Automating a webpage with a captcha
-
I have an incredible amount of labels to generate using this webpage and I was wondering if there was some easy way to automate the process in C#?
The source data is in a SQL database and I guess I'd have to have the app display the captchas for solving and then collect the download the site generates after a redirect to a 'wait for your file' page.I found Watin is recommended but it doesn't seem to be able to do what I need with the Captcha.
Has anyone done something similar before?
-
What fields change in your dataset?
You could generate one label for each efficiency-level from this site, with placeholder texts (longer than max length of text in database).
Then replace the texts in the PDFs locally with texts from your database.
-
 Bitcoin-prijs daalt nadat Trump zegt dat de crypto ‘lijkt op een scam’ - Eepf-energylabelgenerator
Bitcoin-prijs daalt nadat Trump zegt dat de crypto ‘lijkt op een scam’ - Eepf-energylabelgenerator

Ik ben een in Engeland geboren verslaggever die het laatste nieuws voor Forbes dekt. TOPLINE Voormalig president Donald Trump – die van oudsher een strijdlustige relatie heeft met cryptocurrency – lanceerde maandag een harde aanvalsronde tegen Bitcoin en noemde het een “zwendel tegen de dollar”...
Ask here.
If they added a CAPTCHA to the page, that mean they don't want automated submissions. Don't be a jerk and do it anyway. Just contact them like a normal civilized human being and ask about your options.
-
I did some scraping automation in C# using two methods:
1. Ordinary HTTP
Download html, use html normalizer (to convert it to xhtml format), then xml parser (to convert it to
XmlDocument). Then use xpath and similar methods to find the data you need. Also use CookieJar to save session. In your case, it looks like you'd need a relatively straightforward 3 step process (get captcha, submit form, initiate download), so this is feasible.Upside: fast, efficient, great for simple scraping
Downside: no javascript, no ajax, nothing advanced2. Selenium Web Driver
It's a java library with NET interop. You get a nice class library, you start up browser (I used firefox with this), and you tell it what to do.
Upside: can get a handle on more complicated pages
Downside: fiddly, difficult to debug, slow, performance heavySounds like this watin is similar to selenium. In your place, I'd first try to do it with pure HTTP, and only if you hit a wall, go with these test automation drivers.
-
If they added a CAPTCHA to the page, that mean they don't want automated submissions. Don't be a jerk and do it anyway. Just contact them like a normal civilized human being and ask about your options.
It just means they are prejudiced against robots.
Fuck those bigots, you show them, @cursorkeys!
-
Also the templates for generating the labels offline are published: https://ec.europa.eu/energy/en/energy-labelling-tools
Judging from the painfully slow download speed I experienced when getting a single example label, local generation will be much faster.
-
If they added a CAPTCHA to the page, that mean they don't want automated submissions. Don't be a jerk and do it anyway. Just contact them like a normal civilized human being and ask about your options.
I was kind of subconsciously thinking that as I'd be filling out the captchas by hand it wouldn't be really anything different than fully manual, except for saving a crapload of typing on part numbers.
That's probably faulty thinking now you've brought that up. I'll contact them and ask for explicit permission if I do go down that route.
Also the templates for generating the labels offline are published: https://ec.europa.eu/energy/en/energy-labelling-tools
I'd need InDesign for that unfortunately. I'll ask again but last time the Adobe suite was judged too expensive to get me a license.
What fields change in your dataset?
You could generate one label for each efficiency-level from this site, with placeholder texts (longer than max length of text in database).Then replace the texts in the PDFs locally with texts from your database.
Pretty much just the part number and, occasionally, the efficiency level.
That might be a good way to tackle the problem. I'll have a look for a library to edit PDF documents and see how feasible that is.
1. Ordinary HTTP
2. Selenium Web DriverThanks! Selenium looks awesome but I'll take your advice and try the simpler method first.
-
That's probably faulty thinking now you've brought that up. I'll contact them and ask for explicit permission if I do go down that route.
You should contact them first because they probably already have a mail-merge-like solution you're not aware of because you haven't simply asked about it yet.
I'd need InDesign for that unfortunately. I'd ask again but last time the Adobe suite was judged too expensive to get me a license.
