So about strings. And Unicode.
-
Continuing the discussion from Who needs warnings anyway? (Trigger Warning: Crystal):
@LB_, post:4, topic:52218, full:false said:
> A Char represents a Unicode code point. It occupies 32 bits.
I'm actually wondering about this. Is it worth the memory sacrifice to not have to worry about the intricacies of UTF-8 encoded strings?I guess if you don't care about memory usage at all, this is a pretty good temporary solution.
In my spare time I'm making my own programming language (mostly just writing down notes about what to do and what not to do), and I want to make sure I get this right. I was thinking, what if the default string type wastes space but is easier to use and more efficient as a result, and there is a secondary string type which uses UTF-8 to save on memory? Basically, the Crystal approach but with more choice. How do other languages do it wrong or do it right?
Also, what if one day a Unicode character requires more than 32 bits to represent? Is that something to be worried about?
These are the things that keep me up at night. Unicode is pretty scary.
-
Is that something to be worried about?
Yes, it already is. A unicode code point, regardless of its representation, does not necessarily represent "a character".You may well have to deal with unicode in strings, and that's bad enough, but for the love of all that's holy don't allow it anywhere near your source code.
-
Oh, right...that complicates things quite a bit. I forgot about the stacked accent nonsense...
I might be considering three string types... and an expensive character type...
-
Is it worth the memory sacrifice to not have to worry about the intricacies of UTF-8 encoded strings?
YES.
-
Ok, then what about UTF-32 encoded strings? How should the situation of the crazy accent stacking be dealt with in your opinion? I'm trying to figure where to draw the line.
-
Ok, then what about UTF-32 encoded strings? How should the situation of the crazy accent stacking be dealt with in your opinion? I'm trying to figure where to draw the line.
hmm that's a tough question. codepoints off the BMP are pretty rare, but they do crop up so you UTF16 needs surogate pairs even so.
and the zalgo.....
text is hard, yo!
-
I was thinking, what if the default string type wastes space but is easier to use and more efficient as a result, and there is a secondary string type which uses UTF-8 to save on memory?
That sounds like a terrible idea if your language is going to have shared libraries.
-
Why would that be? And no, the way I've done modules does away with the whole shared/static nightmare (in theory).
-
Library A uses UTF-8 strings, Library B uses 32-bit strings, your code has to constantly convert from one to the other to use its libraries.
If you're going to do this at least let them both have the same interface (or equivalent) so they're interchangeable.
-
Why would that be?
bytevsshortvsintvslongvsdecimalvsfloatvsdoublevsBigIntvsBigFloatthe more types you have for the same thing the more chance you have of someone getting it wrong.
/me would have two at the most types for number (
intanddecimal) that were basically BigInt and BigDecimal that did cool compiler tricks well outside of the visibility of the programmer to use underlying int when the rangers worked, and fell back on the bigint when it didn't.i could see
byteas useful too, but that's the end of it.same for string types. ONE TYPE IS GOOD, MANY TYPES BAD
-
No, I mean both types would coexist at the same time - you don't choose one or the other at compile time.
@accalia I'm not so sure I agree, could you explain more?
-
I'm actually wondering about this. Is it worth the memory sacrifice to not have to worry about the intricacies of UTF-8 encoded strings?
In my spare time I'm making my own programming language (mostly just writing down notes about what to do and what not to do), and I want to make sure I get this right. I was thinking, what if the default string type wastes space but is easier to use and more efficient as a result, and there is a secondary string type which uses UTF-8 to save on memory? ...
Also, what if one day a Unicode character requires more than 32 bits to represent? Is that something to be worried about?
It's going to depend on what your purpose is for the language.
If you're dealing with something for systems-level programming, then you probably want to offload stuff like this into a standard library and keep the language closely tied to the OS and processor (much like the various C-like languages do.)
