WTF Bites
-
When a vfat thumbdrive which contains `` or $() in its volume label is plugged and mounted trough the device notifier, it's interpreted as a shell command, leaving a possibility of arbitrary commands execution. an example of offending volume label is "$(touch b)" which will create a file called b in the home folder.
Oh, for fuck's sake. They have to have written the notification handler as a shell script. It's freaking hard to write secure shell scripts; I know most of the common vulnerabilities and mitigations and I still wouldn't want to write one for a production system. It's just too convoluted.
For an (effective) OS component used by thousands of people? Drop the shell script and write the code in a programming language that better separates code and data, you lazy. stupid. fucks.
-
@heterodox said in WTF Bites:
Oh, for fuck's sake. They have to have written the notification handler as a shell script.
QString exec = m_service.exec(); MacroExpander mx(device); - mx.expandMacros(exec); + mx.expandMacrosShellQuote(exec);
-
@bb36e You forgot the next line.
KRun::runCommand(exec, QString(), m_service.icon(), 0);It's not written in shell script, but explicitly calls the shell.
-
Cocoa has the NSURLSession class which can do asynchronous loads from an URL, supporting various URL schemes and supposedly handling all issues related to protocol, caching, authentication, etc. It takes an URL and a block which will be called once the transfer is done. The block receives three parameters, the last of which is called "error" and is set to "[a]n error object that indicates why the request failed, or nil if the request was successful."
Guess what the value of "error" is if the URL is a HTTP URL and the server returned an error status code (for example a 404 Not Found).
Of course, according to StackOverflow, "The reason you're not getting an error is that there was no error; this is a perfectly valid and complete communication back and forth across the network."

-
When a vfat thumbdrive which contains `` or $() in its volume label is plugged and mounted trough the device notifier, it's interpreted as a shell command, leaving a possibility of arbitrary commands execution. an example of offending volume label is "$(touch b)" which will create a file called b in the home folder.
Cue @blakeyrat preaching that it's stupid to serialize everything as text and parsing it again a thousand times, then everyone telling him he's wrong and you just need to know how many levels of escaping you need to turn a
"into a\\\\\\\".(I'd have used back ticks instead of full quotes, but ironically, I don't know how to escape back ticks inside Markdown)
-
@ixvedeusi said in WTF Bites:
"The reason you're not getting an error is that there was no error; this is a perfectly valid and complete communication back and forth across the network."
This bit me in the past, but I can see the utility in differentiating between the two. If your HTTP request blows up (e.g. on a lower layer) then the best you can usually do is try it again. Whereas you might be able to react to HTTP codes in a more nuanced way. It would be convenient though, if you could pass in a 'non-200' block in addition to an error block.
-
@bb36e Some errors you can recover from like that. Others, you can't. Typically, 200 (or other 2**) means you should already have what you need, 3** means go elsewhere, 4** means change something in the request before resubmitting, and 5** means “the server's done something wrong” and you might be able to resubmit or you might not. (The 1** codes shouldn't ever be returned to you, and are pretty rare in reality.) In practice, you need handlers for 3** to prevent link loops and quite a bit of thought about which of the 4** and 5** error codes need handling and how.
Some of the 5** codes indicate that you should try later, but it could be a lot later. Often better to not auto-recover from those (and most 5** codes don't give much of an option other than to say “hey, user; that site is broke”). Resubmitting a request with no changes at all after a 4** is pretty much always wrong, but the sort of wrong determines the recovery strategy; some require that the client become more accepting of responses or reformat its uploaded document, some need the client to submit an auth token, and some are really just not easily recovered from. A 404 has no low-level recovery strategy, nor usually does a 400.
HTTP is messy, and the mess is probably largely necessary too.
-
I can see the utility in differentiating between the two
How about you differentiate the two by inspecting the error? It makes IMHO no sense whatsoever to ever treat a 4xx status code as a success; it's the HTTP equivalent of "On Error Resume Next".