Pretty sure you can subscribe to it for one month (long enough to complete the task) for like $20. If your company can't afford that, then they're not going to be able to make your payroll anyway.
-
Pretty sure you can subscribe to it for one month (long enough to complete the task) for like $20. If your company can't afford that, then they're not going to be able to make your payroll anyway.
Yep, £17.15, that shouldn't be a problem. I think it was over a thousand pounds when I looked at it last.
I'd like a solution that isn't tied to renting another piece of software, if possible, though. This is going to be a sporadically recurring thing.You should contact them first because they probably already have a mail-merge-like solution you're not aware of because you haven't simply asked about it yet.
Point taken, I'll ask.
-
Well I'm not an open source rah rah rah kind of guy, but I do actually agree that your Government shouldn't require you to buy/rent a closed-source software product to get the job done. But if they do, sometimes you just have to cope with reality.
This is going to be a sporadically recurring thing.
You'd have to spend like 200 $20 InDesign rentals before it'd be worth the salary for someone to come up with a different solution to the problem. Seriously. Unless your time is literally worthless, just rent the software.
-
You'd have to spend like 200 $20 InDesign rentals before it'd be worth the salary for someone to come up with a different solution to the problem. Seriously. Unless your time is literally worthless, just rent the software.
But then I don't get to play around with a fun new framework

It turns out we have full licences for all of Adobe's Creative Cloud on our Marketing Departments Macintoshes. I have been instructed to use one. This should be exciting, the last Mac I used was a Mac Classic.
Thanks for all the help everyone. I'm going to play around with both of @cartman82's suggestions at home. Selenium especially looks very powerful for doing pretty much anything.
@Adynathos's suggestion on directly editing PDFs looked interesting but it seems that unless the text happens to be a very specific PDF entity (or a field) it's generally not possible. There is a nice library called iTextSharp though.