On the other hand, if you're targeting application/web programming, where functionality and portability is your top concern, then it makes perfect sense to have a multilingual character string as basic type (and maybe the only supported string type.) For such a type, the APIs should work in terms of printable characters (and associated accents) without regard to the internal byte-stream representation. UTF-8, UTF-16, 32-bit Unicode, various 8-bit types, or anything else should be an implementation detail. There should be appropriate (and hopefully not too hard to use) read/write APIs to convert text in specific formats to/from the internal representation. This will allow implementers to change the internal representation without breaking existing applications.
And yes, this will completely tick off developers who want to write high-performance system-level code. Which is fine - they should be using a language without this kind of overhead anyway.
-
I'm keeping game programming in mind, so portability and close ties to the system are both important, but I also want safety like Rust. Pretty impossible sounding, right?
-
@accalia I'm not so sure I agree, could you explain more?
take your favorite language and do
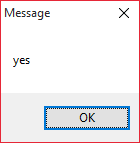
alert(0.1 + 0.2 === 0.3):-D
Hint: the result is [spoiler]false[/spoiler]!
-
Also, what if one day a Unicode character requires more than 32 bits to represent?
We'll run out long before then. The highest codepoint UTF-8 or UTF-16 can represent is U+10FFFF. The former because of the latter.
-
Games/graphics are a great example of when the loss of precision is negligible for the benefit of speed gain. Unless exact precision numbers are much more efficient nowadays, I'm sticking to providing both types and letting the programmer choose on a case-by-case basis.
-
You sure about that?
-
We'll run out long before then. The highest codepoint UTF-8 or UTF-16 can represent is U+10FFFF. The former because of the latter.
I'm not talking about code points, I'm talking about characters. A single character could be tens of code points, right?
-
No, I mean both types would coexist at the same time - you don't choose one or the other at compile time.
Right but that means the type of string used by the library is chosen by the library writer. It may or may not fit in with the one you picked. Now you have to convert strings all the fucking time. PITA.
-
A single character can be q̵̪͎̰̯͎̻̙̮̬̯̗ͧͣ̆͐͠ͅư̤̣͎̲̗̻̝͔̺̦̠̭̻͑͊̀́̈́ͧͦ̆̚͢͞͡͞ỉ̡ͣͮͬ̀̂͏̧̢̗͍̹̪͉̹̮͉̼̹͚̮̹̰͚͕t̬͓̝̪̯͓͚̝̘̙͓͎̭̦̘͖̅̿̄ͪͫ̒̉ͪ̏̚͘͠eͫ̌ͮ͗ͯ͋̾͌̃̔҉̣̹͓̤̱̱̬̠̮̀͟ ̷̫͖̤̥̭͕ͩ̀ͪͩͥͧͤ͝͝ą̾̉͐͆̂͆ͫ̅̉̅̾͏̛҉͍͖͉͈̥͈̯͓̱̟ ̴̟̙̼̜͓̥̫̬̥̙̦͓͈̫͙̮̠͇ͣ́̑ͣͫ͑͛ͯͯ̓ͥ̏́f̻̯̣͍͚̳͍̰̼͚̲͕̲̘̪̬͇̼̓͊̍͋̃ͪ͒ͧ̓͊ͣͤ̚̚͟ͅë́͋ͯͧ͛ͬ̇̆̃̃͜͠҉͉̗̜̱̫̳͔͕̫̖̦͖̮̼w̩̲̰̞̯̯̟̠͉̔̂ͦ́̅̈́͗͐̈ͨͪͮ͂̾̀͝͠ ̈́ͥ͆̓͆̄̊͂̽̾ͯ͛̍̒̎̽̍ͦ͟͞͏҉̠͍̫͈̥̪̻c̨̢͔̟͎̻̭͙̮̘̳̪̝͇̝̦͉̫̠ͪ̓̀̃͢͞ǫ̴̈́ͤͭ̐͆ͨ̈͛̿́͏̗͈̘͍͚̙̭͔̻̳͔͇͓̱ḑ̸͇̬̗͖̗͉̳̯͛̿̈́̿͘͡͝e̢ͯ̆̈́̓̽̓ͦ͂ͯ̔̄̿̐̾̅҉̛̪̘̘͚͙̩̦͈͞ ̡̢ͬͤͨ̑̊҉̭̦̪͎͔̰̺p̶̶̧̪͔̞̱̱̖̗͇̰̯̘̞̠͚̲̫̹ͪ̃̆̉̌ͣ͒͌ͨͯ̓̈́̏̕͝ǫ̸̵͓͙̤̙̭̳̙̪̩̠͚̠͈̠̮̭͐̆̓̆́͝ȋ̡̬̤̣̫̺͈̺͇̗͚͎̹́̃͒̽͐́̾͂́͜ͅṉ̷̨̦͓̻͍͇̪̜̽̈́̾̊ͣ̄̏̽ͫ͋́̇̅̂̈́ͨ̉̚t̶̞̪͙̥͍̺͙̻̪̲͌̐͆ͤͦ͒ͫ̓̋͑͛͋̒ͤͅs̴̢̙̬͈̖̣̼̗̼̥͍͓̞̝̗̰̫̹͙̘̾ͪͤ͊̿̏̍̔̄ͮ͐ͩ̅̊ͧ͢͟͝.
