Why nested loop?
-
Hey, I'm working on a slow monster query. I narrowed down the performance bottleneck to a part where I'm deleting records from a large table (25M+ records) using a temporary table as an id lookup.
Execute this on a PostgreSQL server to generate a repro setup.
-- Create data table CREATE TABLE items( item character varying PRIMARY KEY, price integer ); -- Create temp table CREATE TEMPORARY TABLE scratch( item character varying PRIMARY KEY ); -- Generate 1M+ records DO $$ BEGIN FOR i IN 1 .. 1000000 LOOP INSERT INTO items(item, price) SELECT array_to_string(ARRAY(SELECT substr('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789', trunc(random() * 62)::integer + 1, 1) FROM generate_series(1, 12)), ''), random() * 100; END LOOP; END $$ LANGUAGE plpgsql;Execute analyze on this query:
DELETE FROM items WHERE item IN ( SELECT item FROM scratch ) RETURNING items.item, items.priceI get this:
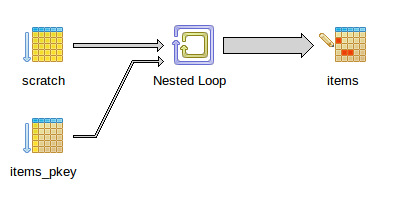
Points of interest:
- Complexity is estimeted as < 10000. In production, this part lasts ~ 5 minutes.
- Scratch table here is empty. In reality it can contain both keys that are part of the "items" table and fresh values.
- If I reduce the number of records in the "items" table, I get "hash semi join", with much better complexity score (<2000). So I presume postgres has decided 1M+ records is too much for hashing it in RAM.
Anyway, anyone has an idea how to speed this up? Since both tables are joined on the indexed primary key, there's got to be a better strategy here than the fucking nested loop.
-
Ok I dunno Postgres, but the obvious thing to try here would be to delete on a JOIN, not on a sub-query.
-
Ok I dunno Postgres, but the obvious thing to try here would be to delete on a JOIN, not on a sub-query.
Can't do that in Postgres.
 PostgreSQL delete with inner join
PostgreSQL delete with inner join

DELETE B.* FROM m_productprice B INNER JOIN m_product C ON B.m_product_id = C.m_product_id WHERE C.upc = '7094' AND B.m_pricelist_version_id = '1000020' i am getting the following er...
I tried several other variants, and they all produced the same plan.
-
Try the USING statement, like the first answer at that link.
Really weird that they removed the ability to use JOINs with DELETE. WTF?
-
DELETE FROM items USING scratch WHERE items.item = scratch.item RETURNING items.item, items.priceSame plan.
-
I don't know postgres well, but this is what I would try:
[code]
DELETE FROM items i
WHERE EXISTS (
SELECT item
FROM scratch s where s.item = i.item
)
RETURNING items.item, items.price
[/code]Assuming stratch.item has an index, it should be pretty fast.
-
I get the same plan.
I got it to use Hash Semi Join with
SET enable_nestloop = false;But that's even worse.
Delete on items (cost=39.48..168644.36 rows=1310 width=12) -> Hash Semi Join (cost=39.48..168644.36 rows=1310 width=12) Hash Cond: ((items.item)::text = (scratch.item)::text) -> Seq Scan on items (cost=0.00..145292.10 rows=8875510 width=19) -> Hash (cost=23.10..23.10 rows=1310 width=38) -> Seq Scan on scratch (cost=0.00..23.10 rows=1310 width=38)So maybe nested loop IS the best strategy here, I don't know.
-
It still bugs me, because I can guarantee you SQL Server can do that operation in an order of magnitude less time, and there's no way Postgres is that inferior.
You really need to find someone who knows Postgres inside and out. It's possible that they have this dead-last on their optimization priorities, because very few databases do large deletes like this. (Most databases do large inserts, and periodic deletes of a couple rows at a time.) Maybe they've never thought this was worth working on.
EDIT: out of curiosity, have you tried it without the RETURNING clause?
-
Same.
It doesn't seem to have anything to do with DELETE either.