In addition, it breaks the abstraction of the specific protocol and URL scheme. NSURLSession is supposed to handle protocol issues for me. It does actually handle 3xx redirect responses correctly, so why can't it also treat errors as errors? How about other URL schemes? This means I would now have to include protocol-specific code for every URL scheme this system may support now or in the future.
-
@dkf Except 408, which means retry immediately with no changes.
For HTTP the distinction between 4xx and 5xx doesn’t itself carry information useful to the client. The client has to do a table lookup on the entire code.
-
@ixvedeusi said in WTF Bites:
Guess what the value of "error" is if the URL is a HTTP URL and the server returned an error status code (for example a 404 Not Found).
Oh yeah. Similar thing happens with http request in UE4. Returns a boolean "bIsSuccess" which is almost always true unless there is no network or some other serious systemic problems are occurring.
-
@ixvedeusi said in WTF Bites:
Guess what the value of "error" is if the URL is a HTTP URL and the server returned an error status code (for example a 404 Not Found).
Of course, according to StackOverflow, "The reason you're not getting an error is that there was no error; this is a perfectly valid and complete communication back and forth across the network."I agree with them. A 404 response from a web server is not a HTTP error. HTTP functioned normally, worked as intended, and you got a complete and perfectly valid response.
Whether it's an error for your application, that's another issue. But the framework shouldn't make that decision for you. Otherwise, you're mixing your abstraction layers together into a big glob of shit.
I wish .NET operated the way that library does; it currently throws Exceptions for 4xx responses from HTTP servers. Which in my eyes is clearly wrong.
-
@greybeard said in WTF Bites:
Except 408, which means retry immediately with no changes.
You don't necessarily want to do that either, or at least not more than a small number of times, since the problem could be persistent (e.g., issues to do with someone else using high-bandwidth applications on your local network).
-
@dkf That would be in the category of a server returning 408 inappropriately. Overload is 502/503/504/500. But yes, you want a budget on the number of retries, among other things.
408 is itself just unnecessary complexity, leading to more opportunity for bugs. Better for the server to just close the connection.
-
@blakeyrat said in WTF Bites:
I agree with them. A 404 response from a web server is not a HTTP error. HTTP functioned normally, worked as intended, and you got a complete and perfectly valid response.
It is an error insofar as I will not get the document I was trying to get. If I ignore this condition, it is almost certain that something is going to break somewhere down the road, because I think I have a piece of data when in fact I don't. I can't think of any use case for the function in question where this wouldn't be the case.
-
@topspin As has been mentioned a few times, use extra backticks as your "quotation marks".
-
@ixvedeusi said in WTF Bites:
I can't think of any use case for the function in question where this wouldn't be the case.
What if I'm crawling to find bad links? That's just off the tippy-top of my head.
The real issue is more philosophical: layers shouldn't all mix and glom together. If the library is supposed to implement HTTP, it should implement HTTP, it shouldn't make assumptions about what the application its in is using HTTP for.
-
@ixvedeusi said in WTF Bites:
I can't think of any use case for the function in question where this wouldn't be the case.
Just read upthread for a use case: to help determine whether and when to retry the request.
-
@blakeyrat said in WTF Bites:
What if I'm crawling to find bad links? That's just off the tippy-top of my head.
@greybeard said in WTF Bites:
Just read upthread for a use case: to help determine whether and when to retry the request.
In both of these cases, you absolutely, positiely do want to know if your request succeeded or failed, you can't just ignore the HTTP status code.
If you're at a restaurant, ordering a steak, and instead you get a slip of paper saying "steaks are out", would you eat the slip of paper? Because that's the equivalent of what you're claiming here.
@blakeyrat said in WTF Bites:
The real issue is more philosophical: layers shouldn't all mix and glom together.
