Programming Language Learning Curves
-
 articles/programming_language_learning_curves.md at master · Dobiasd/articles
articles/programming_language_learning_curves.md at master · Dobiasd/articles
thoughts on programming. Contribute to Dobiasd/articles development by creating an account on GitHub.
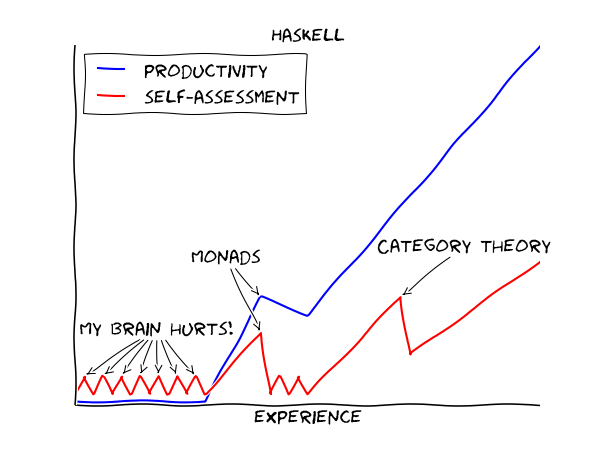
The curve for haskell is pretty accurate.
-
I've seen it. Most of these are bullshit.
Example: compare haskell productivity vs PHP productivity. And then compare the shitload of work that got done with PHP with the academic circlejerk of haskell.
-
For reference:
I've seen it. Most of these are bullshit.
That's how I read the disclaimer. Still, the Haskell one is pretty funny.
-
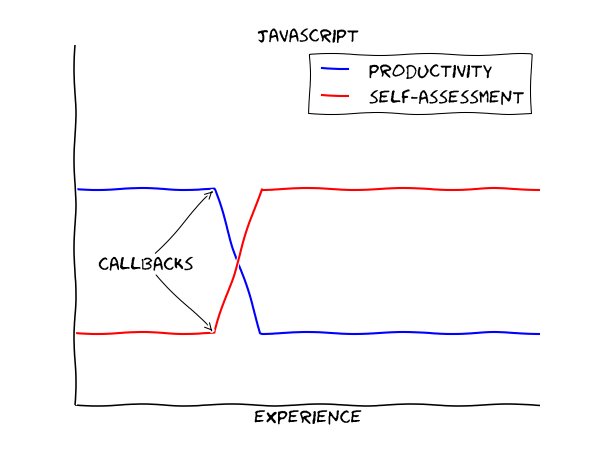
yeah i can see how that'd be accurate.
well not 100% but callbacks are one of those things that are incredibly powerful, but also hard to reason about.
-
And now we know what AbstractSingletonBeanFactories are really for ...
-
well not 100% but callbacks are one of those things that are incredibly powerful, but also hard to reason about.
I've done a lot of callback stuff with the Win32 API, but not a lot of javascript. Are js callbacks more difficult for some reason that isn't clear to me? Or is it that everyone wants to use anonymous functions for every fucking thing and nothing has a goddamned name?
I've recently (last couple of weeks) started using some 3rd party js controls to do stuff, so I'm starting to work with this stuff, and except for truly trivial stuff, I convert anonymous functions to regular functions and pass them.
-
not really more difficult, except that unlike Cpp js callbacks aren't strongly typed.
I've linked it many times here, but if you're interested @sockbot is almost entirely written in Continuation Passing Style (CPS) which makes extensive use of callbacks.
Like i said they are powerful, but hard to reason about (in any language, more so in dynamic languages, but that's because dynamic languages are dynamic)
-
@accalia has summoned me, and so I appear.
-
huh... i wasn't sure that would count as a mention.
EDIT: oh. lovely the link is broken by the @mention.
nope. i just can't link.
-
academic circlejerk of haskell.
You can get useful work done in Haskell, and you might even be able to upgrade to the next version without your code breaking.
-
As a newbie to Node.js, I've found many of the libraries (especially sqlite3) have function calls which return immediately. One of the function parameters is a callback the function will call when it actually completes.
Presumably, the library is async for performance, your code can go on and do other things while sqlite is hung up on disk I/O, but in practice it's kind of a pain and you end up with huge chains of callbacks. In my case I can see how it'll be a good thing though, while waiting on a query for whatever my server can continue to process requests from other clients and such.
-
not really more difficult, except that unlike Cpp js callbacks aren't strongly typed.
Well, yeah, like anything in js.
Like i said they are powerful, but hard to reason about
I'll take your word for it.
Continuation Passing Style (CPS) which makes extensive use of callbacks.
The Haskell framing removed any transfer of information into my brain, I'm afraid. However, looking at stuff on wiki, I see that I've used that in various ways in several languages over the years.
-
Well, yeah, like anything in js.
obviously. ;-)
I'll take your word for it.
maybe it's just that @accalia is slow... Callbacks in js do tend to lead to "curly brace hell" as callbacks nest within callbacks.... ick! split those callbacks out into named functions!