-
Also, what if one day a Unicode character requires more than 32 bits to represent?
That's 4 billion characters. That means you would have a little more than 1 character for every 2 people on earth (or 1 character for every 27 people to ever exist). Can I say that we really don't need that many or would I still be leaving out people's names?
Maybe Unicode should go 128-bit per character so everyone can have their own private space to fill with alphabets? Or we could unify the IP and Unicode protocols so that your personal IP address also doubles as the UTF-128 encoding of the character containing your signature.
-
Right but that means the type of string used by the library is chosen by the library writer. It may or may not fit in with the one you picked. Now you have to convert strings all the fucking time. PITA.
Point taken, thanks.
That's 4 billion characters. That means you would have a little more than 1 character for every 2 people on earth (or 1 character for every 27 people to ever exist). Can I say that we really don't need that many or would I still be leaving out people's names?
As explained above there are already more than 4 billion characters, even if they haven't all been written yet. Because of code point madness a single character could span hundreds of bytes.
-
@LB_ said:
@accalia I'm not so sure I agree, could you explain more?
take your favorite language and do
alert(0.1 + 0.2 === 0.3):-D
Hint: the result is [spoiler]false[/spoiler]!
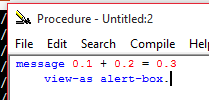
Some languages have a decimal type instead of a floating-point one.
-
In my spare time I'm making my own programming language (mostly just writing down notes about what to do and what not to do), and I want to make sure I get this right. I was thinking, what if the default string type wastes space but is easier to use and more efficient as a result, and there is a secondary string type which uses UTF-8 to save on memory? Basically, the Crystal approach but with more choice. How do other languages do it wrong or do it right?
Unicode has turned text into a complex thing. I don't really know all the details, I know you can "normalize" strings to turn them into a canonical representation and stuff. But I have two important points:
- Try to go the Python3 way and have the concepts of "byte array" and "unicode string" as separate things. You want users to have one simple type to use for reading binary files and receiving raw data from other programs, and one simple type they can use for text that will be obtained from and presented to the user.
- Don't try to abstract things that can't be abstracted! A Unicode array is a complex object, and it's OK to provide different functions to do advanced stuff with them, instead of trying to be smart. I'm sure the Unicode people have already thought of all the problems you can have, like searching text, comparing text, or character transformations (uppercase a string).
I think the thing Python does where you can open() a file in "text mode" or "binary mode" is confusing. A file is a binary string, binary strings might then be interpreted as Unicode. You can still have a function like OpenFileAndInterpretAsUnicode() but don't make it the same as plain open().
-
Try to go the Python3 way and have the concepts of "byte array" and "unicode string" as separate things. You want users to have one simple type to use for reading binary files and receiving raw data from other programs, and one simple type they can use for text that will be obtained from and presented to the user.
Ah, good point - instead of inventing a secondary string type I can just have the one and only string type be serializable to a byte array.