Edit: Why can't I have two solutions. I want to mark @blakeyrat *and* @Adynathos
-
Can you upload a sample PDF with representative data in all of the fields? I'm curious to see what it looks like.
-
Can you upload a sample PDF with representative data in all of the fields? I'm curious to see what it looks like.
Sure, these are about the lengths our real range and part number are. I've just noticed there is a formatting issue with the 'LED' text getting in the way of the cross. At least doing it in InDesign I can fix that.
TEST.pdf (900.1 KB)
-
Oh wow, that's really simple... I was afraid it was going to have barcodes or something... you might actually be able to just edit the PDF files, manually or with a script.
lamps-h.pdf (900.1 KB)
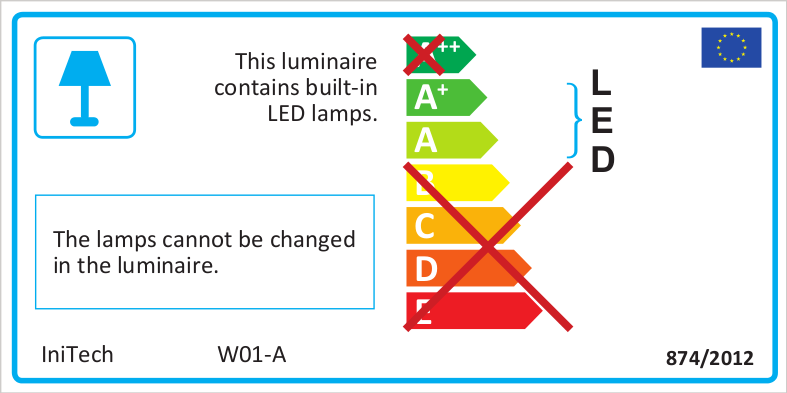
Okay... generate the label for each efficiency level you'll need to use. Naturally, it's compressed. Run it through
cpdfwith the-decompressoption:cpdf -decompress "lamps-h.pdf" -o "lamps-h-decompressed.pdf"Open in Notepad++, find the string "IniTech":

Replace both of those text fields with your actual values... I'll just use the ones in your test PDF:

Now, if you've changed the length of the text in those fields, the PDF's cross-reference segment will be incorrect... if so, you'll need to find
xref, near the end of the file, and delete that and every line following it, up to and not including thetrailerline: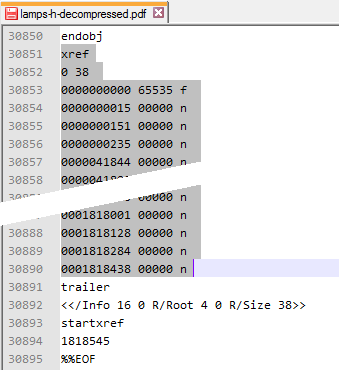
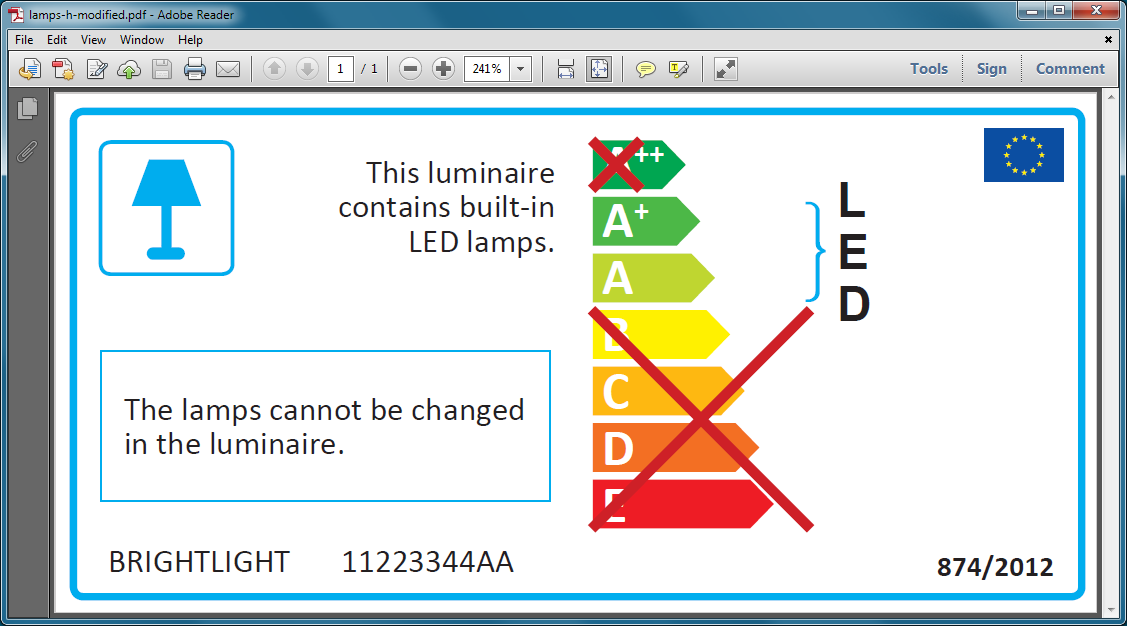
Save, and run it through
smpdf(which was included in thecpdfzip) to recreate the cross-reference and re-compress the file:smpdf "lamps-h-decompressed.pdf" -o "lamps-h-modified.pdf"And there it is:
NOTE: That only works if all the text is ASCII. Those
Tdfields don't support Unicode. At all.
-
Also, if the width of that red X is bothering you, it looks like those two Xs are just made from 4 lines, defined immediately below the text strings... in the TEST.pdf file you provided (after decompressing it), I found this:
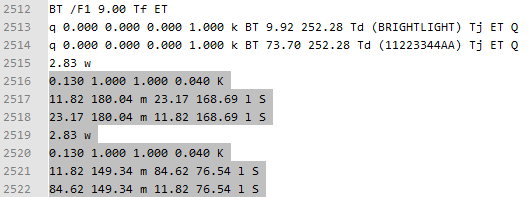
Changing
84.62to64.62in lines 2521 & 2522 resulted in changing this: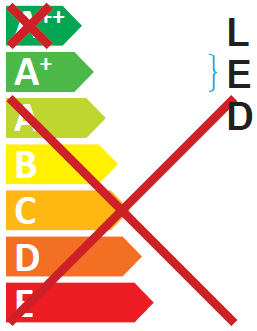 to
to 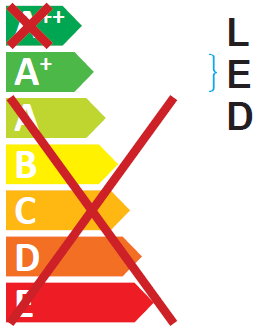
Or, leaving the red X alone and looking a few lines further down...
