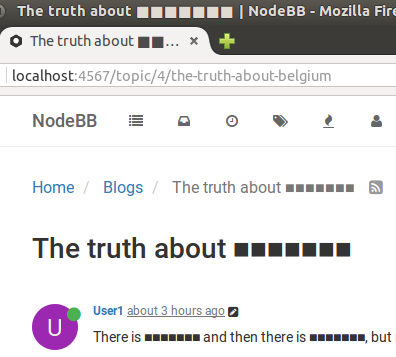
-
@NedFodder said in Belgium!:
filter:parse.raw: for the composer preview windowOh, that's a postback? Well, that explains why it gets stuck at times...
It's funny, they actually can reliably run the same parser on both client and server as opposed to Discourse (where they had to use two different parsers, even though they claimed they don't I kinda doubt it given the testing) yet they choose not to.
Well, I stand corrected on that one. That's also an interesting thing to consider if you were to try and make a native application for NodeBB, since that endpoint already exists you might as well want to use it... Hmmm...
Damn it, why don't I have more time to play with this!
-
even though they claimed they don't I kinda doubt it given the testing
They were the Discosame.
-
@loopback0 @Onyx I recall we got
 to admit that both the client and server ran the same parser but that the server did more sanitization.
to admit that both the client and server ran the same parser but that the server did more sanitization.
-
@NedFodder I remember that, but it was still a lie as there were clearly different parsers. Maybe not intentionally, but they were still different.
-
@loopback0 There are always subtle differences. I personally use Mustache, JS implementation for the client and PHP implementation for the server. They basically do the same thing, yes, but I had to tweak some templates multiple times to get it to produce the same results. Some of it is the way DOM injection works, some of it is PHP casting stuff differently than JS and vice-versa, and some of it is just
 .
.I assume it was the same thing, Ruby and JS parsers for the same templating engine, producing subtle differences for... raisins.
-
@Onyx Yeah, fine, but they actively claimed they were the same when that was clearly not true.
-
@loopback0 Not disputing that. That's kinda the reason I say I'm surprised NodeBB uses postbacks since they can run the same parser, given that the backend is also JS.
I wonder if they do it due to DOM fuckery or there are other reasons...
-
@Onyx They could do it the same way you do PDF generation in Node: take the incoming post, launch a server instance, render the post using client-side JS, browse to it using a headless browser, take the rendered DOM, and server that back up
-
@Yamikuronue Speaking as somebody who generates PDFs for a living.... WHAT THE FUCK!?
-
@Yamikuronue said in Belgium!:
PDF generation in Node: take the incoming post, launch a server instance, render the post using client-side JS, browse to it using a headless browser, take the rendered DOM, and server that back up

-
@Weng http://www.feedhenry.com/server-side-pdf-generation-node-js/
That's basically how I heard it explained to me: "There's libraries to actually generate PDFs, but that's hard, so we just use Phantom."
-
@Yamikuronue said in Belgium!:
"There's libraries to actually generate PDFs, but that's hard, so we just use Phantom."
B*****m!
-
@Yamikuronue Actually, their description of the problem domain
The API looked good, but it was too high level. It would require a lot of time to get a dynamically generated layout working. This was an important factor as the order, types and number of fields to include in the PDF would be outside our control e.g. there could be any number of text fields followed by any number of image files, which could span multiple pages. Calculating where to put each of these would require a lot of time to get right, especially trying to prevent images spanning the bottom of 1 page and the top of the next page.
is a pretty good argument against traditional PDF generation in their use case. It's very true.
But it's also a key indication that the road they chose not to take is the correct one in any case where you actually know what the hell your document needs to look like in anything but the vaguest terms.
-
Incidentally, WtfCorp has long struggled with "Turn this HTML into a PDF/printed document/part of a printed document plz!" requests from our customers. If I'd known there were a headless Webkit out there with a MakeMeAPDF() function I'd have been crowned king of Shit Hill years ago. I shall now go get myself crowned king of Shit Valley instead.
-
@Weng We successfully use that : http://wkhtmltopdf.org/
-
@Weng I hope you don't need large table support with headers on top of each page because that shit has been broken since 2012 or something. Still not fixed.
-
It's funny, they actually can reliably run the same parser on both client and server as opposed to Discourse (where they had to use two different parsers, even though they claimed they don't I kinda doubt it given the testing) yet they choose not to.
But then you'd have to also have all the plugins running on the client. Which can theoretically access anything in NodeBB, which means you're running all of NodeBB on the client.
-
@boomzilla Ah, fair point. I keep forgetting emoji and such are plugins as well.
-
@Weng Yeah, in our case I think they just skimmed an article like that one (if not that exact article), because we have people sending us PSDs of exactly what the PDF should look like, no deviance allowed, and yet they went the webkit method.
-
Damn it, why don't I have more time to play with this!
Here's my code if you want to laugh at it...
 GitHub - NedFodder/nodebb-plugin-tdwtf-censor: Censor for WTDWTF
GitHub - NedFodder/nodebb-plugin-tdwtf-censor: Censor for WTDWTF
Censor for WTDWTF. Contribute to NedFodder/nodebb-plugin-tdwtf-censor development by creating an account on GitHub.
-
Here's my code if you want to laugh at it
HAHA!!!
…oh, wait, you actually wanted us to read your code? Nah, that sounds like too much work for 11pm.