The Haskell framing removed any transfer of information into my brain, I'm afraid.
sorry, but the haskell wiki had the simplest explanation of the pattern i couls quickly find that was still completely accurate.
However, looking at stuff on wiki, I see that I've used that in various ways in several languages over the years.
not surprising. if using callbacks it's one of the simplest patterns to fall into. it's also a really awesome pattern. double good!
-
maybe it's just that @accalia is slow... Callbacks in js do tend to lead to "curly brace hell" as callbacks nest within callbacks.... ick! split those callbacks out into named functions!
Yes, that stuff is terrible form, and I never use them for anything but trivial cases. I can see how getting stuck in that anti-pattern would suck.
-
Yes, that stuff is terrible form, and I never use them for anything but trivial cases.
agreed. I'll let myself descend one level if it's something like this:
function fn1(callback) { callbackFunctionThatCanError(function(err, result){ callback(null, result || {}); }); }anything more than that needs to be split out into a proper function (usually hidden by a closure or in the case of a node module just not exported)
-
I would add a drop to the red line in Python were you start to understand imports and modules... Ugh!
-
I would add a drop to the red line in Python were you start to understand imports and modules... Ugh!
Why? They're not that hard.
-
That's how I've seen them being used. 'Hey, here is a nice shiny toy! Lets use it everywhere, the maintenance won't bite us before we have moved on to the next hype anyway!'
Not like in lisp, where callbacks serve a meaningful purpose of e.g. enabling customisations. (End flamebait)
-
IDK why but it was the hardest thing for me to understand. Maybe because my Java and C++ background. At least it has namespaces unlike others.
-
split those callbacks out into named functions!
Using curried functions can make for a reasonable compromise between named functions and continuation passing. It introduces an extra binding layer, but that can be made really thin and easy to understand.
Instead of this:
abc.def(x, function(xx) { ghj.pqr(y, function(yy) { kln.stu(z, function(zz) { done(xx, yy, zz); }); }); });You instead can do this:
abc.def(x, function(xx) { done_x(y, z, xx); }); function done_x(y, z, xx) { ghj.pqr(y, function(yy) { done_x_y(z, xx, yy); }); } function done_x_y(z, xx, yy) { kln.stu(z, function(zz) { done(xx, yy, zz); }); }Which isn't much of a simplification in this case but is pretty good when you're dealing with anything more complex.
Of course, if there were a good coroutine implementation, you'd be able to just make a pretend thread and write “linear” code. But I don't know if any of the current normal JS implementations support that sort of thing…
-
abc.def(x, function(xx) {
ghj.pqr(y, function(yy) {
kln.stu(z, function(zz) {
done(xx, yy, zz);
});
});
});actually that pattern i'd do with this:
var async = require('async'); // or equivalent async.series([ function(next) { abc.def(x, next); }, function(next) { ghi.pqr(y, next); }, function(next) { kln.stu(z, next); } ], function(err, results) { if (err) { //do error stuff return; } done.apply(this, results); });
GitHub - caolan/async: Async utilities for node and the browser
Async utilities for node and the browser. Contribute to caolan/async development by creating an account on GitHub.
-
Callbacks in js do tend to lead to "curly brace hell" as callbacks nest within callbacks.... ick! split those callbacks out into named functions!
A named function that is passed to a function and then called is still a callback. There are even some languages that support callbacks that have no syntax for anonymous functions, for example - early versions of C#.
-
A named function that is passed to a function and then called is still a callback.
while i'll admit i may have been vague i believe i never said they weren't i was referring to the pattern of anonymous functions that @dkf showed here:
Instead of this:
abc.def(x, function(xx) { ghj.pqr(y, function(yy) { kln.stu(z, function(zz) { done(xx, yy, zz); }); }); }); ```</blockquote> EDIT: GFM codeblocks are a PITA to make work in a quote. i'm not going to attempt to figure out what arcane thing i have to do to make it work here. If you know PM me or ask one of the mods to edit this and correct it.
-
I was going to quote @accalia, but it's code and Discourse so Belgium it.
How does that work with accumulation of results from the intermediate functions? It's trivial enough without the accumulation, but getting the accumulation right usually forces things to be a bit messier. (Remember, no changing of the API of the thing you're calling. Pretend all the functions are really in different libraries maintained by different people who don't really talk to each other…)
And ick, JS's syntax for currying is more than a bit ugly…
-
ok, assuming the libraries are really designed in an anti-nodejs pattern and do not pass any errors as the first parameter i do need to change the code slightly...
as for the ordering of things, that's why i use caolan's async library he already figured all that out for me and gave me a pure JS library to use (it also works just fine in the browser.)
var async = require('async'); // or equivalent function nextfn (next){ return function() { var a = Array.prototype.slice.call(arguments); a.unshift(null); next.apply(this, a); } } async.series([ function(next) { abc.def(x, nextfn(next)); }, function(next) { ghi.pqr(y, nextfn(next)); }, function(next) { kln.stu(z, nextfn(next)); } ], function(err, results) { if (err) { //do error stuff return; } done.apply(this, results); });
-
-
neither was i.