SELECT COUNT(*) FROM items WHERE item IN ( SELECT item FROM scratch )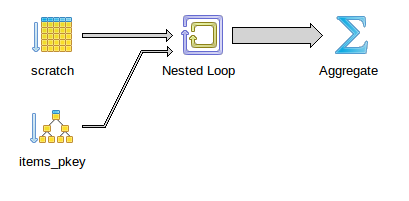
Same complexity.
-
Have you tried creating a foreign key between the tables?
Or is it possible to construct the items table where all the items you want to drop are in a partition?
Another thought, it might also be faster to truncate the table and reload everything minus the scratch items.
Postgres seems to be doing a very poor job here, imo.
-
Have you tried creating a foreign key between the tables?
ERROR: constraints on temporary tables may reference only temporary tables
SQL state: 42P16So much for that idea.
Or is it possible to construct the items table where all the items you want to drop are in a partition?
No, I don't know which items I want to drop in advance. These items are determined in a stored function and stuffed in the "scratch" table.
Another thought, it might also be faster to truncate the table and reload everything minus the scratch items.
I don't think so. In production, "items" table is like 25M, "scratch" is like 10K rows.
-
I suspect you'd prefer an index based join? Though I'm not sure whether that works on bitmap indexes.
-
It's a terrible hack, but could you break the set of deletions down into manageable chunks on the API/web server/application/whatever and do it in multiple operations? If it has to be transactional I guess not but might be worth a try.
-
Since both tables are joined on the indexed primary key, there's got to be a better strategy here than the fucking nested loop.
I'm not sure of that. You say scratch is much smaller than items, so I think that it'd make more sense to loop over scratch, then match a record from items to it on the PK, than to either browse items hashing every single entry there, or generate a hash table for items.
And merge-sort on a 25M row table is, I'm pretty sure, out of the question. I wonder why it takes that much time to do the nested loops in your prod, though - some cascade deletes you might've missed?
-
Had the same issue with SQL Server, that a big delete with a join on a temporary table took a long time to execute. What helped me was using the TABLOCKX hint in the delete statement to exclusively lock the table while deleting, i.e.
DELETE t FROM SomeTable t WITH (TABLOCKX) JOIN #tempTable o ON o.Id = t.Id
It made a huge impact, like from > 1 minute to < 1 second. I'd presume Postgres has some similar locking hint you can use? LOCK TABLE items IN EXCLUSIVE MODE?
-
Give this a shot:
CLUSTER items USING items_pkey;
-
Sorry it took me a few days, busy busy!
It's a terrible hack, but could you break the set of deletions down into manageable chunks on the API/web server/application/whatever and do it in multiple operations? If it has to be transactional I guess not but might be worth a try.
This is a part of a stored function. No point.
I'm not sure of that. You say scratch is much smaller than items, so I think that it'd make more sense to loop over scratch, then match a record from items to it on the PK, than to either browse items hashing every single entry there, or generate a hash table for items.
And merge-sort on a 25M row table is, I'm pretty sure, out of the question. I wonder why it takes that much time to do the nested loops in your prod, though - some cascade deletes you might've missed?
I'm beginning to suspect you're right. There's a reason why pg picked this strategy. And when I think logically about it, there's really no better alternative.
Don't know why so slow, though. Probably because the server itself is overloaded.
Had the same issue with SQL Server, that a big delete with a join on a temporary table took a long time to execute. What helped me was using the TABLOCKX hint in the delete statement to exclusively lock the table while deleting, i.e.
DELETE t FROM SomeTable t WITH (TABLOCKX) JOIN #tempTable o ON o.Id = t.Id
It made a huge impact, like from > 1 minute to < 1 second. I'd presume Postgres has some similar locking hint you can use? LOCK TABLE items IN EXCLUSIVE MODE?
Tried it in production. No discernible difference.
CLUSTER items USING items_pkey;
I had no idea about this. Cool!
Did it. The times are all over the place, but generally seem to be 50% faster.
I'll give it a few days, to see if things stabilize. With some other updates I made, this hotspot isn't so hot anymore.
Thanks everyone!