Increasing
77.2441and82.9134by about 13 will move the}and theLEDtext over to the right a bit, enough so it doesn't overlap the X...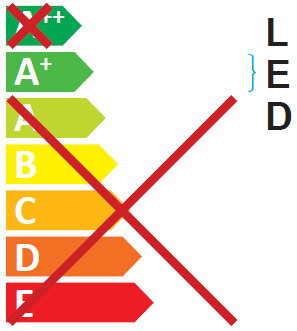
-
I don't give a shit if you mark mine as a "solution", if that helps you make your decision.
-
Oh wow, that's really simple... I was afraid it was going to have barcodes or something... you might actually be able to just edit the PDF files, manually or with a script.
...
[Awesomeness]That's really interesting, thank you for the detailed examples. Guess those articles that said PDFs couldn't be directly edited apart from fields were full of crap. They made it sound like the whole thing was vectors or similar.
I've been asked to do this task via InDesign now after explaining the options earlier to my boss. So unless InDesign turns out to be extremely slow for edit-and-save I'll have to do that (roughly 300 part numbers to do). This should definitely come in handy in the future though at the very least.
-
Guess those articles that said PDFs couldn't be directly edited apart from fields were full of crap.
Shh, let's just let the lawyer-types continue thinking that's true. ;)
They made it sound like the whole thing was vectors or similar.
Well... to be fair... it does take a bit of trial and error to find some things, like the lines that made up those Xs. I lucked out, because those were right after the text... apparently when that website generates the PDF, it dumps the dynamic content all in one place.
Text, though, is usually just text; once you decompress the PDF, you can edit it. The main gotcha is that changing the length of anything in the PDF even by a single byte will make the cross-reference incorrect, and Adobe will say it's corrupt. So there's the workaround of just removing the cross-reference and letting
smpdfrebuild it when it compresses the file.If you don't change the PDF's length, then you actually don't need to worry about the cross-reference. For instance, all the tweaking that I did to try to find those Xs was just by changing single characters in the uncompressed PDF... changing a
1to a3, for instance... so the length of the PDF doesn't change and the cross-reference doesn't cause problems. You can just save and then immediately open it in Adobe Reader to see what changed.
-
Guess those articles that said PDFs couldn't be directly edited apart from fields were full of crap
Indeed they were.
While editing existing elements may be difficult, adding new elements (which can cover the old ones and thus replace them in a printed label) is trivial.
Currently I am working on a program to make notes on lecture slides in PDF, and my way to edit PDF is to generate all my notes into a separate PDF (with QT's QGraphicsScene) and then use PyPDF2 (or pdfrw) to merge them with the original - which overlays my notes over it.
-
Guess those articles that said PDFs couldn't be directly edited apart from fields were full of crap. They made it sound like the whole thing was vectors or similar.
It depends. Some of them are, but PDFs are just an extension to PostScript, down at their core, so depending on the creator it might be text that's easily editable like that, or it might be a hex-encoded image or something that you can't really edit.
-
Guess those articles that said PDFs couldn't be directly edited apart from fields were full of crap. They made it sound like the whole thing was vectors or similar.
PDF evolves from PostScript, therefore also inherits those commands to print text and objects directly.Btw, the articles that said it couldn't be directly edited probably take into account that most these documents will convert all characters to curve so they don't have to embed the fonts, where in such case although you make still see the words as plain text if they don't remove them in save option, changing these text will have no effect on the displayed PDF file.
-
most these documents will convert all characters to curve so they don't have to embed the fonts
They can do that, but I wouldn't say that most do.
Generally speaking, it's a pain in the ass, it'll make the PDF file larger than simply embedding the correct font, and it's really only useful when you're worried that the recipient won't be able to see the correct fonts even though they're embedded in the PDF... yeah, apparently Illustrator has this problem. I suppose you could do it just because you want to obfuscate the PDF, but that's
 .
.