-
Are js callbacks more difficult for some reason that isn't clear to me?
There's the whole closure/scoping business which gets somewhat weird, but the sole concept of "passing a function in a variable and having it called when stuff is done" isn't really either exotic or JS-specific.
-
But you still have to play 'pass around the error objects and check if they're null'.
func count_table(table string) (result int, err error) { result, err = database.Sql("SELECT COUNT(*) FROM ?", table); return }
-
But you still have to play 'pass around the error objects and check if they're null'.
There are three options when it comes to error handling.
- Pass around the error objects like a patsy.
- Throw exceptions and hope the caller will catch you when you faIl.
- Fail in a miserable heap with unexpected behaviour and maybe a crash.
#3 seems to be the most popular one in the wild…
-
You forgot :
4. swallow the error silently and hope for the best.
In retrospect I guess that falls under unexpected behaviour.
-
Addendum:
4a. Log the errors and hide them from the user because they are only useful for debugging anyway.
-
Log the errors and hide them from the user because they are only useful for debugging anyway.
There's also the biologists approach: catch the error, log it, and then send it on its way again by rethrowing it. Because you want that error to be logged as many times as possible, with a full stack trace each time!
Filed under: Discourse disk space usage
-
I think you confusing my suggestion of something that can be done with something that should be done.
In any case, there's is a difference between the handling of the error and the displaying of it.
You should still in most cases say something to the end user, even if it's not super-detailed.
-
There's also the biologists approach: catch the error, log it, and then send it on its way again by rethrowing it. Because you want that error to be logged as many times as possible, with a full stack trace each time!
Don't just rethrow it! Each level that touches it should wrap it up in their own exception type. Separation of Concerns and all that. Don't want presentation layer code touching a persistence layer exception, do you?
-
Seen in the wild:
Catch (Exception e) { throw new Exception(e.Message); }
-
Because Belgium maintenance programmers!
-
Don't just rethrow it! Each level that touches it should wrap it up in their own exception type. Separation of Concerns and all that. Don't want presentation layer code touching a persistence layer exception, do you?
We actually at one time had exceptions which would log themselves upon construction. Real fun when the code would rewrap and then in other places log once more.
-
We actually at one time had exceptions which would log themselves upon construction. Real fun when the code would rewrap and then in other places log once more.
Is that logception or exceptionception or some combination thereof?
-
Why do you have a global variable named database? And why does database.Sql return an int?
Shouldn't you be using the sql package?
-
I don't know, I was making it up as I wrote it.
-
Why do you have a global variable named database?
How many databases do you need, Ben?
-
clearly, the solution is:
connection := <-core.ConnectionPoolwith another goroutine continually rotating connections into the pool
-
The returned DB is safe for concurrent use by multiple goroutines and maintains its own pool of idle connections. Thus, the Open function should be called just once. It is rarely necessary to close a DB.
The DB type handles connection pooling for you.
-
Okay, well there's the reason for a global ;)
-
You mean this goroutine?
go/src/database/sql/sql.go at master · golang/go
The Go programming language. Contribute to golang/go development by creating an account on GitHub.
-
I found the Haskell learning curve to be really shallow. I read the "Gentle Introduction to Haskell 98" and re-implemented the Prelude (the standard library) by reading the types and writing the functions that same day. Functional programming is very easy. The main technique is induction/recursion, which is so easy even freshmen college students are expected to understand it.
-
I read the "Gentle Introduction to Haskell 98" and re-implemented the Prelude (the standard library) by reading the types and writing the functions that same day.
From the quote file:
Brend: Whoever chose the title "A Gentle Introduction to Haskell" is obviously accustomed to wrestling bears in piranha pits or something.
Ferdirand: I was TA for a C++ programming course aimed at 1st year physics once. Some girl asked for help "i wrote pseudo-code but I cannot translate it to C++". Her pseudo-code was valid haskell. I cried.
Learning Haskell isn't really that hard, but there's a major TMI problem that makes people spend a lot of time learning things they don't really need yet. For example, unless you're writing a library, you probably don't need to create your own monads.
-
Seen in the wild:
Catch (Exception e) { throw new Exception(e.Message); }</blockquote>My favourite variation on that one is this:
catch (NullPointerException e) { throw new Exception(e.getMessage()); }It's a clbuttic, because a Java NPE has — for mysterious reasons — an empty message. The result is that you're left wondering WTF happened as everything that might be informative has been stripped. (It's usually not quite that blatant, but it's so easy for someone to make code where that happens, especially when they don't really know what the failure modes are.)
For bonus points, don't log the stack trace when finally trapping it. The message will be enough…
-