But this is precisely the issue here: this is not a HTTP layer library. It's a library to fetch arbitrary URLs, it sits on top of a HTTP library. These can be http://, data://, file://, ftp://, whatever:// URLs. The fact that one particular URL may use the HTTP protocol to do so is an implementation detail. I don't care where the thing came from, I just want to know if I was able to get it. And if the server replies "oops, 404", I was not able to get it.
So the way this is implemented, I have this nice encapsulation for getting the contents of an arbitrary URL, but once I receive "my data", I have to turn around and pierce through that encapsulation to find out if it happens to have been fetched with a HTTP request, and then do my own error handling in that case. And what about the non-HTTP cases? Does any other URL scheme pull the same shenanigans on me? Fuck if I know. And if Apple decides to support some new protocol in the future? SOL, I can't, today, write the error handling code for a protocol which might not even exist yet, so things are going to break.
-
@greybeard said in WTF Bites:
Better for the server to just close the connection.
It can always shut down the receiving side of the connection, blat the 408 out, and then do the close.
-
@ixvedeusi said in WTF Bites:
If you're at a restaurant, ordering a steak, and instead you get a slip of paper saying "steaks are out", would you eat the slip of paper? Because that's the equivalent of what you're claiming here.
That's an invalid analogy, because your server knows that you ordered a steak. The transport layer of your network knows no such thing about your request; all it knows is that it has a request to deliver and it needs to return back whatever the response is. Errors at that level consist of things like "I couldn't find anyone by the name you addressed it to" or "when I tried to deliver your request, nobody answered". They don't include "I delivered your request successfully, and got a response, but it probably isn't the answer you were hoping for". As long as it was able to deliver the request successfully, get a response, and return that response back to you, it considers that a success.
It's up to you as the application designer to check the response and handle cases where you got a response, but it wasn't the one that you wanted to get.
-
@dkf But that gives the client the opportunity to do the wrong thing when it sees the 408. The client already has to handle the connection closing on it; if servers just closed the connection there would be one fewer opportunity per client for a bug.
-
@ixvedeusi said in WTF Bites:
In both of these cases, you absolutely, positiely do want to know if your request succeeded or failed, you can't just ignore the HTTP status code.
If you're at a restaurant, ordering a steak, and instead you get a slip of paper saying "steaks are out", would you eat the slip of paper? Because that's the equivalent of what you're claiming here.
You need to work on your reading comprehension. I never claimed that you could just ignore the HTTP status code.
But this is precisely the issue here: this is not a HTTP layer library. It's a library to fetch arbitrary URLs, it sits on top of a HTTP library.
Wrong. If that library abstracted out HTTP, then it wouldn't return an HTTP status code for you to query.
-
(I'd have used back ticks instead of full quotes, but ironically, I don't know how to escape back ticks inside Markdown)
They don't work right:
one backtickinside single backticks`two backticks `` inside single backticksThe next two work, but require a lot more typing:
a single backtick ` inside a triple backtick blocka single backtick ` inside code tagsEdit: Then there's starting and ending on the same line with triple backticks:
single backtick ` and double backtick `` on a line with triple backtick endsthree backtickson a line with triple backtick ends```four backticks ```` on a line with triple backtick endssix backticks `````` on a line with triple backtick ends
-
@djls45 to embed backticks, just use more (or fewer) backticks to delimit it than you need to embed:
``````one `, two ``, three ```, four ````, five ````` in a six-backtick delimited string``````
=>
one `, two ``, three ```, four ````, five ````` in a six-backtick delimited string`two ``, three ```, four ````, five `````, six `````` in a single-backtick delimited string`
=>
two ``, three ```, four ````, five `````, six `````` in a single-backtick delimited stringInside
<tt>or<code>tags, you can use\`to produce backticks:
`one`, ``two``, ```three```
`one`, ``two``, ```three```However, then you'll also need to HTML-encode
<and>characters:
Use<code><code>\\\`one\\\`</code></code>to produce<code>\`one\`</code>
Use<code>\`one\`</code>to produce`one`
-
@greybeard said in WTF Bites:
If that library abstracted out HTTP, then it wouldn't return an HTTP status code for you to query.