Don't try to abstract things that can't be abstracted! A Unicode array is a complex object, and it's OK to provide different functions to do advanced stuff with them, instead of trying to be smart. I'm sure the Unicode people have already thought of all the problems you can have, like searching text, comparing text, or character transformations (uppercase a string).
I'm planning to use http://site.icu-project.org/ in some way, that should do a lot of heavy lifting already, right?I think the thing Python does where you can open() a file in "text mode" or "binary mode" is confusing. A file is a binary string, binary strings might then be interpreted as Unicode. You can still have a function like OpenFileAndInterpretAsUnicode() but don't make it the same as plain open().
Good point, I agree. C and C++ are also confusing in this regard.
-
Try to go the Python3 way and have the concepts of "byte array" and "unicode string" as separate things. You want users to have one simple type to use for reading binary files and receiving raw data from other programs, and one simple type they can use for text that will be obtained from and presented to the user.
Well derp.
You still have Byte as a data type. So you can still make arrays of Bytes. And Char is a completely different data type, so that strings can be represented as arrays of Chars. (BASICALLY DO WHAT C# DOES.)
... what the heck did Python 2 do!?
While I'm pointing out shit: also follow C#'s lead in making a proper "TimeSpan" class, so people don't have to fudge DateTime to represent the time between two events. Since C# introduced me to the concept of TimeSpan, it drives me NUTS to see DateTime repurposed like this.
-
So, my current thoughts so far:
- There should only be one string type, and the underlying representation (UTF8/16/24/32) should be an implementation detail.
- Strings should consist of code points, and characters are an emergent property
- The default way to iterate over a string should be to iterate over the characters in the string, but you can iterate over the code points if needed
- There probably shouldn't be a character type or character literals, so how about a code point type and code point literals instead? Obviously there will be string literals, and single characters are just stored in strings.
-
BASICALLY DO WHAT C# DOES
Well, not exactly what C# does, that would be silly:
Console.WriteLine("".Length); // 2what the heck did Python 2 do
It violated it's own Tau, which resulted in lots of pain and suffering. It implicitly would convert back and forth between a byte array and a unicode string sequence, resulting in random decoding / encoding errors at run-time when combining a byte string and a unicode string as the byte string was implicitly converted to a string using the ASCII encoding (by default).
There probably shouldn't be a character type or character literals, so how about a code point type and code point literals instead? Obviously there will be string literals, and single characters are just stored in strings.
Take a look at what Perl 6 is doing ([spoiler]They're giving a type to each way of looking at strings - bytes, code points, and graphemes[/spoiler])
-
Ah, that pretty much mirrors what I want to do then. Thanks for the link!
-
I know you can "normalize" strings to turn them into a canonical representation
Did you know there are TWO canonical Unicode representations?
-
Based on that Perl 6 article, it looks like there are at least three: NFD, NFC, NFG, and some Kompatibility ones...?
-
Unicode has turned text into a complex thing. ...
Text has always been a complex thing. Unicode standardized the complexity so you didn't have to re-invent the wheel for each and every platform you need to support.
I was working on multi-lingual UI code in the 90's, when most platforms did not yet support Unicode. At that time, you had to deal with many different 8-bit encodings (all of the ISO-8859 variants, Apple variants, Microsoft variants, and many proprietary encodings.) Then there were multiple 16- and mixed-width representations for Chinese, Japanese and Korean. Bi-directional input and rendering for Hebrew and Arabic. And a host of other interesting issues, including the fact that Unicode existed but didn't have any standardized library support, making it yet another encoding we needed to manually support.
Most operating systems had some way to deal with this, but everybody did it differently. Even in the UNIX world, there was little standardization. For instance, Toshiba and Hitachi and Sony all had different (and not-quite-compatible) input method packages for extending X11. Apple had WorldScript (introduced as an extension to System 7.) Windows (that would be 3.1, 95, and NT 3.5) had a few different proprietary systems.
And any cross-platform library needed to deal with all of this in a way that would be portable and reasonable to developers on all of the supported platforms.
Unicode doesn't solve all the problems, but when used conjunction with API standardization on the big-3 platforms, the problems are not nearly as painful as they used to be.