And it doesn't. Instead it gives me a generic "URLResponse" object, which may or may not under the hood actually be a HTTPURLResponse object. In order for me to check the HTTP status code, I need to 1) check if I did indeed get a HTTPURLResponse by type inspection 1, 2) manually down-cast it to a HTTPURLResponse, and then finally 3) check if that response is a success or error.
Here I just want do fetch a darn URL. If I wanted to do advanced stuff, and would need to handle specific HTTP responses differently, I could do this whole dance just the same even if the "error" param wasn't NULL. Setting "error" on a failed response would have absolutely zero influence on this. The only thing it does is that now any user whatsoever of this interface will have to go through this type-check - down-cast - error-check dance, because there is simply no possible use case where just relying on "error" can ever be sufficient.
1 And of course the major question here is: what if it's not a HTTP response? Are there any other protocols which pull that kind of stunt? What about when Apple next decides to add support for a bunch of completely new protocols?
-
@ixvedeusi said in WTF Bites:
Instead it gives me a generic "URLResponse" object
Tomato, tomahto.
Library doesn't abstract out something you wish it did. Coding something that uses the network requires knowledge of networking protocol details. Welcome to software development.
-
-
Password=wtf47wtf 47
47with some obfuscation of details
-
@heterodox said in WTF Bites:
Drop the shell script and write the code in a programming language that better separates code and data, you lazy. stupid. fucks.
They
probably¹ did. That's why they have the error.See, shell does not do expansion and filename generation in the result of expanding a variable, only word splitting. Where this kind of error usually occurs is when one process, in any, non-shell, language, is spawning another process and uses the “simpler” API that does it through shell.
That is like assembling SQL commands by hand and should be treated the same. Well, in a sense it is—many programmers still do it even though it's evil.
-
@heterodox said in WTF Bites:
Drop the shell script and write the code in a programming language that better separates code and data, you lazy. stupid. fucks.
They probably did. That's why they have the error.
See, shell does not do expansion and filename generation in the result of expanding a variable, only word splitting. Where this kind of error usually occurs is when one process, in any, non-shell, language, is spawning another process and uses the “simpler” API that does it through shell.
That is like assembling SQL commands by hand and should be treated the same. Well, in a sense it is—many programmers still do it even though it's evil.
Here's something that could very easily fix most of that stuff:
Make the syntax for what is currently
$foomore complicated than the syntax for what is currently"$foo".Be honest: has anyone ever written
$@instead of"$@"in a shell script on purpose?I remember Google Gears throwing an exception if you tried to run a SQL query containing a string literal that was created through concatenation, or something like that. It was a pretty nice way to say "HEY IDIOT PROGRAMMER, DON'T DO THAT".
-
@blakeyrat said in WTF Bites:
layers shouldn't all mix and glom together
I agree, but
@blakeyrat said in WTF Bites:
If the library is supposed to implement HTTP
No, it isn't. It is supposed to implement getting resources by URL, abstracting away the scheme. And to abstract away the scheme, it needs to also abstract the error conditions, so a 404 for
http:resource should end up unified withENOENTforfile:resource.@blakeyrat said in WTF Bites:
What if I'm crawling to find bad links?
Well, if you were looking for bad
file:links, you would still be looking for those that produce an error using the error reporting mechanism. The meaning what is an error can, and often does, change between layers.@blakeyrat said in WTF Bites:
I wish .NET operated the way that library does; it currently throws Exceptions for 4xx responses from HTTP servers. Which in my eyes is clearly wrong.
That's a different thing. In C#, exceptions are not appropriate for conditions you actually expect, so you should be able to request a different method of reporting them. But this interface provides an error object. Being nominally an error is OK here. And even an exception would be fine e.g. in Python where exceptions in normal flow are considered OK.
-
@ben_lubar said in WTF Bites:
Make the syntax for what is currently $foo more complicated than the syntax for what is currently "$foo".
zshdoes that (subject to option).@ben_lubar said in WTF Bites:
Be honest: has anyone ever written $@ instead of "$@" in a shell script on purpose?
$@probably no, but$somethingI certainly did. But indeed rarely, so it would still make sense to make that the more complicated syntax.@ben_lubar said in WTF Bites:
Here's something that could very easily fix most of that stuff:
Unfortunately, no. It can be done—and is in some—done in interactive shells, but for backward compatidebility the
/bin/shwill still behave the unfortunate way it always did and the libraries will always use that.The real fix is to deprecate the run-with-shell flag in all the libraries like Qt and standard libraries of perl, python, javascript (node) etc. 99.9% of time there is absolutely no reason to.
-
@anotherusername said in WTF Bites:
That's an invalid analogy, because
because in this case the slip of paper in fact looks exactly like a steak, and I have to take it down to the lab to dissect it and check if there's that small inscription somewhere saying "Steaks are out, actually. And also, this is not really a steak and you'll die a slow, horrible death if you eat it."
-
Bite:
Here's the LRM dialog for picking a due date and time for an assignment when the screen is wide enough
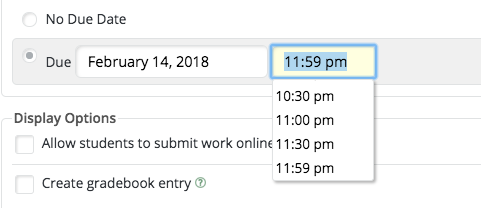
The dropdown suggestion box is nicely positioned and moves appropriately when scrolling the page.
Now here's what happens if you make the window a bit smaller--
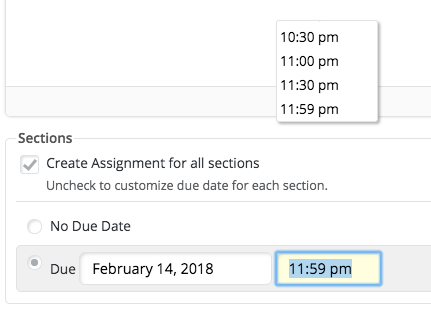
Note the position of the dropdown. It also moves (relative to the text box) when you scroll the page--it frequently shows up off screen.
-
@anotherusername said in WTF Bites:
because your server knows that you ordered a steak
And so does the HTTP server. It's even as kind to return an error to tell me that there's a problem. You know that there's a standard which defines the meanings of such codes, right? And there is a section called "errors" in there. These indicate, you guessed it, error conditions.
@anotherusername said in WTF Bites:
The transport layer of your network
I'm sure the transport layer is doing its work just nicely. I'm not talking to the transport layer. I'm talking to a library which is supposed to fetch URLs. That library has full knowledge of the HTTP protocol, including the meaning of its various status codes.
-
@ixvedeusi said in WTF Bites:
@anotherusername said in WTF Bites:
That's an invalid analogy, because
because in this case the slip of paper in fact looks exactly like a steak, and I have to take it down to the lab to dissect it and check if there's that small inscription somewhere saying "Steaks are out, actually. And also, this is not really a steak and you'll die a slow, horrible death if you eat it."
Stop trying to fix the broken analogy. It doesn't work. You can't fix it.
Realistically it's more like mailing a postcard. Your letter carrier cares about one thing and one thing only: that it gets to its addressed recipient. If it cannot, that is an error. If it can, the operation was a success and the mail carrier's job is done. They don't even care whether they get a response to bring back to you; that'd be up to the application layer -- the sender and the recipient. If the sender decides to send a response (hey, it's HTTP, so the sender should -- but again, this "should" is happening at the application layer, not the transport layer), then a postal worker will dutifully deliver that message too. All the transport layer cares about is seeing that messages get from point A to point B. What the application layer is saying in those messages literally does not matter to it.*
* ignoring, for the sake of simplicity, any deep-packet inspection that is done while enforcing QoS rules used for packet prioritization.