If all you needed to do in the 90's was support ASCII text and maybe a few European accents, consider yourself lucky!
-
The default way to iterate over a string should be to iterate over the characters in the string
That's pretty much impossible. How would you interact with the character "[̝̗̹̺̗̱̱̬͈͍͕̘̰̺̳̥̑ͧ̋̍ͣ̆ͦͩͦͯ̇̾̈́͛̒̈́̐̊̅͞", for example? Generally, a type has to have a consistent size, so you're saying that each character of a string should be a dynamic array?
-
Yes, that's exactly what I am saying. Read that Perl 6 article that was linked earlier.
-
⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠⃠
-
#?

-
That's one character.
-
Yeah, it selects all at once but I guess all of the glyphs are missing in whatever font I have or Chrome just doesn't know how to render it correctly. So what?
-
I think it's COMBINING ENCLOSING CIRCLE BACKSLASH, so it should render as:

rather than a ridiculously long string of circles. I'm just glad we're not discussing rendering these things, representing them is bad enough!
-
The highest codepoint UTF-8 or UTF-16 can represent is U+10FFFF. The former because of the latter.
Yep. UTF-8 stretches completely naturally to code points up to U+7FFFFFF using an encoding like 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx.
If UTF-16 and its BOM were ever to be no longer a thing, thereby unreserving the byte values 0xFE and 0xFF, UTF-8 could go unambiguously to U+FFFFFFFF via a 111111xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx encoding style. This lets an arbitrary 32-bit code point fit in 6 bytes, but it breaks the existing UTF-8 pattern where the number of leading 1-bits in the first byte of a multibyte encoding sequence always gives you the sequence length.
Extending that pattern would allow the 7-byte form 11111110 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx and the 8-byte form 11111111 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx, meaning that UTF-8 would be usable for code points up to U+3FFFFFFFFFF (requiring a 42 bit integer type to hold an individual code point). But I suspect that even the best efforts of the multicolored emoji lunatic design brigade will fall well short of requiring four billion distinct code points.
-
A single character could be tens of code points, right?
A single glyph can indeed require an arbitrary number of code points to render via composition.
-
Or a combination of other ways of representing real numbers, usually with a flag for those which are inexact. Meaning that non only can you happily refer to 1/3 or √2 and combine them with other exact or inexact values, and even in some cases compare two inexact values of different types and get the expected result when the result is within the relevant number of ULPs.
In short, not all languages are shit at maths.
-
But I suspect that even the best efforts of the multicolored emoji lunatic design brigade will fall well short of requiring four billion distinct code points.
Imagine the size of a font that includes 4398046511103 distinct glyphs. Imagine trying to load that into memory. Maybe with an italic variant and a bold variant. And a bold-italic variant.
-
Exactly. There are natural limits to this kind of thing.
Conditions apply. Limits not guaranteed stable. The entire risk is with the reader. In no event will this poster be liable to the reader for any damages, disadvantages and expenses, including any pecuniary damages, loss of data and the like, arising to the reader or a third party out of, or in connection with, the assumption of, or inability to estimate, such limits in any given century.
-
I can say that the time frame where it's viable to transfer a many-terabytes font file over the internet as part of a stylesheet will start long after it's viable to load that into memory, and that will come long after it's viable to store a many-terabytes font file on anything at all.
-
take your favorite language and do
alert(0.1 + 0.2 === 0.3)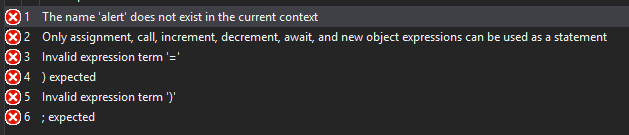
You're right, that doesn't work at all
-

Obviously, "translating for your language of choice as needed" was implied in my statement.
-
Do I look like a mindreader?
-
-
Aside: I like how it errors on
) expected
right next to
Invalid expression term: )
 Go Playground - The Go Programming Language
Go Playground - The Go Programming Language

 or not?
or not?