@ixvedeusi said in WTF Bites:
I'm not talking to the transport layer. I'm talking to a library which is supposed to fetch URLs. That library has full knowledge of the HTTP protocol, including the meaning of its various status codes.
URL != HTTP. There are tons of URI schemes; HTTP is just one of them.
I'll grant that this means my letter-carrier analogy was also flawed because a library that fetches URLs does, at least, know and care that some form of response is usually expected. It still doesn't know or care what, though.
-
@anotherusername said in WTF Bites:
URL != HTTP. There are tons of URI schemes; HTTP is just one of them.
Which is exactly my point, and the reason why this library is not part of the transport layer but of the application layer.
-
@ixvedeusi You're not supporting your idea that it should inspect the response to provide special error handling for HTTP response statuses.
If it did, then it'd also need to provide that sort of error handling for every other URI scheme.
-
@anotherusername said in WTF Bites:
URL != HTTP
What's the difference between a URL and a URI? Asking for a friend.
-
@ben_lubar One identifies a resource in the universe, the other locates it. It's right there in the name.
-
@ben_lubar said in WTF Bites:
@anotherusername said in WTF Bites:
URL != HTTP
What's the difference between a URL and a URI? Asking for a friend.
If I'm not mistaken, every URL is also a URI, and a URI is a URL if it includes a scheme (
http://,ftp://,file://, etc.).
-
No, it isn't. It is supposed to implement getting resources by URL, abstracting away the scheme.
Ok well in C# it's a HTTP layer specifically. I don't know jack shit about Swift.
-
@hungrier what about URNs?
-

-
-
-

I wonder if it's fixed if you Tab over to it and hold down Enter...
-
@hungrier what about URNs?
You can serve coffee from them.
From urin?
-
View from admin account:
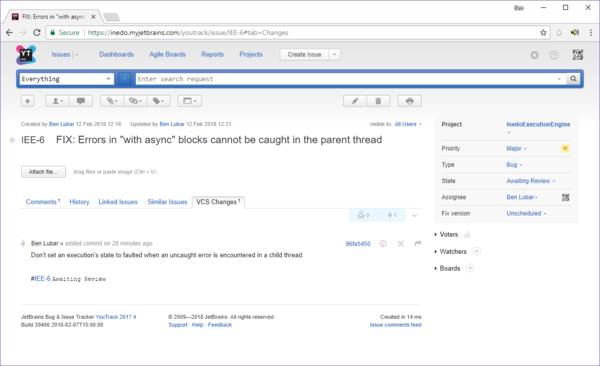
View from guest account:
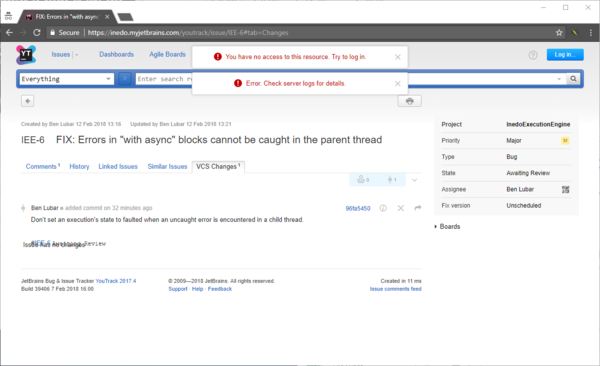
The errors only happen on the VCS Changes tab, so it's not the two hidden headings in the sidebar.
What information is the guest user not allowed to see?
-
@hungrier what about URNs?
You can serve coffee from them.
From urin?
Be careful with that, it might make you URL
 — it's exactly what they did
— it's exactly what they did